الاستعلام عن Apache Hive من خلال برنامج تشغيل JDBC في HDInsight
تعرف على كيفية استخدام برنامج تشغيل JDBC من تطبيق Java. لإرسال استعلامات Apache Hive إلى Apache Hadoop في Azure HDInsight. توضح المعلومات الواردة SQuirreL SQL في هذا المستند كيفية الاتصال برمجيا ومن العميل.
للحصول على مزيدٍ من المعلومات عن Hive JDBC Interface، راجع HiveJDBCInterface.
المتطلبات الأساسية
- مجموعة HDInsight Hadoop. لإنشاء واحدة، راجع ابدأ باستخدام Azure HDInsight. تأكد من تشغيل خدمة HiveServer2.
- Java Developer Kit (JDK) version 11 الإصدار 11 أو أعلى.
- SQuirreL SQL. SQuirreL عبارة عن تطبيق عميل JDBC.
سلسلة اتصال JDBC
يتم إجراء اتصالات JDBC بمجموعة HDInsight على Azure عبر منفذ 443. يتم تأمين نسبة استخدام الشبكة باستخدام TLS/SSL. البوابة العامة التي تجلس خلفها المجموعات تعيد توجيه حركة المرور إلى المنفذ الذي يستمع إليه HiveServer2 بالفعل. توضح سلسلة الاتصال التالية التنسيق المطلوب استخدامه مع HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
استبدل CLUSTERNAME باسم مجموعة HDInsight الخاصة بك.
اسم المضيف في سلسلة الاتصال
اسم المضيف "CLUSTERNAME.azurehdinsight.net" في سلسلة الاتصال هو عنوان URL نفسه الخاص بالمجموعة. يمكنك الحصول عليه من خلال مدخل Azure.
منفذ في سلسلة الاتصال
يمكنك فقط استخدام المنفذ 443 للاتصال بالمجموعة من بعض الأماكن خارج شبكة Azure الظاهرية. HDInsight هي خدمة مُدارة، مما يعني أن جميع الاتصالات إلى المجموعة تتم إدارتها عبر بوابة آمنة. لا يمكنك الاتصال بـ HiveServer 2 مباشرةً على المنفذين 10001 أو 10000. هذه المنافذ ليست مكشوفة للخارج.
المصادقة
عند إنشاء الاتصال، استخدم اسم مدير مجموعة HDInsight وكلمة المرور للمصادقة. من عملاء JDBC مثل SQuirreL SQL، أدخل اسم المسؤول وكلمة المرور في محددات الوحدة التابعة.
من تطبيق Java، يجب عليك استخدام الاسم وكلمة المرور عند إنشاء اتصال. على سبيل المثال، يفتح كود Java التالي اتصالاً جديدًا:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
التواصل مع عميل SQuirreL SQL
SQuirreL SQL عبارة عن عميل JDBC يمكن استخدامه لتشغيل استعلامات Hive عن بُعد باستخدام مجموعة HDInsight الخاصة بك. تفترض الخطوات التالية أنك ثبّّتَ SQuirreL SQL بالفعل.
أنشئ دليلاً يحتوي على ملفات معينة ليتم نسخها من المجموعة الخاصة بك.
في البرنامج النصي التالي، استبدل
sshuserباسم حساب مستخدم SSH للمجموعة. استبدلCLUSTERNAMEباسم مجموعة HDInsight. من سطر الأوامر، غيِّر دليل العمل الخاص بك إلى الدليل الذي تم إنشاؤه في الخطوة السابقة، ثم أدخل الأمر التالي لنسخ الملفات من مجموعة HDInsight:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .ابدأ تشغيل تطبيق SQuirreL SQL. من يسار النافذة، حدد برامج تشغيل الجهاز.

من الرموز الموجودة أعلى مربع حوار برامج تشغيل الجهاز، حدد رمز + لإنشاء برنامج تشغيل.
في مربع الحوار برنامج التشغيل المضاف، أضف المعلومات التالية:
الخاصية القيمة الاسم Hive مثال عنوان URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2مسار فئة إضافية استخدم زر إضافة لإضافة كافة ملفات jar التي تم تنزيلها مسبقًا. اسم الفئة org.apache.hive.jdbc.HiveDriver 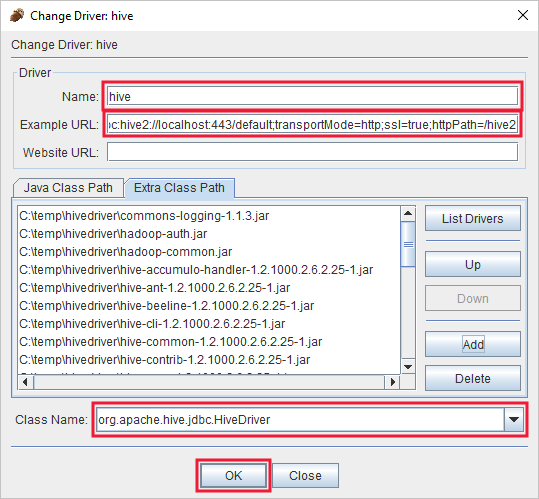
حدد موافق لحفظ هذه الإعدادات.
على يسار نافذة SQuirreL SQL، حدد الأسماء المستعارة. ثم حدد أيقونة + لإنشاء اسم مستعار للاتصال.
استخدم القيم التالية لمربع حوار إضافة اسم مستعار:
الخاصية القيمة الاسم Hive على HDInsight برنامج التشغيل استخدم القائمة المنسدلة لتحديد محرك Hive. عنوان URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. استبدل CLUSTERNAME باسم مجموعة HDInsight الخاصة بك.اسم المستخدم اسم حساب تسجيل دخول المجموعة لمجموعة HDInsight الخاصة بك. الاسم الافتراضي هو admin. كلمة المرور كلمة المرور لحساب تسجيل الدخول إلى المجموعة. 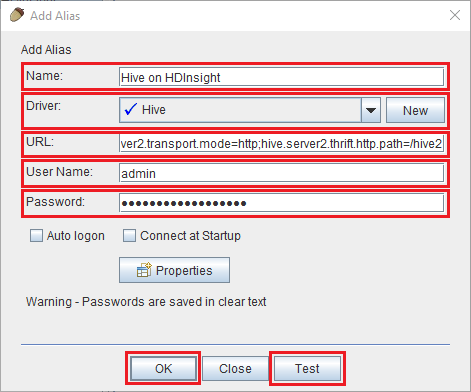
هام
استخدم زر اختبار للتحقق من عمل الاتصال. عندما يظهر مربع حوار الاتصال بـ: Hive على HDInsight، حدد اتصال لإجراء الاختبار. في حالة نجاح الاختبار، سترى مربع حوار تم الاتصال بنجاح. في حالة حدوث خطأ، راجع استكشاف الأخطاء وإصلاحها.
لحفظ الاسم المستعار للاتصال، استخدم زر موافق في الجزء السفلي من مربع حوار إضافة اسم مستعار.
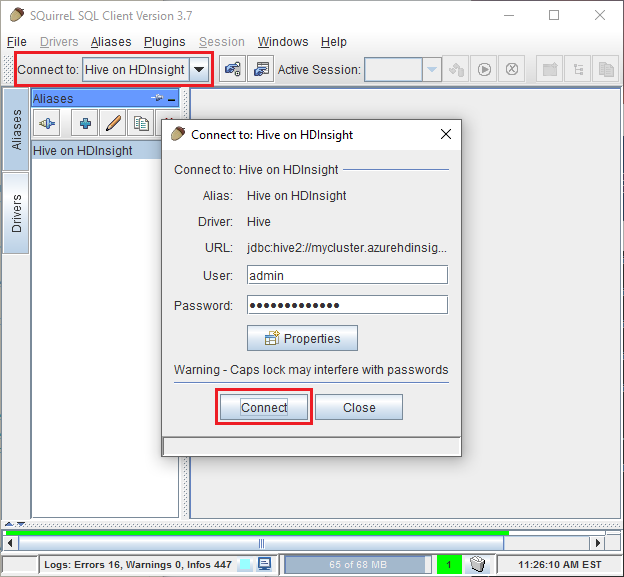
من القائمة المنسدلة اتصال بـ في الجزء العلوي من SQuirreL SQL، حدد Hive على HDInsight. عند المطالبة، حدد اتصال.
بمجرد الاتصال، أدخل الاستعلام التالي في مربع حوار استعلام SQL، ثم حدد أيقونة تشغيل (شخص قيد التشغيل). يجب أن تعرض منطقة النتائج نتائج الاستعلام.
select * from hivesampletable limit 10;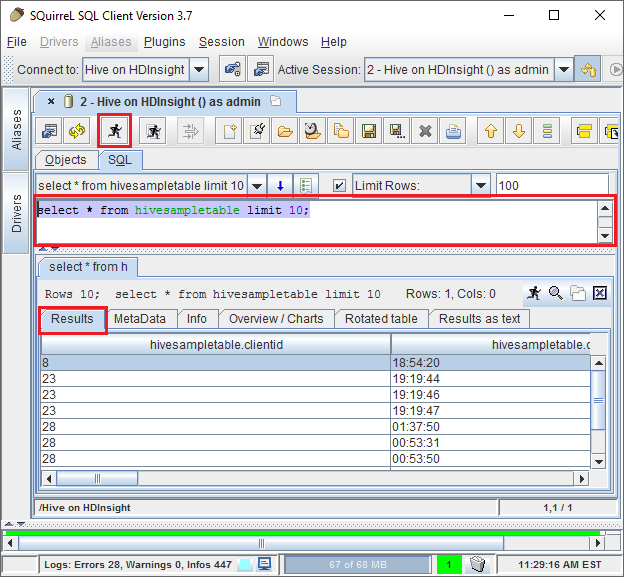
الاتصال من مثال تطبيق Java
مثال على استخدام عميل Java للاستعلام عن Hive على HDInsight متاح في https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. اتبع التعليمات الواردة في المستودع لبناء العينة وتشغيلها.
استكشاف الأخطاء وإصلاحها
حدث خطأ غير متوقع أثناء محاولة فتح اتصال SQL
الأعراض: عند الاتصال بمجموعة HDInsight من الإصدار 3.3 أو أحدث، قد تتلقى خطأ بحدوث خطأ غير متوقع. يبدأ تتبع المكدس لهذا الخطأ بالأسطر التالية:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
السبب: يحدث هذا الخطأ بسبب إصدار أقدم من ملف commons-codec.jar مضمن مع SQuirreL.
الحل: لإصلاح هذا الخطأ، استخدم الخطوات التالية:
اخرج من SQuirreL، ثم انتقل إلى الدليل حيث تم تثبيت SQuirreL على نظامك، ربما
C:\Program Files\squirrel-sql-4.0.0\lib. في دليل SquirreL، ضمن دليلlib، استبدل commons-codec.jar الحالي بالملف الذي تم تنزيله من مجموعة HDInsight.أعد تشغيل SQuirreL. ينبغي ألا يحدث الخطأ بعد الآن عند الاتصال بـ Hive على HDInsight.
قطع الاتصال عن طريق HDInsight
الأعراض: يقطع HDInsight الاتصال بشكل غير متوقع عند محاولة تنزيل كمية هائلة من البيانات (على سبيل المثال عدة GBs) من خلال JDBC/ODBC.
السبب: القيد على عقد البوابة يسبب هذا الخطأ. عند إحضار البيانات من JDBC/ODBC، يجب أن تمر جميع البيانات عبر عقدة البوابة. ومع ذلك، لم يتم تصميم البوابة لتنزيل كمية هائلة من البيانات، لذل قد تغلق البوابة الاتصال إذا لم تستطع التعامل مع نسبة استخدام الشبكة.
الحل: تجنب استخدام برنامج تشغيل JDBC/ODBC لتنزيل كميات ضخمة من البيانات. انسخ البيانات مباشرةً من تخزين blob بدلاً من ذلك.
الخطوات التالية
الآن بعد أن تعلمت كيفية استخدام JDBC للعمل مع Hive، استخدم الروابط التالية لاستكشاف طرق أخرى للعمل مع Azure HDInsight.
- إظهار بيانات Apache Hive باستخدام معلومات Microsoft Power المهنية في Azure HDInsight.
- إظهار بيانات Interactive Query Hive باستخدام معلومات Power المهنية في Azure HDInsight.
- توصيل Excel بـ HDInsight باستخدام برنامج تشغيل Microsoft Hive ODBC.
- قم بتوصيل Excel بـ Apache Hadoop باستخدام Power Query.
- استخدام Apache Hive مع HDInsight
- استخدام Apache Pig مع HDInsight
- استخدام مهام MapReduce مع HDInsight