Architektura velkých objemů dat je navržená tak, aby umožňovala příjem, zpracování a analýzu dat, která jsou pro tradiční databázové systémy příliš rozsáhlá nebo složitá. Prahová hodnota, při které organizace vstupují do světa velkých objemů dat, se můžou lišit v závislosti na schopnostech uživatelů a jejich nástrojích. Někdy se může jednat o stovky gigabajtů dat, jindy zase o stovky terabajtů. Vzhledem k tomu, že se nástroje pro práci s velkými datovými sadami posunou, znamená to význam velkých objemů dat. Tento termín čím dál tím víc označuje spíš hodnotu, kterou můžete ze svých datových sad získat díky pokročilým analýzám, než jenom velikost dat, i když v těchto případech většinou bývají poměrně velká.
V průběhu let se svět dat proměňuje. Změnilo se to, co můžete s daty provádět a co se od vás očekává. Náklady na úložiště výrazně klesly, zatímco neustále možnosti shromažďování dat se neustále rozšiřují. Některá data přibývají rychlým tempem a vyžadují ustavičné shromažďování a pozorování. Další data přibývají pomaleji, ale zato ve velkých blocích, často v podobě historických dat za desítky let. Můžete se setkat s problémem, který vyžaduje pokročilou analýzu nebo třeba strojové učení. Právě takovéto výzvy se snaží překonávat architektury pro velké objemy dat.
Řešení pro velká data obvykle zahrnují jeden nebo více z následujících typů úloh:
- Dávkové zpracování zdrojů velkých objemů dat v klidovém stavu.
- Zpracování velkých objemů dat v reálném čase za provozu.
- Interaktivní zkoumání velkých objemů dat.
- Prediktivní analýza a strojové učení.
Architektury pro velké objemy dat můžete zvážit, když potřebujete provádět tyto úkony:
- Ukládání a zpracování dat v objemech, které jsou pro tradiční databázi příliš velké.
- Transformace nestrukturovaných dat pro analýzu a vytváření sestav.
- Zachycování, zpracování a analýza streamů dat bez vazby v reálném čase nebo s nízkou latencí.
Komponenty architektury pro velké objemy dat
Následující diagram znázorňuje logické komponenty, které patří do architektury pro velký objem dat. Konkrétní řešení nemusí obsahovat všechny položky v tomto diagramu.
