Mnoho služeb používá model omezování k řízení prostředků, které spotřebovávají, a omezuje rychlost, s jakou k nim mají přístup jiné aplikace nebo služby. Model omezování rychlosti vám pomůže vyhnout se chybám omezování nebo minimalizovat související s těmito limity omezování a přesněji předpovědět propustnost.
Model omezování rychlosti je vhodný v mnoha scénářích, ale je zvlášť užitečný pro rozsáhlé opakované automatizované úlohy, jako je dávkové zpracování.
Kontext a problém
Provádění velkého počtu operací s využitím omezené služby může vést ke zvýšení provozu a propustnosti, protože budete muset sledovat zamítnuté požadavky a potom tyto operace opakovat. S rostoucím počtem operací může omezení omezení vyžadovat více průchodů dat opětovného odeslání, což vede k většímu dopadu na výkon.
Představte si například následující naïve opakování procesu chyby při ingestování dat do služby Azure Cosmos DB:
- Vaše aplikace potřebuje ingestovat 10 000 záznamů do služby Azure Cosmos DB. Každý záznam stojí 10 jednotek žádostí (RU) na příjem, což k dokončení úlohy vyžaduje celkem 100 000 RU.
- Vaše instance Azure Cosmos DB má zřízenou kapacitu 20 000 RU.
- Všech 10 000 záznamů odešlete do služby Azure Cosmos DB. 2 000 záznamů se úspěšně zapíše a odmítne se 8 000 záznamů.
- Zbývající 8 000 záznamů odešlete do služby Azure Cosmos DB. Úspěšně zapsáno 2 000 záznamů a odmítnuto je 6 000 záznamů.
- Zbývající 6 000 záznamů odešlete do služby Azure Cosmos DB. 2 000 záznamů se úspěšně zapíše a odmítne se 4 000 záznamů.
- Zbývající 4 000 záznamů odešlete do služby Azure Cosmos DB. 2 000 záznamů se úspěšně zapíše a zamítne se 2 000 záznamů.
- Zbývající 2 000 záznamů odešlete do služby Azure Cosmos DB. Všechny se úspěšně zapisují.
Úloha příjmu dat se úspěšně dokončila, ale až po odeslání 30 000 záznamů do služby Azure Cosmos DB, i když celá datová sada obsahovala pouze 10 000 záznamů.
V předchozím příkladu je potřeba vzít v úvahu další faktory:
- Velký počet chyb může také vést k dalšímu zpracování těchto chyb a zpracování výsledných dat protokolu. Tento přístup naïve bude zpracovávat 20 000 chyb a protokolování těchto chyb může nutit náklady na prostředky úložiště, zpracování, paměti nebo úložiště.
- Když neznáte limity omezování služby příjmu dat, nemá naïve způsob, jak nastavit očekávání pro dobu zpracování dat. Omezení rychlosti vám umožní vypočítat čas potřebný k příjmu dat.
Řešení
Omezování rychlosti může snížit provoz a potenciálně zlepšit propustnost snížením počtu záznamů odeslaných do služby v daném časovém období.
Služba může v průběhu času omezovat různé metriky, například:
- Počet operací (například 20 požadavků za sekundu)
- Množství dat (například 2 GiB za minutu).
- Relativní náklady na provoz (například 20 000 RU za sekundu)
Bez ohledu na metriku použitou pro omezování bude implementace omezování rychlosti zahrnovat řízení počtu a/nebo velikosti operací odesílaných do služby v určitém časovém období, optimalizaci využití služby, aniž by překročila její kapacitu omezování.
Ve scénářích, kdy vaše rozhraní API můžou zpracovávat požadavky rychleji než jakékoli omezené služby příjmu dat, budete muset spravovat, jak rychle můžete službu používat. Problém s neshodou četnosti dat se ale dá považovat pouze za problém s omezováním a jednoduše ukládat požadavky na příjem dat do vyrovnávací paměti, dokud služba omezeného rozsahu nedosáhne, je riziková. Pokud se vaše aplikace v tomto scénáři chybově ukončí, riskujete ztrátu jakéhokoli z těchto dat uložených do vyrovnávací paměti.
