Kurz: Zachytávání dat služby Event Hubs ve formátu Parquet a analýza pomocí Azure Synapse Analytics
V tomto kurzu se dozvíte, jak pomocí editoru Stream Analytics bez kódu vytvořit úlohu, která zachytává data služby Event Hubs, aby se Azure Data Lake Storage Gen2 ve formátu Parquet.
V tomto kurzu se naučíte:
- Nasazení generátoru událostí, který odesílá ukázkové události do centra událostí
- Vytvoření úlohy Stream Analytics pomocí editoru bez kódu
- Kontrola vstupních dat a schématu
- Konfigurace Azure Data Lake Storage Gen2, do kterého se budou zachytávat data centra událostí
- Spuštění úlohy Stream Analytics
- Použití Azure Synapse Analytics k dotazování souborů Parquet
Požadavky
Než začnete, ujistěte se, že jste dokončili následující kroky:
- Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet.
- Nasaďte aplikaci generátoru událostí TollApp do Azure. Nastavte parametr interval na hodnotu 1 a pro tento krok použijte novou skupinu prostředků.
- Vytvořte pracovní prostor Azure Synapse Analytics s účtem Data Lake Storage Gen2.
Použití editoru kódu k vytvoření úlohy Stream Analytics
Vyhledejte skupinu prostředků, ve které byl generátor událostí TollApp nasazen.
Vyberte obor názvů Azure Event Hubs.
Na stránce Obor názvů služby Event Hubs vyberte v nabídce vlevo v části Entity možnost Event Hubs.
Vyberte
entrystreaminstanci.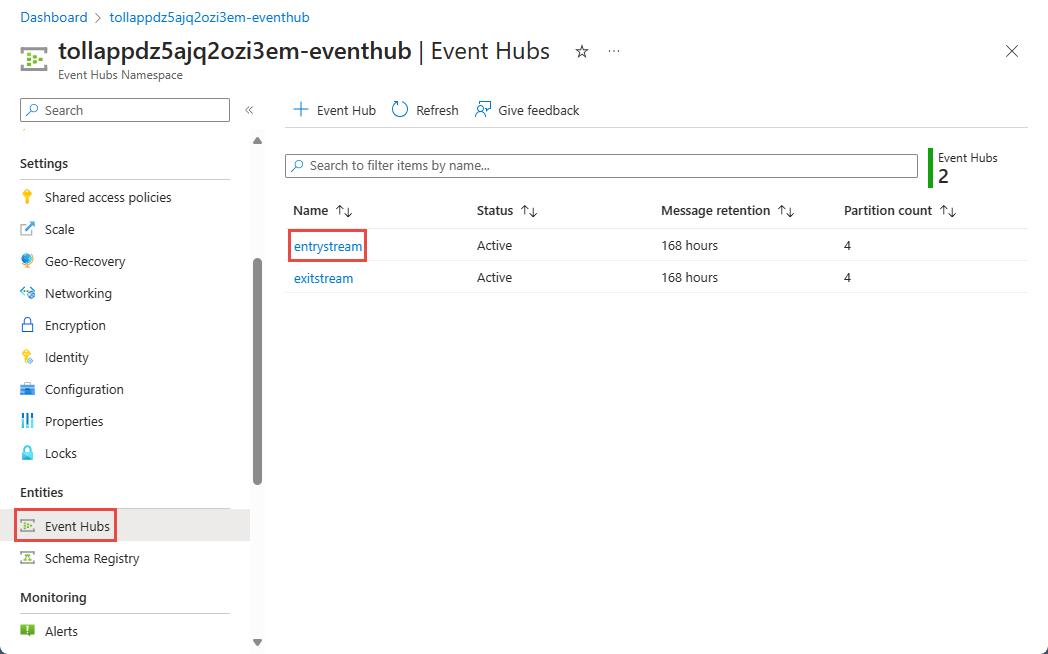
Na stránce Instance služby Event Hubs vyberte Zpracovat data v části Funkce v nabídce vlevo.
Vyberte Spustit na dlaždici Zachytávat data do ADLS Gen2 ve formátu Parquet .
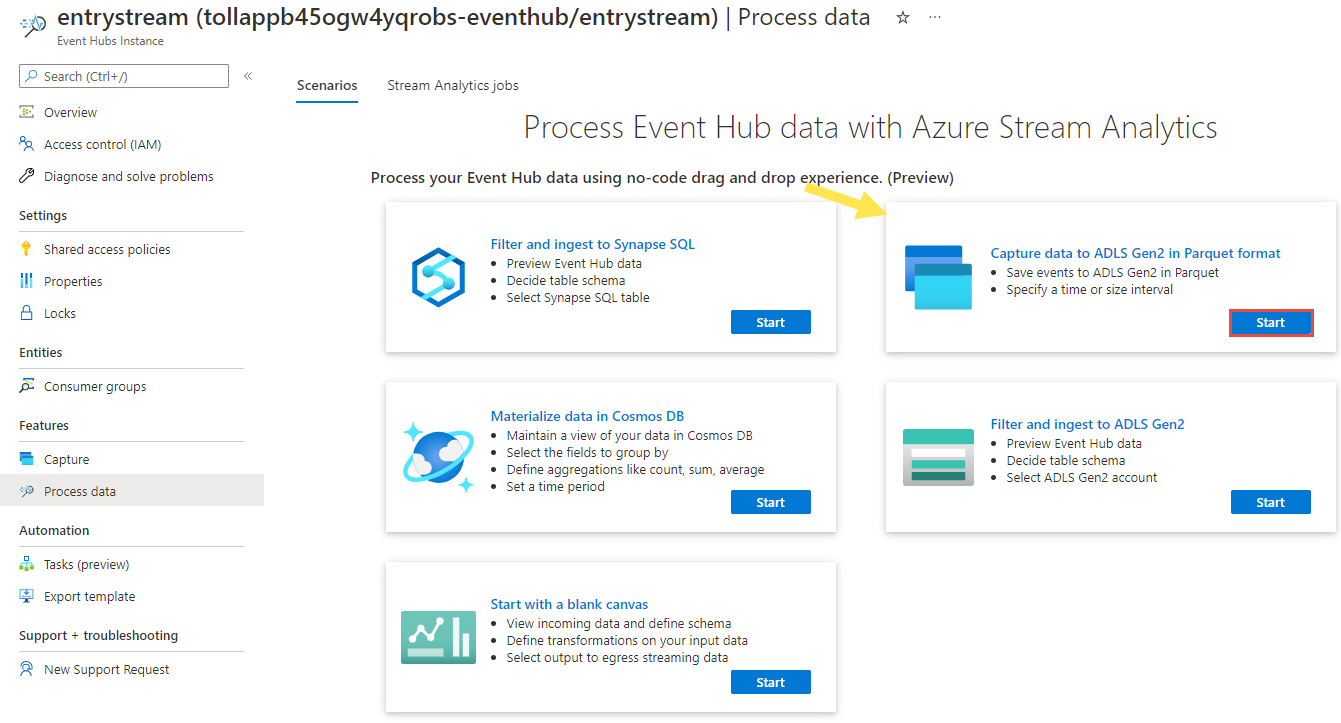
Pojmenujte úlohu
parquetcapturea vyberte Vytvořit.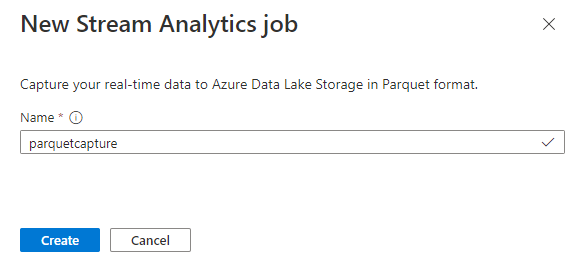
Na stránce konfigurace centra událostí potvrďte následující nastavení a pak vyberte Připojit.
Skupina uživatelů: Výchozí
Typ serializace vstupních dat: JSON
Režim ověřování , který úloha použije pro připojení k centru událostí: Připojovací řetězec.
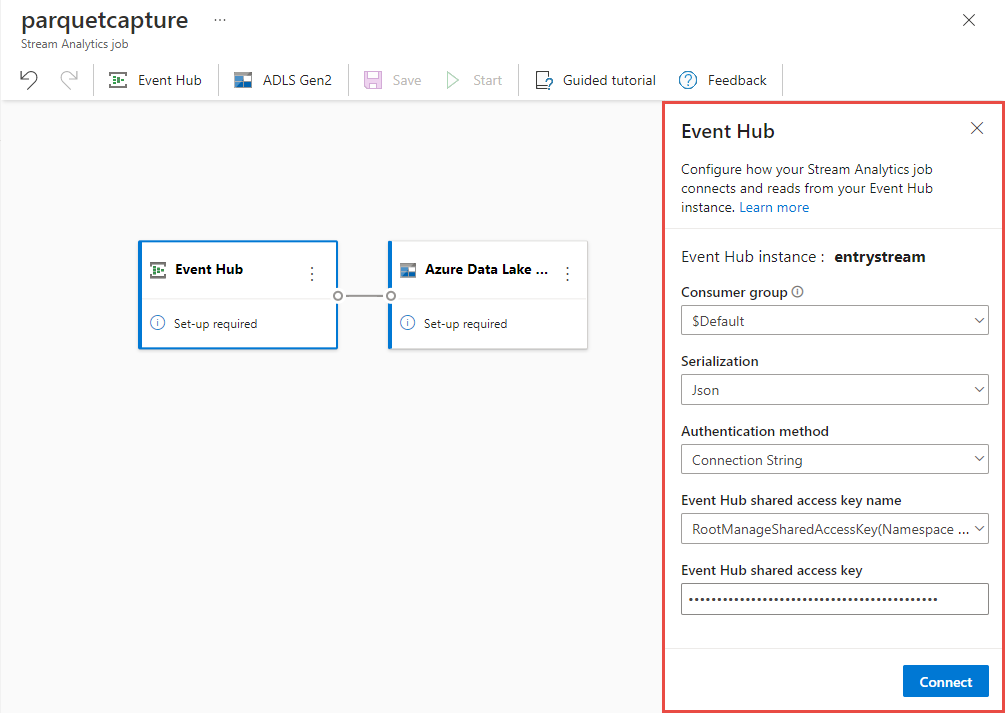
Během několika sekund uvidíte ukázková vstupní data a schéma. Můžete zvolit, jestli chcete pole vyřadit, přejmenovat je nebo změnit datový typ.
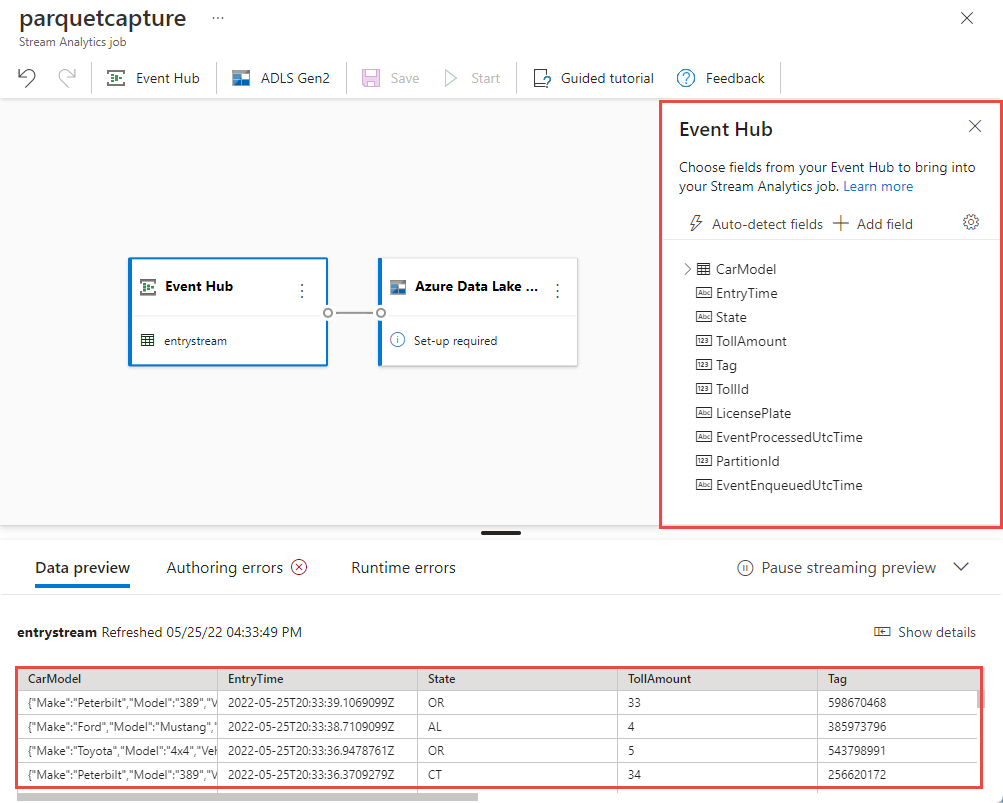
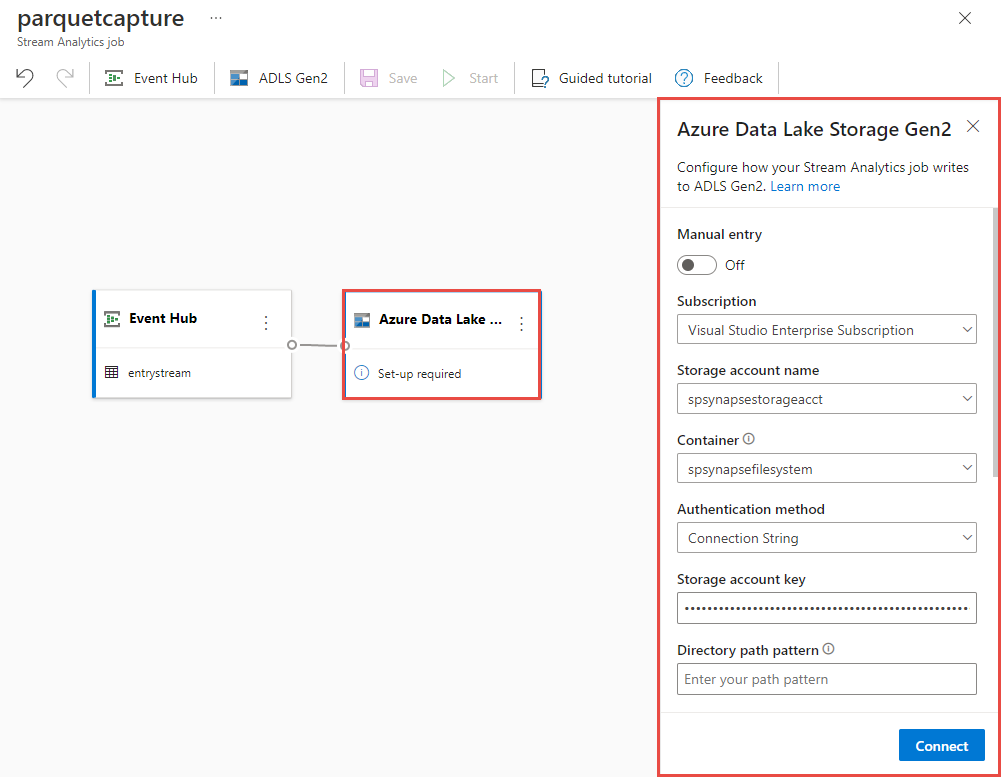
Vyberte dlaždici Azure Data Lake Storage Gen2 na plátně a nakonfigurujte ji zadáním
- Předplatné, ve kterém se nachází váš účet Azure Data Lake Gen2
- Název účtu úložiště, což by měl být stejný účet ADLS Gen2, který se používá s pracovním prostorem Azure Synapse Analytics v části Požadavky.
- Kontejner, ve kterém budou vytvořeny soubory Parquet.
- Vzor cesty nastavený na {date}/{time}
- Vzor data a času jako výchozí yy-mm-dd a HH.
- Vyberte Připojit.
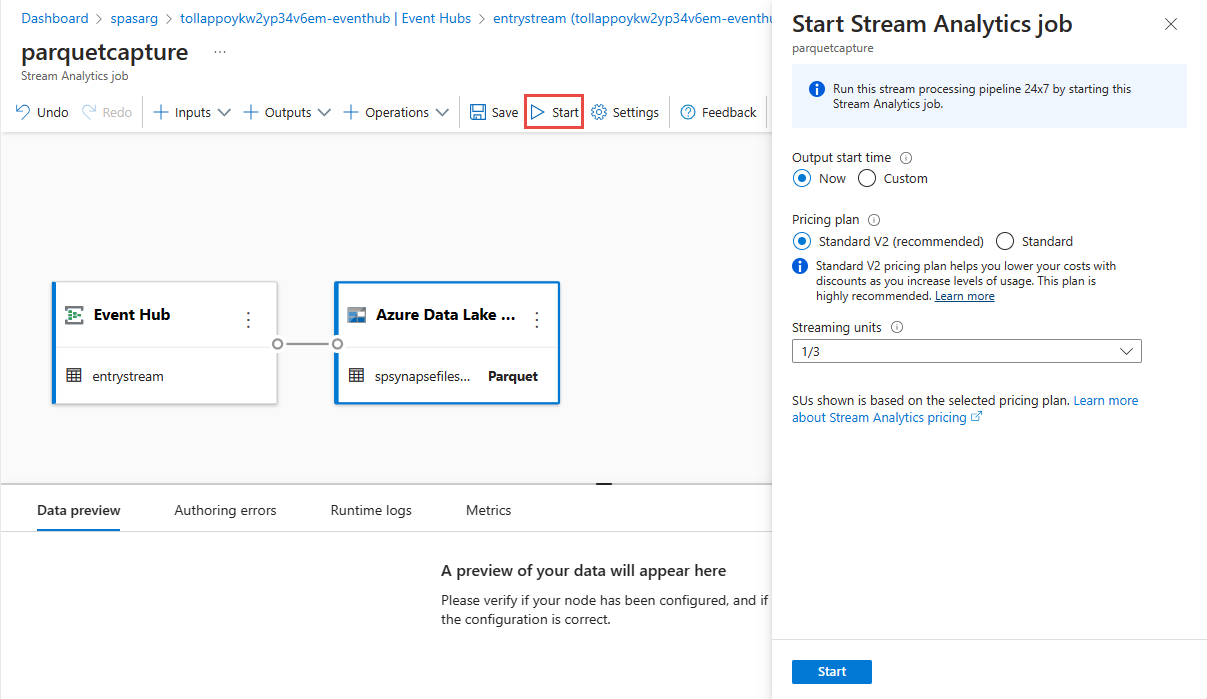
Na horním pásu karet vyberte Uložit , aby se úloha uložila, a pak ji spusťte tak, že vyberete Spustit . Po spuštění úlohy vyberte X v pravém rohu a zavřete tak stránku úlohy Stream Analytics .
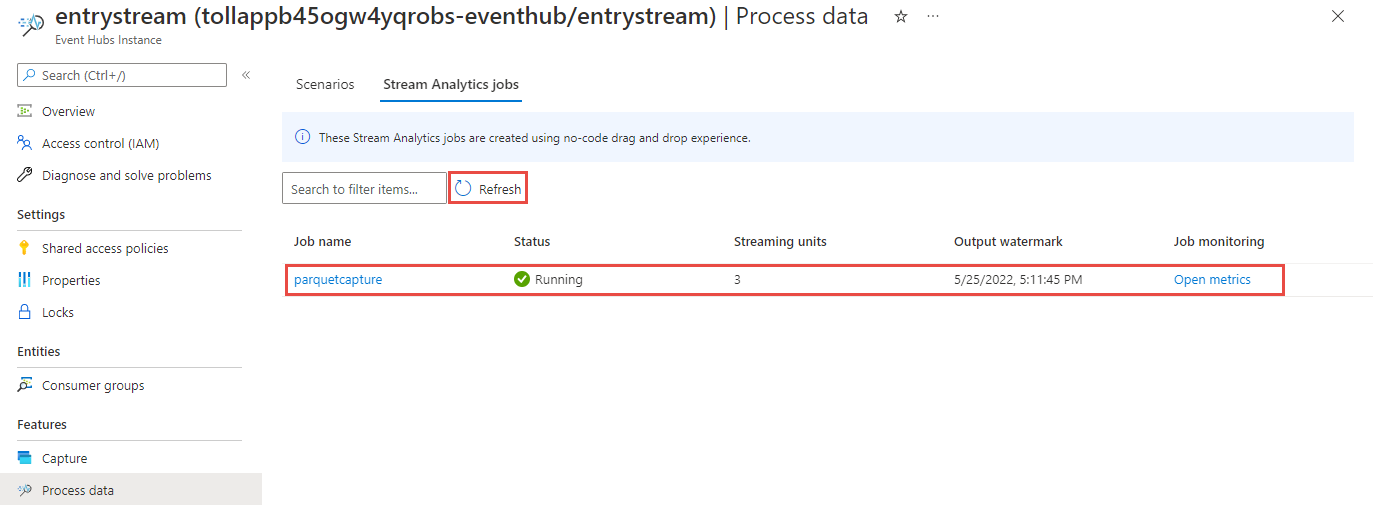
Zobrazí se seznam všech úloh Stream Analytics vytvořených pomocí editoru bez kódu. A během dvou minut vaše úloha přejde do stavu Spuštěno . Výběrem tlačítka Aktualizovat na stránce zobrazte změnu stavu z Hodnoty Vytvořeno –> Spouštění – Spuštěno> .








Zobrazení výstupu v účtu Azure Data Lake Storage Gen2
Vyhledejte účet Azure Data Lake Storage Gen2, který jste použili v předchozím kroku.
Vyberte kontejner, který jste použili v předchozím kroku. Uvidíte soubory Parquet vytvořené na základě vzoru cesty {date}/{time} použitého v předchozím kroku.
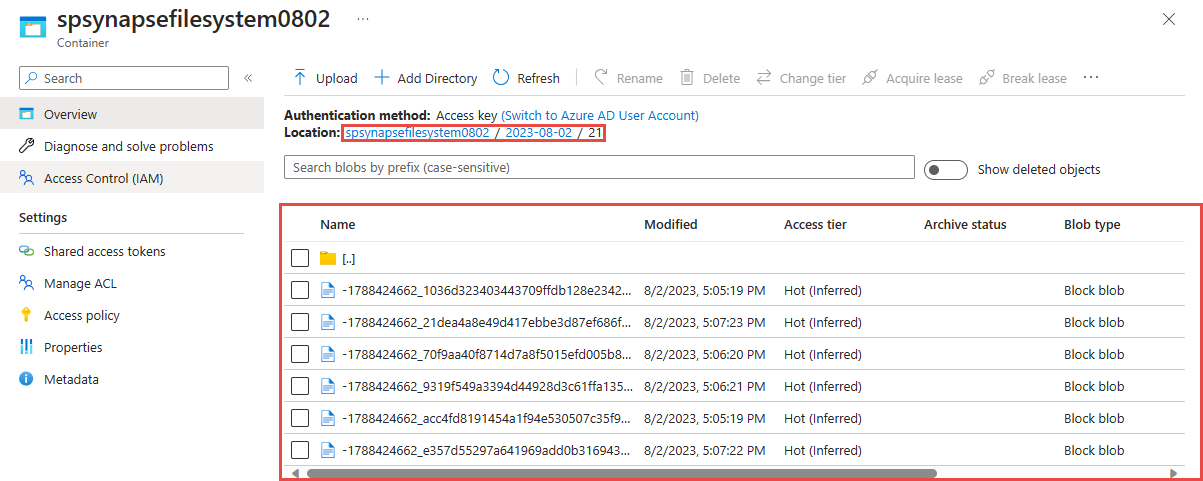
Dotazování na zachycená data ve formátu Parquet pomocí Azure Synapse Analytics
Dotazování pomocí Azure Synapse Sparku
Vyhledejte pracovní prostor Azure Synapse Analytics a otevřete Synapse Studio.
Pokud ještě neexistuje, vytvořte ve svém pracovním prostoru bezserverový fond Apache Sparku.
V Synapse Studio přejděte do centra Vývoj a vytvořte nový poznámkový blok.
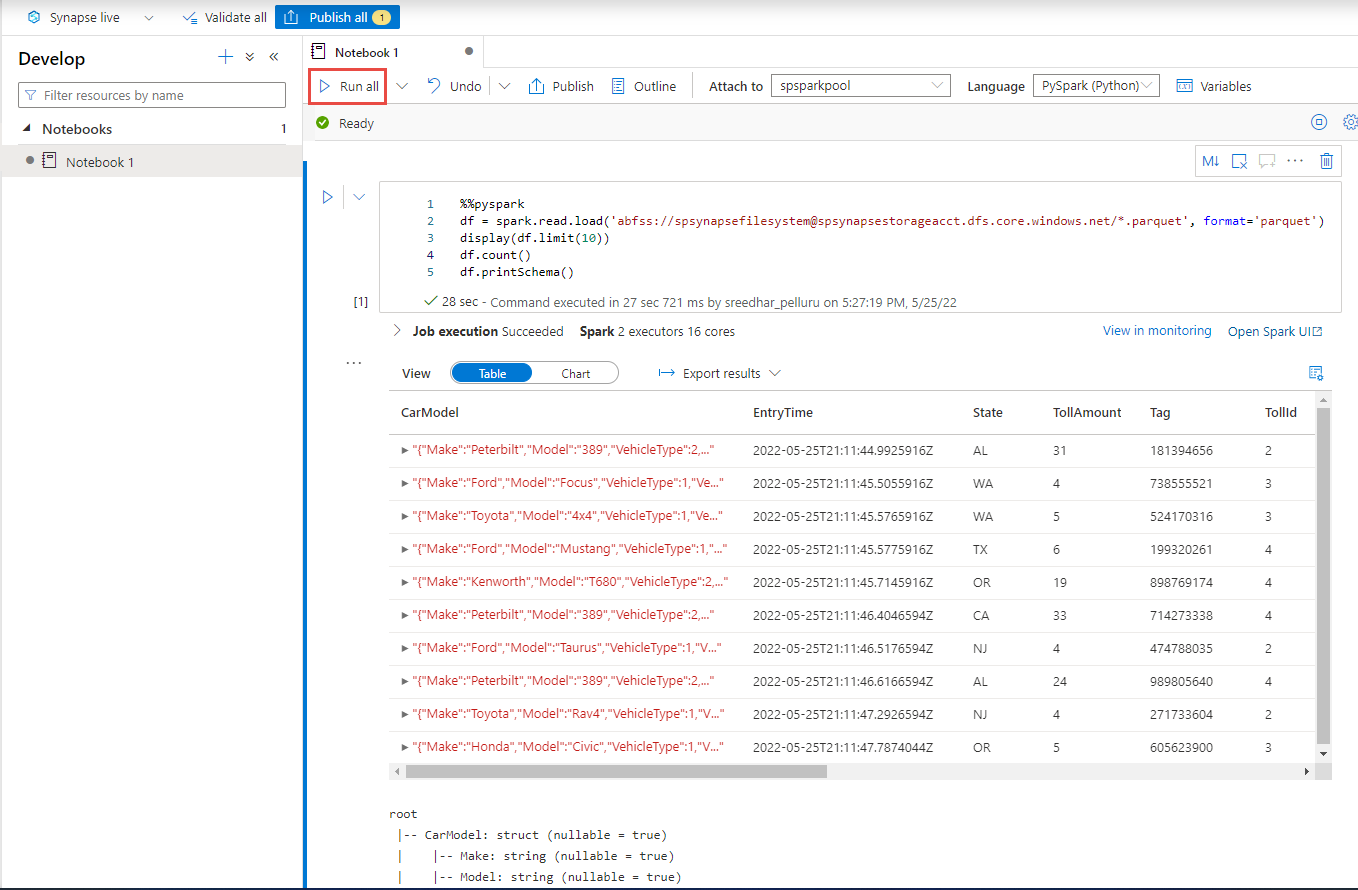
Vytvořte novou buňku kódu a vložte do této buňky následující kód. Nahraďte container a adlsname názvem kontejneru a účtu ADLS Gen2, který jste použili v předchozím kroku.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()V části Připojit k na panelu nástrojů vyberte v rozevíracím seznamu fond Sparku.
Pokud chcete zobrazit výsledky, vyberte Spustit vše .

Dotazování pomocí Azure Synapse bezserverového SQL
V centru Vývoj vytvořte nový skript SQL.
Vložte následující skript a spusťte ho pomocí integrovaného bezserverového koncového bodu SQL. Nahraďte container a adlsname názvem kontejneru a účtu ADLS Gen2, který jste použili v předchozím kroku.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]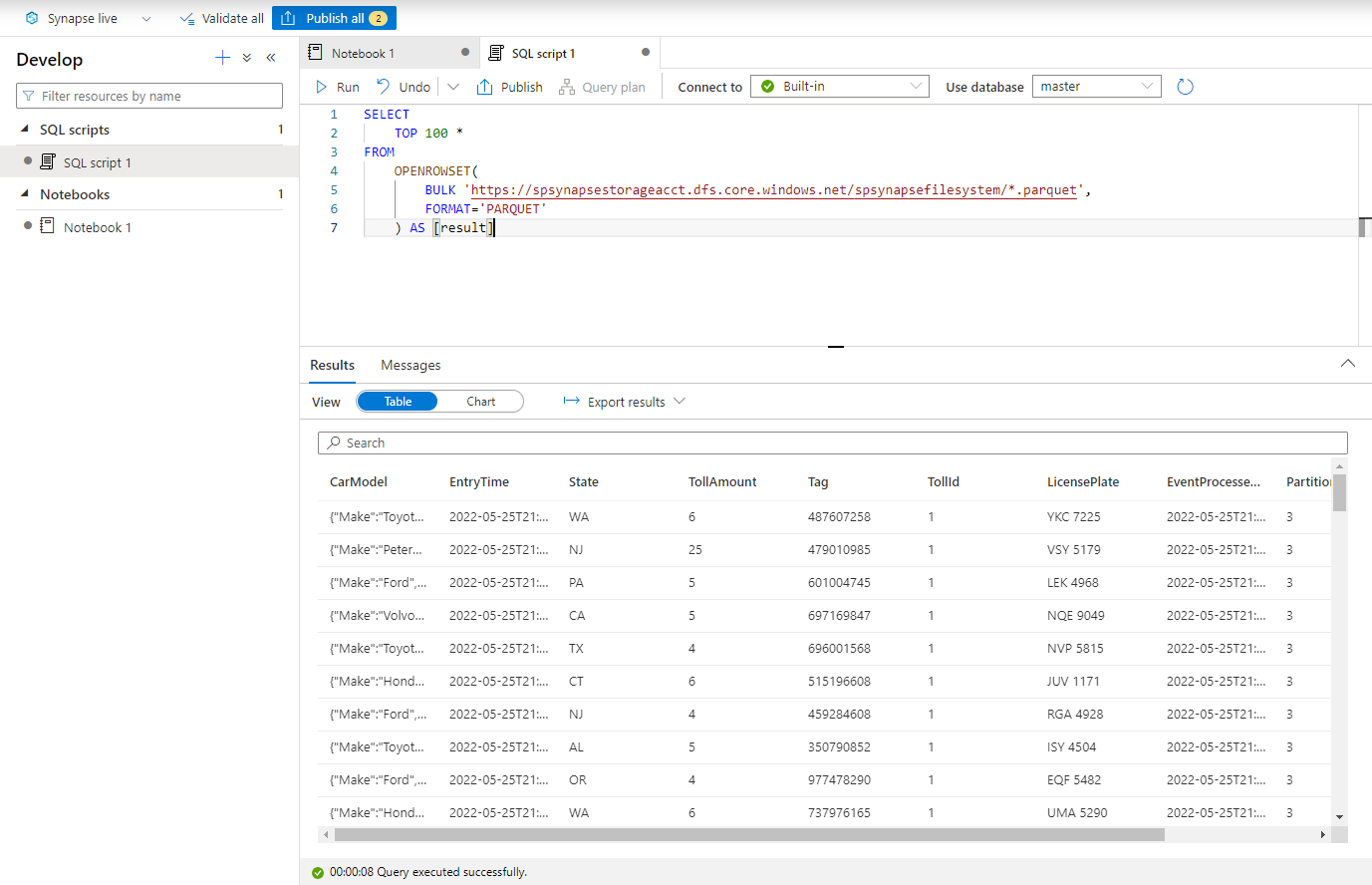

Vyčištění prostředků
- Vyhledejte instanci služby Event Hubs a podívejte se na seznam úloh Stream Analytics v části Zpracování dat . Zastavte všechny spuštěné úlohy.
- Přejděte do skupiny prostředků, kterou jste použili při nasazování generátoru událostí TollApp.
- Vyberte Odstranit skupinu prostředků. Odstranění potvrďte zadáním názvu skupiny prostředků.
Další kroky
V tomto kurzu jste zjistili, jak vytvořit úlohu Stream Analytics pomocí editoru bez kódu k zachycení datových proudů služby Event Hubs ve formátu Parquet. Pak jste použili Azure Synapse Analytics k dotazování souborů Parquet pomocí Synapse Sparku i Synapse SQL.