Použití externích úložišť metadat v Azure HDInsightu
Důležité
Výchozí metastore poskytuje azure SQL Database úrovně Basic s pouze 5 DTU a maximální velikostí 2 GB dat (NEUPGRADOVATELNÉ).! Používejte ho pouze pro účely kontroly kvality a testování. V případě produkčních nebo rozsáhlých úloh doporučujeme migrovat na externí metastore!
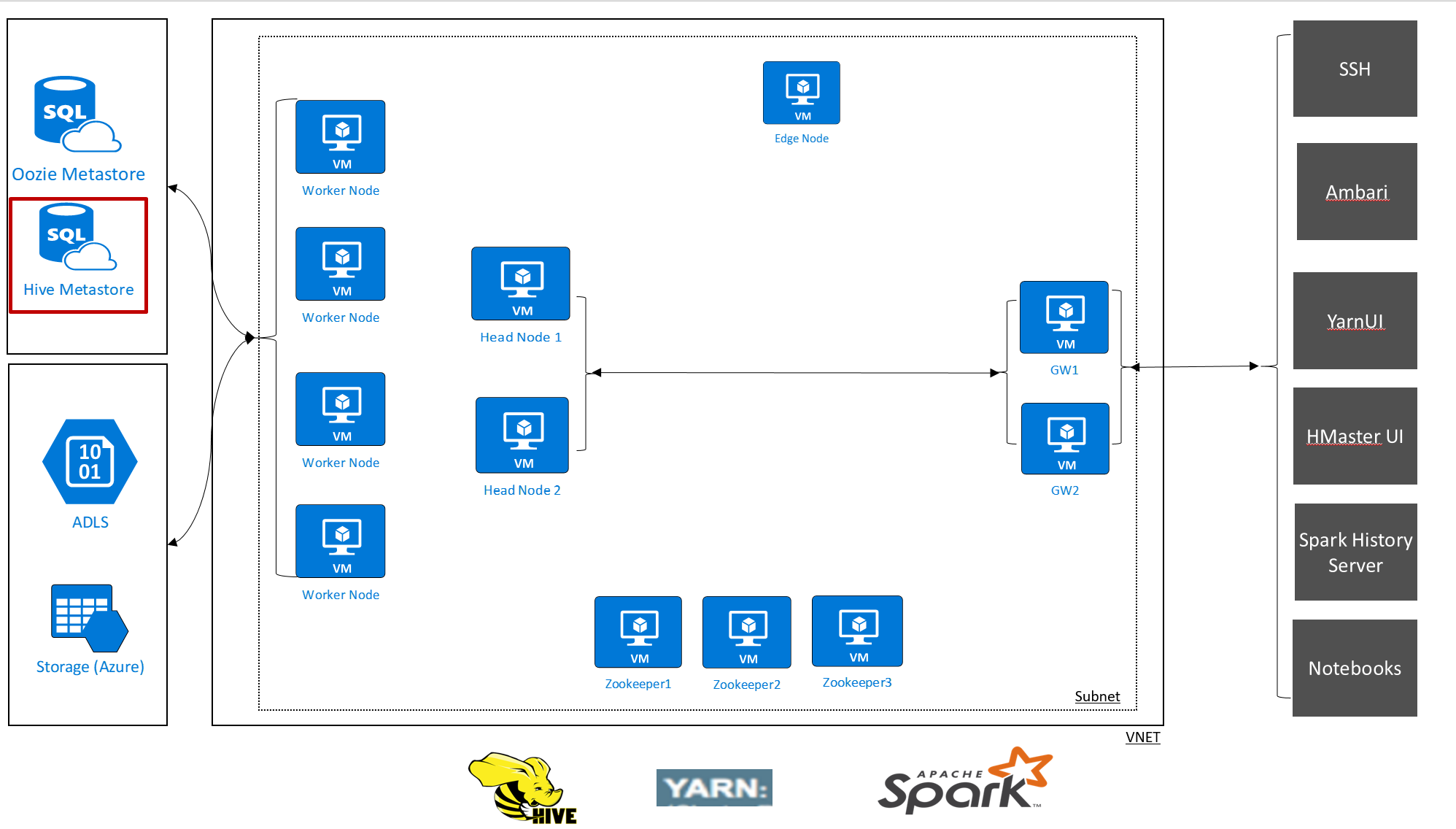
HDInsight umožňuje převzít kontrolu nad daty a metadaty s externími úložišti dat. Tato funkce je dostupná pro metastor Apache Hive, metastore Apache Oozie a databázi Apache Ambari.
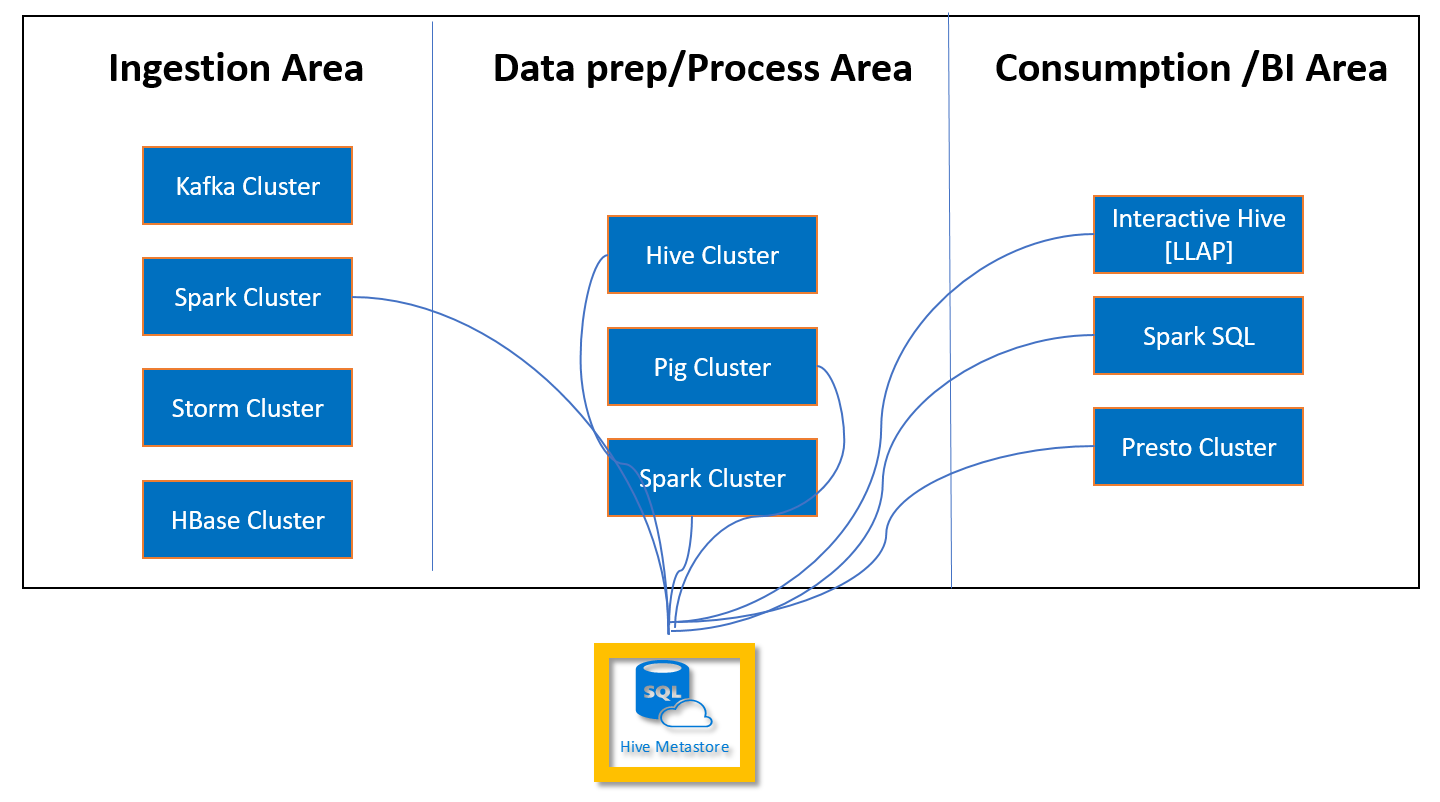
Metastore Apache Hive ve službě HDInsight je základní součástí architektury Apache Hadoop. Metastore je centrální úložiště schémat. Metastor se používá jinými nástroji pro přístup k velkým objemům dat, jako jsou Apache Spark, Interactive Query (LLAP), Presto nebo Apache Pig. HDInsight používá jako metastore Hive službu Azure SQL Database.
Metastore pro clustery HDInsight můžete nastavit dvěma způsoby:
Výchozí metastore
Ve výchozím nastavení služba HDInsight vytvoří metastore s každým typem clusteru. Místo toho můžete zadat vlastní metastore. Výchozí metastore zahrnuje následující aspekty:
Omezené prostředky. Podívejte se na oznámení v horní části stránky.
Žádné další náklady. HDInsight vytvoří metastore s každým typem clusteru bez jakýchkoli dalších nákladů.
Výchozí metastore je součástí životního cyklu clusteru. Když odstraníte cluster, odstraní se také odpovídající metastor a metadata.
Výchozí metastore se doporučuje jenom pro jednoduché úlohy. Úlohy, které nevyžadují více clusterů a nepotřebují metadata zachovaná mimo životní cyklus clusteru.
Výchozí metastor nejde sdílet s jinými clustery.
Vlastní metastore
HDInsight také podporuje vlastní metastory, které se doporučují pro produkční clustery:
Jako metastore zadáte vlastní službu Azure SQL Database .
Životní cyklus metastoru není vázán na životní cyklus clusterů, takže můžete vytvářet a odstraňovat clustery bez ztráty metadat. Metadata, jako jsou vaše schémata Hive, se zachovají i po odstranění a opětovném vytvoření clusteru HDInsight.
Vlastní metastore umožňuje připojit k tomuto metastoru více clusterů a typů clusterů. Jeden metastor lze například sdílet mezi clustery Interactive Query, Hive a Spark v HDInsight.
Platíte za náklady na metastore (Azure SQL Database) podle vámi zvolené úrovně výkonu.
Podle potřeby můžete vertikálně navýšit kapacitu metastoru.
Cluster a externí metastore musí být hostované ve stejné oblasti.
Vytvoření a konfigurace služby Azure SQL Database pro vlastní metastore
Vytvoření nebo vytvoření existující služby Azure SQL Database před nastavením vlastního metastoru Hive pro cluster HDInsight Další informace najdete v tématu Rychlý start: Vytvoření izolované databáze ve službě Azure SQL Database.
Při vytváření clusteru se služba HDInsight musí připojit k externímu metastoru a ověřit přihlašovací údaje. Nakonfigurujte pravidla brány firewall služby Azure SQL Database tak, aby umožňovala službám a prostředkům Azure přístup k serveru. Tuto možnost povolte na webu Azure Portal výběrem možnosti Nastavit bránu firewall serveru. Potom vyberte Možnost Ne pod odepřením přístupu k veřejné síti a ano pod položkou Povolit službám a prostředkům Azure přístup k tomuto serveru pro Azure SQL Database. Další informace najdete v tématu Vytvoření a správa pravidel firewallu protokolu IP.
Privátní koncové body pro úložiště SQL se podporují jenom v clusterech vytvořených pomocí outbound ResourceProvideru Připojení ion. Další informace najdete v této dokumentaci.


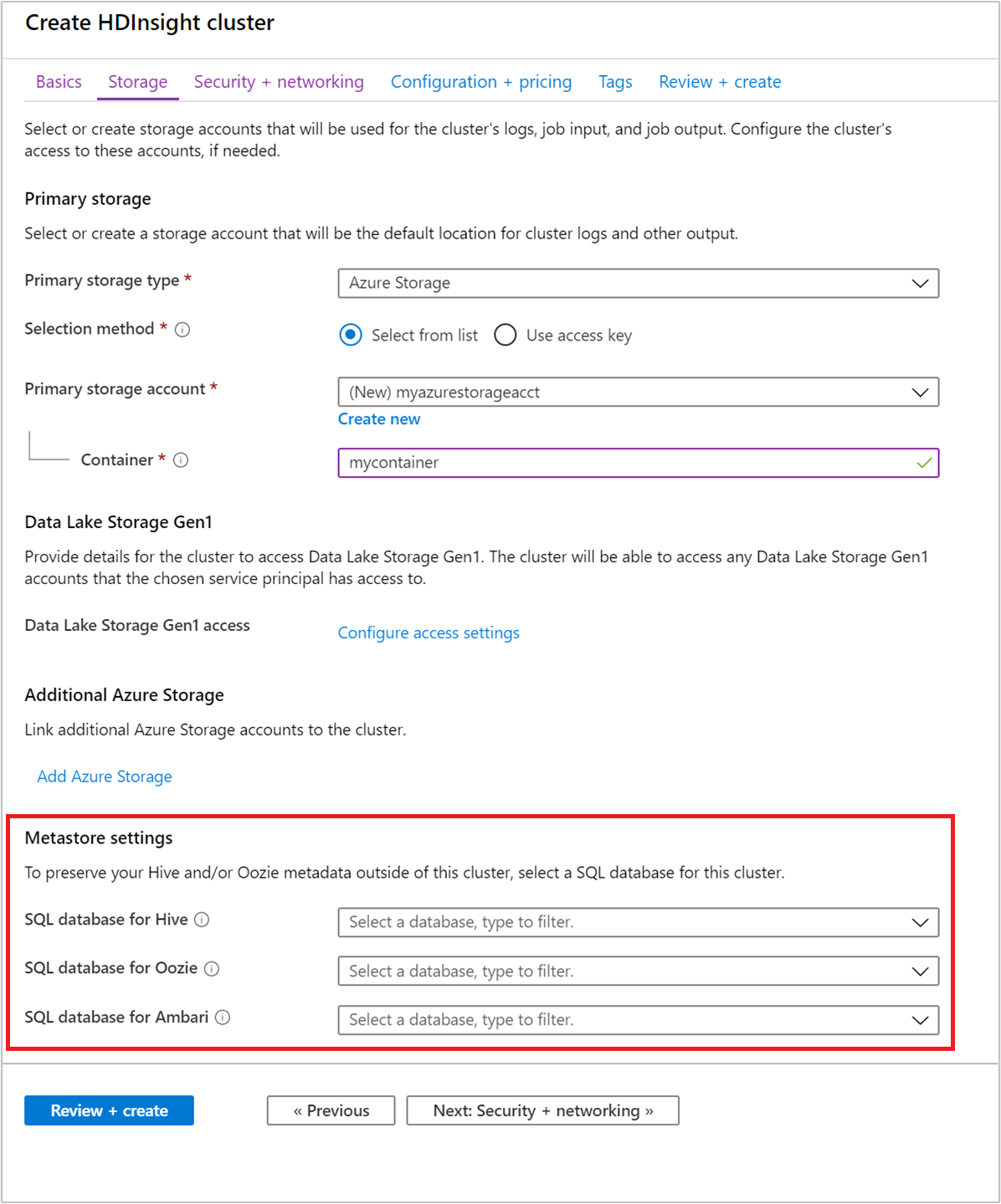
Výběr vlastního metastoru během vytváření clusteru
Cluster můžete kdykoli nasměrovat na dříve vytvořenou službu Azure SQL Database. Pro vytvoření clusteru prostřednictvím portálu se možnost zadává z nastavení metastoru úložiště>.
Pokyny k metastoru Apache Hive
Poznámka:
Pokud je to možné, použijte vlastní metastor, který pomáhá oddělit výpočetní prostředky (spuštěný cluster) a metadata (uložená v metastoru). Začněte vrstvou S2, která poskytuje 50 DTU a 250 GB úložiště. Pokud se zobrazí kritický bod, můžete vertikálně navýšit kapacitu databáze.
Pokud máte v úmyslu získat přístup k samostatným datům více clusterů HDInsight, použijte pro každý cluster samostatnou databázi metastoru. Pokud sdílíte metastor napříč několika clustery HDInsight, znamená to, že clustery používají stejná metadata a podkladové soubory uživatelských dat.
Vlastní metastore pravidelně zálohujte. Azure SQL Database generuje zálohy automaticky, ale časový rámec uchovávání záloh se liší. Další informace naleznete v tématu Další informace týkající se automatické zálohy databáze SQL.
