Datové objekty v Datovém jezeře Databricks
Databricks Lakehouse organizuje data uložená s Delta Lake v cloudovém úložišti objektů se známými relacemi, jako jsou databáze, tabulky a zobrazení. Tento model kombinuje řadu výhod podnikového datového skladu se škálovatelností a flexibilitou datového jezera. Přečtěte si další informace o tom, jak tento model funguje, a vztah mezi daty objektů a metadaty, abyste mohli použít osvědčené postupy při navrhování a implementaci Databricks Lakehouse pro vaši organizaci.
Jaké datové objekty jsou v Datovém jezeře Databricks?
Architektura Databricks Lakehouse kombinuje data uložená s protokolem Delta Lake v cloudovém úložišti objektů s metadaty registrovanými do metastoru. Databricks Lakehouse obsahuje pět primárních objektů:
- Katalog: seskupení databází.
- Databáze nebo schéma: seskupení objektů v katalogu. Databáze obsahují tabulky, zobrazení a funkce.
- Tabulka: kolekce řádků a sloupců uložených jako datové soubory v úložišti objektů.
- Zobrazení: Uložený dotaz obvykle používá jednu nebo více tabulek nebo zdrojů dat.
- Funkce: uložená logika, která vrací skalární hodnotu nebo sadu řádků.
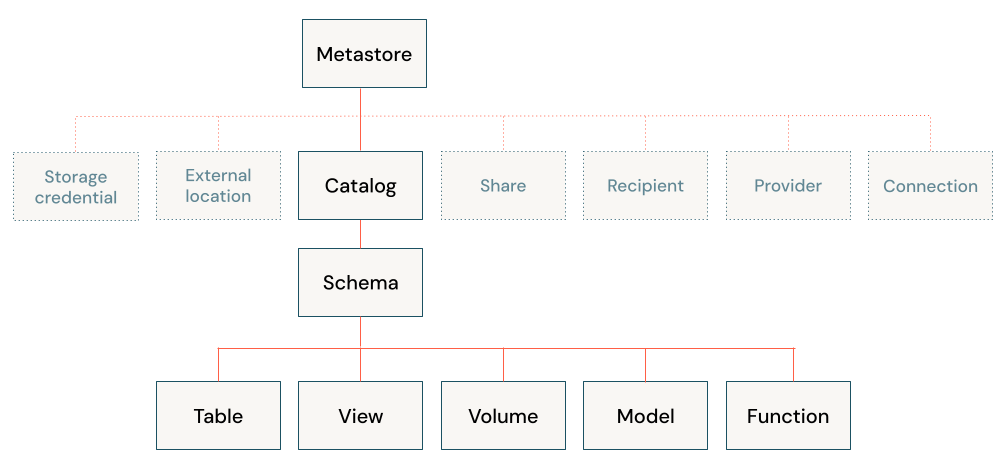
Informace o zabezpečení objektů pomocí katalogu Unity najdete v modelu zabezpečitelných objektů.
Co je metastore?
Metastore obsahuje všechna metadata, která definují datové objekty v jezeře. Azure Databricks nabízí následující možnosti metastoru:
Metastore katalogu Unity: Katalog Unity poskytuje centralizované řízení přístupu, auditování, rodokmen a možnosti zjišťování dat. Metastory katalogu Unity vytvoříte na úrovni účtu Azure Databricks a jeden metastor můžete použít v několika pracovních prostorech.
Každý metastore katalogu Unity je nakonfigurovaný s umístěním kořenového úložiště v kontejneru Azure Data Lake Storage Gen2 ve vašem účtu Azure. Toto umístění úložiště se ve výchozím nastavení používá k ukládání dat pro spravované tabulky.
Data v katalogu Unity jsou ve výchozím nastavení zabezpečená. Uživatelé zpočátku nemají přístup k datům v metastoru. Přístup může udělit správce metastoru nebo vlastník objektu. Zabezpečitelné objekty v katalogu Unity jsou hierarchické a oprávnění se dědí dolů. Katalog Unity nabízí jedno místo pro správu zásad přístupu k datům. Uživatelé mají přístup k datům v katalogu Unity z libovolného pracovního prostoru, ke kterému je metastor připojený. Další informace najdete v tématu Správa oprávnění v katalogu Unity.
Integrovaný metastore Hive (starší verze): Každý pracovní prostor Azure Databricks zahrnuje integrovaný metastor Hive jako spravovanou službu. Instance metastoru se nasadí do každého clusteru a bezpečně přistupuje k metadatům z centrálního úložiště pro každý pracovní prostor zákazníka.
Metastore Hive poskytuje méně centralizovaný model zásad správného řízení dat než Katalog Unity. Cluster ve výchozím nastavení umožňuje všem uživatelům přístup ke všem datům spravovaným integrovaným metastorem Hive pracovního prostoru, pokud pro tento cluster není povolené řízení přístupu k tabulce. Další informace najdete v tématu Řízení přístupu k tabulce metastoru Hive (starší verze).
Řízení přístupu k tabulce se neukládají na úrovni účtu, a proto je nutné je nakonfigurovat samostatně pro každý pracovní prostor. Databricks doporučuje upgradovat tabulky spravované metastorem Hive vašeho pracovního prostoru na metastore katalogu Unity, aby využívala centralizovaný a zjednodušený model zásad správného řízení dat, který poskytuje Katalog Unity.
Externí metastore Hive (starší verze): Do Azure Databricks můžete také přenést vlastní metastor. Clustery Azure Databricks se můžou připojit k existujícím externím metastorům Apache Hive. Ke správě oprávnění v externím metastoru můžete použít řízení přístupu k tabulce. Řízení přístupu k tabulce nejsou uložena v externím metastoru, a proto je nutné je nakonfigurovat zvlášť pro každý pracovní prostor. Databricks doporučuje místo toho používat katalog Unity pro jednoduchost a model zásad správného řízení na střed účtu.
Azure Databricks ukládá všechna data tabulky v úložišti objektů v cloudovém účtu bez ohledu na to, co používáte.
Co je katalog?
Katalog je nejvyšší abstrakce (nebo nejhrubší agregace) v relačním modelu Databricks Lakehouse. Každá databáze bude přidružena ke katalogu. Katalogy existují jako objekty v rámci metastoru.
Před zavedením katalogu Unity použil Azure Databricks dvouvrstvou obor názvů. Katalogy jsou třetí úrovní modelu pro řádkování názvů Unity:
catalog_name.database_name.table_name
Integrovaný metastor Hive podporuje pouze jeden katalog . hive_metastore
Co je databáze?
Databáze je kolekce datových objektů, jako jsou tabulky nebo zobrazení (označované také jako "relace") a funkce. V Azure Databricks se termíny "schéma" a "databáze" používají zaměnitelně (zatímco v mnoha relačních systémech je databáze kolekcí schémat).
Databáze budou vždy přidruženy k umístění v cloudovém úložišti objektů. Volitelně můžete zadat LOCATION při registraci databáze, mějte na paměti, že:
- Přidružené
LOCATIONk databázi se vždy považují za spravované umístění. - Vytvoření databáze nevytvoří žádné soubory v cílovém umístění.
- Databáze
LOCATIONurčí výchozí umístění pro data všech tabulek registrovaných do této databáze. - Úspěšné vyřazení databáze rekurzivně odstraní všechna data a soubory uložené ve spravovaném umístění.
Tato interakce mezi umístěními spravovanými databází a datovými soubory je velmi důležitá. Abyste se vyhnuli náhodnému odstranění dat:
- Nesdílejte umístění databáze napříč několika definicemi databáze.
- Nezaregistrujte databázi do umístění, které již obsahuje data.
- Pokud chcete spravovat životní cyklus dat nezávisle na databázi, uložte data do umístění, které není vnořené do žádného umístění databáze.
Co je tabulka?
Tabulka Azure Databricks je kolekce strukturovaných dat. Tabulka Delta ukládá data jako adresář souborů v cloudovém úložišti objektů a registruje metadata tabulek do metastoru v rámci katalogu a schématu. Protože Delta Lake je výchozím poskytovatelem úložiště pro tabulky vytvořené v Azure Databricks, všechny tabulky vytvořené v Databricks jsou ve výchozím nastavení tabulky Delta. Vzhledem k tomu, že tabulky Delta ukládají data v cloudovém úložišti objektů a poskytují odkazy na data prostřednictvím metastoru, můžou uživatelé v organizaci přistupovat k datům pomocí svých upřednostňovaných rozhraní API; v Databricks to zahrnuje SQL, Python, PySpark, Scala a R.
Všimněte si, že je možné vytvářet tabulky v Databricks, které nejsou tabulkami Delta. Tyto tabulky nejsou podporovány Delta Lake a nebudou poskytovat transakce ACID a optimalizovaný výkon tabulek Delta. Tabulky spadající do této kategorie zahrnují tabulky registrované proti datům v externích systémech a tabulkách registrovaných v jiných formátech souborů v datovém jezeře. Viz Připojení ke zdrojům dat.
Databricks obsahuje dva druhy tabulek, spravované a nespravované (nebo externí) tabulky.
Poznámka:
Rozdíl mezi živými tabulkami delta a streamovanými živými tabulkami se nevynucuje z perspektivy tabulky.
Co je spravovaná tabulka?
Azure Databricks spravuje metadata i data pro spravovanou tabulku; když odstraníte tabulku, odstraníte také podkladová data. Toto chování můžou preferovat datoví analytici a další uživatelé, kteří v SQL většinou pracují. Spravované tabulky jsou při vytváření tabulky výchozí. Data spravované tabulky se nacházejí v LOCATION databázi, do které je zaregistrovaná. Tato spravovaná relace mezi umístěním dat a databází znamená, že pokud chcete přesunout spravovanou tabulku do nové databáze, musíte přepsat všechna data do nového umístění.
Existují různé způsoby vytváření spravovaných tabulek, mezi které patří:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Co je nespravovaná tabulka?
Azure Databricks spravuje pouze metadata pro nespravované (externí) tabulky; když tabulku vypustíte, nemáte vliv na podkladová data. Nespravované tabulky budou vždy určovat LOCATION během vytváření tabulky. Můžete buď zaregistrovat existující adresář datových souborů jako tabulku, nebo zadat cestu při prvním definování tabulky. Vzhledem k tomu, že data a metadata se spravují nezávisle, můžete tabulku přejmenovat nebo zaregistrovat do nové databáze, aniž byste museli přesouvat žádná data. Datoví inženýři často dávají přednost nespravovaným tabulkám a flexibilitě, kterou poskytují pro produkční data.
Existuje řada způsobů, jak vytvořit nespravované tabulky, včetně:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Co je zobrazení?
Zobrazení ukládá text dotazu obvykle pro jeden nebo více zdrojů dat nebo tabulek v metastoru. V Databricks je zobrazení ekvivalentní datovému rámci Sparku, který je trvalý jako objekt v databázi. Na rozdíl od datových rámců můžete dotazovat zobrazení z libovolné části produktu Databricks za předpokladu, že k tomu máte oprávnění. Vytvoření zobrazení nezpracuje ani nezapisuje žádná data; Pouze text dotazu je registrován do metastoru v přidružené databázi.
Co je dočasné zobrazení?
Dočasné zobrazení má omezený rozsah a trvalost a není zaregistrované ve schématu nebo katalogu. Životnost dočasného zobrazení se liší v závislosti na prostředí, které používáte:
- V poznámkových blocích a úlohách jsou dočasná zobrazení vymezená na úroveň poznámkového bloku nebo skriptu. Nelze na nich odkazovat mimo poznámkový blok, ve kterém jsou deklarovány, a již nebudou existovat, když se poznámkový blok oddělí od clusteru.
- V Databricks SQL jsou dočasná zobrazení vymezená na úroveň dotazu. Dočasné zobrazení může použít více příkazů v rámci stejného dotazu, ale nelze na něj odkazovat v jiných dotazech, a to ani v rámci stejného řídicího panelu.
- Globální dočasná zobrazení jsou vymezená na úroveň clusteru a dají se sdílet mezi poznámkovými bloky nebo úlohami, které sdílejí výpočetní prostředky. Databricks doporučuje používat zobrazení s příslušnými seznamy ACL tabulky místo globálních dočasných zobrazení.
Co je funkce?
Funkce umožňují přidružit uživatelsky definovanou logiku k databázi. Funkce můžou vracet skalární hodnoty nebo sady řádků. Funkce slouží k agregaci dat. Azure Databricks umožňuje ukládat funkce v různých jazycích v závislosti na kontextu spuštění, přičemž SQL je široce podporovaný. Funkce můžete použít k poskytování spravovaného přístupu k vlastní logice napříč různými kontexty v produktu Databricks.
Jak fungují relační objekty v rozdílových živých tabulkách?
Delta Live Tables používá deklarativní syntaxi k definování a správě nasazení DDL, DML a infrastruktury. Delta Live Tables používá koncept "virtuálního schématu" během plánování a spouštění logiky. Rozdílové živé tabulky můžou pracovat s jinými databázemi v prostředí Databricks a Delta Live Tables můžou publikovat a uchovávat tabulky pro dotazování jinde zadáním cílové databáze v nastavení konfigurace kanálu.
Všechny tabulky vytvořené v rozdílových živých tabulkách jsou tabulky Delta. Při použití katalogu Unity s delta živými tabulkami jsou všechny tabulky spravované službou Unity Catalog. Pokud není katalog Unity aktivní, je možné tabulky deklarovat jako spravované nebo nespravované tabulky.
I když se zobrazení dají deklarovat v rozdílových živých tabulkách, měly by se považovat za dočasná zobrazení vymezená na kanál. Dočasné tabulky v tabulkách Delta Live Jsou jedinečným konceptem: tyto tabulky uchovávají data v úložišti, ale nepublikují data do cílové databáze.
Některé operace, například APPLY CHANGES INTO, zaregistrují tabulku i zobrazení do databáze. Název tabulky bude začínat podtržítkem (_) a zobrazení bude mít název tabulky deklarovaný jako cíl APPLY CHANGES INTO operace. Zobrazení se dotazuje odpovídající skryté tabulky, aby se výsledky materializovaly.