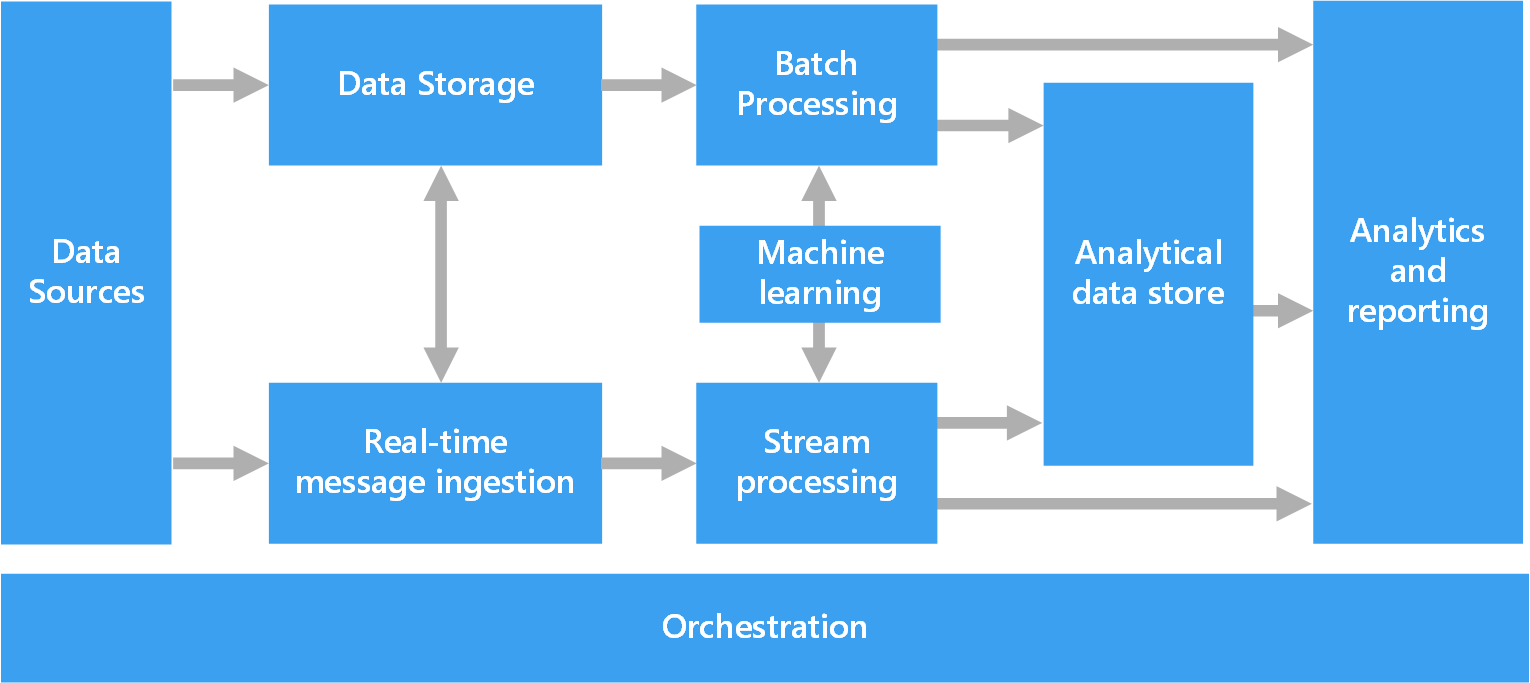
Většina architektur s velkými objemy dat zahrnuje některé nebo všechny z následujících součástí:
Zdroje dat. Všechna řešení pro velké objemy dat začínají s jedním nebo více zdroji dat. Příkladem může být:
- Úložiště dat aplikací, například relační databáze.
- Statické soubory vytvořené aplikacemi, například soubory protokolu webového serveru.
- Zdroje dat v reálném čase, například zařízení IoT.
Úložiště dat – Data pro operace dávkového zpracování jsou obvykle uložená v distribuovaném úložišti souborů, které může obsahovat velké objemy rozsáhlých souborů v různých formátech. Tomuto druhu úložiště se často říká data lake. Mezi možnosti implementace tohoto úložiště patří služba Azure Data Lake Store nebo kontejnery objektů blob ve službě Azure Storage.
Dávkové zpracování. Jelikož jsou sady dat velmi velké, řešení pro velké objemy dat musí často zpracovávat datové soubory pomocí dlouhotrvajících dávkových úloh filtrování, agregace a další přípravy dat pro analýzu. Tyto úlohy obvykle zahrnují čtení zdrojových souborů, jejich zpracování a zápis výstupu do nových souborů. Mezi možnosti patří spouštění úloh U-SQL ve službě Azure Data Lake Analytics, použití Hive, Pig nebo vlastních úloh mapování/zmenšování v clusteru HDInsight Hadoop, případně použití programů v jazycích Java, Python nebo Scala v clusteru HDInsight Spark.
Přijímání zpráv v reálném čase. Pokud řešení obsahuje zdroje v reálném čase, architektura musí obsahovat způsob, jak zprávy v reálném čase zachycovat a ukládat pro zpracování streamů. Může se jednat o jednoduché úložiště dat, ve kterém se příchozí zprávy zařazují do složky ke zpracování. Mnoho řešení však potřebuje úložiště pro příjem zpráv, které by mělo funkci vyrovnávací paměti pro zprávy a podporovalo zpracování škálování na více instancí, spolehlivé doručování a další sémantiku řízení front zpráv. Tato část architektury streamování se často označuje jako ukládání datového proudu do vyrovnávací paměti. Mezi možnosti patří Azure Event Hubs, Azure IoT Hub a Kafka.
Zpracování streamů. Po zachycení zpráv v reálném čase je řešení musí zpracovat filtrováním, agregací a další přípravou dat pro analýzu. Zpracovaná data streamu se poté zapíšou do výstupní jímky. Azure Stream Analytics poskytuje spravovanou službu zpracování streamů založenou na soustavném zadávání dotazů SQL, které pracují se streamy bez vazby. Můžete také použít opensourcové technologie streamování Apache, jako je Streamování Sparku v clusteru HDInsight.
Strojové učení. Ke čtení připravených dat pro analýzu (ze dávkového zpracování nebo zpracování datových proudů) je možné použít algoritmy strojového učení k vytváření modelů, které mohou předpovídat výsledky nebo klasifikovat data. Tyto modely je možné vytrénovat na velkých datových sadách a výsledné modely je možné použít k analýze nových dat a vytváření předpovědí. Můžete to provést pomocí služby Azure Machine Učení
Úložiště analytických dat. Mnoho řešení pro velké objemy dat připravuje data pro analýzu a pak zpracovaná data předává ve strukturovaném formátu, na který je možné zadávat dotazy pomocí analytických nástrojů. Úložištěm analytických dat používaným k předávání těchto dotazů může být datový sklad relačních dat typu Kimball, jak je vidět ve většině tradičních řešení business intelligence. Alternativně se data můžou předávat prostřednictvím technologie NoSQL s nízkou latencí, jako je například HBase, nebo přes interaktivní databázi Hive, která poskytuje abstrakci metadat pro datové soubory v distribuovaném úložišti dat. Azure Synapse Analytics nabízí spravované služby pro rozsáhlé datové sklady cloudového typu. HDInsight podporuje technologie Interactive Hive, HBase a Spark SQL, které je možné použít i pro předávání dat k analýze.
Analýza a vytváření sestav. Cílem většiny řešení pro velké objemy dat je poskytnout přehled o datech prostřednictvím analýzy a vytváření sestav. Architektura může obsahovat vrstvu modelování dat, například krychli v multidimenzionálním režimu OLAP nebo tabulkový datový model v Azure Analysis Services, aby uživatelům umožnila analýzu dat. Může podporovat i samoobslužné funkce business intelligence s použitím technologií modelování a vizualizace v Microsoft Power BI nebo Microsoft Excelu. Analýza a vytváření sestav může mít také podobu interaktivního zkoumání dat odborníky přes data nebo datovými analytiky. V případě těchto scénářů mnoho služeb Azure podporuje analytické poznámkové bloky, například Jupyter, které těmto uživatelům umožňují využívat stávající znalosti Pythonu nebo R. Při zkoumání velkých objemů dat můžete použít Microsoft R Server buď samostatně, nebo se Sparkem.
Orchestrace. Většina řešení pro velké objemy dat sestává z operací opakovaného zpracování dat zapouzdřených v pracovních postupech, které transformují zdrojová data, přesouvají data mezi více zdroji a jímkami, načítají zpracovaná data do úložiště analytických dat nebo předávají výsledky přímo do sestavy nebo na řídicí panel. K automatizaci těchto pracovních postupů můžete použít technologii orchestrace, například Azure Data Factory nebo Apache Oozie a Sqoop.
Architektura Lambda
Při práci s velmi velkými datovými sadami může spuštění takových dotazů, jaké klient potřebuje, trvat dlouhou dobu. Tyto dotazy se nedají provést v reálném čase a často vyžadují algoritmy, jako je MapReduce, které pracují paralelně napříč celou datovou sadu. Výsledky se potom ukládají odděleně od nezpracovaných dat a používají se k dotazování.
Jednou z nevýhod tohoto přístupu je, že představuje latenci – pokud zpracování trvá několik hodin, dotaz může vrátit výsledky, které jsou staré několik hodin. Vy byste ale raději získali nějaké výsledky v reálném čase (klidně i s určitou ztrátou přesnosti) a zkombinovali je s výsledky dávkových analýz.
Tento problém řeší architektura lambda, se kterou jako první přišel Nathan Marz a která vytváří dvě cesty toku dat. Těmito dvěma cestami procházejí všechna data, která přicházejí do systému:
Dávková vrstva (studená cesta) ukládá všechna příchozí data v nezpracované formě a provádí dávkové zpracování dat. Výsledek tohoto zpracování se ukládá jako dávkové zobrazení.
Rychlostní vrstva (horká cesta) analyzuje data v reálném čase. Tato vrstva je určená pro nízkou latenci, ovšem na úkor přesnosti.
Dávková vrstva ústí do obslužné vrstvy, která indexuje dávkové zobrazení za účelem efektivního dotazování. Rychlostní vrstva přidává do obslužné vrstvy přírůstkové aktualizace založené na nejnovějších datech.
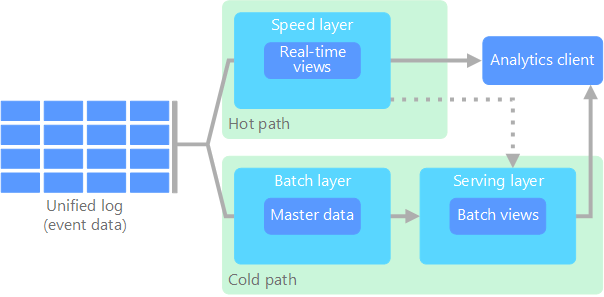
Data, která proudí do horké cesty, jsou omezená požadavky na latenci kladenými rychlostní vrstvou, takže je možné je zpracovat co nejrychleji. To často určitý kompromis z hlediska přesnosti, ovšem ve prospěch toho, že jsou data k dispozici co nejrychleji. Představte si například scénář IoT, ve kterém velké množství senzorů teploty odesílá telemetrická data. Ke zpracování klouzavého časového období příchozích dat může sloužit rychlostní vrstva.
Data odesílaná do studené cesty na druhou stranu nepodléhají stejným požadavkům na nízkou latenci. To umožňuje přesnější výpočty napříč velkými datovými sadami, což může být velmi časově náročné.
Horká a studená cesta se nakonec sbíhají v analytické klientské aplikaci. Když klient potřebuje rychle zobrazit data v reálném čase, i když možná s menší přesností, získá výsledek z horké cesty. V opačném případě si zvolí výsledky ze studené cesty a zobrazí méně aktuální, ale o to přesnější data. Jinak řečeno, horká cesta obsahuje data za relativně krátké období, po jehož uplynutí se dají výsledky aktualizovat pomocí přesnějších dat ze studené cesty.
Nezpracovaná data uložená v dávkové vrstvě se nedají měnit. Příchozí data se vždycky připojí k existujícím datům a předchozí data se nikdy nepřepisují. Všechny změny hodnoty určitého data se ukládají v podobě záznamu události s novým časovým razítkem. Díky tomu se dá v kterémkoli časovém bodě historie shromážděných dat provést nový výpočet. Možnost přepočtu dávkového zobrazení na základě původních nezpracovaných dat je důležitá, protože se díky ní dají s rozvíjením systému vytvářet nová zobrazení.
Architektura Kappa
Nevýhodou architektury lambda je její složitost. Logika zpracování se zobrazuje na dvou různých místech – studených a horkých cest – pomocí různých architektur. To vede k duplicitní výpočetní logice a složité správě architektury pro obě cesty.
Jay Kreps navrhl jako alternativu k architektuře lambda architekturu kappa. Ta má stejné základní cíle jako architektura lambda, ale s jedním zásadním rozdílem: všechna data prochází stejnou cestou využívající systém zpracování datových proudů.
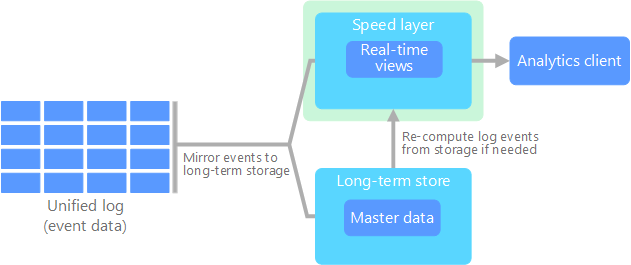
Existují tu určité podobnosti s dávkovou vrstvou architektury lambda, konkrétně v tom, že data událostí jsou neměnná a shromažďují se všechna, ne jenom jejich podmnožina. Data přijímá sjednocený protokol s tolerancí vůči chybám ve formě datového proudu událostí. Tyto události jsou seřazené a aktuální stav události se mění jenom tak, že se připojí nová událost. Podobně jako u rychlostní vrstvy architektury lambda probíhá veškeré zpracování událostí na vstupním datovém proudu a znázorňuje se v zobrazení v reálném čase.
Když potřebujete přepočítat celou datovou sadu (což se podobá tomu, co dělá dávková vrstva v architektuře lambda), jednoduše datový proud znovu přehrajete, většinou paralelně, aby se výpočet dokončil včas.
Internet věcí (IoT)
Z praktického hlediska představuje internet věcí (IoT) veškerá zařízení připojená k internetu. Patří sem váš počítač, mobilní telefon, chytré hodinky, chytrý termostat, chytrá lednice, automobil s připojením k internetu, implantáty monitorující srdeční činnost a cokoli dalšího, co se připojuje k internetu a odesílá nebo přijímá data. Počet připojených zařízení každým dnem roste, stejně jako množství dat, která se z nich shromažďují. Tato data se často shromažďují ve vysoce omezených prostředích, někdy s vysokou latencí. V ostatních případech data odesílají z prostředí s nízkou latencí tisíce nebo miliony zařízení, takže je potom potřeba data rychle přijmout a odpovídajícím způsobem zpracovat. Proto je potřeba důkladné plánování, aby se těmto omezením a jedinečným požadavkům vyhovělo.
Architektury založené na událostech se soustředí na řešení IoT. Následující diagram znázorňuje možnou logickou architekturu pro IoT. Diagram zvýrazňuje komponenty streamování událostí v rámci architektury.

Cloudová brána ingestuje události zařízení na hranici cloudu pomocí spolehlivého systému zasílání zpráv s nízkou latencí.
Zařízení můžou odesílat události přímo do cloudové brány, nebo prostřednictvím hraniční brány. Hraniční brána je specializované zařízení nebo software, je obvykle umístěná společně se zařízeními, přijímá události a předává je cloudové bráně. Hraniční brána může také události předběžně zpracovávat a provádět funkce, jako je například filtrování, agregace nebo transformace protokolu.
Po ingestování události procházejí jedním nebo více procesory streamu, které můžou směrovat data (například do úložiště) nebo provádět analýzy a další zpracování.
Toto jsou některé běžné typy zpracování. (Tento seznam určitě není vyčerpávající.)
Zápis dat událostí do studeného úložiště pro archivaci nebo dávkovou analýzu
Analýza kritické cesty, analyzující stream událostí v (téměř) reálném čase, slouží k detekci anomálií, rozpoznávání vzorů v klouzavých časových oknech nebo aktivaci upozornění, pokud dojde ve streamu k určitým podmínkám
Zpracování speciálních typů zpráv bez telemetrie ze zařízení, jako jsou oznámení a výstrahy
Strojové učení
Pole, která jsou šedá, zobrazují komponenty systému IoT, které přímo nesouvisejí se streamováním událostí, ale jsou zde uvedené pro úplnost.
Registr zařízení je databáze obsahující zřízená zařízení včetně ID zařízení a obvykle metadat zařízení, jako je například umístění.
Rozhraní API zřizování je běžné externí rozhraní pro zřizování a registraci nových zařízení.
Některá řešení IoT umožňují posílat zařízením příkazy a řídicí zprávy.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Zoiner Tejada | Generální ředitel a architekt
Další kroky
Projděte si následující relevantní služby Azure: