Antipattern nadbytečného načítání
Anti-vzory jsou běžné chyby návrhu, které mohou narušit váš software nebo aplikace v situacích stresu a neměly by být přehlédnuty. Při nadbytečného načítání antipatternu se pro obchodní operaci načítá více než potřebná data, což často vede k zbytečným režijním nákladům na vstupně-výstupní operace a nižší odezvě.
Příklady nadbytečného načítání antipatternu
K tomuto antipatternu může docházet v případě, že se aplikace snaží minimalizovat počet požadavků na vstupně-výstupní operace načítáním všech dat, která může potřebovat. To je často důsledkem nadměrné kompenzace antipatternu přetížení vstupně-výstupních operací. Aplikace například může načítat podrobnosti o každém produktu v databázi. Uživatel však může potřebovat pouze podmnožinu těchto podrobností (některé nemusí být pro zákazníky důležité) a pravděpodobně nepotřebuje zobrazit všechny produkty najednou. I když uživatel prochází celý katalog, mělo by smysl stránkovat výsledky – například 20 najednou.
Dalším zdrojem tohoto problému je používání špatných postupů při vývoji nebo návrhu. Například následující kód používá Entity Framework k načtení kompletních podrobností o všech produktech. Výsledky pak filtruje a vrací pouze podmnožinu polí, přičemž zbytek zahodí. Kompletní ukázku najdete tady.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
V následujícím příkladu aplikace načítá data a provádí agregaci, kterou by místo ní mohla provádět databáze. Aplikace počítá celkový prodej tak, že získá všechny záznamy pro všechny objednávky a pak z těchto záznamů vypočítá celkové množství. Kompletní ukázku najdete tady.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
Další příklad ukazuje drobný problém způsobený tím, jak Entity Framework používá technologii LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Aplikace se pokouší vyhledat produkty, jejichž SellStartDate (Datum začátku prodeje) je starší než týden. Ve většině případů by technologie LINQ to Entities převedla klauzuli where na příkaz jazyka SQL, který provádí databáze. V tomto případě však technologie LINQ to Entities nemůže metodu AddDays mapovat na jazyk SQL. Místo toho se vrátí všechny řádky z tabulky Product a výsledky se filtrují v paměti.
Volání AsEnumerable naznačuje, že dochází k problému. Tato metoda převádí výsledky do rozhraní IEnumerable. I když IEnumerable podporuje filtrování, toto filtrování se provádí na straně klienta, a ne databáze. LINQ to Entities ve výchozím nastavení používá rozhraní IQueryable, které předává zodpovědnost za filtrování do zdroje dat.
Jak opravit antipattern nadbytečné načítání
Vyhněte se načítání velkých objemů dat, která můžou být rychle zastaralá nebo zahozená, a načítejte pouze data potřebná pro právě prováděnou operaci.
Místo získávání všech sloupců z tabulky a jejich následného filtrování vybírejte z databáze jen ty sloupce, které potřebujete.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Podobně agregaci provádějte v databázi, a ne v paměti aplikace.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Při použití Entity Framework se ujistěte, že jsou dotazy LINQ vyřešeny pomocí IQueryable rozhraní, a ne IEnumerable. Možná budete muset dotaz upravit tak, aby se v něm používaly pouze funkce, které je možné mapovat na zdroj dat. Předchozí příklad je možné refaktorovat a odebrat z dotazu metodu AddDays, což umožní, aby filtrování prováděla databáze.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Důležité informace
V některých případech můžete vylepšit výkon pomocí horizontálního dělení dat. V případě, že různé operace přistupují k různým atributům dat, muže horizontální dělení snížit množství kolizí. Často se stává, že se většina operací spouští pro malou podmnožinu dat, takže rozprostření zátěže může zlepšit výkon. Viz téma Dělení dat.
Pro operace, které musí podporovat neomezené dotazy, implementujte stránkování a načítejte pouze omezený počet entit najednou. Například když zákazník prochází katalog produktů, můžete zobrazovat jednotlivé stránky výsledků.
Pokud je to možné, využívejte integrované výhody úložiště dat. Například databáze SQL obvykle poskytují agregační funkce.
Pokud používáte úložiště dat, které nepodporuje nějakou konkrétní funkci, například agregaci, můžete vypočítaný výsledek uložit někam jinam a tuto hodnotu aktualizovat při přidání nebo aktualizaci záznamů. Aplikace tak nebude muset znovu počítat hodnotu pokaždé, když je potřeba.
Pokud zjistíte, že požadavky načítají velké množství polí, prozkoumejte zdrojový kód a určete, jestli jsou všechna tato pole skutečně nezbytná. Někdy jsou takové požadavky výsledkem špatně navrženého dotazu
SELECT *.Podobně požadavky, které načítají velké množství entit, můžou být znamením, že aplikace nefiltruje data správně. Ověřte, že všechny tyto entity jsou skutečně potřeba. Pokud je to možné, používejte filtrování na straně databáze, například pomocí klauzulí
WHEREv jazyce SQL.Snižování zátěže zpracování do databází není vždy nejlepší možností. Tuto strategii používejte, pouze pokud je k tomu databáze navržená nebo optimalizovaná. Většina databázových systémů je vysoce optimalizovaných pro určité funkce, ale nejsou navržené, aby fungovaly jako jádra aplikací pro obecné účely. Další informace najdete v tématu Antipattern zaneprázdněné databáze.
Jak zjistit antipattern nadbytečné načítání
Mezi příznaky nadbytečného načítání patří vysoká latence a nízká propustnost. Pokud se data načítají z úložiště dat, může se také zvyšovat množství kolizí. Koncoví uživatelé pravděpodobně hlásí delší dobu odezvy nebo chyby způsobené časovým limitem služeb. Tato selhání můžou vracet chyby HTTP 500 (interní server) nebo chyby HTTP 503 (Nedostupná služba). Zkontrolujte protokoly událostí webového serveru, které budou pravděpodobně obsahovat podrobnější informace o příčinách a okolnostech chyb.
Příznaky tohoto antipatternu a některá ze získaných telemetrických dat můžou být velmi podobné jako u antipatternu monolitické trvalosti.
Následující postup vám pomůže identifikovat příčinu problému:
- Identifikujte pomalé úlohy nebo transakce provedením zátěžového testování, monitorováním procesů nebo jinými metodami zachytávání dat instrumentace.
- Sledujte případné vzorce chování, které systém vykazuje. Existují nějaká konkrétní omezení z hlediska počtu transakcí za sekundu nebo množství uživatelů?
- Proveďte korelaci instancí pomalých úloh se vzorci chování.
- Identifikujte používaná úložiště dat. Pro každý zdroj dat spusťte telemetrii nižší úrovně a sledujte chování operací.
- Identifikujte všechny pomalé dotazy, které na tyto zdroje dat odkazují.
- Proveďte analýzu specifickou pro prostředky pomalých dotazů a zjistěte, jak se data používají a spotřebovávají.
Hledejte některý z těchto příznaků:
- Časté a velké požadavky na vstupně-výstupní operace prováděné na stejném prostředku nebo zdroji dat.
- Kolize ve sdíleném prostředku nebo úložišti dat.
- Operace, která často přijímá velké objemy dat přes síť.
- Aplikace a služby, které tráví značnou dobu čekáním na dokončení vstupně-výstupních operací.
Ukázková diagnostika
V následujících částech se tento postup použije pro předchozí příklady.
Identifikace pomalých úloh
Tento graf ukazuje výsledky výkonu ze zátěžového testu, který simuloval až 400 souběžných uživatelů spouštějících metodu GetAllFieldsAsync popsanou výše. Propustnost se pomalu snižuje s nárůstem zatížení. Průměrná doba odezvy se s nárůstem zatížení prodlužuje.

Zátěžový test pro operaci AggregateOnClientAsync vykazuje podobný vzorec. Množství požadavků je poměrně stabilní. Průměrná doba odezvy se s nárůstem zatížení prodlužuje, i když pomaleji než v předchozím grafu.

Korelace pomalých úloh se vzorci chování
Jakákoli korelace mezi normálním obdobím vysokého využití a zpomalováním výkonu může značit kritický bod. Pečlivě zkontrolujte profil výkonu funkce s podezřením na pomalost a určete, jestli odpovídá dříve provedenému zátěžovému testování.
Proveďte zátěžový test stejné funkce s použitím uživatelského krokového zatížení a zjistěte, kdy dochází k výraznému snížení výkonu nebo úplnému selhání. Pokud je tento okamžik v mezích předpokládaného reálného využití, prozkoumejte, jak je funkce implementovaná.
Pomalá operace nemusí nutně představovat problém, pokud se neprovádí, když je systém vytížený, není náročná na rychlou odezvu a nemá negativní vliv na výkon jiných důležitých operací. Například generování měsíčních provozních statistik může být dlouhotrvající operace, ale pravděpodobně je možné ji provádět jako dávkové zpracování a spouštět jako úlohu s nízkou prioritou. Na druhé straně dotazování katalogu produktů zákazníky představuje klíčovou obchodní operaci. Zaměřte se na telemetrii generovanou těmito klíčovými operacemi a zjistěte, jak se výkon mění během období vysokého využití.
Identifikace zdrojů dat v pomalých úlohách
Pokud máte podezření, že je špatný výkon služby způsobený tím, jak načítá data, prozkoumejte, jak aplikace komunikuje s úložišti, která používá. Monitorujte systém za provozu a zjistěte, ke kterým zdrojům se přistupuje během období špatného výkonu.
Pro každý zdroj dat instrumentujte systém tak, aby zachytával následující informace:
- Frekvence přístupu k jednotlivých úložištím dat.
- Objem dat přicházejících do úložiště dat a odcházejících z něj.
- Načasování těchto operací, zejména latence požadavků.
- Povaha a četnost všech chyb, ke kterým dochází při přístupu k jednotlivým úložištím dat při obvyklém zatížení.
Tyto informace porovnejte s objemem dat vracených aplikací do klienta. Sledujte poměr obejmu dat vrácených úložištěm dat a dat vrácených do klienta. Pokud zjistíte velký nepoměr, proveďte šetření a určete, jestli aplikace nenačítá data, která nepotřebuje.
Tato data možná budete moci zachytávat sledováním systému za provozu a trasováním životního cyklu jednotlivých požadavků uživatele. Případně můžete vymodelovat sérii umělých úloh a spouštět je v testovacím systému.
Následující grafy ukazují telemetrická data zachycená pomocí New Relic APM během zátěžového testu metody GetAllFieldsAsync. Všimněte si rozdílů mezi objemy dat přijatých z databáze a odpovídajícími odpověďmi HTTP.

Pro každý požadavek databáze vrátila 80 503 bajtů, ale odpověď do klienta obsahovala pouze 19 855 bajtů, což je přibližně 25 % velikost odpovědi databáze. Velikost dat vrácených do klienta se může lišit v závislosti na formátu. Pro účely tohoto zátěžového testu klient vyžádal data ve formátu JSON. Při samostatném testování s použitím XML (není zobrazené) byla velikost odpovědi 35 655 bajtů neboli 44 % velikosti odpovědi databáze.
Zátěžový test pro metodu AggregateOnClientAsync vykazuje ještě extrémnější výsledky. V tomto případě každý test provedl dotaz, který z databáze načetl více než 280 kB dat, ale odpověď JSON měla pouhých 14 bajtů. Tento velký rozdíl je způsobený tím, že metoda počítá agregovaný výsledek z velkého objemu dat.
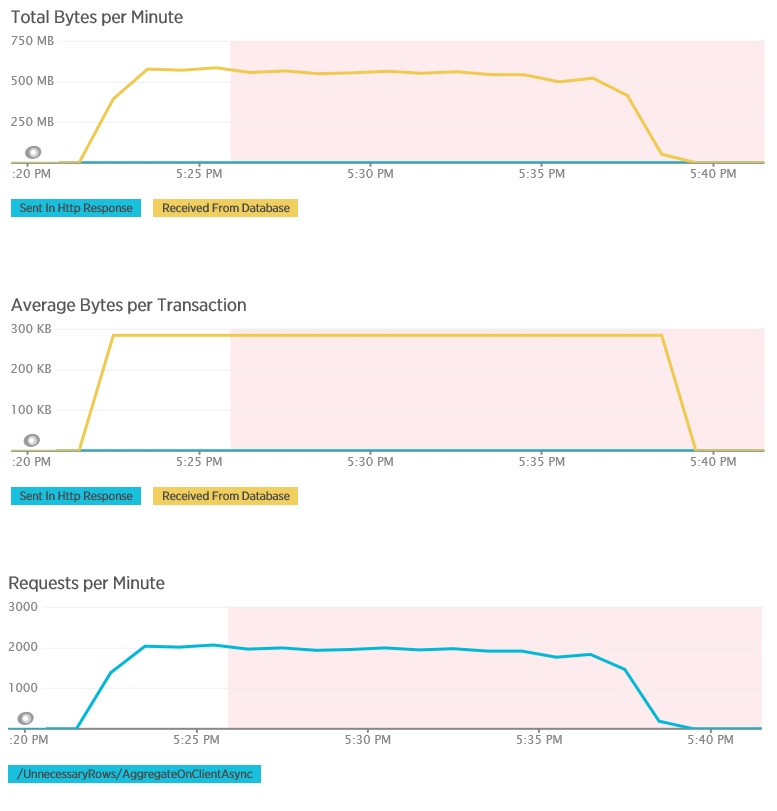
Identifikace a analýza pomalých dotazů
Hledejte databázové dotazy, které spotřebovávají nejvíce prostředků a jejichž provedení trvá nejdéle. Můžete přidat instrumentaci, pomocí které zjistíte časy spuštění a dokončení řady databázových operací. Řada úložišť dat také poskytuje podrobné informace o způsobu provádění a optimalizace dotazů. Například v podokně Výkon dotazu na portálu pro správu Azure SQL Database můžete vybrat nějaký dotaz a zobrazit podrobné informace o výkonu modulu runtime. Tady je dotaz vygenerovaný operací GetAllFieldsAsync:

Implementace řešení a ověření výsledku
Po změně metody GetRequiredFieldsAsync tak, aby používala příkaz SELECT na straně databáze, ukázalo zátěžové testování následující výsledky.
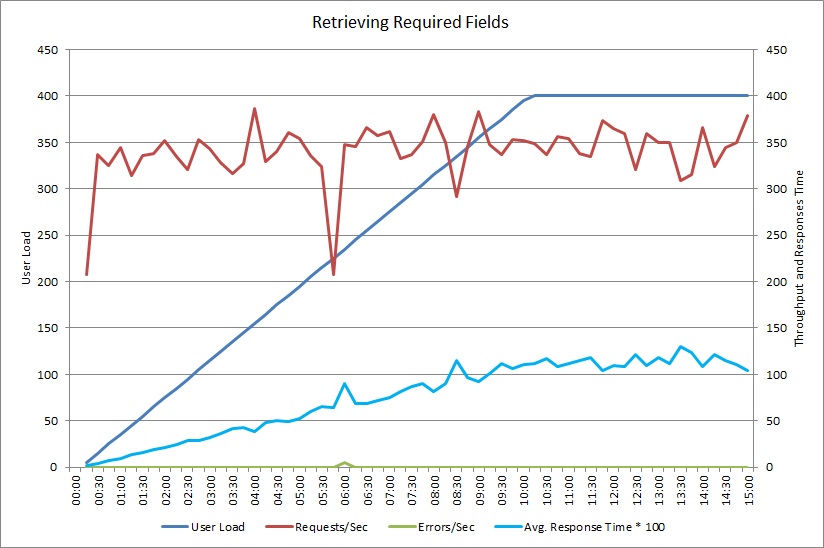
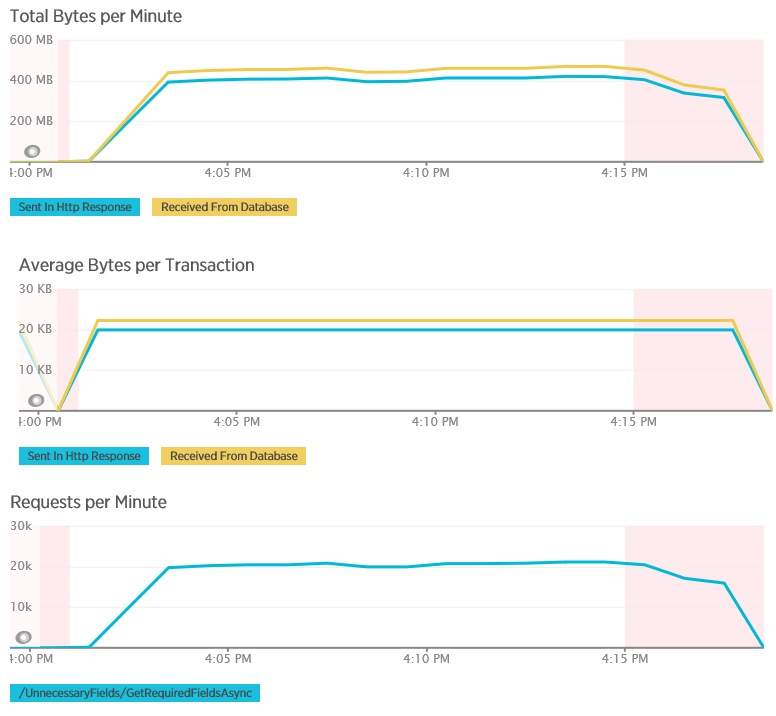
Při tomto zátěžovém testu se použilo stejné nasazení a stejné simulované zatížení 400 souběžných uživatelů jako v předchozím případě. Graf ukazuje mnohem nižší latenci. Doba odezvy se s nárůstem zatížení prodlužuje až na přibližně 1,3 sekundy v porovnání se 4 sekundami v předchozím případě. Propustnost je také vyšší – 350 požadavků za sekundu v porovnání se 100 v předchozím případě. Objem dat načtených z databáze teď do značné míry odpovídá velikosti zpráv s odpověďmi HTTP.
Zátěžové testování s použitím metody AggregateOnDatabaseAsync vygenerovalo následující výsledky:
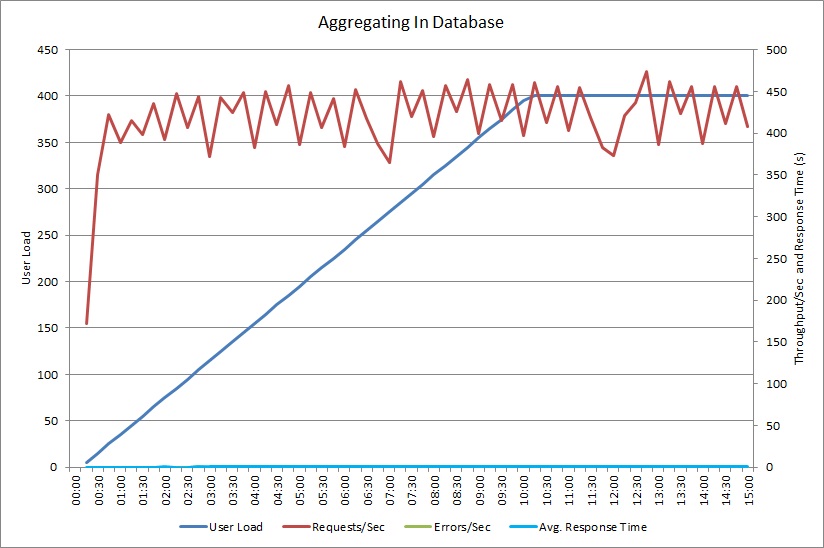
Průměrná doba odezvy je teď nejnižší. Jedná se o řádové zlepšení výkonu způsobené především výrazným snížením množství vstupně-výstupních operací na straně databáze.
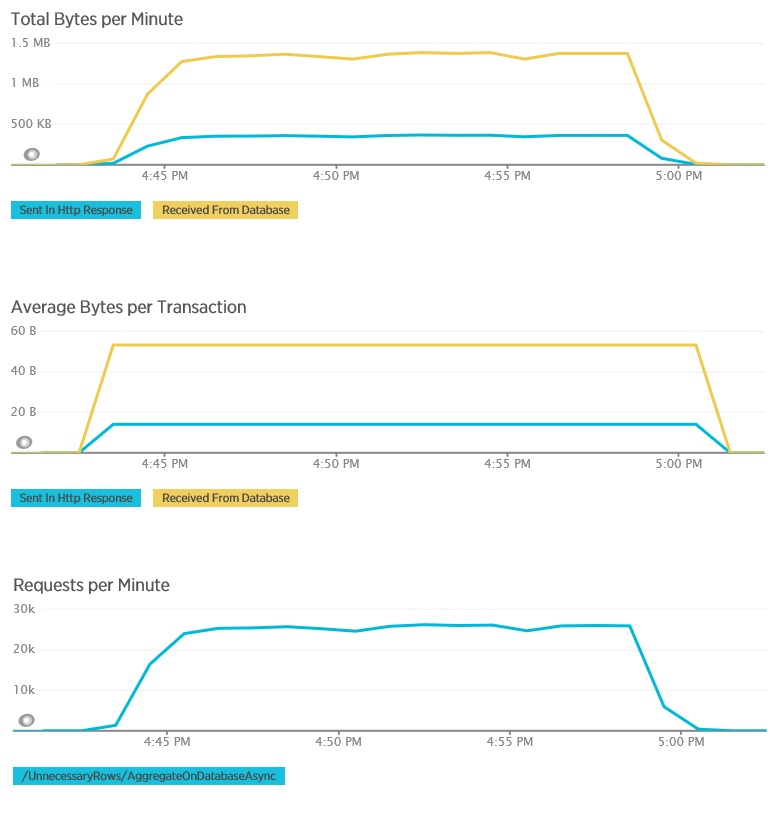
Tady je odpovídající telemetrie pro metodu AggregateOnDatabaseAsync. Objem dat načtených z databáze se výrazně snížil, a to z více než 280 kB na transakci na 53 bajtů. Ve výsledku se maximální udržitelný počet požadavků za minutu zvýšil z přibližně 2 000 na více než 25 000.
Související prostředky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro