Antipattern přetížení vstupně-výstupních operací
Kumulativní efekt velkého počtu požadavků na vstupně-výstupní operace může mít závažný dopad na výkon a rychlost odezvy.
Popis problému
Volání sítě a jiné vstupně-výstupní operace jsou ze své podstaty ve srovnání s výpočetními úlohami pomalé. Každý požadavek na vstupně-výstupní operace má významné režijní náklady a kumulativní efekt početných vstupně-výstupních operací může systém zpomalit. Toto jsou časté příčiny většího množství vstupně-výstupních operací.
Čtení a zápis jednotlivých záznamů do databáze jako samostatných požadavků
Následující příklad čte z databáze produktů. Jsou tu tři tabulky: Product, ProductSubcategory a ProductPriceListHistory. Kód načte všechny produkty v podkategorii, společně s informacemi o cenách, spuštěním řady dotazů:
- Dotaz na podkategorii z tabulky
ProductSubcategory - Vyhledání všech produktů v dané podkategorii dotazováním na tabulku
Product - Dotaz pro každý produkt na informace o ceně z tabulky
ProductPriceListHistory
Aplikace používá k dotazování databáze rozhraní Entity Framework. Kompletní ukázku najdete tady.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
V tomto příkladu se problém ukazuje explicitně. Pokud ale O/RM implicitně načítá podřízené záznamy postupně, může problém maskovat. Tento problém se označuje jako „problém N+1“.
Implementace jedné logické operace jako řady požadavků HTTP
K této situaci často dochází, když se vývojáři pokouší sledovat objektově orientované paradigma a vzdálené objekty považují za místní objekty v paměti. Důsledkem může být příliš velký počet síťových přenosů. Například následující webové rozhraní API zveřejní jednotlivé vlastnosti objektů User prostřednictvím jednotlivých metod HTTP GET.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
I když na tomto přístupu není technicky nic špatného, většina klientů bude zřejmě muset pro každý objekt User načíst několik vlastností. Výsledkem pak bude takovýto klientský kód.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Čtení a zápis do souboru na disku
Vstupně-výstupní operace souboru zahrnují otevření souboru a přesunutí do odpovídajícího bodu před čtením nebo zápisem dat. Jakmile se operace dokončí, soubor se může zavřít, aby ušetřil prostředky operačního systému. Aplikace, která průběžně čte a zapisuje do souboru malá množství informací, generuje významné režijní náklady na vstupně-výstupní operace. Požadavky na zápisy menšího množství informací mohou dále vést k fragmentaci souboru a dalšímu zpomalení následných vstupně-výstupních operací.
Následující příklad používá k zápisu objektu Customer do souboru FileStream. Když se vytvoří FileStream, dojde k otevření souboru a po jeho uvolnění se soubor zavře. (Příkaz using automaticky odstraní FileStream objekt.) Pokud aplikace volá tuto metodu opakovaně při přidání nových zákazníků, může se režie vstupně-výstupních operací rychle nahromadět.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Jak problém vyřešit
Omezte počet vstupně-výstupních požadavků tak, že data zabalíte do menšího počtu větších požadavků.
Načítejte data z databáze prostřednictvím jednoho dotazu, nikoli několika menších dotazů. Tady je upravená verze kódu, který načítá informace o produktu.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Dodržujte principy návrhu REST pro webová rozhraní API. Tady je upravená verze webového rozhraní API z dřívějšího příkladu. Místo samostatných metod GET pro jednotlivé vlastnosti je tu jedna metoda GET, která vrací User. V důsledku toho je text odpovědi pro každý požadavek větší, ale jednotliví klienti budou pravděpodobně uskutečňovat menší počet volání rozhraní API.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
U vstupně-výstupních operací souboru zvažte uložení dat do vyrovnávací paměti a zápis těchto dat do souboru v rámci jedné operace. Tento přístup snižuje režijní náklady plynoucí z opakovaného otevírání a zavírání souboru a pomáhá snížit fragmentaci souboru na disku.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Důležité informace
První dva příklady uskutečňují menší počet volání vstupně-výstupních operací, každý z nich ale načítá více informací. Mezi těmito dvěma faktory je potřeba najít kompromis. Správná odpověď bude záviset na skutečném způsobu využití. U příkladu webového rozhraní API může třeba vyjít najevo, že klienti často potřebují jenom uživatelské jméno. V takovém případě může být vhodné ho zveřejnit prostřednictvím samostatného volání rozhraní API. Další informace najdete v tématu Antipattern nadbytečného načítání.