Abyste se tomuto riziku vyhnuli, zvažte odeslání záznamů do odolného systému zasílání zpráv, který dokáže zpracovat vaši plnou rychlost příjmu dat. (Služby, jako je Azure Event Hubs, můžou zpracovávat miliony operací za sekundu). Potom můžete použít jeden nebo více procesorů úloh ke čtení záznamů ze systému zasílání zpráv s řízenou rychlostí, která je v mezích omezení služby. Odesílání záznamů do systému zasílání zpráv může ušetřit vnitřní paměť tím, že umožňuje odložit pouze záznamy, které lze zpracovat během daného časového intervalu.
Azure poskytuje několik trvalých služeb zasílání zpráv, které můžete použít s tímto vzorem, včetně:
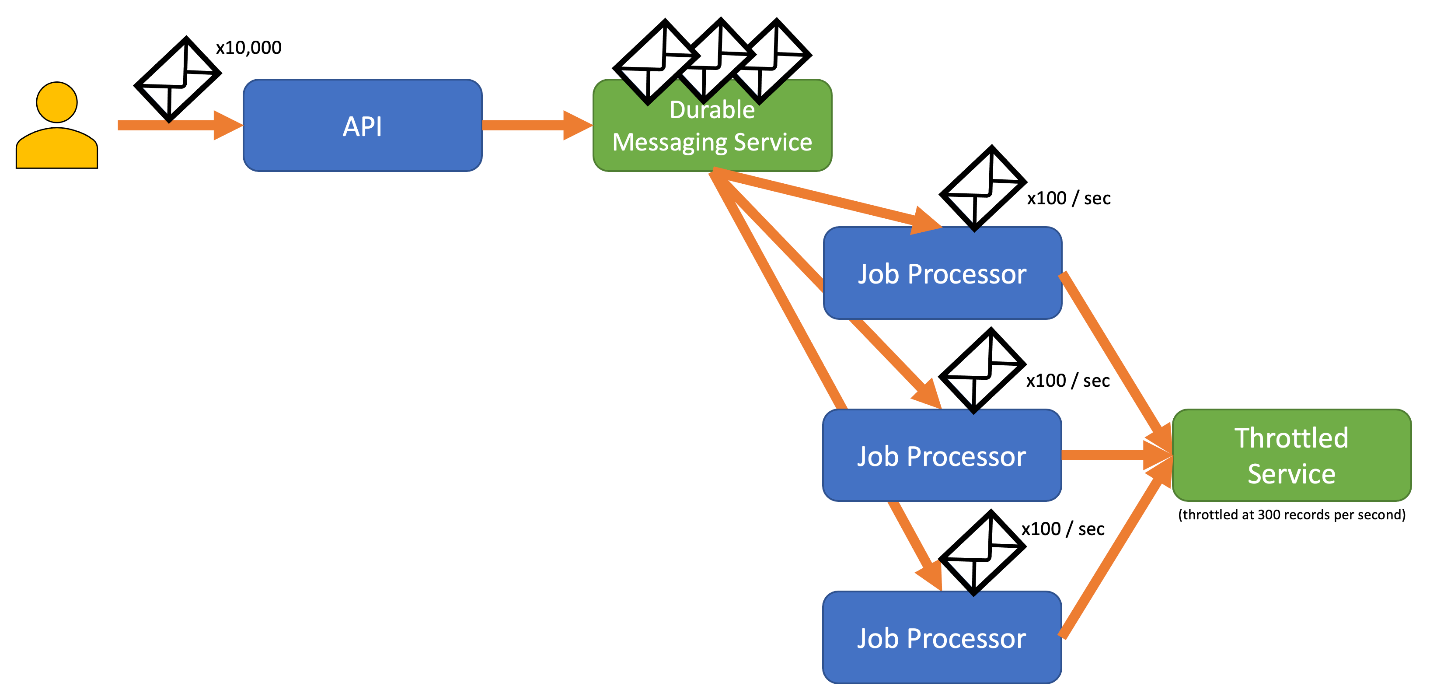
Při odesílání záznamů může být časové období, které používáte pro vydávání záznamů, podrobnější než období, ve kterém služba omezuje. Systémy často nastavují omezení na základě časových rozsahů, se kterými můžete snadno pochopit a pracovat s tím. U počítače se službou však tyto časové rámce mohou být velmi dlouhé ve srovnání s tím, jak rychle může zpracovávat informace. Systém může například omezovat za sekundu nebo minutu, ale obvykle se kód zpracovává v pořadí nanosekund nebo milisekund.
