Přehled služby Azure Storage ve službě HDInsight
Azure Storage je robustní řešení úložiště pro obecné účely, které se bezproblémově integruje se službou HDInsight. HDInsight může jako výchozí systém souborů pro cluster používat kontejner objektů blob ve službě Azure Storage. Prostřednictvím rozhraní HDFS může úplná sada komponent v HDInsight pracovat přímo se strukturovanými nebo nestrukturovanými daty uloženými jako objekty blob.
Pro výchozí úložiště clusteru a obchodní data doporučujeme používat samostatné kontejnery úložiště. Oddělení spočívá v izolaci protokolů HDInsight a dočasných souborů od vlastních obchodních dat. Doporučujeme také po každém použití odstranit výchozí kontejner objektů blob, který obsahuje protokoly aplikací a systémů, aby se snížily náklady na úložiště. Než odstraníte kontejner, nezapomeňte tyto protokoly načíst.
Pokud se rozhodnete zabezpečit účet úložiště pomocí omezení brány firewall a virtuálních sítí ve vybraných sítích, nezapomeňte povolit výjimku Povolit důvěryhodné služby Microsoft.... Výjimkou je, aby služba HDInsight přistupovala k vašemu účtu úložiště.
Architektura úložiště HDInsight
Následující diagram poskytuje abstraktní zobrazení architektury HDInsight služby Azure Storage:
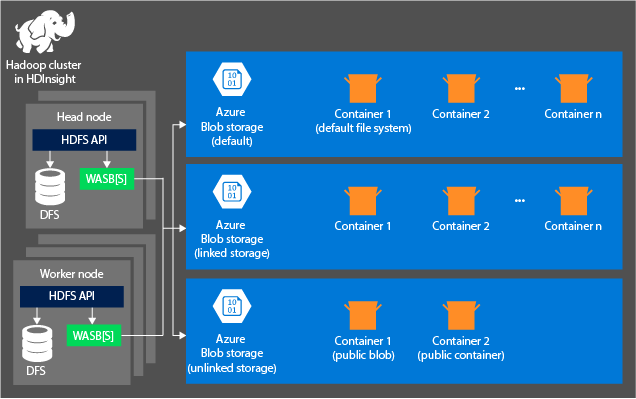
Služba HDInsight poskytuje přístup do systému souborů DFS, který je místně připojen k výpočetním uzlům. Tento systém souborů je přístupný pomocí plně kvalifikovaného identifikátoru URI, například:
hdfs://<namenodehost>/<path>
Prostřednictvím SLUŽBY HDInsight můžete také přistupovat k datům ve službě Azure Storage. Syntaxe je následující:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Pro účty s hierarchickým oborem názvů (Azure Data Lake Storage Gen2) je syntaxe následující:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Při použití účtu služby Azure Storage s clustery HDInsight zvažte následující principy:
Kontejnery v účtech úložiště, které jsou připojeny ke clusteru: Vzhledem k tomu, že název účtu a klíč jsou během vytváření přidružené ke clusteru, máte plný přístup k objektům blob v těchto kontejnerech.
Veřejné kontejnery nebo veřejné objekty blob v účtech úložiště, které nejsou připojené ke clusteru: K objektům blob v kontejnerech máte oprávnění jen pro čtení.
Poznámka:
Veřejné kontejnery umožňují získat seznam všech objektů blob, které jsou v daném kontejneru k dispozici, a získat metadata kontejneru. Veřejné objekty blob umožňují přístup k objektům blob jenom v případě, že znáte přesnou adresu URL. Další informace najdete v tématu Správa anonymního přístupu pro čtení ke kontejnerům a objektům blob.
Privátní kontejnery v účtech úložiště, které nejsou připojené ke clusteru: K objektům blob v kontejnerech nemáte přístup, pokud při odesílání úloh WebHCat nedefinujete účet úložiště.
Účty úložiště, které se definují v procesu vytváření a jejich klíče jsou uloženy v %HADOOP_HOME%/conf/core-site.xml na uzlech clusteru. HdInsight ve výchozím nastavení používá účty úložiště definované v souboru core-site.xml. Toto nastavení můžete upravit pomocí Apache Ambari. Další informace o nastavení účtu úložiště, která je možné upravit nebo umístit do souboru core-site.xml, najdete v těchto článcích:
Několik úloh WebHCat, včetně Apache Hivu. A MapReduce, streamování Apache Hadoop a Apache Pig mají popis účtů úložiště a metadat. (Tento aspekt je aktuálně pravdivý pro Pig s účty úložiště, ale ne pro metadata.) Další informace najdete v tématu Použití clusteru HDInsight s alternativními účty úložiště a metastory.
Objekty blob lze použít pro strukturovaná i nestrukturovaná data. Kontejnery objektů blob ukládají data jako páry klíč/hodnota a nemají žádnou hierarchii adresáře. Název klíče však může obsahovat znak lomítka ( / ), aby se zobrazil, jako by byl soubor uložen v adresářové struktuře. Například klíč objektu blob může být input/log1.txt. Neexistuje žádný skutečný input adresář, ale kvůli znaku lomítka v názvu klíče klíč vypadá jako cesta k souboru.
Výhody služby Azure Storage
Výpočetní clustery a prostředky úložiště, které nejsou společně umístěné, mají předpokládané náklady na výkon. Tyto náklady se zmírňují způsobem, jakým se výpočetní clustery vytvářejí blízko prostředků účtu úložiště v oblasti Azure. V této oblasti můžou výpočetní uzly efektivně přistupovat k datům přes vysokorychlostní síť ve službě Azure Storage.
Při ukládání dat ve službě Azure Storage místo HDFS získáte několik výhod:
Opakované použití dat a sdílení: data v HDFS se nachází uvnitř výpočetního clusteru. Jenom aplikace, které mají přístup k výpočetnímu clusteru, můžou používat data pomocí rozhraní API HDFS. Data ve službě Azure Storage jsou naopak přístupná prostřednictvím rozhraní API HDFS nebo rozhraní REST API služby Blob Storage. Z tohoto uspořádání lze k vytváření a využívání dat použít větší sadu aplikací (včetně jiných clusterů HDInsight) a nástrojů.
Archivace dat: Pokud jsou data uložená ve službě Azure Storage, clustery HDInsight používané pro výpočty je možné bezpečně odstranit bez ztráty uživatelských dat.
Náklady na úložiště dat: Ukládání dat v systému souborů DFS za dlouhodobé období je nákladnější než ukládání dat ve službě Azure Storage. Vzhledem k tomu, že náklady na výpočetní cluster jsou vyšší než náklady na Azure Storage. Vzhledem k tomu, že se data nemusí znovu načítat pro každou generaci výpočetního clusteru, šetříte také náklady na načítání dat.
Elastické škálování: I když HDFS poskytuje škálovaný systém souborů, škála se určuje podle počtu uzlů, které vytvoříte pro svůj cluster. Změna škálování může být složitější než možnosti elastického škálování, které získáte automaticky ve službě Azure Storage.
Geografická replikace: Vaše služba Azure Storage může být geograficky replikovaná. I když geografická replikace poskytuje geografické obnovení a redundanci dat, převzetí služeb při selhání do geograficky replikovaného umístění výrazně ovlivňuje váš výkon a může se vám vyžadovat další náklady. Proto zvolte geografickou replikaci opatrně a pouze v případě, že hodnota dat zdůvodní dodatečné náklady.
Některé úlohy a balíčky MapReduce můžou vytvářet přechodné výsledky, které byste nechtěli uložit ve službě Azure Storage. V takovém případě můžete data uložit do místního HDFS. HDInsight používá dfs pro několik z těchto průběžných výsledků v úlohách Hive a dalších procesech.
Poznámka:
Většina příkazů HDFS (například ls, copyFromLocala mkdir) funguje podle očekávání ve službě Azure Storage. Pouze příkazy specifické pro nativní implementaci HDFS (která se označuje jako DFS), například fschk a dfsadminzobrazují různé chování ve službě Azure Storage.