Při čtení dat nevytvářejte příliš velké požadavky na vstupně-výstupní operace. Aplikace by měla načíst jenom takové informace, které pravděpodobně bude používat.
Někdy pomáhá rozdělit informace pro objekt do dvou bloků dat – často používaná data, která se používají pro většinu požadavků, a méně často používaná data, která se používají zřídka. Často používaná data obvykle tvoří pouze relativně malou část celkových dat objektu. Vrácením pouze této části dat tak můžete režijní náklady na vstupně-výstupní operace značně ušetřit.
Při zápisu dat se vyhněte zamknutí prostředků na delší než nezbytnou dobu. Snížíte tak pravděpodobnost kolize během operace s delším průběhem. Pokud operace zápisu zahrnuje více úložišť dat, souborů nebo služeb, použijte konzistentní přístup. Projděte si pokyny pro konzistenci dat.
Pokud data před zápisem ukládáte do vyrovnávací paměti, jsou tato data v případě chyby procesu zranitelná. Pokud přenos dat obsahuje často shluky nebo je relativně zhuštěný, může být bezpečnější uložit data do vyrovnávací paměti v externí odolné frontě, např. ve službě Event Hubs.
Zvažte uložení dat, která se načítají ze služby nebo databáze, do mezipaměti. Může vám to pomoct snížit objem vstupně-výstupních operací, protože se vyhnete opakovaným požadavkům na stejná data. Další informace najdete v tématu Osvědčené postupy pro ukládání do mezipaměti.
Jak zjistit problém
Mezi příznaky přetížení vstupně-výstupních operací patří vysoká latence a nízká propustnost. Koncoví uživatelé budou pravděpodobně hlásit delší dobu odezvy nebo chyby způsobené vypršením časového limitu služeb v důsledku zvýšeného počtu kolizí prostředků vstupně-výstupních operací.
Následující postup vám pomůže identifikovat příčiny jakýchkoli problémů:
- Proveďte monitorování procesů produkčního systému. Můžete tak identifikovat operace s horšími dobami odezvy.
- Proveďte zátěžové testování každé operace identifikované v předchozím kroku.
- Během zátěžového testování shromažďujte telemetrická data týkající se požadavků na přístup k datům, které vytvořily jednotlivé operace.
- Shromážděte podrobné statistiky pro jednotlivé požadavky odeslané do úložiště dat.
- Profilujte aplikaci v testovacím prostředí, abyste zjistili, kde se mohou vyskytovat případné kritické body vstupně-výstupních operací.
Hledejte některý z těchto příznaků:
- Velký počet malých požadavků na vstupně-výstupní operace provedených vůči stejnému souboru
- Velký počet malých síťových požadavků provedených instancí aplikace vůči stejné službě
- Velký počet malých požadavků provedených instancí aplikace vůči stejnému úložišti dat
- Aplikace a služby vázané na vstupně-výstupní operace
Ukázková diagnostika
V následujících částech se tento postup použije pro příklad s dotazováním databáze uvedený dříve.
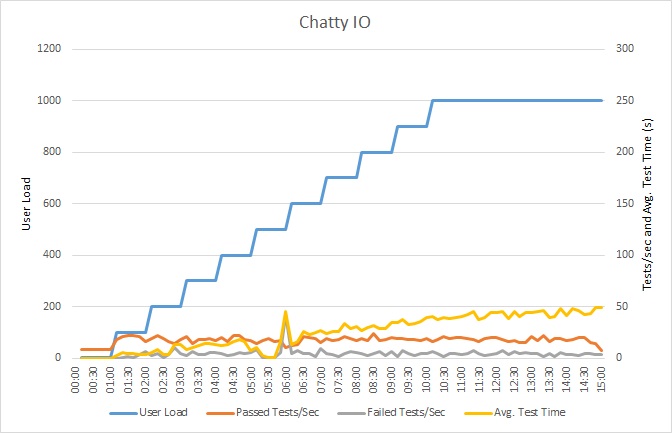
Zátěžový test aplikace
Tento graf znázorňuje výsledky zátěžového testování. Medián doby odezvy se měří v desítkách sekund na požadavek. Graf zobrazuje velmi vysokou latenci. Při zatížení 1000 uživateli může uživatel čekat na zobrazení výsledků dotazu téměř minutu.