I když to není nutné, často se doporučuje odesílat menší objemy záznamů častěji, aby se zlepšila propustnost. Takže místo toho, abyste se snažili rozsádvat dávky pro vydání jednou za sekundu nebo jednou minutu, můžete být podrobnější než to, abyste udrželi spotřebu prostředků (paměť, procesor, síť atd.), což brání potenciálním kritickým bodům v důsledku náhlého nárůstu požadavků. Pokud například služba umožňuje 100 operací za sekundu, může implementace omezovače rychlosti dokonce vyřadit požadavky uvolněním 20 operací každých 200 milisekund, jak je znázorněno v následujícím grafu.

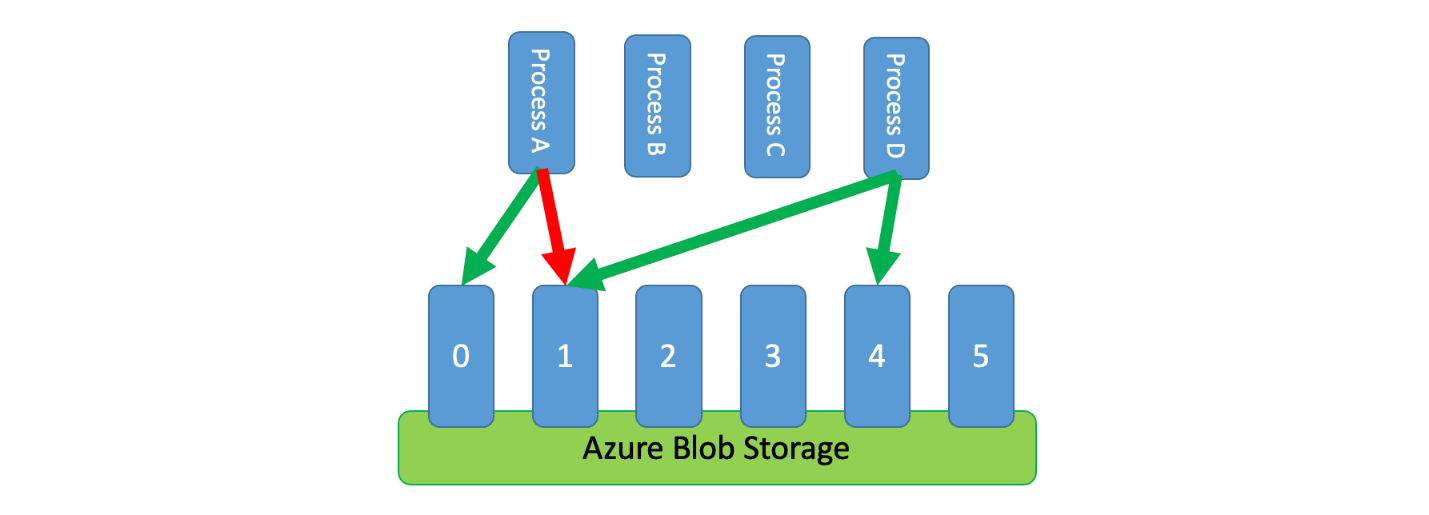
Kromě toho je někdy nutné, aby několik nekoordovaných procesů sdílelo omezené služby. K implementaci omezování rychlosti v tomto scénáři můžete logicky rozdělit kapacitu služby a pak použít distribuovaný systém vzájemného vyloučení ke správě výhradních zámků v těchto oddílech. Nekoordované procesy pak můžou soutěžit o zámky v těchto oddílech, kdykoli potřebují kapacitu. Pro každý oddíl, pro který proces uchovává zámek, je udělena určitá kapacita.
Pokud například omezený systém umožňuje 500 požadavků za sekundu, můžete vytvořit 20 oddílů za 25 požadavků za sekundu. Pokud proces potřeboval vydat 100 požadavků, může požádat distribuovaný systém vzájemného vyloučení o čtyři oddíly. Systém může udělit dva oddíly po dobu 10 sekund. Proces pak omezí rychlost na 50 požadavků za sekundu, dokončí úlohu za dvě sekundy a pak uvolní zámek.
Jedním ze způsobů, jak tento model implementovat, je použít Azure Storage. V tomto scénáři vytvoříte jeden 0bajtů objekt blob na logický oddíl v kontejneru. Vaše aplikace pak můžou získat výhradní zapůjčení přímo proti těmto objektům blob po krátkou dobu (například 15 sekund). Pro každé zapůjčení aplikace bude moct využívat kapacitu daného oddílu. Aplikace pak potřebuje sledovat dobu zapůjčení, aby po vypršení platnosti přestala využívat kapacitu, kterou byla udělena. Při implementaci tohoto modelu budete často chtít, aby se každý proces pokusil zapůjčení náhodného oddílu, když potřebuje kapacitu.
Pokud chcete dále snížit latenci, můžete pro každý proces přidělit malou exkluzivní kapacitu. Proces by se pak snažil získat zapůjčení sdílené kapacity pouze v případě, že by potřeboval překročit svou rezervovanou kapacitu.
Jako alternativu ke službě Azure Storage můžete také implementovat tento druh systému správy zapůjčení pomocí technologií, jako jsou Zookeeper, Consul, etcd, Redis/Redsync a další.
Problémy a důležité informace
Při rozhodování o implementaci tohoto modelu zvažte následující skutečnosti:
- I když model omezování rychlosti může snížit počet chyb omezování, vaše aplikace bude stále muset správně zpracovat všechny chyby omezování, ke kterým může dojít.
- Pokud má vaše aplikace více pracovních proudů, které přistupují ke stejné omezené službě, budete je muset integrovat do strategie omezování rychlosti. Můžete například podporovat hromadné načítání záznamů do databáze, ale také dotazování na záznamy ve stejné databázi. Kapacitu můžete spravovat tak, že zajistíte, aby všechny pracovní proudy byly brány stejným mechanismem omezování rychlosti. Alternativně můžete vyhraďte samostatné fondy kapacity pro každý pracovní stream.
- Omezovaná služba se může používat ve více aplikacích. V některých , ale ne ve všech případech, je možné koordinovat toto použití (jak je znázorněno výše). Pokud se vám začne zobrazovat větší než očekávaný počet chyb omezování, může se jednat o znaménko kolizí mezi aplikacemi, které přistupují ke službě. Pokud ano, možná budete muset dočasně snížit propustnost, kterou váš mechanismus omezování rychlosti omezuje, dokud se využití z jiných aplikací nezmenšuje.
Kdy se má tento model použít
Tento model použijte k:
- Omezte chyby omezování vyvolané omezenou službou.
- Snižte provoz v porovnání s naivním opakováním při přístupu k chybám.
- Snížení spotřeby paměti odstraněním fronty záznamů pouze v případech, kdy je kapacita ke zpracování.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu omezování rychlosti v návrhu úloh k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Tato taktika chrání klienta tím, že potvrzuje a respektuje omezení a náklady na komunikaci se službou, když služba chce zabránit nadměrnému využití. - RE:07 Sebezáchování |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Následující ukázková aplikace umožňuje uživatelům odesílat záznamy různých typů do rozhraní API. Pro každý typ záznamu existuje jedinečný procesor úloh, který provádí následující kroky:
- Ověřování
- Rozšíření
- Vložení záznamu do databáze
Všechny komponenty aplikace (ROZHRANÍ API, procesor úloh A a procesor úloh B) jsou samostatné procesy, které se můžou škálovat nezávisle. Procesy mezi sebou nekomunikují přímo.
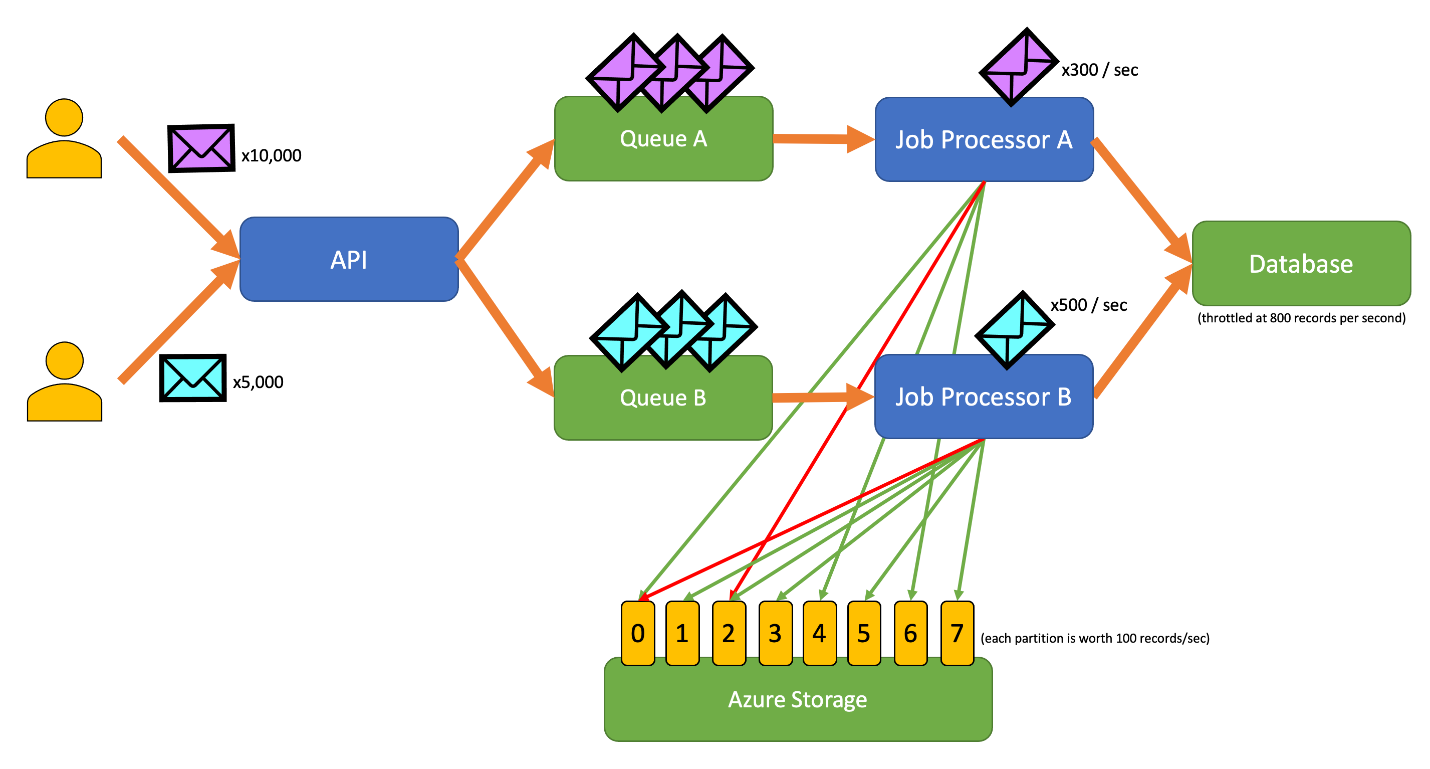
Tento diagram zahrnuje následující pracovní postup:
- Uživatel odešle do rozhraní API 10 000 záznamů typu A.
- Rozhraní API vytvoří frontu těchto 10 000 záznamů ve frontě A.
- Uživatel odešle do rozhraní API 5 000 záznamů typu B.
- Rozhraní API vytvoří frontu těchto 5 000 záznamů ve frontě B.
- Procesor úloh A vidí, že fronta A obsahuje záznamy a snaží se získat výhradní zapůjčení objektu blob 2.
- Procesor úloh B vidí, že fronta B obsahuje záznamy a snaží se získat výhradní zapůjčení objektu blob 2.
- Procesor úloh A nemůže získat zapůjčení.
- Procesor úloh B získá zapůjčení objektu blob 2 po dobu 15 sekund. Teď může omezit četnost požadavků na databázi rychlostí 100 za sekundu.
- Procesor úloh B odřadí 100 záznamů z fronty B a zapíše je.
- Jedna sekunda projde.
- Procesor úloh A vidí, že fronta A obsahuje více záznamů a snaží se získat výhradní zapůjčení objektu blob 6.
- Procesor úloh B vidí, že fronta B obsahuje více záznamů a snaží se získat výhradní zapůjčení objektu blob 3.
- Procesor úloh A získá zapůjčení objektu blob 6 po dobu 15 sekund. Teď může omezit četnost požadavků na databázi rychlostí 100 za sekundu.
- Procesor úloh B získá zapůjčení objektu blob 3 po dobu 15 sekund. Teď může omezit požadavky na databázi rychlostí 200 za sekundu. (Obsahuje také zapůjčení objektu blob 2.)
- Procesor úloh A odřadí 100 záznamů z fronty A a zapíše je.
- Procesor úloh B odřadí 200 záznamů z fronty B a zapíše je.
- Jedna sekunda projde.
- Procesor úloh A vidí, že fronta A obsahuje více záznamů a snaží se získat výhradní zapůjčení objektu blob 0.
- Procesor úloh B vidí, že fronta B obsahuje více záznamů a snaží se získat výhradní zapůjčení objektu blob 1.
- Procesor úloh A získá zapůjčení objektu blob 0 po dobu 15 sekund. Teď může omezit požadavky na databázi rychlostí 200 za sekundu. (Obsahuje také zapůjčení objektu blob 6.)
- Procesor úloh B získá zapůjčení objektu blob 1 po dobu 15 sekund. Teď může omezit požadavky na databázi rychlostí 300 za sekundu. (Obsahuje také zapůjčení objektů blob 2 a 3.)
- Procesor úloh A odřadí 200 záznamů z fronty A a zapíše je.
- Procesor úloh B odřadí 300 záznamů z fronty B a zapíše je.
- A tak dále...
Po 15 sekundách se jedna nebo obě úlohy stále nedokončí. Když vyprší platnost zapůjčení, procesor by měl také snížit počet žádostí, které vypíše a zapisuje.
 Implementace tohoto modelu jsou k dispozici v různých programovacích jazycích:
Implementace tohoto modelu jsou k dispozici v různých programovacích jazycích:
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující modely a pokyny:
- Omezování. Zde probíraný model omezování rychlosti se obvykle implementuje v reakci na službu, která je omezena.
- Opakování. Když požadavky na omezené služby vedou k chybám omezování, je obecně vhodné je zkusit je opakovat po příslušném intervalu.
Vyrovnávání zatížení na základě fronty je podobné, ale liší se od vzoru omezování rychlosti několika klíčovými způsoby:
- Omezování rychlosti nemusí nutně používat fronty ke správě zatížení, ale potřebuje využívat odolnou službu zasílání zpráv. Například model omezování rychlosti může využívat služby, jako je Apache Kafka nebo Azure Event Hubs.
- Model omezování rychlosti představuje koncept distribuovaného systému vzájemného vyloučení v oddílech, který umožňuje spravovat kapacitu pro více nekomordovaných procesů, které komunikují se stejnou omezené službou.
- Model vyrovnávání zatížení na základě fronty se dá použít, kdykoli dojde k neshodě výkonu mezi službami nebo ke zlepšení odolnosti. Díky tomu je širší než omezování rychlosti, což se konkrétně zabývá efektivním přístupem k omezené službě.