Vyhledejte metastore a cluster HDInsight ve stejné oblasti. Tato konfigurace zajistí nejvyšší výkon a nejnižší poplatky za výchozí přenos dat sítě.
Monitorování výkonu a dostupnosti metastoru pomocí monitorovacích nástrojů služby Azure SQL Database nebo protokolů služby Azure Monitor
Když se vytvoří nová, vyšší verze Azure HDInsight pro existující vlastní databázi metastoru, systém upgraduje schéma metastoru. Upgrade je nevratný bez obnovení databáze ze zálohy.
Pokud sdílíte metastor napříč několika clustery, ujistěte se, že všechny clustery jsou stejné verze HDInsight. Různé verze Hive používají různá schémata databáze metastoru. Například nemůžete sdílet metastor napříč clustery Hive 2.1 a Hive 3.1 verze.
Ve službě HDInsight 4.0 spark a Hive používají nezávislé katalogy pro přístup k tabulkám SparkSQL nebo Hive. Tabulka vytvořená Sparkem se nachází v katalogu Spark. Tabulka vytvořená Hivem žije v katalogu Hive. Toto chování se liší od HDInsight 3.6, kde Hive a Spark sdílely společný katalog. Integrace Hivu a Sparku ve službě HDInsight 4.0 závisí na Připojení oru Hive Warehouse (HWC). HWC funguje jako most mezi Sparkem a Hivem. Přečtěte si o Připojení oru služby Hive Warehouse.
Pokud chcete v HDInsight 4.0 sdílet metastor mezi Hivem a Sparkem, můžete to udělat tak, že změníte metastore.catalog.default na Hive v clusteru Spark. Tuto vlastnost najdete v Ambari Advanced spark2-hive-site-override. Je důležité si uvědomit, že sdílení metastoru funguje jenom u externích tabulek Hive, nebude to fungovat, pokud máte interní/spravované tabulky Hive nebo tabulky ACID.
Aktualizace vlastního hesla metastoru Hive
Při použití vlastní databáze metastoru Hive máte možnost změnit heslo databáze SQL. Pokud změníte heslo pro vlastní metastore, nebudou služby Hive fungovat, dokud neaktualizujete heslo v clusteru HDInsight.
Aktualizace hesla metastoru Hive:
- Otevřete uživatelské rozhraní Ambari.
- Klikněte na Services --> Hive --> Configs --> Database.
- Aktualizujte pole Heslo databáze na nové heslo databáze SQL Serveru.
- Klikněte na tlačítko Test Připojení ion a ujistěte se, že nové heslo funguje.
- Klikněte na tlačítko Uložit.
- Podle pokynů Ambari uložte konfiguraci a restartujte požadované služby.
Metastore Apache Oozie
Apache Oozie je systém koordinace pracovních postupů, který spravuje úlohy platformy Hadoop. Oozie podporuje úlohy Hadoopu pro Apache MapReduce, Pig, Hive a další. Oozie používá metastor k ukládání podrobností o pracovních postupech. Pokud chcete zvýšit výkon při použití Oozie, můžete službu Azure SQL Database použít jako vlastní metastore. Metastor poskytuje přístup k datům úlohy Oozie po odstranění clusteru.
Pokyny k vytvoření metastoru Oozie s Azure SQL Database najdete v tématu Použití Apache Oozie pro pracovní postupy.
Aktualizace vlastního hesla metastoru Oozie
Při použití vlastní databáze metastoru Oozie máte možnost změnit heslo databáze SQL. Pokud změníte heslo pro vlastní metastore, nebudou služby Oozie fungovat, dokud neaktualizujete heslo v clusteru HDInsight.
Aktualizace hesla metastoru Oozie:
- Otevřete uživatelské rozhraní Ambari.
- Click Services --> Oozie --> Configs --> Database.
- Aktualizujte pole Heslo databáze na nové heslo databáze SQL Serveru.
- Klikněte na tlačítko Test Připojení ion a ujistěte se, že nové heslo funguje.
- Klikněte na tlačítko Uložit.
- Podle pokynů Ambari uložte konfiguraci a restartujte požadované služby.
Vlastní Ambari DB
Pokud chcete použít vlastní externí databázi s Apache Ambari ve službě HDInsight, přečtěte si téma Vlastní databáze Apache Ambari.