Poznámka:
Aplikace byla nasazena jako webová aplikace služby Azure App Service pomocí služby Azure SQL Database. Zátěžový test použil simulované krokové zatížení až 1000 souběžných uživatelů. Databáze byla nakonfigurována s fondem připojení podporujícím až 1000 souběžných připojení, aby se snížila pravděpodobnost ovlivnění výsledků kolizemi připojení.
Monitorování aplikace
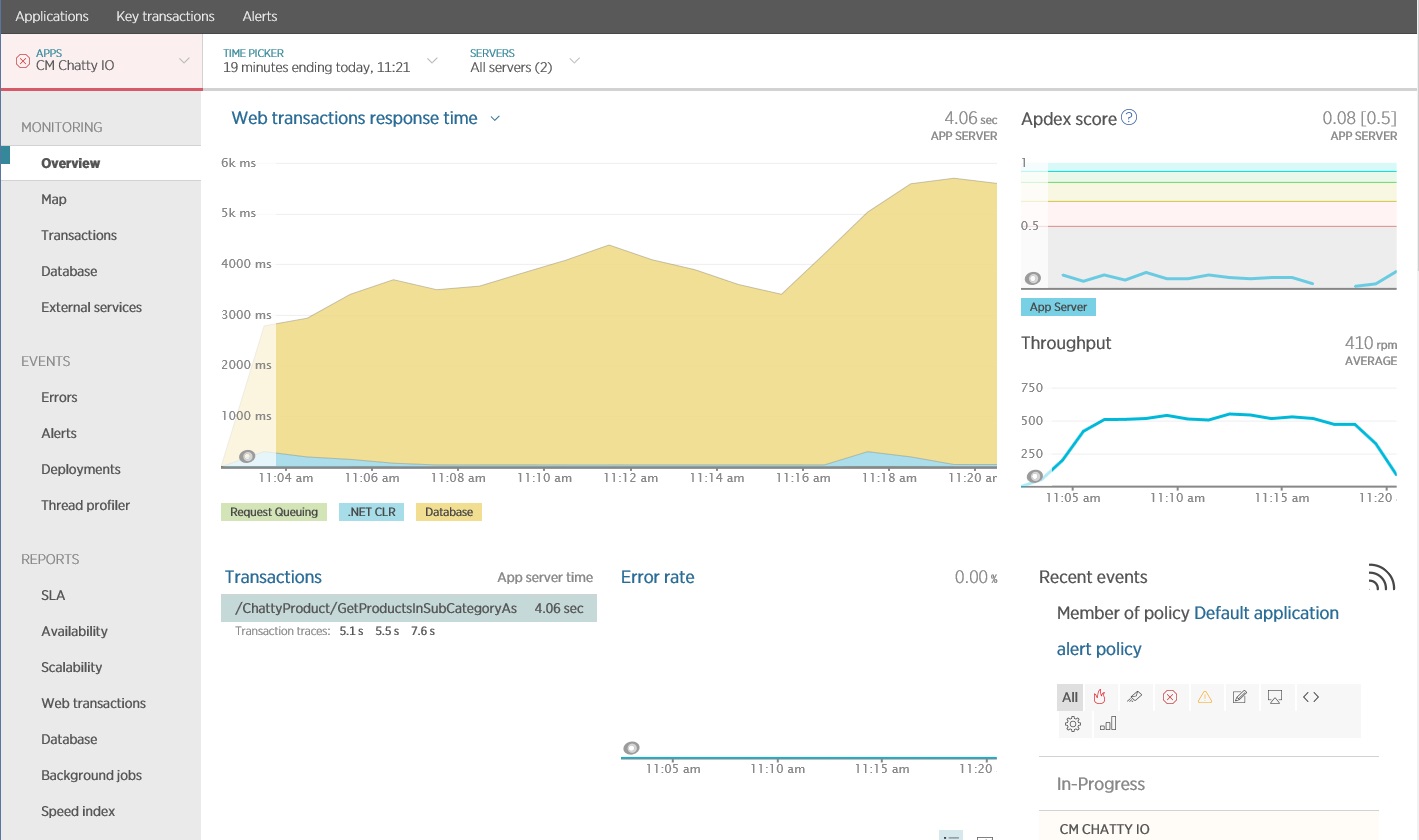
K zachycení a analýze klíčových metrik, které by mohly identifikovat přetížené vstupně-výstupní operace, můžete použít balíček APM (Application Performance Monitoring). To, které metriky jsou důležité, bude záviset na zatížení vstupně-výstupních operací. V tomto příkladu byly zajímavými požadavky na vstupně-výstupní operace databázové dotazy.
Následující obrázek zobrazuje výsledky vygenerované pomocí New Relic APM. Průměrná doba odezvy databáze dosáhla během maximálního zatížení svého maxima přibližně na hodnotě 5,6 sekundy na požadavek. Systém byl během testu schopný podporovat průměrně 410 požadavků za minutu.
Shromažďování podrobných informací o přístupu k datům
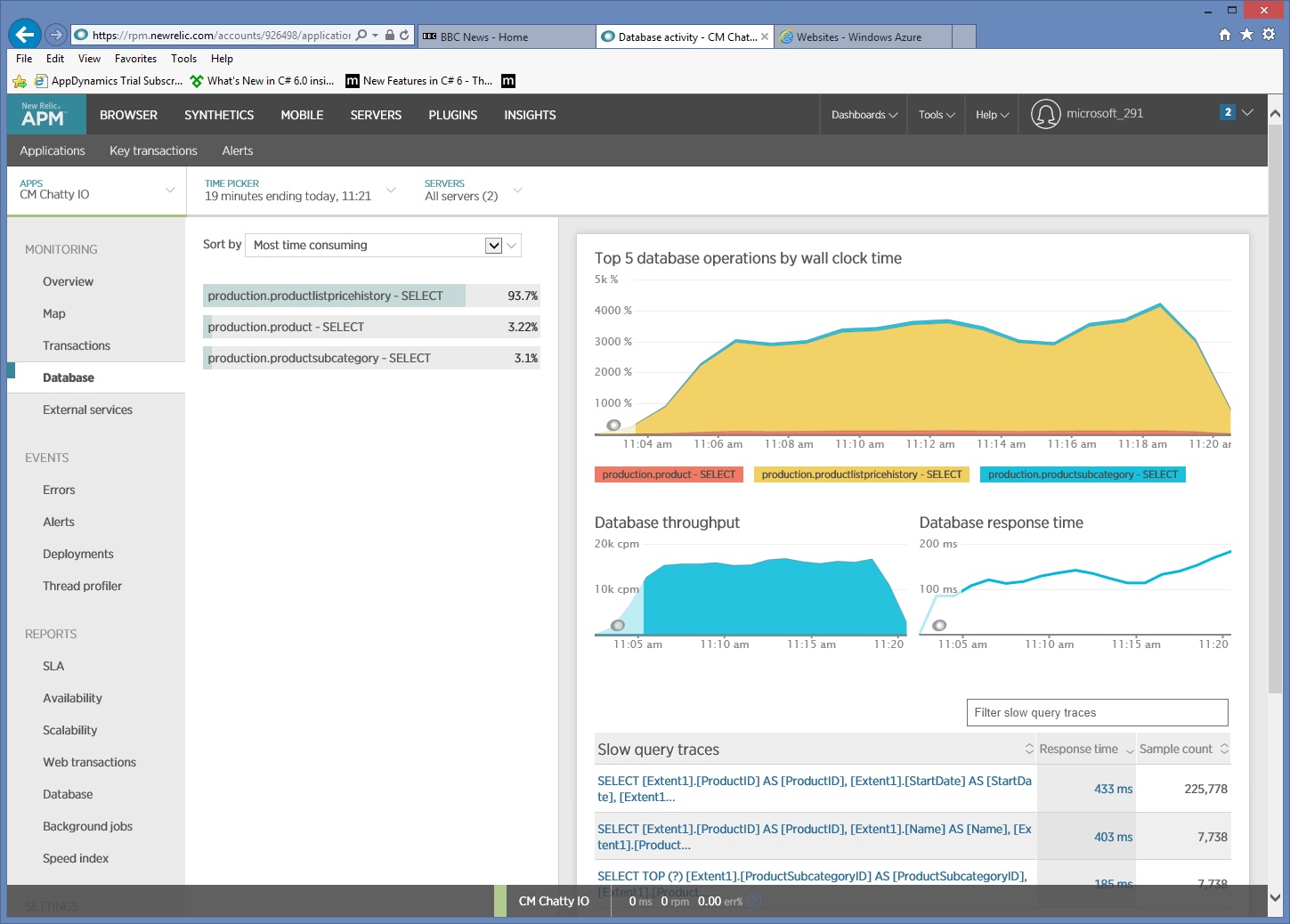
Při bližším pohledu na data monitorování vidíme, že aplikace provádí tři různé příkazy SQL SELECT. Tyto příkazy odpovídají požadavkům vygenerovaným rozhraním Entity Framework pro načtení dat z tabulek ProductListPriceHistory, Product a ProductSubcategory. Dotaz načítající data z tabulky ProductListPriceHistory je navíc řádově zdaleka nejčastěji spouštěným příkazem SELECT.
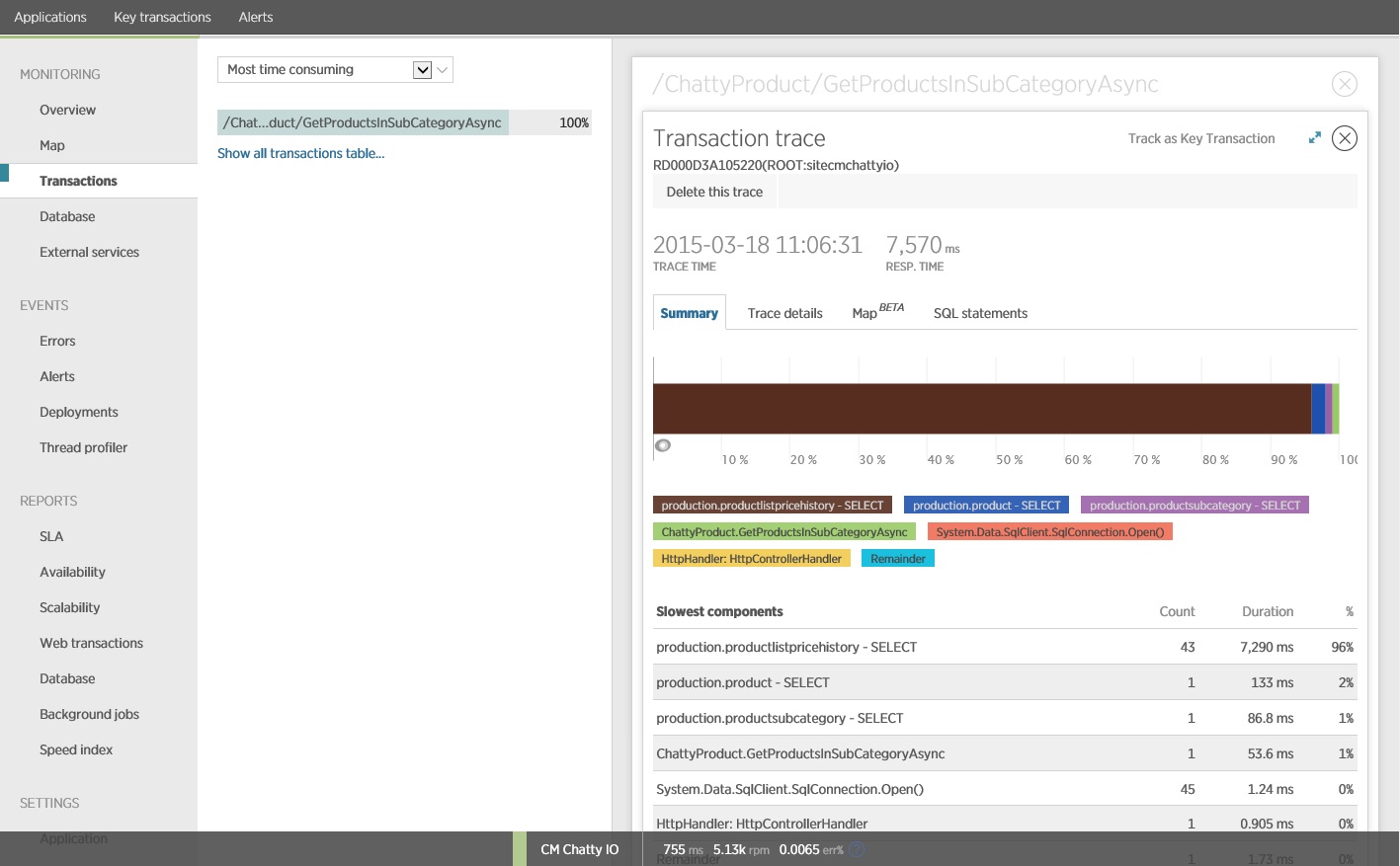
Ukazuje se, že metoda GetProductsInSubCategoryAsync uvedená výše provede 45 dotazů SELECT. Každý dotaz způsobí, že aplikace otevře nové připojení SQL.
Poznámka:
Tento obrázek zobrazuje informace o trasování pro nejpomalejší instanci operace GetProductsInSubCategoryAsync v zátěžovém testu. V produkčním prostředí je vhodné zkontrolovat trasování nejpomalejších instancí, abyste zjistili, jestli