Zpracování přirozeného jazyka (NLP) má mnoho použití: analýzu mínění, rozpoznávání témat, rozpoznávání jazyka, extrakci klíčových frází a kategorizaci dokumentů.
Konkrétně můžete použít NLP k:
- Klasifikovat dokumenty Dokumenty můžete například označovat jako citlivé nebo spamové.
- Proveďte následné zpracování nebo vyhledávání. Pro tyto účely můžete použít výstup NLP.
- Sumarizovat text identifikací entit, které jsou v dokumentu.
- Označte dokumenty klíčovými slovy. Pro klíčová slova může NLP používat identifikované entity.
- Umožňuje vyhledávání a načítání na základě obsahu. Díky označování je tato funkce možná.
- Shrnutí důležitých témat dokumentu NLP může zkombinovat identifikované entity do témat.
- Kategorizovat dokumenty pro navigaci Pro tento účel používá NLP zjištěná témata.
- Vytvořte výčet souvisejících dokumentů na základě vybraného tématu. Pro tento účel používá NLP zjištěná témata.
- Určení skóre pro mínění Pomocí této funkce můžete vyhodnotit pozitivní nebo negativní tón dokumentu.
Apache®, Apache Spark a logo plamene jsou registrované ochranné známky nebo ochranné známky nadace Apache Software Foundation v USA a/nebo v jiných zemích. Použití těchto značek nevyžaduje žádné doporučení Apache Software Foundation.
Potenciální případy použití
Mezi obchodní scénáře, které můžou těžit z vlastního NLP, patří:
- Ručně psané nebo strojově vytvořené dokumenty v oblasti financí, zdravotnictví, maloobchodu, státní správy a dalších sektorů
- Úlohy NLP nezávislé na oboru pro zpracování textu, jako je rozpoznávání entit názvů (NER), klasifikace, sumarizace a extrakce relací. Tyto úlohy automatizují proces načítání, identifikace a analýzy informací o dokumentech, jako jsou textová a nestrukturovaná data. Mezi příklady těchto úloh patří modely stratifikace rizik, klasifikace ontologie a souhrny maloobchodního prodeje.
- Vytváření sémantických vyhledávání v grafu informací a vytváření znalostních grafů Tato funkce umožňuje vytvářet grafy lékařských znalostí, které podporují zjišťování léků a klinické studie.
- Překlad textu pro konverzační systémy AI v zákaznických aplikacích napříč maloobchodem, financemi, cestováními a dalšími odvětvími
Apache Spark jako přizpůsobená architektura NLP
Apache Spark je architektura paralelního zpracování, která podporuje zpracování v paměti za účelem zvýšení výkonu analytických aplikací pro velké objemy dat. Azure Synapse Analytics, Azure HDInsight a Azure Databricks nabízejí přístup ke Sparku a využívají jeho výpočetní výkon.
Pro přizpůsobené úlohy NLP slouží Spark NLP jako efektivní architektura pro zpracování velkého množství textu. Tato opensourcová knihovna NLP poskytuje knihovny Pythonu, Javy a Scaly, které nabízejí úplné funkce tradičních knihoven NLP, jako jsou spaCy, NLTK, Stanford CoreNLP a Open NLP. Spark NLP také nabízí funkce, jako je kontrola pravopisu, analýza mínění a klasifikace dokumentů. Spark NLP zlepšuje předchozí úsilí tím, že poskytuje nejmodernější přesnost, rychlost a škálovatelnost.
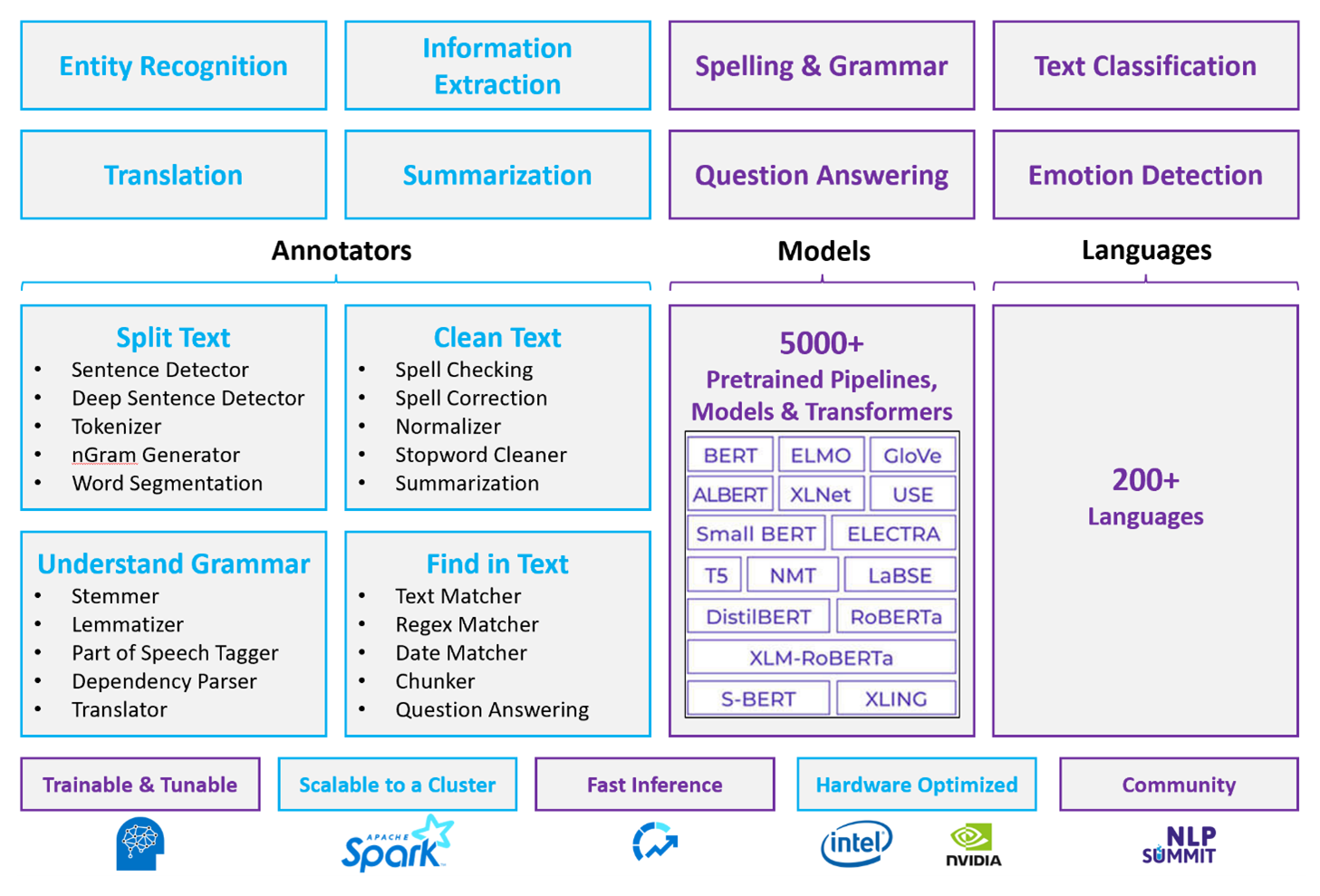
Nedávné veřejné srovnávací testy ukazují Spark NLP jako 38 a 80krát rychlejší než spaCy s srovnatelnou přesností pro trénování vlastních modelů. Spark NLP je jediná opensourcová knihovna, která může používat distribuovaný cluster Spark. Spark NLP je nativní rozšíření Spark ML, které pracuje přímo na datových rámcích. Výsledkem je, že zrychlení v clusteru vede k dalšímu rozsahu zvýšení výkonu. Vzhledem k tomu, že každý kanál Spark NLP je kanál Spark ML, je NLP pro vytváření sjednocených kanálů NLP a strojového učení vhodných pro vytváření sjednocených kanálů NLP a strojového učení, jako je klasifikace dokumentů, predikce rizik a doporučovací kanály.
Kromě vynikajícího výkonu přináší Spark NLP také nejmodernější přesnost pro rostoucí počet úloh NLP. Tým Spark NLP pravidelně čte nejnovější relevantní akademické dokumenty a implementuje nejmodernější modely. V posledních dvou až třech letech používaly modely s nejlepším výkonem hluboké učení. Knihovna obsahuje předem připravené modely hlubokého učení pro rozpoznávání pojmenovaných entit, klasifikaci dokumentů, detekci mínění a emocí a detekci vět. Knihovna obsahuje také desítky předem natrénovaných jazykových modelů, které zahrnují podporu pro vkládání slov, bloků dat, vět a dokumentů.
Knihovna optimalizovala sestavení pro procesory, GPUS a nejnovější čipy Intel Xeon. Procesy trénování a odvozování můžete škálovat, abyste mohli využívat clustery Spark. Tyto procesy se můžou spouštět v produkčním prostředí na všech oblíbených analytických platformách.
Problémy
- Zpracování kolekce bezplatných textových dokumentů vyžaduje značné množství výpočetních prostředků. Zpracování je také časově náročné. Tyto procesy často zahrnují nasazení výpočetních prostředků GPU.
- Bez standardizovaného formátu dokumentu může být obtížné dosáhnout konzistentně přesných výsledků při použití bezplatného zpracování textu k extrakci konkrétních faktů z dokumentu. Představte si například textovou reprezentaci faktury – může být obtížné vytvořit proces, který správně extrahuje číslo faktury a datum, když jsou faktury od různých dodavatelů.
Klíčová kritéria výběru
Služby Sparku, jako jsou Azure Databricks, Azure Synapse Analytics a Azure HDInsight, poskytují funkce NLP, když je používáte se Spark NLP. Služba Azure Cognitive Services je další možností pro funkce NLP. Pokud se chcete rozhodnout, kterou službu použít, zvažte tyto otázky:
Chcete použít předem připravené nebo předem natrénované modely? Pokud ano, zvažte použití rozhraní API, která nabízí azure Cognitive Services. Nebo si stáhněte model podle výběru prostřednictvím Spark NLP.
Potřebujete trénovat vlastní modely proti velkému korpusu textových dat? Pokud ano, zvažte použití Azure Databricks, Azure Synapse Analytics nebo Azure HDInsight se Spark NLP.
Potřebujete funkce NLP nízké úrovně, jako je tokenizace, stemming, lemmatizace a frekvence/inverzní frekvence dokumentů (TF/IDF)? Pokud ano, zvažte použití Azure Databricks, Azure Synapse Analytics nebo Azure HDInsight se Spark NLP. Nebo použijte opensourcovou softwarovou knihovnu ve zvoleném nástroji pro zpracování.
Potřebujete jednoduché funkce NLP vysoké úrovně, jako je identifikace entit a záměrů, detekce témat, kontrola pravopisu nebo analýza mínění? Pokud ano, zvažte použití rozhraní API, která služba Cognitive Services nabízí. Nebo si stáhněte model podle výběru prostřednictvím Spark NLP.
Matice schopností
Následující tabulky shrnují klíčové rozdíly ve schopnostech služeb NLP.
Obecné možnosti
| Schopnost | Služba Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) se Spark NLP | Azure Cognitive Services |
|---|---|---|
| Poskytuje předem natrénované modely jako službu. | Ano | Yes |
| REST API | Ano | Yes |
| Programovatelnost | Python, Scala | Informace o podporovaných jazycích najdete v tématu Další zdroje informací. |
| Podporuje zpracování sad velkých objemů dat a velkých dokumentů. | Yes | No |
Možnosti NLP nízké úrovně
| Funkce anotátorů | Služba Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) se Spark NLP | Azure Cognitive Services |
|---|---|---|
| Detektor vět | Yes | No |
| Detektor hluboké věty | Ano | Yes |
| Tokenizátor | Ano | Yes |
| Generátor N-gram | Yes | No |
| Segmentace slov | Ano | Yes |
| Stemmer | Yes | No |
| Lemmatizer | Yes | No |
| Označování částí řeči | Yes | No |
| Analyzátor závislostí | Yes | No |
| Překlad | Yes | No |
| Čistič stopek | Yes | No |
| Oprava pravopisu | Yes | No |
| Normalizer | Ano | Yes |
| Text matcher | Yes | No |
| TF/IDF | Yes | No |
| Porovnávání regulárních výrazů | Ano | Vložené ve službě Language Understanding Service (LUIS). Nepodporuje se v modulu CLU (Conversational Language Understanding), který nahrazuje službu LUIS. |
| Matcher data | Ano | Možné ve službě LUIS a CLU prostřednictvím rozpoznávání data a času |
| Chunker | Yes | No |
Možnosti NLP vysoké úrovně
| Schopnost | Služba Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) se Spark NLP | Azure Cognitive Services |
|---|---|---|
| Kontrolu pravopisu | Yes | No |
| Souhrn | Ano | Yes |
| Odpovídání na dotazy | Ano | Yes |
| rozpoznávání mínění, | Ano | Yes |
| Detekce emocí | Ano | Podporuje dolování názorů |
| Klasifikace tokenů | Ano | Ano, prostřednictvím vlastních modelů |
| Klasifikace textu | Ano | Ano, prostřednictvím vlastních modelů |
| Reprezentace textu | Yes | No |
| NER | Ano | Ano – analýza textu poskytuje sadu NER a vlastní modely jsou v rozpoznávání entit. |
| rozpoznávání entit, | Ano | Ano, prostřednictvím vlastních modelů |
| Rozpoznávání jazyka | Ano | Yes |
| Podporuje jazyky kromě angličtiny. | Ano, podporuje více než 200 jazyků. | Ano, podporuje více než 97 jazyků. |
Nastavení Spark NLP v Azure
Pokud chcete nainstalovat Spark NLP, použijte následující kód, ale nahraďte <version> ho číslem nejnovější verze. Další informace najdete v dokumentaci k NLP sparku.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Vývoj kanálů NLP
Pro pořadí provádění kanálu NLP se Spark NLP řídí stejným konceptem vývoje jako tradiční modely strojového učení Spark ML. Spark NLP ale používá techniky NLP.
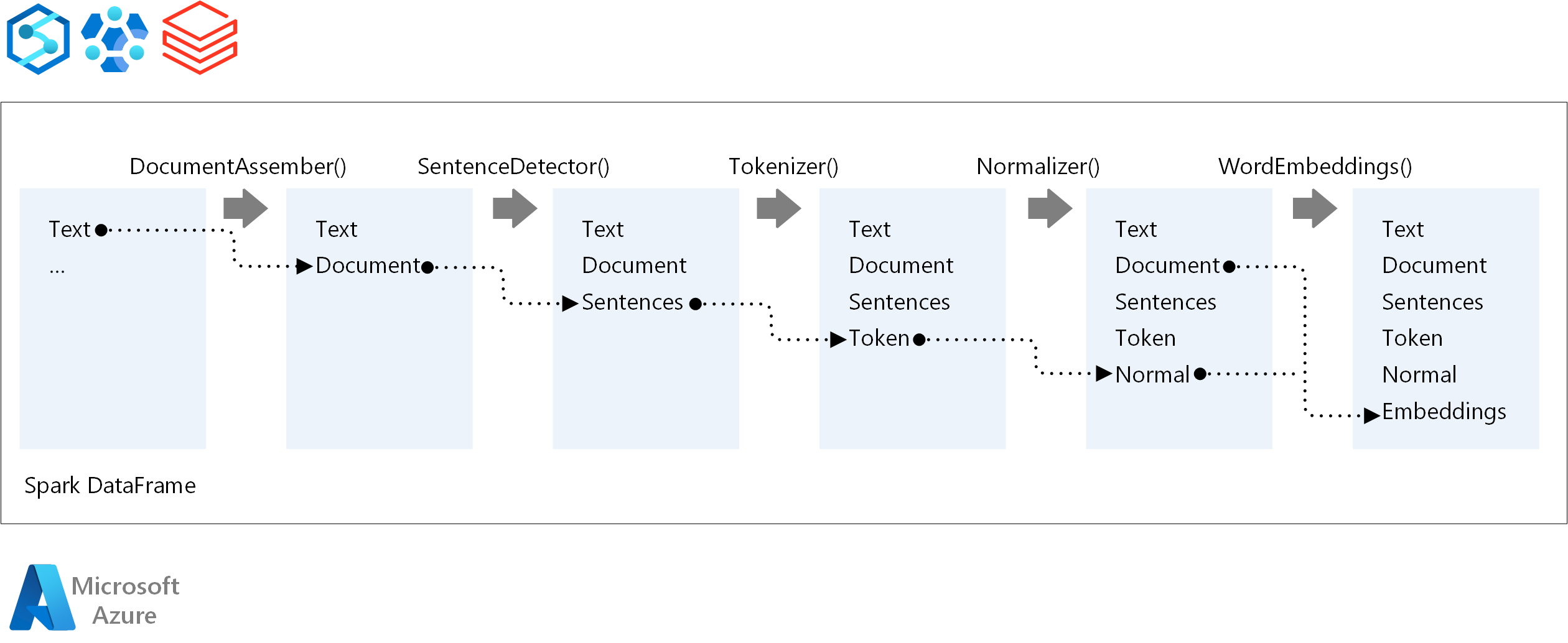
Základní komponenty kanálu Spark NLP jsou:
DocumentAssembler: Transformátor, který připraví data tak, že je změní na formát, který může Spark NLP zpracovat. Tato fáze je vstupním bodem pro každý kanál Spark NLP. DocumentAssembler může číst
Stringsloupec nebo .Array[String]Můžete použítsetCleanupModek předběžnému zpracování textu. Ve výchozím nastavení je tento režim vypnutý.SentenceDetector: Annotator, který zjišťuje hranice vět pomocí přístupu, který je daný. Tento anotátor může vrátit každou extrahovaný větu v objektu
Array. Pokud nastavíteexplodeSentenceshodnotu true, může tato věta vrátit i každou větu v jiném řádku.Tokenizátor: Anotátor, který odděluje nezpracovaný text na tokeny, nebo jednotky, jako jsou slova, čísla a symboly, a vrací tokeny ve struktuře
TokenizedSentence. Tato třída není fitovaná. Pokud se hodí tokenizátor, interníRuleFactorypoužívá vstupní konfiguraci k nastavení pravidel tokenizace. Tokenizer používá otevřené standardy k identifikaci tokenů. Pokud výchozí nastavení nevyhovuje vašim potřebám, můžete přidat pravidla pro přizpůsobení tokenizátoru.Normalizer: Annotator, který vyčistí tokeny. Normalizátor vyžaduje kmeny. Normalizátor používá regulární výrazy a slovník k transformaci textu a odebrání nezašpiněných znaků.
WordEmbeddings: Look-up annotators that map tokens to vectors. Můžete použít
setStoragePathk zadání vlastního vyhledávacího slovníku tokenů pro vkládání. Každý řádek slovníku musí obsahovat token a jeho vektorové znázornění oddělené mezerami. Pokud se ve slovníku nenajde token, je výsledkem nulový vektor stejné dimenze.
Spark NLP používá kanály Spark MLlib, které MLflow nativně podporuje. MLflow je opensourcová platforma pro životní cyklus strojového učení. Mezi její komponenty patří:
- Mlflow Tracking: Zaznamenává experimenty a poskytuje způsob dotazování výsledků.
- Projekty MLflow: Umožňuje spouštět kód datových věd na libovolné platformě.
- Modely MLflow: Nasadí modely do různých prostředí.
- Registr modelů: Spravuje modely, které ukládáte v centrálním úložišti.
MLflow je integrovaný v Azure Databricks. MLflow můžete nainstalovat do libovolného jiného prostředí založeného na Sparku a sledovat a spravovat experimenty. Registr modelů MLflow můžete také použít k zpřístupnění modelů pro produkční účely.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Moritz Steller | Vedoucí architekt cloudových řešení
- Zoiner Tejada | Generální ředitel a architekt
Další kroky
Dokumentace ke SparkU NLP:
Komponenty Azure:
Zdroje informací:
Související prostředky
- Rozsáhlé vlastní zpracování přirozeného jazyka v Azure
- Volba technologie služeb Microsoft Cognitive Services
- Porovnání produktů a technologií strojového učení od Microsoftu
- MLflow a Azure Machine Learning
- Rozšiřování umělé inteligence pomocí zpracování obrázků a přirozeného jazyka ve službě Azure Cognitive Search
- Analýza informačních kanálů pomocí analýzy téměř v reálném čase pomocí zpracování obrázků a přirozeného jazyka
- Návrhy značek obsahu s využitím NLP s využitím hloubkového učení