This reference architecture shows how to perform batch scoring with R models using Azure Batch. Azure Batch works well with intrinsically parallel workloads and includes job scheduling and compute management. Batch inference (scoring) is widely used to segment customers, forecast sales, predict customer behaviors, predict maintenance, or improve cyber security.
Download a Visio file of this architecture.
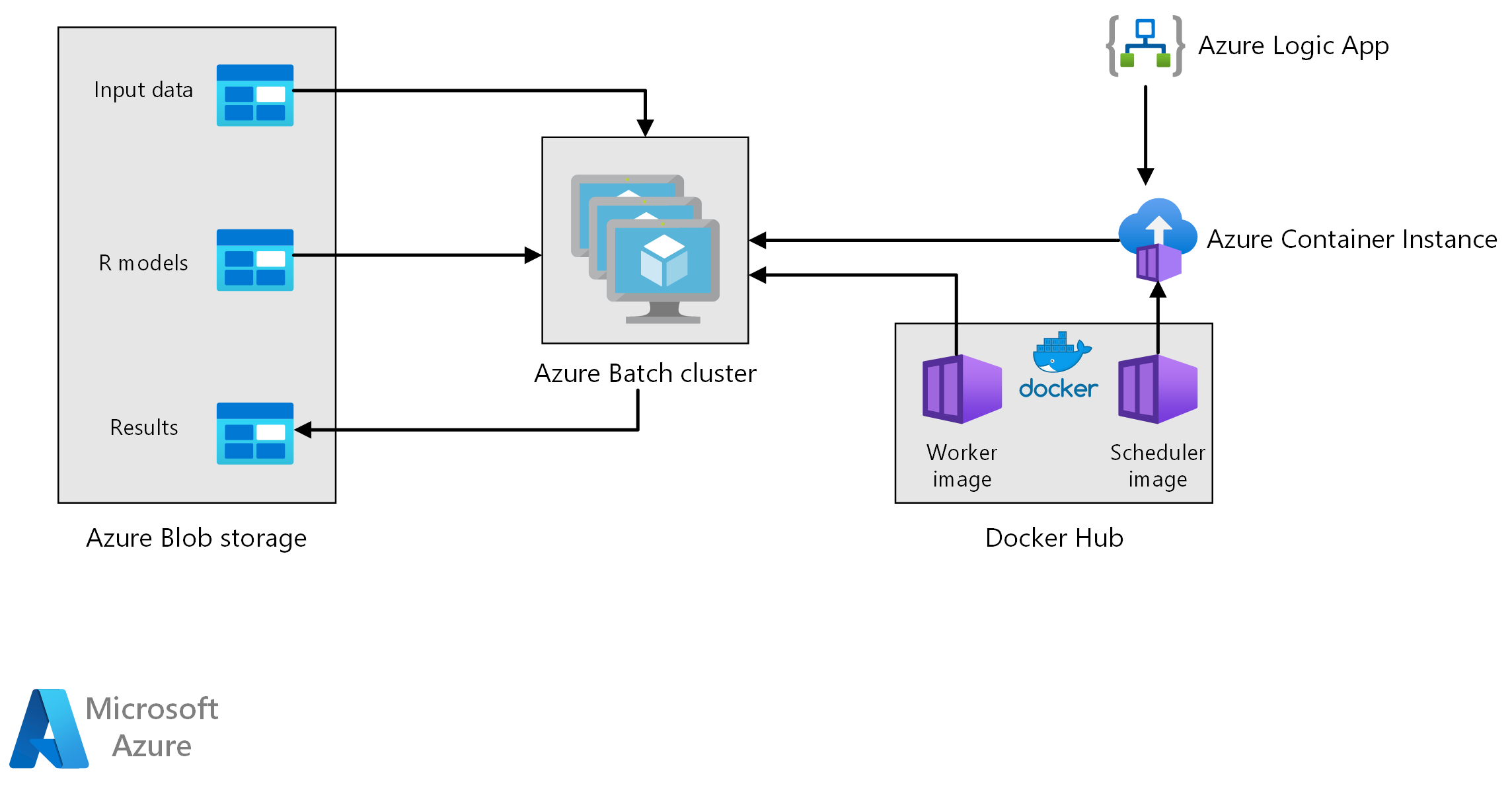
Workflow
This architecture consists of the following components.
Azure Batch runs forecast generation jobs in parallel on a cluster of virtual machines. Predictions are made using pre-trained machine learning models implemented in R. Azure Batch can automatically scale the number of VMs based on the number of jobs submitted to the cluster. On each node, an R script runs within a Docker container to score data and generate forecasts.
Azure Blob Storage stores the input data, the pre-trained machine learning models, and the forecast results. It delivers cost-effective storage for the performance that this workload requires.
Azure Container Instances provides serverless compute on demand. In this case, a container instance is deployed on a schedule to trigger the Batch jobs that generate the forecasts. The Batch jobs are triggered from an R script using the doAzureParallel package. The container instance automatically shuts down once the jobs have finished.
Azure Logic Apps triggers the entire workflow by deploying the container instances on a schedule. An Azure Container Instances connector in Logic Apps allows an instance to be deployed upon a range of trigger events.
Components
Solution details
Although the following scenario is based on retail store sales forecasting, its architecture can be generalized for any scenario requiring the generation of predictions on a larger scale using R models. A reference implementation for this architecture is available on GitHub.
Potential use cases
A supermarket chain needs to forecast sales of products over the upcoming quarter. The forecast allows the company to manage its supply chain better and ensure it can meet demand for products at each of its stores. The company updates its forecasts every week as new sales data from the previous week becomes available and the product marketing strategy for next quarter is set. Quantile forecasts are generated to estimate the uncertainty of the individual sales forecasts.
Processing involves the following steps:
An Azure logic app triggers the forecast generation process once per week.
The logic app starts an Azure Container Instance running the scheduler Docker container, which triggers the scoring jobs on the Batch cluster.
Scoring jobs run in parallel across the nodes of the Batch cluster. Each node:
Pulls the worker Docker image and starts a container.
Reads input data and pre-trained R models from Azure Blob storage.
Scores the data to produce forecasts.
Writes forecast results to blob storage.
The following figure shows the forecasted sales for four products (SKUs) in one store. The black line is the sales history, the dashed line is the median (q50) forecast, the pink band represents the 25th and 75th percentiles, and the blue band represents the 50th and 95th percentiles.

Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Performance
Containerized deployment
With this architecture, all R scripts run within Docker containers. Using containers ensures that the scripts run in a consistent environment every time, with the same R version and packages versions. Separate Docker images are used for the scheduler and worker containers, because each has a different set of R package dependencies.
Azure Container Instances provides a serverless environment to run the scheduler container. The scheduler container runs an R script that triggers the individual scoring jobs running on an Azure Batch cluster.
Each node of the Batch cluster runs the worker container, which executes the scoring script.
Parallelize the workload
When batch scoring data with R models, consider how to parallelize the workload. The input data must be partitioned so that the scoring operation can be distributed across the cluster nodes. Try different approaches to discover the best choice for distributing your workload. On a case-by-case basis, consider:
- How much data can be loaded and processed in the memory of a single node.
- The overhead of starting each batch job.
- The overhead of loading the R models.
In the scenario used for this example, the model objects are large, and it takes only a few seconds to generate a forecast for individual products. For this reason, you can group the products and execute a single Batch job per node. A loop within each job generates forecasts for the products sequentially. This method is the most efficient way to parallelize this particular workload. It avoids the overhead of starting many smaller Batch jobs and repeatedly loading the R models.
An alternative approach is to trigger one Batch job per product. Azure Batch automatically forms a queue of jobs and submits them to be executed on the cluster as nodes become available. Use automatic scaling to adjust the number of nodes in the cluster, depending on the number of jobs. This approach is useful if it takes a relatively long time to complete each scoring operation, which justifies the overhead of starting the jobs and reloading the model objects. This approach is also simpler to implement and gives you the flexibility to use automatic scaling, an important consideration if the size of the total workload isn't known in advance.
Monitor Azure Batch jobs
Monitor and terminate Batch jobs from the Jobs pane of the Batch account in the Azure portal. Monitor the batch cluster, including the state of individual nodes, from the Pools pane.
Log with doAzureParallel
The doAzureParallel package automatically collects logs of all stdout/stderr for every job submitted on Azure Batch. These logs can be found in the storage account created at setup. To view them, use a storage navigation tool such as Azure Storage Explorer or Azure portal.
To quickly debug Batch jobs during development, view the logs in your local R session. For more information, see using the Configure and submit training runs.
Cost optimization
Cost optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
The compute resources used in this reference architecture are the most costly components. For this scenario, a cluster of fixed size is created whenever the job is triggered and then shut down after the job has completed. Cost is incurred only while the cluster nodes are starting, running, or shutting down. This approach is suitable for a scenario where the compute resources required to generate the forecasts remain relatively constant from job to job.
In scenarios where the amount of compute required to complete the job isn't known in advance, it might be more suitable to use automatic scaling. With this approach, the size of the cluster is scaled up or down depending on the size of the job. Azure Batch supports a range of autoscale formulas, which you can set when defining the cluster using the doAzureParallel API.
For some scenarios, the time between jobs might be too short to shut down and start up the cluster. In these cases, keep the cluster running between jobs if appropriate.
Azure Batch and doAzureParallel support the use of low-priority VMs. These VMs come with a significant discount but risk being appropriated by other higher priority workloads. Therefore, the use of low-priority VMs isn't recommended for critical production workloads. However, they're useful for experimental or development workloads.
Deploy this scenario
To deploy this reference architecture, follow the steps described in the GitHub repo.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Angus Taylor | Senior Data Scientist
To see non-public LinkedIn profiles, sign in to LinkedIn.