zde neexistuje vzor, který by naznačoval problém. Pokud se podíváte jen na průměrné hodnoty, můžete přehlédnout problémy, které se při zatížení výrazně zhorší.
Následující obrázek znázorňuje skutečné příkazy SQL, které byly vydány. Dotaz načítající informace o cenách se spouští pro jednotlivé produkty v podkategorii produktů. Spojením by se výrazně snížil počet volání databáze.
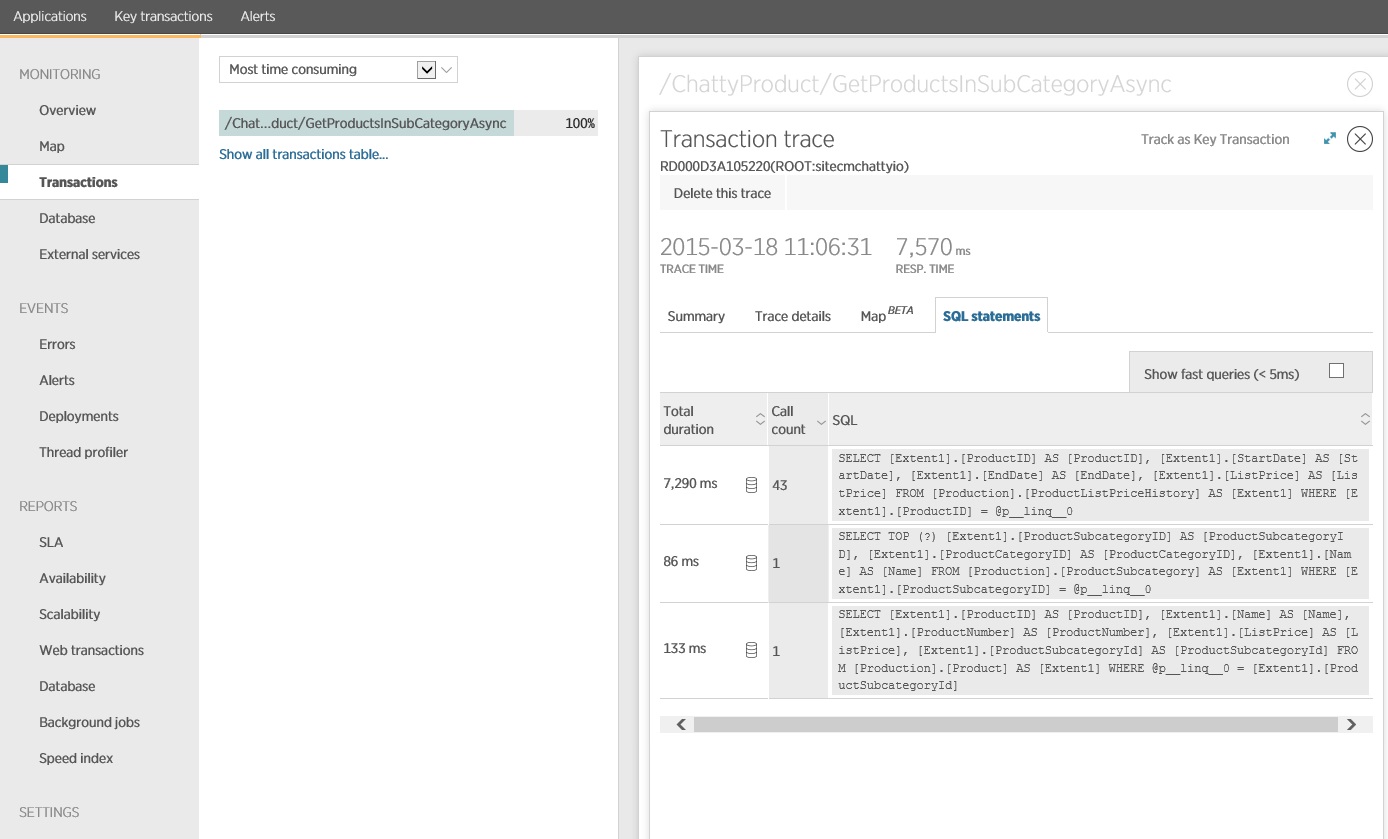
Pokud používáte O/RM, jako je například rozhraní Entity Framework, může vám trasování dotazů SQL poskytnout přehled o tom, jak O/RM převádí programová volání na příkazy SQL, a označit oblasti, ve kterých se dá přístup k datům optimalizovat.
Implementace řešení a ověření výsledku
Přepis volání do rozhraní Entity Framework vyprodukoval následující výsledky.
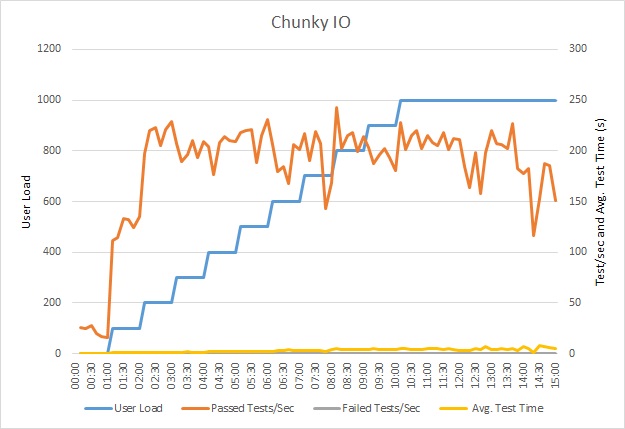
Tento zátěžový test proběhl ve stejném nasazení při použití stejného profilu zatížení. Graf tentokrát zobrazuje mnohem menší latenci. Průměrná doba požadavku při 1000 uživatelích je mezi 5 a 6 sekundami (v předchozím testu to byla skoro minuta).
Systém tentokrát podporoval průměrně 3970 požadavků za minutu (ve srovnání se 410 požadavky v předchozím testu).
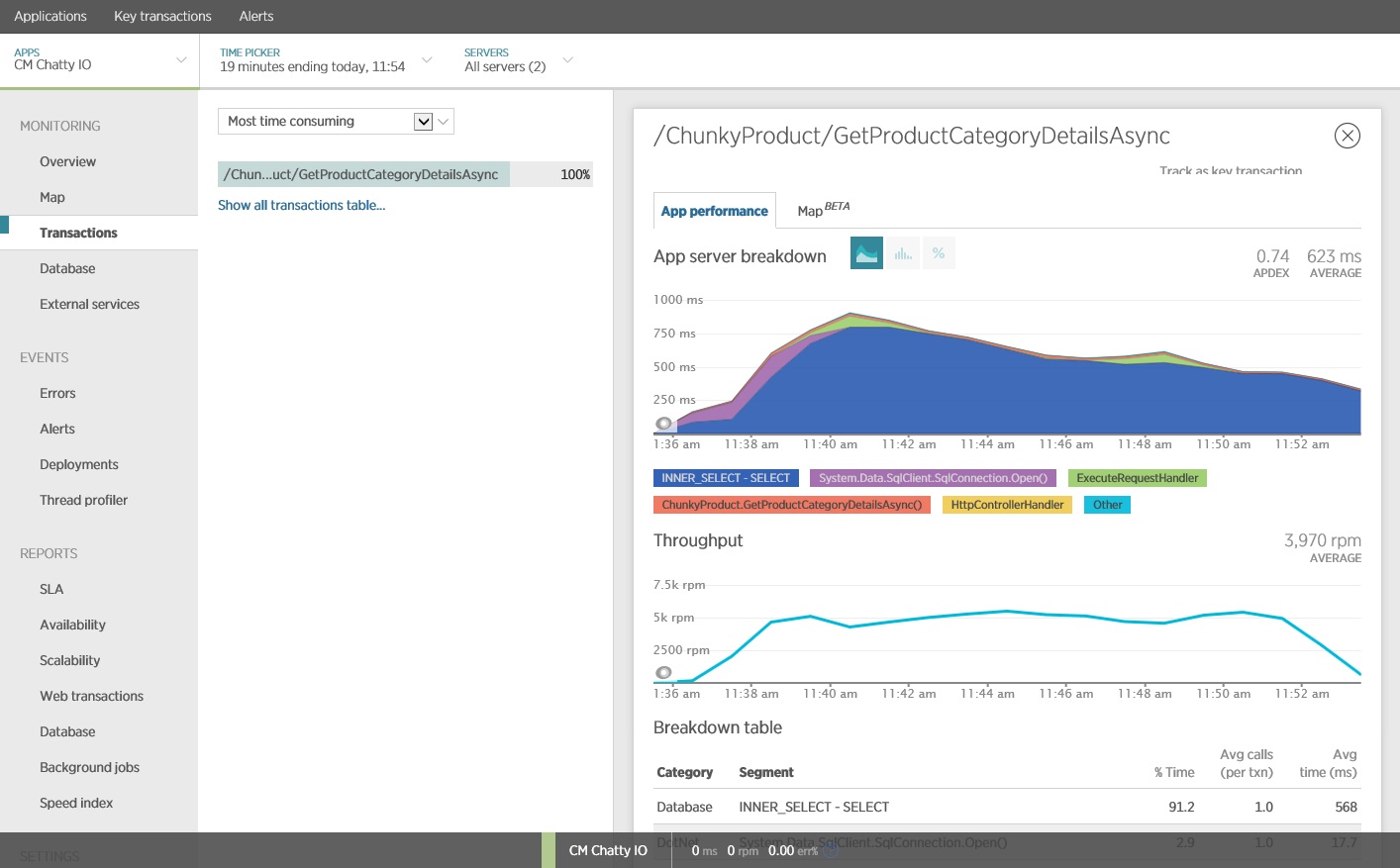
Trasování příkazu SQL ukazuje, že se všechna data načítají v jednom příkazu SELECT. Tento dotaz je sice podstatně složitější, ale provádí se v operaci jenom jednou. A i když mohou být složitá spojení nákladná, systémy relačních databází jsou pro tento typ dotazu optimalizované.

Související prostředky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro