البرنامج التعليمي: استخدام الدفق المنظم لدى Apache Spark مع Apache Kafka على HDInsight
يوضح هذا البرنامج التعليمي كيفية استخدام Apache Spark Structured Streaming لقراءة البيانات وكتابتها باستخدام Apache Kafka على Azure HDInsight.
إن Spark Structured Streaming هو محرك معالجة دفق مبني على Spark SQL. فهو يسمح لك بالتعبير عن حسابات التدفق بنفس طريقة حساب الدُفعات على البيانات الثابتة.
في هذا البرنامج التعليمي، تتعلم كيفية:
- استخدم قالب Azure Resource Manager لإنشاء مجموعات
- استخدم Spark Structured Stream مع Kafka
عند الانتهاء من الخطوات الواردة في هذا المستند، تذكر حذف المجموعات لتجنب الرسوم الزائدة.
المتطلبات الأساسية
jq، معالج JSON لسطر الأوامر. راجع https://stedolan.github.io/jq/.
الإلمام باستخدام Jupyter Notebooks مع Spark على HDInsight. للحصول على مزيدٍ من المعلومات، راجع مستند تحميل البيانات وتشغيل الاستعلامات باستخدام Apache Spark على HDInsight.
الإلمام بلغة البرمجة Scala. تكون التعليمات البرمجية المستخدمة في هذا البرنامج التعليمي مكتوبة بلغة Scala.
المعرفة بإنشاء موضوعات Kafka. للحصول على مزيدٍ من المعلومات، انظر المستند بدء التشغيل السريع لـ Apache Kafka على HDInsight.
هام
تتطلب الخطوات في هذا المستند مجموعة موارد Azure التي تحتوي على كل من مجموعتي Spark على HDInsight وKafka على HDInsight. تقع هاتان المجموعتان داخل شبكة Azure افتراضية، ما يسمح لمجموعة Spark بأن تتواصل مباشرةً مع مجموعة Kafka.
من أجل راحتك، يرتبط هذا المستند بقالب يستطيع إنشاء كل موارد Azure المطلوبة.
للاطلاع على مزيد من المعلومات حول استخدام HDInsight في شبكة افتراضية، انظر المستند تخطيط شبكة افتراضية لـ HDInsight.
Structured Streaming مع Apache Kafka
إن Spark Structured Streaming هو محرك معالجة دفق مبني على محرك Spark SQL. عند استخدام Structured Streaming، يمكنك كتابة استعلامات متدفقة بنفس الطريقة التي تكتب بها الاستعلامات المجمعة.
توضح مقتطفات التعليمات البرمجية التالية القراءة من Kafka وتخزينها في ملف. يكون المقتطف الأول هو عملية دفعية، بينما المقتطف الثاني هو عملية دفق:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
في كلا المقتطفين، تُقرأ البيانات من Kafka وتُكتب في ملف. تكون الاختلافات بين الأمثلة هي:
| دُفعة | الدفق |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
كما تستخدم عملية الدفق awaitTermination(30000)، الذي يوقف الدفق بعد 30000 مللي ثانية.
لاستخدام Structured Streaming مع Kafka، يجب أن يعتمد مشروعك على الحزمة org.apache.spark : spark-sql-kafka-0-10_2.11. يجب أن يتطابق إصدار هذه الحزمة مع إصدار Spark على HDInsight. بالنسبة إلى Spark 2.4 (متوفر في HDInsight 4.0)، يمكنك العثور على معلومات التبعية لمختلف أنواع المشاريع في https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
بالنسبة إلى Jupyter Notebook المستخدم مع هذا البرنامج التعليمي، تقوم الخلية التالية بتحميل تبعية الحزمة هذه:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
إنشاء مجموعات
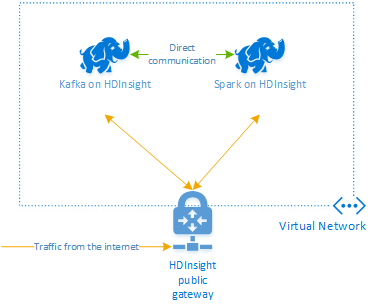
لا يقدم Apache Kafka على HDInsight إمكانية الوصول إلى وسطاء Kafka عبر اتصال الإنترنت العام. يجب أن يوجد أي شيء يستخدم Kafka في شبكة Azure الافتراضية نفسها. في هذا البرنامج التعليمي، يوجد كلا مجموعتي Kafka وSpark في شبكة Azure الافتراضية نفسها.
