Federace více lokalit a více oblastí
Řada sofistikovaných řešení vyžaduje, aby byly stejné streamy událostí dostupné pro využití na více místech, nebo vyžadují shromažďování datových proudů událostí na více místech a jejich následnou konsolidaci do konkrétního umístění, aby je bylo možné využít. Často je také potřeba rozšířit nebo omezit streamy událostí nebo provádět převody formátu událostí, a to i v rámci jedné oblasti a řešení.
Prakticky to znamená, že vaše řešení bude udržovat více služeb Event Hubs, často v různých oblastech a oborech názvů služby Event Hubs, a pak mezi nimi replikovat události. Události si také můžete vyměňovat se zdroji a cíli, jako jsou Azure Service Bus, Azure IoT Hub nebo Apache Kafka.
Udržování několika aktivních center událostí v různých oblastech také umožňuje klientům zvolit a přepínat mezi nimi, pokud se jejich obsah slučuje, což celkový systém zlepšuje odolnost proti problémům s dostupností v jednotlivých oblastech.
Tato kapitola "Federace" vysvětluje vzory federace a vysvětluje, jak tyto vzory realizovat pomocí bezserverové služby Azure Stream Analytics nebo Azure Functions modulů runtime s možností mít vlastní kód transformace nebo rozšiřování přímo v cestě toku událostí.
Vzory federace
Existuje mnoho potenciálních motivací, proč byste mohli chtít přesouvat události mezi různými službami Event Hubs nebo jinými zdroji a cíli. V této části najdete výčet nejdůležitějších vzorů a také odkaz na podrobnější pokyny pro příslušný vzor.
- Odolnost proti událostem dostupnosti v jednotlivých oblastech
- Optimalizace latence
- Ověřování, redukce a rozšiřování
- Integrace s analytickými službami
- Konsolidace a normalizace datových proudů událostí
- Rozdělení a směrování datových proudů událostí
- Projekce protokolů
Odolnost proti událostem dostupnosti v jednotlivých oblastech
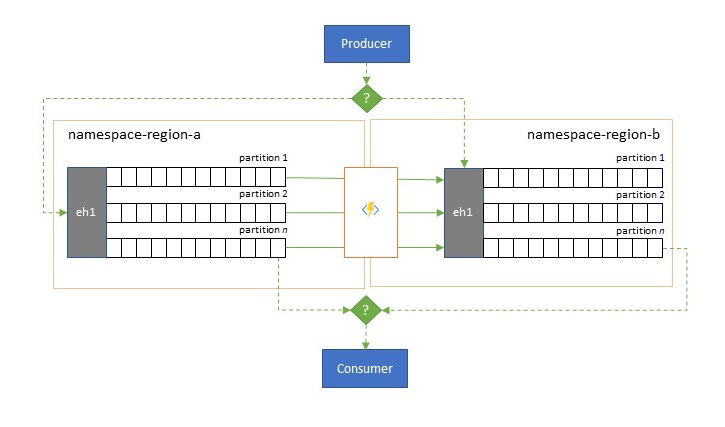
I když je maximální dostupnost a spolehlivost hlavní provozní prioritou služby Event Hubs, existuje mnoho způsobů, jak může být producenti nebo příjemci zabráněno v komunikaci se svou přiřazenou "primární" službou Event Hubs kvůli problémům se sítí nebo překladem názvů nebo v případech, kdy služba Event Hubs skutečně dočasně nereaguje nebo vrací chyby.
Takové podmínky nejsou "katastrofické", proto byste chtěli úplně opustit regionální nasazení, jako je tomu v případě zotavení po havárii , ale obchodní scénář některých aplikací už může být ovlivněn událostmi dostupnosti, které netrvají déle než několik minut nebo i sekund.
Existují dva základní vzory pro řešení takových scénářů:
- Vzor replikace spočívá v replikaci obsahu primární služby Event Hubs do sekundární služby Event Hubs, přičemž primární službu Event Hubs aplikace obecně používá k vytváření i využívání událostí a sekundární služba slouží jako záložní možnost pro případ, že primární služba Event Hubs začíná být nedostupná. Vzhledem k tomu, že replikace je jednosměrná, z primárního na sekundární, přepnutí producentů i příjemců z nedostupného primárního na sekundární způsobí, že starý primární server přestane přijímat nové události, a proto už nebude aktuální. Čistá replikace je proto vhodná pouze pro scénáře jednosměrného převzetí služeb při selhání. Po převzetí služeb při selhání se původní primární server opustí a je potřeba vytvořit novou sekundární službu Event Hubs v jiné cílové oblasti.
- Model sloučení rozšiřuje model replikace tím, že provádí průběžné slučování obsahu dvou nebo více center událostí. Každá událost původně vygenerovaná do jednoho ze služeb Event Hubs, které jsou součástí schématu, se replikuje do jiné služby Event Hubs. Při replikaci se události anotují tak, že se následně ignorují procesem replikace cíle replikace. Výsledkem použití vzoru sloučení jsou dvě nebo více služeb Event Hubs, která budou obsahovat stejnou sadu událostí v konečném důsledku konzistentním způsobem.
V obou případech nebude obsah služby Event Hubs identický. Události od libovolného producenta seskupené podle stejného klíče oddílu se zobrazí ve stejném relativním pořadí jako původně odeslané, ale absolutní pořadí událostí se může lišit. To platí zejména pro scénáře, kde se liší počet oddílů zdrojového a cílového centra událostí, což je žádoucí pro několik zde popsaných rozšířených vzorů. Rozdělovač nebo směrovač může získat řez mnohem větší služby Event Hubs se stovkami oddílů a trychtýřovým trychtýřem do menší služby Event Hubs s několika málo oddíly, což je vhodnější pro zpracování podmnožina s omezenými prostředky zpracování. Konsolidace může naopak trychtýřovat data z několika menších center událostí do jednoho většího event hubs s více oddíly, aby se vyrovnala s konsolidovanými požadavky na propustnost a zpracování.
Kritériem pro zachování událostí pohromadě je klíč oddílu, nikoli původní ID oddílu. Další důležité informace o relativním pořadí a o tom, jak provést převzetí služeb při selhání z jednoho centra událostí do dalšího, aniž byste museli spoléhat na stejný rozsah posunů datových proudů, jsou popsány v popisu modelu replikace .
Pokyny:
Optimalizace latence
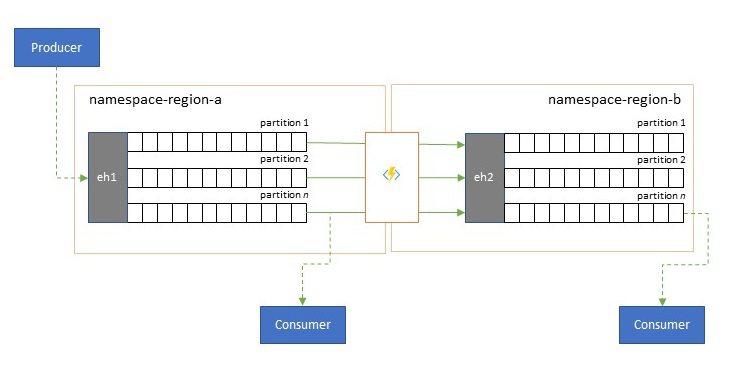
Streamy událostí zapisují producenti jednou, ale příjemci událostí je můžou číst kolikrát. Ve scénářích, kdy stream událostí v oblasti sdílí více příjemců a musí se k němu opakovaně přistupovat během zpracování analýz umístěných v jiné oblasti nebo s požadavky, které by vyhladověly souběžné příjemce, může být výhodné umístit kopii streamu událostí poblíž analytického procesoru, aby se snížila latence odezvy.
Dobrým příkladem toho, kdy by replikace měla být upřednostněna před vzdáleným využíváním událostí z různých oblastí, jsou zejména ty, kde jsou oblasti extrémně vzdálené, například Evropa a Austrálie jsou téměř antipody, geograficky a latence sítě může při jakékoli době odezvy snadno překročit 250 ms. Nemůžete zrychlit rychlost světla, ale můžete snížit počet odezvy s vysokou latencí při interakci s daty.
Pokyny:
Ověřování, redukce a rozšiřování
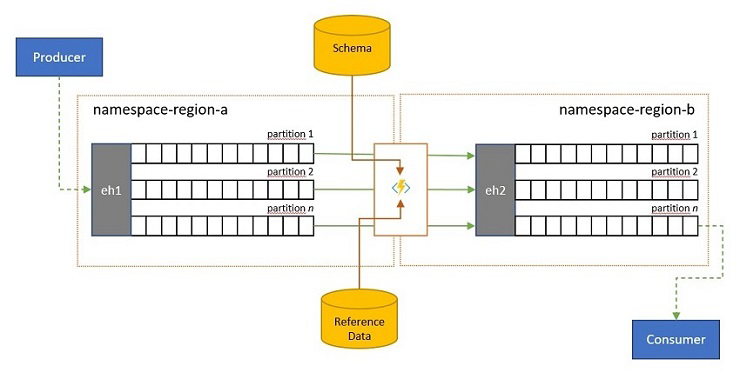
Streamy událostí můžou do služby Event Hubs odesílat klienti mimo vaše vlastní řešení. Takové streamy událostí mohou vyžadovat, aby externě odeslané události byly kontrolovány z důvodu dodržování předpisů s daným schématem a nekompatibilních událostí byly vyřazeny.
Ve scénářích, kdy jsou klienti extrémně omezeni šířkou pásma, jako je tomu v mnoha scénářích internetu věcí s měřenou šířkou pásma, nebo kdy se události původně odesílají přes jiné sítě než IP s omezenou velikostí paketů, může být nutné události rozšířit o referenční data, aby se přidal další kontext pro použití podřízenými procesory událostí.
V jiných případech, zejména při slučování datových proudů, může být nutné zmenšit složitost nebo velikost dat událostí vynecháním některých podrobností.
Kterákoli z těchto operací může probíhat jako součást toků replikace, konsolidace nebo sloučení.
Pokyny:
Integrace s analytickými službami
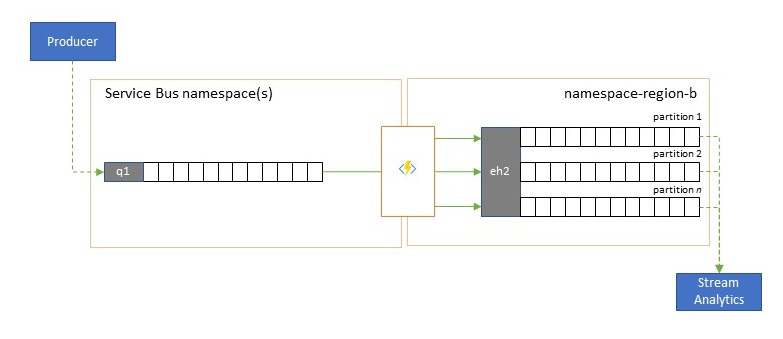
Několik analytických služeb Azure nativních pro cloud, jako je Azure Stream Analytics nebo Azure Synapse nejlépe funguje se streamovanými nebo předem dávkovanými daty servírovanými z Azure Event Hubs a Azure Event Hubs také umožňuje integraci s několika opensourcovými analytickými balíčky, jako jsou Apache Samza, Apache Flink, Apache Spark a Apache Storm.
Pokud vaše řešení primárně využívá Službu Service Bus nebo Event Grid, můžete tyto události snadno zpřístupnit těmto analytickým systémům a také k archivaci pomocí funkce Event Hubs Capture, pokud je do služby Event Hubs vložíte. Event Grid to může udělat nativně se svou integrací služby Event Hubs. V případě služby Service Bus postupujte podle pokynů k replikaci služby Service Bus.
Azure Stream Analytics se integruje přímo se službou Event Hubs.
Pokyny:
Konsolidace a normalizace datových proudů událostí
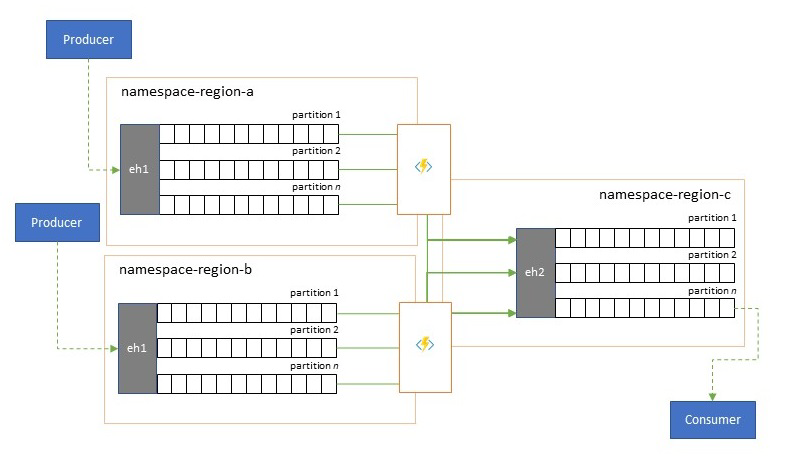
Globální řešení se často skládají z regionální stopy, která jsou do značné míry nezávislá, včetně vlastních analytických možností, ale nadregionální a globální analytické perspektivy budou vyžadovat integrovanou perspektivu, a proto centrální konsolidaci stejných toků událostí, které se vyhodnocují v příslušných regionálních stopách pro místní perspektivu.
Normalizace je příchuť scénáře konsolidace, kdy dva nebo více příchozích datových proudů událostí nesou stejný druh událostí, ale s různými strukturami nebo odlišnými kódováními, a události, které se před použitím nejčastěji překódují nebo transformují.
Normalizace může také zahrnovat kryptografickou práci, jako je dešifrování komplexních šifrovaných datových částí a jejich opětovné zašifrování pomocí různých klíčů a algoritmů pro cílovou skupinu podřízených příjemců.
Pokyny:
Rozdělení a směrování datových proudů událostí
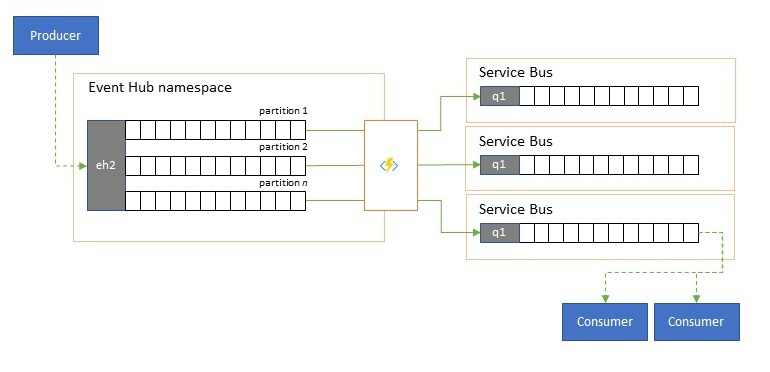
Azure Event Hubs se příležitostně používá ve scénářích ve stylu publikování a odběru, kde příchozí příval přijatých událostí výrazně překračuje kapacitu Azure Service Bus nebo Azure Event Grid. Obě tyto možnosti mají nativní možnosti filtrování a distribuce publikování a odběru a jsou pro tento model preferované.
I když skutečná funkce publikování a odběru nechává na odběratelích, aby si vybrali události, které chtějí, model rozdělení namapuje události producenta na oddíly předem určeným distribučním modelem a určení příjemci pak budou stahovat výhradně ze svého oddílu. Když služba Event Hubs ukládá celkový provoz do vyrovnávací paměti, obsah konkrétního oddílu, který představuje zlomek původního objemu propustnosti, se pak může replikovat do fronty pro spolehlivou, transakční a konkurující si spotřebu uživatelů.
V mnoha scénářích, kdy se služba Event Hubs primárně používá k přesunu událostí v rámci aplikace v rámci oblasti, se v některých případech musí vybrat události, třeba jen z jednoho oddílu, zpřístupnit i jinde. Tento scénář se podobá scénáři rozdělení, ale může použít škálovatelný směrovač, který bere v úvahu všechny zprávy přicházející do služby Event Hubs a vybere jen několik z těchto zpráv pro další směrování a může odlišit cíle směrování podle metadat událostí nebo obsahu.
Pokyny:
Projekce protokolů
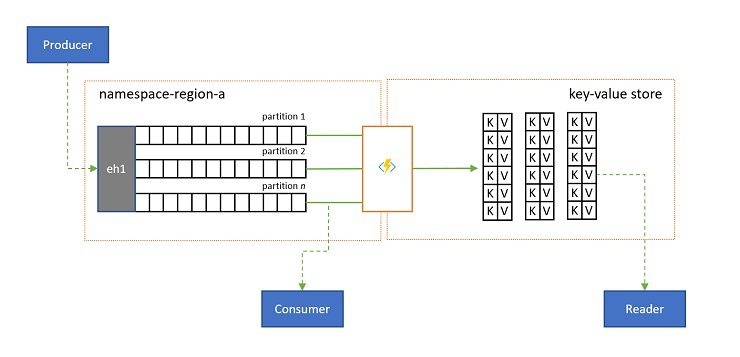
V některých scénářích budete chtít mít přístup k nejnovější hodnotě odesílané pro jakýkoli podstream události a běžně se rozlišují podle klíče oddílu. V Apache Kafka se toho často dosahuje povolením komprimace protokolů v tématu, která zahodí všechny události kromě nejnovější události označené libovolným jedinečným klíčem. Přístup ke komprimování protokolů má tři složené nevýhody:
- Komprimace vyžaduje průběžnou reorganizaci protokolu, což je pro zprostředkovatele, který je optimalizovaný pro úlohy pouze připojení, příliš nákladná operace.
- Komprimace je destruktivní a neumožňuje zkomprimovat a nezkomprimovat perspektivu stejného proudu.
- Zkomprimovaný datový proud má stále model sekvenčního přístupu, což znamená, že vyhledání požadované hodnoty v protokolu vyžaduje čtení celého protokolu v nejhorším případě, což obvykle vede k optimalizacím, které implementují přesný zde uvedený vzor: promítání obsahu protokolu do databáze nebo mezipaměti.
V konečném důsledku je komprimovaný protokol úložištěm klíč-hodnota, a proto se jedná o nejhorší možnou možnost implementace pro takové úložiště. Pro vyhledávání a dotazy je mnohem efektivnější vytvořit a použít trvalou projekci protokolu do správného úložiště klíč-hodnota nebo do jiné databáze.
Vzhledem k tomu, že události jsou neměnné a pořadí se v protokolu vždy zachová, bude jakákoli projekce protokolu do úložiště klíč-hodnota vždy stejná pro stejný rozsah událostí, což znamená, že projekce, kterou aktualizujete, vždy poskytuje autoritativní zobrazení a po sestavení není nikdy žádný dobrý důvod k jejímu opětovnému sestavení z obsahu protokolu.
Pokyny:
Technologie replikace aplikací
Implementace výše uvedených vzorů vyžaduje škálovatelné a spolehlivé spouštěcí prostředí pro úlohy replikace, které chcete nakonfigurovat a spustit. V Azure jsou pro tyto úlohy nejvhodnější bezstavová prostředí Azure Stream Analytics pro úlohy replikace stavového datového proudu a Azure Functions pro úlohy bezstavové replikace.
Aplikace stavové replikace v Azure Stream Analytics
Pro aplikace stavové replikace, které potřebují brát v úvahu vztahy mezi událostmi, vytvářet složené události, rozšiřovat události nebo omezovat události, vytvářet agregace dat a transformovat datové části událostí, je nejlepší možností implementace Azure Stream Analytics .
V Azure Stream Analytics vytváříte úlohy , které integrují vstupy a výstupy a integrují data ze vstupů prostřednictvím dotazů , které poskytují výsledek, který se pak zpřístupní ve výstupech.
Dotazy jsou založené na dotazovacím jazyce SQL a dají se použít ke snadnému filtrování, řazení, agregaci a spojování streamovaných dat během časového období. Tento jazyk SQL můžete také rozšířit o uživatelem definované funkce jazykaJavaScript a C#. Možnosti řazení událostí a dobu trvání časových intervalů při provádění agregačních operací můžete snadno upravit pomocí jednoduchých jazykových konstruktorů nebo konfigurací.
Každá úloha má jeden nebo několik výstupů pro transformovaná data a můžete řídit, co se stane v reakci na informace, které jste analyzovali. Můžete například:
- Odesílat data do služeb, jako jsou Azure Functions, témata služby Service Bus nebo fronty, aby se aktivovala komunikace nebo vlastní podřízené pracovní postupy.
- Odesílání dat na řídicí panel Power BI pro řídicí panely v reálném čase
- Ukládejte data v jiných službách úložiště Azure (například Azure Data Lake, Azure Synapse Analytics atd.), abyste mohli provádět dávkové analýzy nebo trénovat modely strojového učení založené na velmi velkých indexovaných fondech historických dat.
- Ukládejte projekce (označované také jako materializovaná zobrazení) v databázích (SQL Database, Azure Cosmos DB).
Aplikace bezstavové replikace v Azure Functions
Pro úlohy bezstavové replikace, kde chcete předávat události bez zvážení jejich datových částí nebo je jednotlivě zpracovává, aniž byste museli brát v úvahu vztahy událostí (s výjimkou jejich relativního pořadí), můžete použít Azure Functions, který poskytuje obrovskou flexibilitu.
Azure Functions má předem připravené škálovatelné aktivační události a výstupní vazby pro Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid a Azure Queue Storage a také vlastní rozšíření pro RabbitMQ a Apache Kafka. Většina aktivačních událostí se dynamicky přizpůsobí potřebám propustnosti škálováním počtu souběžně spouštěných instancí nahoru a dolů na základě zdokumentovaných metrik.
Pro vytváření projekcí protokolů Azure Functions podporuje výstupní vazby pro Azure Cosmos DB a Azure Table Storage.
Azure Functions může běžet pod spravovanou identitou Azure, a díky tomu může uchovávat hodnoty konfigurace přihlašovacích údajů v úzce řízeném úložišti v rámci Azure Key Vault.
Azure Functions navíc umožňuje přímou integraci úloh replikace s virtuálními sítěmi a koncovými body služby Azure pro všechny služby zasílání zpráv Azure a snadno se integruje se službou Azure Monitor.
S plánem Azure Functions Consumption se můžou předem vytvořené aktivační události dokonce vertikálně snížit na nulu, zatímco nejsou k dispozici žádné zprávy pro replikaci, což znamená, že se vám za udržování konfigurace připravené na vertikální navýšení kapacity neúčtují žádné náklady. Klíčovou nevýhodou použití plánu Consumption je, že latence úloh replikace, které se "probouzí" z tohoto stavu, je výrazně vyšší než u plánů hostování, ve kterých je infrastruktura stále spuštěná.
Na rozdíl od toho všeho většina běžných replikačních modulů pro zasílání zpráv a událostí, jako je mirrormaker apache kafka, vyžaduje, abyste sami poskytli hostitelské prostředí a škálovali replikační modul. To zahrnuje konfiguraci a integraci funkcí zabezpečení a sítě a usnadnění toku dat monitorování, takže stále nemáte možnost vkládat do toku vlastní úlohy replikace.
Volba mezi Azure Functions a Azure Stream Analytics
Azure Stream Analytics (ASA) je nejlepší volbou, kdykoli potřebujete zpracovávat datovou část událostí při jejich replikaci. ASA může kopírovat události jednu po druhé nebo může vytvářet agregace, které před předáním zkondenzují informace datových proudů událostí. Může se snadno opřít o doplnění referenčních dat uložených v Azure Blob Storage nebo Azure SQL Database, aniž by tato data musela importovat do datového proudu.
S ASA můžete snadno vytvářet trvalá materializovaná zobrazení datových proudů v databázích s hyperškálovým škálováním. Je to mnohem lepší přístup k nepřehlednému modelu "komprimace protokolů" Apache Kafka a nestálým projekcím tabulek na straně klienta streamů Kafka.
ASA dokáže snadno zpracovávat události s datovými částmi kódovanými ve formátech CSV, JSON a Apache Avro a můžete připojit vlastní deserializéry pro jakýkoli jiný formát.
Pro všechny úlohy replikace, ve kterých chcete kopírovat streamy událostí "tak, jak jsou" a bez zásahu do datových částí, nebo pokud potřebujete implementovat směrovač, provést kryptografickou práci, změnit kódování datových částí nebo pokud jinak potřebujete úplnou kontrolu nad obsahem datového streamu, je nejlepší volbou Azure Functions.
Další kroky
V tomto článku jsme prozkoumali řadu vzorů federace a vysvětlili roli Azure Functions jako modulu runtime replikace událostí a zasílání zpráv v Azure.
Dále si můžete přečíst, jak nastavit aplikaci replikátoru pomocí Azure Stream Analytics nebo Azure Functions a jak replikovat toky událostí mezi službou Event Hubs a různými dalšími systémy pro vytváření událostí a zasílání zpráv: