Kurz: Nahrání, přístup k datům a prozkoumání dat ve službě Azure Machine Učení
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
V tomto kurzu se naučíte:
- Nahrání dat do cloudového úložiště
- Vytvoření datového prostředku azure machine Učení
- Přístup k datům v poznámkovém bloku pro interaktivní vývoj
- Vytvoření nových verzí datových prostředků
Začátek projektu strojového učení obvykle zahrnuje průzkumnou analýzu dat (EDA), předběžné zpracování dat (čištění, přípravu funkcí) a vytváření prototypů modelu strojového Učení k ověření hypotéz. Tato fáze projektu prototypů je vysoce interaktivní. Hodí se k vývoji v integrovaném vývojovém prostředí (IDE) nebo poznámkovém bloku Jupyter s interaktivní konzolou Pythonu. Tento kurz popisuje tyto myšlenky.
Toto video ukazuje, jak začít studio Azure Machine Learning, abyste mohli postupovat podle kroků v tomto kurzu. Video ukazuje, jak vytvořit poznámkový blok, naklonovat poznámkový blok, vytvořit výpočetní instanci a stáhnout data potřebná pro tento kurz. Kroky jsou popsané také v následujících částech.
Požadavky
-
Pokud chcete používat Učení Azure Machine, budete nejdřív potřebovat pracovní prostor. Pokud ho nemáte, dokončete vytváření prostředků, které potřebujete, abyste mohli začít vytvářet pracovní prostor a získat další informace o jeho používání.
-
Přihlaste se do studia a vyberte pracovní prostor, pokud ještě není otevřený.
-
Otevřete nebo vytvořte poznámkový blok v pracovním prostoru:
- Pokud chcete zkopírovat nebo vložit kód do buněk, vytvořte nový poznámkový blok.
- Nebo otevřete kurzy/get-started-notebooks/explore-data.ipynb v části Ukázky studia. Potom vyberte Clone (Klonovat ) a přidejte poznámkový blok do složky Soubory. (Podívejte se, kde najít ukázky.)
Nastavení jádra
Na horním panelu nad otevřeným poznámkovým blokem vytvořte výpočetní instanci, pokud ji ještě nemáte.

Pokud je výpočetní instance zastavená, vyberte Spustit výpočetní prostředky a počkejte, až bude spuštěný.

Ujistěte se, že jádro, které se nachází v pravém horním rohu, je
Python 3.10 - SDK v2. Pokud ne, vyberte toto jádro pomocí rozevíracího seznamu.
Pokud se zobrazí banner s informací, že potřebujete být ověřeni, vyberte Ověřit.



Důležité
Zbytek tohoto kurzu obsahuje buňky poznámkového bloku kurzu. Zkopírujte nebo vložte je do nového poznámkového bloku nebo přepněte do poznámkového bloku, pokud jste ho naklonovali.
Stažení dat použitých v tomto kurzu
Při příjmu dat zpracovává Azure Data Explorer nezpracovaná data v těchto formátech. Tento kurz používá tuto ukázku dat klienta ve formátu CSV. Uvidíme postup, jak pokračovat v prostředku azure machine Učení. V tomto prostředku vytvoříme místní složku s navrhovaným názvem dat přímo pod složkou, ve které se tento poznámkový blok nachází.
Poznámka:
Tento kurz závisí na datech umístěných v umístění složky prostředků azure machine Učení. V tomto kurzu "local" znamená umístění složky v daném prostředku azure machine Učení.
Pod třemi tečkami vyberte Otevřít terminál , jak je znázorněno na tomto obrázku:
Okno terminálu se otevře na nové kartě.
Ujistěte se, že jste
cdve stejné složce, ve které se tento poznámkový blok nachází. Pokud je poznámkový blok například ve složce s názvem get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedZadáním těchto příkazů v okně terminálu zkopírujte data do výpočetní instance:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvTeď můžete okno terminálu zavřít.
Další informace o těchto datech najdete v úložišti UCI Machine Učení.
Vytvoření popisovače do pracovního prostoru
Než se pustíme do kódu, potřebujete způsob, jak odkazovat na váš pracovní prostor. ml_client Vytvoříte pro popisovač pracovního prostoru. Pak použijete ml_client ke správě prostředků a úloh.
Do další buňky zadejte ID předplatného, název skupiny prostředků a název pracovního prostoru. Tyto hodnoty najdete takto:
- V pravém horním studio Azure Machine Learning panelu nástrojů vyberte název pracovního prostoru.
- Zkopírujte hodnotu pro pracovní prostor, skupinu prostředků a ID předplatného do kódu.
- Budete muset zkopírovat jednu hodnotu, zavřít oblast a vložit a pak se vrátit k další hodnotě.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Poznámka:
Vytvoření MLClient se nepřipojí k pracovnímu prostoru. Inicializace klienta je opožděná, bude čekat poprvé, až bude muset provést volání (k tomu dojde v další buňce kódu).
Nahrání dat do cloudového úložiště
Azure Machine Učení používá identifikátory URI (Uniform Resource Identifier), které odkazují na umístění úložiště v cloudu. Identifikátor URI usnadňuje přístup k datům v poznámkových blocích a úlohách. Formáty identifikátorů URI dat vypadají podobně jako webové adresy URL, které používáte ve webovém prohlížeči pro přístup k webovým stránkám. Příklad:
- Přístup k datům z veřejného serveru https:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Přístup k datům z Azure Data Lake Gen2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Datový prostředek služby Azure Machine Učení se podobá záložkám webového prohlížeče (oblíbené položky). Místo zapamatování dlouhých cest úložiště (URI), které odkazují na nejčastěji používaná data, můžete vytvořit datový prostředek a pak k ho získat přístup popisným názvem.
Vytvoření datového assetu také vytvoří odkaz na umístění zdroje dat spolu s kopií jeho metadat. Vzhledem k tomu, že data zůstávají v existujícím umístění, neúčtují se vám žádné další náklady na úložiště a nezpochybňujete integritu zdroje dat. Datové prostředky můžete vytvářet ze služby Azure Machine Učení úložištích dat, Azure Storage, veřejných adres URL a místních souborů.
Tip
V případě nahrávání dat s menší velikostí funguje vytvoření datového prostředku azure machine Učení dobře pro nahrávání dat z prostředků místního počítače do cloudového úložiště. Tento přístup se vyhne nutnosti používat další nástroje nebo nástroje. Nahrání dat s větší velikostí ale může vyžadovat vyhrazený nástroj nebo nástroj – například azcopy. Nástroj příkazového řádku azcopy přesune data do a ze služby Azure Storage. Další informace o azcopy najdete tady.
Další buňka poznámkového bloku vytvoří datový asset. Ukázka kódu nahraje nezpracovaný datový soubor do určeného prostředku cloudového úložiště.
Pokaždé, když vytvoříte datový asset, potřebujete pro něj jedinečnou verzi. Pokud už verze existuje, zobrazí se chyba. V tomto kódu používáme "počáteční" pro první čtení dat. Pokud už tato verze existuje, jeho vytvoření znovu přeskočíme.
Můžete také vynechat parametr verze a vygeneruje se za vás číslo verze, počínaje číslem 1 a následným zvýšením odsud.
V tomto kurzu použijeme jako první verzi název "initial". Kurz Vytvoření produkčního kanálu strojového učení bude také používat tuto verzi dat, takže tady používáme hodnotu, kterou v tomto kurzu znovu uvidíte.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Nahraná data můžete zobrazit tak , že vyberete Data na levé straně. Uvidíte, že se data nahrají a vytvoří se datový asset:
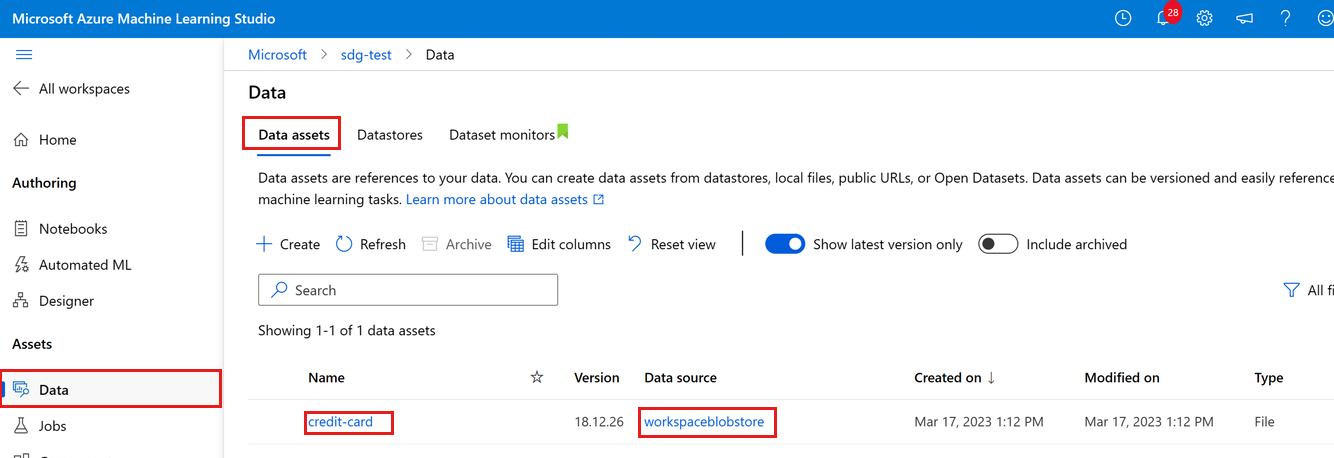
Tato data se nazývají platební karta a na kartě Datové prostředky je vidíme ve sloupci Název . Tato data se nahrála do výchozího úložiště dat pracovního prostoru s názvem workspaceblobstore, které vidíte ve sloupci Zdroj dat.
Úložiště dat azure machine Učení je odkazem na existující účet úložiště v Azure. Úložiště dat nabízí tyto výhody:
- Běžné a snadno použitelné rozhraní API pro interakci s různými typy úložiště (Blob/Files/Azure Data Lake Storage) a metodami ověřování.
- Jednodušší způsob, jak zjistit užitečné úložiště dat při práci jako tým.
- Ve skriptech můžete skrýt informace o připojení pro přístup k datům založeným na přihlašovacích údajích (instanční objekt, SAS/klíč).
Přístup k datům v poznámkovém bloku
Pandas přímo podporuje identifikátory URI – tento příklad ukazuje, jak číst soubor CSV ze služby Azure Machine Učení Datastore:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Jak už jsme ale zmínili dříve, může být obtížné si tyto identifikátory URI zapamatovat. Kromě toho je nutné ručně nahradit všechny <podřetětěžce> v příkazu pd.read_csv skutečnými hodnotami pro vaše prostředky.
Budete chtít vytvořit datové prostředky pro často požadovaná data. Tady je jednodušší způsob, jak získat přístup k souboru CSV v Pandas:
Důležité
V buňce poznámkového bloku spusťte tento kód pro instalaci knihovny Pythonu azureml-fsspec do jádra Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Přečtěte si přístup k datům z cloudového úložiště Azure během interaktivního vývoje a získejte další informace o přístupu k datům v poznámkovém bloku.
Vytvoření nové verze datového assetu
Možná jste si všimli, že data potřebují trochu lehkého čištění, aby se vešel do trénování modelu strojového učení. Má:
- dvě záhlaví
- sloupec ID klienta; Tuto funkci bychom v Učení počítače nepoužili.
- mezery v názvu proměnné odpovědi
Ve srovnání s formátem CSV se formát souboru Parquet stává lepším způsobem, jak tato data uložit. Parquet nabízí kompresi a udržuje schéma. Proto pokud chcete data vyčistit a uložit do Parquet, použijte:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Tato tabulka ukazuje strukturu dat v původním souboru default_of_credit_card_clients.csv . Soubor CSV stažený v předchozím kroku Nahraná data obsahují 23 vysvětlujících proměnných a 1 proměnnou odpovědi, jak je znázorněno tady:
| Názvy sloupců | Typ proměnné | Popis |
|---|---|---|
| X1 | Vysvětlující | Částka daného kreditu (NT dollar): zahrnuje jak individuální spotřebitelský úvěr, tak i jejich rodinný (doplňkový) kredit. |
| X2 | Vysvětlující | Pohlaví (1 = muž; 2 = žena). |
| X3 | Vysvětlující | Vzdělávání (1 = absolventská škola; 2 = univerzita; 3 = střední škola; 4 = ostatní). |
| X4 | Vysvětlující | Rodinný stav (1 = ženatý; 2 = single; 3 = ostatní). |
| X5 | Vysvětlující | Věk (roky). |
| X6-X11 | Vysvětlující | Historie předchozích plateb. Sledovali jsme záznamy o minulých měsíčních platbách (od dubna do září 2005). -1 = řádně zaplatit; 1 = zpoždění platby za jeden měsíc; 2 = zpoždění platby po dobu dvou měsíců; . . .; 8 = zpoždění platby po dobu osmi měsíců; 9 = zpoždění platby po dobu devíti měsíců a výše. |
| X12-17 | Vysvětlující | Částka vyúčtování (NT dolar) od dubna do září 2005. |
| X18-23 | Vysvětlující | Výše předchozí platby (NT dolar) od dubna do září 2005. |
| Y | Response | Výchozí platba (Ano = 1, Ne = 0) |
Dále vytvořte novou verzi datového prostředku (data se automaticky nahrají do cloudového úložiště). Pro tuto verzi přidáme časovou hodnotu, aby se při každém spuštění tohoto kódu vytvořilo jiné číslo verze.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Vyčištěný soubor parquet je nejnovějším zdrojem dat verze. Tento kód zobrazí nejprve sadu výsledků verze CSV a pak verzi Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Vyčištění prostředků
Pokud chcete pokračovat v dalších kurzech, přejděte k dalším krokům.
Zastavení výpočetní instance
Pokud ji teď nebudete používat, zastavte výpočetní instanci:
- V sadě Studio v levé navigační oblasti vyberte Compute.
- Na horních kartách vyberte Výpočetní instance.
- V seznamu vyberte výpočetní instanci.
- Na horním panelu nástrojů vyberte Zastavit.
Odstranění všech prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a postupy pro azure machine Učení články.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Úplně nalevo na webu Azure Portal vyberte Skupiny prostředků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Další kroky
Další informace o datových prostředcích najdete v tématu Vytvoření datových prostředků.
Další informace o úložištích dat najdete v tématu Vytváření úložišť dat.
V kurzech se dozvíte, jak vyvíjet trénovací skript.