يبين المخطط التالي كيف يتدفق الاتصال بين Spark وKafka:
إشعار
تقتصر خدمة Kafka على الاتصال داخل الشبكة الافتراضية. يمكن الوصول إلى خدمات أخرى في المجموعة، مثل SSH وAmbari، عبر الإنترنت. للاطلاع على مزيد من المعلومات حول المنافذ العامة المتاحة مع HDInsight، راجع المنافذ وعناوين URL المستخدمة من جانب HDInsight.
لإنشاء Azure Virtual Network، ثم إنشاء أنظمة مجموعات Kafka وSpark داخلها، اتبع الخطوات التالية:
استخدم الزر التالي لتسجيل الدخول إلى Azure وافتح النموذج في مدخل Azure.

يوجد قالب Azure Resource Manager في https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
ينشئ هذا القالب الموارد التالية:
نظام مجموعة Kafka على HDInsight 4.0 أو 5.0.
Spark 2.4 أو 3.1 على نظام مجموعة HDInsight 4.0 أو 5.0.
شبكة Azure Virtual Network تحتوي على أنظمة مجموعات HDInsight.
هام
يتطلب دفتر الملاحظات المتدفق المنظم المستخدم في هذا البرنامج التعليمي Spark 2.4 أو 3.1 على HDInsight 4.0 أو 5.0. إذا كنت تستخدم إصداراً سابقاً من Spark على HDInsight، فستتلقى أخطاء عند استخدام الدفتر.
استخدم المعلومات التالية لملء الإدخالات في قسم القالب المخصص:
الإعداد القيمة الاشتراك اشتراكك في Azure مجموعة الموارد مجموعة الموارد التي تحتوي على موارد. الموقع منطقة Azure التي تم إنشاء الموارد فيها. Spark Cluster Name اسم مجموعة Spark. يجب أن تكون الأحرف الستة الأولى مختلفة عن اسم نظام مجموعة Kafka. Kafka Cluster Name اسم مجموعة Kafka. يجب أن تكون الأحرف الستة الأولى مختلفة عن اسم نظام مجموعة Spark. Cluster Login User Name اسم المستخدم المسؤول للمجموعات. Cluster Login Password كلمة مرور المستخدم المسؤول للمجموعات. SSH User Name مستخدم SSH المقرر إنشاؤه للمجموعات. SSH Password كلمة مرور مستخدم SSH. 
اقرأ البنود والشروط ، ثم حدد I agree to the terms and conditions stated above.
حدد شراء.
إشعار
قد يستغرق إنشاء المجموعات 20 دقيقة.
استخدام Spark Structured Streaming
يوضح هذا المثال كيفية استخدام Spark Structured Streaming مع Kafka على HDInsight. تستخدم البيانات الخاصة برحلات سيارات الأجرة، والتي توفرها مدينة نيويورك. تؤخذ مجموعة البيانات التي يستخدمها هذا الدفتر من 2016 Green Taxi Trip Data.
جمع معلومات المضيف. استخدم الأمرين curl وjq أدناه للحصول على معلومات مضيفي برنامج Kafka ZooKeeper والوسيط. تم تصميم الأوامر لموجه أوامر Windows، وستكون هناك حاجة إلى اختلافات طفيفة في البيئات الأخرى. استبدل
KafkaClusterباسم مجموعة Kafka الخاصة بك، واستبدلKafkaPasswordبكلمة مرور تسجيل دخول المجموعة. وكذلك، استبدلC:\HDI\jq-win64.exeبالمسار الفعلي لتثبيت jq الخاص بك. أدخل الأوامر في موجه أوامر Windows واحفظ النتيجة لاستخدامها في الخطوات اللاحقة.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"من متصفح ويب، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net/jupyter، حيثCLUSTERNAMEهو اسم نظام المجموعة. عند المطالبة، أدخل تسجيل الدخول إلى المجموعة (المسؤول) وكلمة المرور المستخدمة عند إنشاء المجموعة.حدد New > Spark لإنشاء دفتر ملاحظات.
يحتوي تدفق Spark على دفعات صغيرة، ما يعني أن البيانات تأتي على شكل دفعات ويتم تشغيل المنفذين على دفعات من البيانات. إذا كان المنفذ لديه مهلة خمول أقل من الوقت الذي يستغرقه معالجة الدُفعة، فسيتم إضافة المنفذين وإزالتهم باستمرار. إذا كانت مهلة خمول المنفذين أكبر من مدة الدفعة، فلن يتم إزالة المنفذ مطلقاً. ولذا، فنحن نوصي بتعطيل التخصيص الديناميكي عن طريق تعيين تمكين spark.dynamicAllocation ليكون false عند تشغيل تطبيقات البث.
قم بتحميل الحزم التي يستخدمها دفتر الملاحظات بإدخال المعلومات التالية في خلية دفتر ملاحظات. قم بتشغيل الأمر باستخدام CTRL + ENTER.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }إنشاء موضوع Kafka. قم بتحرير الأمر أدناه عن طريق استبدال
YOUR_ZOOKEEPER_HOSTSبمعلومات مضيف Zookeeper المستخرجة في الخطوة الأولى. أدخل الأمر الذي تم تحريره في دفتر Jupyter Notebook لإنشاء موضوعtripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersاسترداد البيانات حول رحلات سيارات الأجرة. أدخل الأمر في الخلية التالية لتحميل البيانات الخاصة برحلات سيارات الأجرة في مدينة نيويورك. يتم تحميل البيانات في إطار بيانات ثم يتم عرض إطار البيانات كنتيجة الخلية.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()تعيين معلومات مضيفي وسيط Kafka. استبدل
YOUR_KAFKA_BROKER_HOSTSبمعلومات مضيفي الوسيط التي قمت باستخراجها في الخطوة 1. أدخل الأمر الذي تم تحريره في خلية Jupyter Notebook التالية.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")أرسل البيانات إلى Kafka. في الأمر التالي، يتم استخدام الحقل
vendoridكقيمة أساسية لرسالة Kafka. يستخدم Kafka المفتاح عند تقسيم البيانات. يتم تخزين جميع الحقول في رسالة Kafka كقيمة سلسلة JSON. أدخل الأمر التالي في Jupyter لحفظ البيانات في Kafka باستخدام استعلام دفعي.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")التعريف بالمخطط. يوضح الأمر التالي كيفية استخدام مخطط عند قراءة بيانات JSON من kafka. أدخل الأمر في خلية Jupyter التالية.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")حدد البيانات وابدأ الدفق. يوضح الأمر التالي كيفية استرداد البيانات من Kafka باستخدام استعلام دفعي. ثم اكتب النتائج في HDFS على مجموعة Spark. في هذا المثال، يسترد
selectالرسالة (حقل القيمة) من Kafka ويطبق المخطط عليها. تتم كتابة البيانات بعد ذلك إلى HDFS (WASB أو ADL) بتنسيق Parquet. أدخل الأمر في خلية Jupyter التالية.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")يمكنك التحقق من إنشاء الملفات عن طريق إدخال الأمر في خلية Jupyter التالية. يسرد الأمر الملفات الوارد في دليل
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataبينما استخدم المثال السابق استعلاماً دُفعياً، يوضح الأمر التالي كيفية القيام بنفس الشيء باستخدام الاستعلام المتدفق. أدخل الأمر في خلية Jupyter التالية.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")قم بتشغيل الخلية التالية للتحقق من كتابة الملفات بواسطة الاستعلام المتدفق.
%%bash hdfs dfs -ls /example/streamingtripdata
تنظيف الموارد
لحذف الموارد المُنشأة خلال هذا البرنامج التعليمي، يمكنك حذف مجموعة الموارد. يؤدي حذف مجموعة الموارد أيضاً إلى حذف مجموعة HDInsight المرتبطة بالمجموعة. وأي موارد أخرى مرتبطة بمجموعة الموارد.
لإزالة مجموعة الموارد باستخدام مدخل Microsoft Azure:
- في مدخل Microsoft Azure، توسيع القائمة على الجانب الأيمن لفتح قائمة الخدمات، ثم اختر Resource Groups لعرض قائمة مجموعات الموارد.
- تحديد موقع مجموعة الموارد لحذفها، ثم التحديد بزر الماوس الأيمن فوق زر المزيد (...) على الجانب الأيمن من القائمة.
- تحديد «Delete resource group» من شريط الأدوات.
تحذير
تبدأ فوترة نظام المجموعة HDInsight بمجرد إنشاء مجموعة، وتتوقف عند حذف المجموعة. يتم احتساب الفوترة بالتناسب لكل دقيقة؛ لذلك يجب عليك دائمًا حذف مجموعتك عندما لا تكون قيد الاستخدام.
إن حذف Kafka من مجموعة HDInsight يحذف أي بيانات مخزنة في Kafka.