Interaktivní transformace dat pomocí Apache Sparku v Azure Machine Učení
Transformace dat se stává jedním z nejdůležitějších kroků v projektech strojového učení. Integrace služby Azure Machine Učení s Azure Synapse Analytics poskytuje přístup k fondu Apache Spark založenému na Azure Synapse pro interaktivní transformace dat pomocí azure Machine Učení Notebooks.
V tomto článku se dozvíte, jak provádět transformace dat pomocí
- Výpočetní prostředí Spark bez serveru
- Připojený fond Synapse Spark
Požadavky
- Předplatné Azure; Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet .
- Pracovní prostor služby Azure Machine Learning. Viz Vytvoření prostředků pracovního prostoru.
- Účet úložiště Azure Data Lake Storage (ADLS) Gen2. Viz Vytvoření účtu úložiště Azure Data Lake Storage (ADLS) Gen2.
- (Volitelné): Azure Key Vault. Viz Vytvoření služby Azure Key Vault.
- (Volitelné): Instanční objekt. Viz Vytvoření instančního objektu.
- (Volitelné): Připojený fond Synapse Sparku v pracovním prostoru azure machine Učení.
Než začnete s úkoly transformace dat, přečtěte si o procesu ukládání tajných kódů.
- Přístupový klíč účtu služby Azure Blob Storage
- Token sdíleného přístupového podpisu (SAS)
- Informace o instančním objektu služby Azure Data Lake Storage (ADLS) Gen2
ve službě Azure Key Vault. Potřebujete také vědět, jak zpracovávat přiřazení rolí v účtech úložiště Azure. Tyto koncepty jsou popsány v následujících částech. Pak prozkoumáme podrobnosti o interaktivní transformaci dat pomocí fondů Spark ve službě Azure Machine Učení Notebooks.
Tip
Informace o konfiguraci přiřazení role účtu úložiště Azure nebo o přístupu k datům v účtech úložiště pomocí předávání identity uživatele najdete v tématu Přidání přiřazení rolí v účtech úložiště Azure.
Transformace interaktivních dat pomocí Apache Sparku
Azure Machine Učení nabízí bezserverové výpočetní prostředky Sparku a připojený fond Synapse Spark pro interaktivní transformaci dat pomocí Apache Sparku v Azure Machine Učení Notebooks. Výpočetní prostředí Spark bez serveru nevyžaduje vytvoření prostředků v pracovním prostoru Azure Synapse. Místo toho se plně spravovaný bezserverový výpočetní výkon Sparku zpřístupní přímo v poznámkových blocích Azure Machine Učení. Použití bezserverového výpočetního prostředí Spark je nejjednodušší přístup ke clusteru Spark v Učení Azure Machine.
Výpočetní prostředí Spark bez serveru ve službě Azure Machine Učení Notebooks
Výpočetní prostředí Spark bez serveru je ve výchozím nastavení dostupné ve službě Azure Machine Učení Notebooks. Pokud k němu chcete získat přístup v poznámkovém bloku, vyberte v části Počítač Azure Učení Bezserverový Spark z nabídky Výběr výpočetních prostředků bezserverové výpočetní prostředky.
Uživatelské rozhraní Poznámkové bloky také poskytuje možnosti konfigurace relace Sparku pro výpočetní prostředí Spark bez serveru. Konfigurace relace Sparku:
- V horní části obrazovky vyberte Konfigurovat relaci .
- V rozevírací nabídce vyberte verzi Apache Sparku.
Důležité
Azure Synapse Runtime pro Apache Spark: Oznámení
- Azure Synapse Runtime pro Apache Spark 3.2:
- Datum oznámení EOLA: 8. července 2023
- Datum ukončení podpory: 8. července 2024. Po tomto datu bude modul runtime zakázán.
- Pro trvalou podporu a optimální výkon doporučujeme migrovat na Apache Spark 3.3.
- Azure Synapse Runtime pro Apache Spark 3.2:
- V rozevírací nabídce vyberte Typ instance. V současné době jsou podporovány následující typy instancí:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Zadejte hodnotu časového limitu relace Sparku v minutách.
- Vyberte, zda se mají exekutory dynamicky přidělovat .
- Vyberte počet exekutorů pro relaci Sparku.
- V rozevírací nabídce vyberte velikost exekutoru.
- V rozevírací nabídce vyberte velikost ovladače.
- Pokud chcete ke konfiguraci relace Sparku použít soubor Conda, zaškrtněte políčko Nahrát soubor conda. Pak vyberte Procházet a zvolte soubor Conda s požadovanou konfigurací relace Sparku.
- Přidejte vlastnosti nastavení konfigurace, vstupní hodnoty do textových polí Vlastnost a Hodnota a vyberte Přidat.
- Vyberte Použít.
- V místní nabídce Konfigurovat novou relaci vyberte Zastavit relaci?
Změny konfigurace relace se zachovají a budou k dispozici pro jinou relaci poznámkového bloku, která se spouští s bezserverovým výpočetním prostředím Spark.
Tip
Pokud používáte balíčky Conda na úrovni relace, můžete zkrátit dobu spuštění relace Sparku, pokud nastavíte konfigurační proměnnou spark.hadoop.aml.enable_cache na hodnotu true. Při prvním spuštění relace s balíčky Conda na úrovni relace obvykle trvá 10 až 15 minut. Následující relace však začíná proměnnou konfigurace nastavenou na true obvykle trvá tři až pět minut.
Import a uspořádání dat z Azure Data Lake Storage (ADLS) Gen2
K datům uloženým v účtech úložiště Azure Data Lake Storage (ADLS) Gen2 můžete přistupovat a měnit jejich uspořádání pomocí abfss:// identifikátorů URI dat, které následují jeden ze dvou mechanismů přístupu k datům:
- Předávání identity uživatele
- Přístup k datům založeným na instančním objektu
Tip
Transformace dat s výpočetním prostředím Spark bez serveru a předáním identity uživatele pro přístup k datům v účtu úložiště Azure Data Lake Storage (ADLS) Gen2 vyžaduje nejmenší počet kroků konfigurace.
Zahájení interaktivní transformace dat s předáváním identity uživatele:
Ověřte, že identita uživatele má v účtu úložiště Azure Data Lake Storage (ADLS) Gen2 přiřazení role Přispěvatela Přispěvateldat objektů blob služby Storage.
Pokud chcete použít bezserverové výpočetní prostředky Sparku, v části Počítač Azure Učení Bezserverové prostředí Spark v nabídce Výběr výpočetních prostředků vyberte bezserverové výpočetní prostředky.
Pokud chcete použít připojený fond Synapse Spark, vyberte připojený fond Synapse Spark v části Fondy Synapse Sparku z nabídky Výběr výpočetních prostředků .
Tento vzorový kód transformace dat Titanic ukazuje použití identifikátoru URI dat ve formátu
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>spyspark.pandasapyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Poznámka:
Tento vzorový kód Pythonu používá
pyspark.pandas. Tuto možnost podporuje pouze modul runtime Spark verze 3.2 nebo novější.
Uspořádání dat prostřednictvím instančního objektu:
Ověřte, že instanční objekt má v účtu úložiště Azure Data Lake Storage (ADLS) Gen2 přiřazené role Přispěvatel dat přispěvatele a Přispěvateldat objektů blob služby Storage.
Vytvořte tajné kódy služby Azure Key Vault pro ID tenanta instančního objektu, ID klienta a hodnoty tajných kódů klienta.
V nabídce pro výběr výpočetních prostředků vyberte výpočetní prostředí Spark bez serveru v azure Učení Bezserverové výpočetní prostředí nebo v nabídce pro výběr výpočetních prostředků vyberte připojený fond Synapse Spark ve fondechSynapse Spark.
Pokud chcete nastavit ID tenanta instančního objektu, ID klienta a tajný klíč klienta v konfiguraci, a spusťte následující ukázku kódu.
Volání
get_secret()v kódu závisí na názvu služby Azure Key Vault a na názvech tajných kódů služby Azure Key Vault vytvořených pro ID tenanta instančního objektu, ID klienta a tajný klíč klienta. Nastavte v konfiguraci tyto odpovídající názvy a hodnoty vlastností:- Vlastnost ID klienta:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Vlastnost tajného klíče klienta:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Vlastnost ID tenanta:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Hodnota ID tenanta:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Vlastnost ID klienta:
Importujte a přeuspořádejte data pomocí identifikátoru URI dat ve formátu
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, jak je znázorněno v ukázce kódu pomocí dat Titanic.
Import a uspořádání dat ze služby Azure Blob Storage
K datům azure Blob Storage můžete přistupovat buď pomocí přístupového klíče účtu úložiště, nebo pomocí tokenu sdíleného přístupového podpisu (SAS). Tyto přihlašovací údaje byste měli uložit ve službě Azure Key Vault jako tajný klíč a nastavit je jako vlastnosti v konfiguraci relace.
Zahájení interaktivní transformace dat:
Na studio Azure Machine Learning levém panelu vyberte Poznámkové bloky.
V nabídce pro výběr výpočetních prostředků vyberte výpočetní prostředí Spark bez serveru v azure Učení Bezserverové výpočetní prostředí nebo v nabídce pro výběr výpočetních prostředků vyberte připojený fond Synapse Spark ve fondechSynapse Spark.
Konfigurace přístupového klíče účtu úložiště nebo tokenu sdíleného přístupového podpisu (SAS) pro přístup k datům ve službě Azure Machine Učení Notebooks:
Pro přístupový klíč nastavte vlastnost
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, jak je znázorněno v tomto fragmentu kódu:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Pro token SAS nastavte vlastnost
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, jak je znázorněno v tomto fragmentu kódu:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Poznámka:
Volání
get_secret()ve výše uvedených fragmentech kódu vyžadují název služby Azure Key Vault a názvy tajných kódů vytvořených pro přístupový klíč účtu služby Azure Blob Storage nebo token SAS.
Spusťte kód transformace dat ve stejném poznámkovém bloku. Naformátujte identifikátor URI dat jako , podobně jako
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>tento fragment kódu:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Poznámka:
Tento vzorový kód Pythonu používá
pyspark.pandas. Tuto možnost podporuje pouze modul runtime Spark verze 3.2 nebo novější.
Import a uspořádání dat ze služby Azure Machine Učení Datastore
Pokud chcete získat přístup k datům ze služby Azure Machine Učení Datastore, definujte cestu k datům v úložišti dat pomocí formátuazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA> URI. Pokud chcete uspořádat data z počítače Azure Učení úložiště dat v relaci poznámkových bloků interaktivně:
V nabídce pro výběr výpočetních prostředků vyberte výpočetní prostředí Spark bez serveru v azure Učení Bezserverové výpočetní prostředí nebo v nabídce pro výběr výpočetních prostředků vyberte připojený fond Synapse Spark ve fondechSynapse Spark.
Tento vzorový kód ukazuje, jak číst a měnit uspořádání dat Titanic ze služby Azure Machine Učení Datastore pomocí
azureml://identifikátoru URIpyspark.pandasúložiště dat apyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Poznámka:
Tento vzorový kód Pythonu používá
pyspark.pandas. Tuto možnost podporuje pouze modul runtime Spark verze 3.2 nebo novější.
Azure Machine Učení úložišti dat mají přístup k datům pomocí přihlašovacích údajů účtu úložiště Azure.
- přístupový klíč
- Token SAS
- instanční objekt
nebo zadejte přístup k datům bez přihlašovacích údajů. V závislosti na typu úložiště dat a základním typu účtu úložiště Azure vyberte příslušný ověřovací mechanismus, který zajistí přístup k datům. Tato tabulka shrnuje mechanismy ověřování pro přístup k datům ve službě Azure Machine Učení úložištích dat:
| Storage account type | Přístup k datům bez přihlašovacích údajů | Mechanismus přístupu k datům | Přiřazení rolí |
|---|---|---|---|
| Azure Blob | No | Přístupový klíč nebo token SAS | Nejsou potřeba žádná přiřazení rolí. |
| Azure Blob | Ano | Předávání identity uživatele* | Identita uživatele by měla mít v účtu služby Azure Blob Storage odpovídající přiřazení rolí. |
| Azure Data Lake Storage (ADLS) Gen 2 | No | Instanční objekt | Instanční objekt by měl mít v účtu úložiště Azure Data Lake Storage (ADLS) Gen2 odpovídající přiřazení rolí. |
| Azure Data Lake Storage (ADLS) Gen 2 | Ano | Předávání identity uživatele | Identita uživatele by měla mít v účtu úložiště Azure Data Lake Storage (ADLS) Gen2 odpovídající přiřazení rolí. |
* Předávání identity uživatele funguje pro úložiště dat bez přihlašovacích údajů, které odkazují na účty úložiště objektů blob v Azure, pouze pokud není povolené obnovitelné odstranění .
Přístup k datům ve výchozí sdílené složce
Výchozí sdílená složka se připojí k výpočetním prostředkům Sparku bez serveru i k připojeným fondům Synapse Spark.
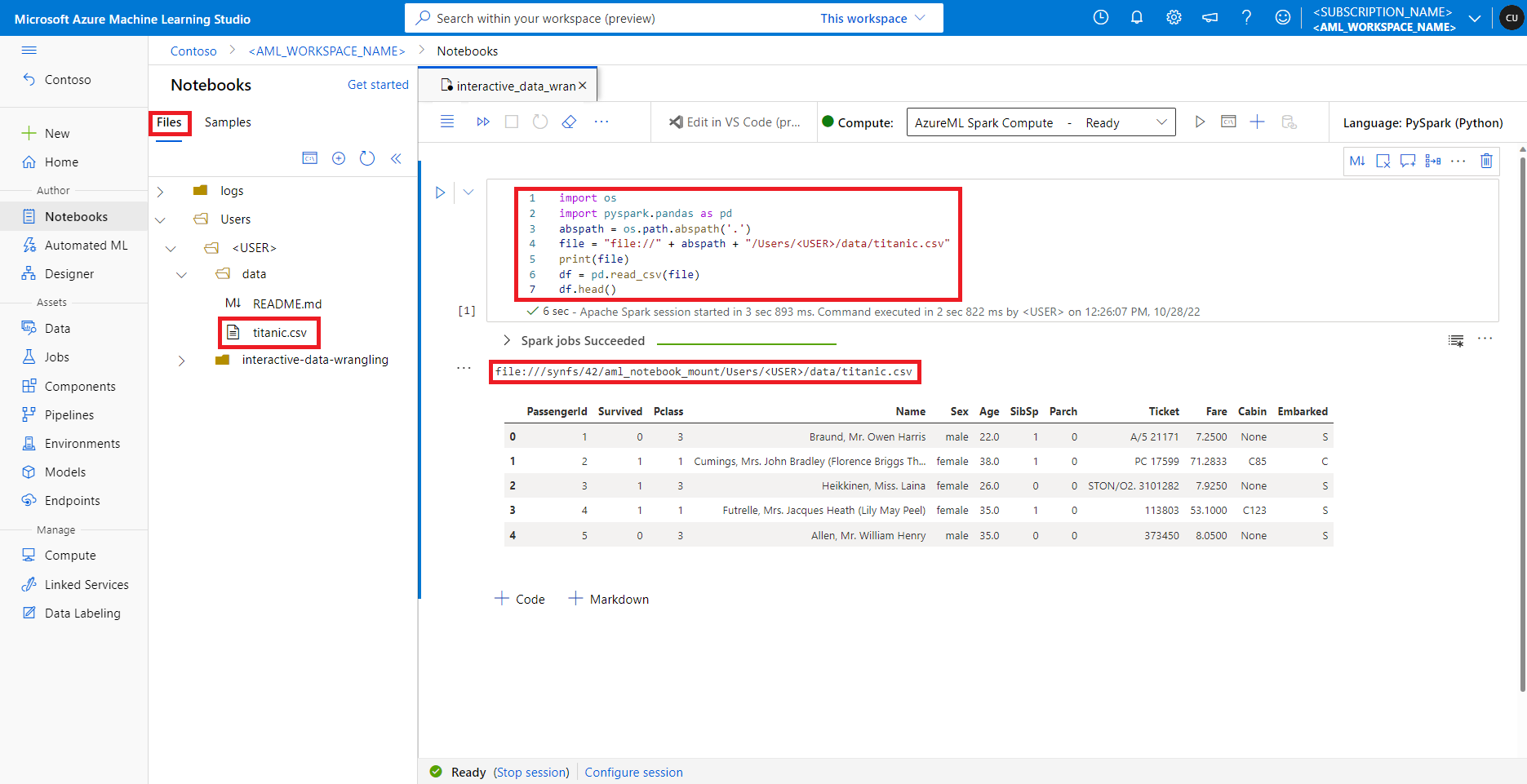
V studio Azure Machine Learning se soubory ve výchozí sdílené složce zobrazují ve stromu adresáře na kartě Soubory. Kód poznámkového bloku může přímo přistupovat k souborům uloženým v této sdílené složce pomocí file:// protokolu spolu s absolutní cestou k souboru bez dalších konfigurací. Tento fragment kódu ukazuje, jak získat přístup k souboru uloženému ve výchozí sdílené složce:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Poznámka:
Tento vzorový kód Pythonu používá pyspark.pandas. Tuto možnost podporuje pouze modul runtime Spark verze 3.2 nebo novější.