Zotavení po havárii a geografická distribuce v Azure Durable Functions
Microsoft se snaží zajistit, aby služby Azure byly vždy dostupné. Může však dojít k neplánovaným výpadkům služeb. Pokud vaše aplikace vyžaduje odolnost proti chybám, Microsoft doporučuje, aby v aplikaci byla nakonfigurována geografická redundance. Zákazníci by navíc měli mít plán zotavení po havárii pro řešení výpadku místní služby. Důležitou součástí plánu zotavení po havárii je příprava na převzetí služeb při selhání sekundární repliky vaší aplikace a úložiště v případě, že primární replika přestane být dostupná.
Ve Durable Functions je ve výchozím nastavení ve službě Azure Storage zachován veškerý stav. Centrum úloh je logický kontejner pro prostředky Azure Storage, které se používají pro orchestrace a entity. Funkce orchestratoru, aktivit a entit můžou vzájemně komunikovat, jenom když patří do stejného centra úloh. Tento dokument bude odkazovat na centra úloh při popisu scénářů pro zajištění vysoké dostupnosti těchto prostředků služby Azure Storage.
Poznámka
Pokyny v tomto článku předpokládají, že k ukládání stavu modulu runtime Durable Functions používáte výchozího poskytovatele služby Azure Storage. Je však možné nakonfigurovat alternativní poskytovatele úložiště, kteří ukládají stav jinde, jako je databáze SQL Server. Alternativní poskytovatelé úložiště můžou vyžadovat různé strategie zotavení po havárii a geografickou distribuci. Další informace o alternativních poskytovatelích úložiště najdete v dokumentaci k poskytovatelům Durable Functions úložiště.
Orchestrace a entity je možné aktivovat pomocí klientských funkcí, které se samy aktivují prostřednictvím protokolu HTTP nebo některého z dalších podporovaných typů triggerů Azure Functions. Můžete je také aktivovat pomocí integrovaných rozhraní HTTP API. Pro zjednodušení se tento článek zaměří na scénáře zahrnující Azure Storage a triggery funkcí založené na protokolu HTTP a možnosti pro zvýšení dostupnosti a minimalizaci výpadků během aktivit zotavení po havárii. Další typy triggerů, jako jsou triggery služby Service Bus nebo Azure Cosmos DB, se explicitně nezabývá.
Následující scénáře jsou založené na konfiguracích Active-Passive, protože se řídí používáním služby Azure Storage. Tento model spočívá v nasazení zálohovací (pasivní) aplikace funkcí do jiné oblasti. Traffic Manager bude monitorovat dostupnost PROTOKOLU HTTP v primární (aktivní) aplikaci funkcí. Pokud primární služba selže, převezme služby při selhání do aplikace funkcí zálohování. Další informace najdete v tématu Metoda priority Traffic-Routingslužby Azure Traffic Manager.
Poznámka
- Navrhovaná konfigurace Active-Passive zajišťuje, že klient bude vždy schopen aktivovat nové orchestrace prostřednictvím protokolu HTTP. V důsledku toho, že dvě aplikace funkcí sdílejí stejné centrum úloh v úložišti, se mezi ně ale rozdělí některé transakce úložiště na pozadí. Tato konfigurace proto pro sekundární aplikaci funkcí účtují určité další náklady na výchozí přenos dat.
- Základní účet úložiště a centrum úloh se vytvoří v primární oblasti a obě aplikace funkcí je sdílejí.
- Všechny aplikace funkcí, které jsou redundantně nasazené, musí v případě aktivace prostřednictvím protokolu HTTP sdílet stejné přístupové klíče funkcí. Modul runtime služby Functions zveřejňuje rozhraní API pro správu , které uživatelům umožňuje programově přidávat, odstraňovat a aktualizovat klíče funkcí. Správa klíčů je také možná pomocí rozhraní API Azure Resource Manager.
Scénář 1 – Výpočetní prostředky s vyrovnáváním zatížení se sdíleným úložištěm
Pokud výpočetní infrastruktura v Azure selže, aplikace funkcí může být nedostupná. Aby se minimalizovala možnost takového výpadku, používá tento scénář dvě aplikace funkcí nasazené v různých oblastech. Traffic Manager je nakonfigurovaný tak, aby detekoval problémy v primární aplikaci funkcí a automaticky přesměroval provoz do aplikace funkcí v sekundární oblasti. Tato aplikace funkcí sdílí stejný účet Azure Storage a centrum úloh. Proto se stav aplikací funkcí neztratí a práce může normálně pokračovat. Po obnovení stavu do primární oblasti začne Azure Traffic Manager automaticky směrovat požadavky na danou aplikaci funkcí.

Použití tohoto scénáře nasazení má několik výhod:
- Pokud výpočetní infrastruktura selže, může se v oblasti převzetí služeb při selhání pokračovat v práci bez ztráty dat.
- Traffic Manager se postará o automatické převzetí služeb při selhání do aplikace funkcí, která je v pořádku.
- Traffic Manager po opravě výpadku automaticky znovu vytvoří provoz do primární aplikace funkcí.
Při použití tohoto scénáře však zvažte následující:
- Pokud je aplikace funkcí nasazená pomocí vyhrazeného plánu App Service, replikace výpočetní infrastruktury v datacentru s podporou převzetí služeb při selhání zvýší náklady.
- Tento scénář se zabývá výpadky výpočetní infrastruktury, ale účet úložiště je i nadále jediným bodem selhání aplikace funkcí. Pokud dojde k výpadku úložiště, dojde k výpadku aplikace.
- Pokud dojde k převzetí služeb při selhání aplikace funkcí, zvýší se latence, protože bude přistupovat ke svému účtu úložiště napříč oblastmi.
- Přístup ke službě úložiště z jiné oblasti, kde se nachází, se kvůli odchozímu síťovému provozu účtují vyšší náklady.
- Tento scénář závisí na Traffic Manageru. Vzhledem k tomu, jak Traffic Manager funguje, může nějakou dobu uplynout, než se klientská aplikace, která využívá durable funkci, bude muset znovu dotázat adresu aplikace funkcí z Traffic Manageru.
Poznámka
Od verze 2.3.0 rozšíření Durable Functions je možné bezpečně spouštět dvě aplikace funkcí současně se stejným účtem úložiště a konfigurací centra úloh. První spuštěná aplikace získá zapůjčení objektů blob na úrovni aplikace, které zabrání ostatním aplikacím v krádeži zpráv z front centra úloh. Pokud tato první aplikace přestane běžet, její zapůjčení vyprší a může ji získat druhá aplikace, která pak bude pokračovat ve zpracování zpráv centra úloh.
Před verzí 2.3.0 budou aplikace funkcí, které jsou nakonfigurované tak, aby používaly stejný účet úložiště, zpracovávat zprávy a aktualizovat artefakty úložiště současně, což vede k mnohem vyšší celkové latenci a nákladům na výchozí přenos dat. Pokud primární aplikace a aplikace repliky mají někdy nasazený jiný kód, a to i dočasně, pak se orchestrace nemusí správně spustit kvůli nekonzistenci funkcí orchestrátoru v obou aplikacích. Proto se doporučuje, aby všechny aplikace, které vyžadují geografickou distribuci pro účely zotavení po havárii, používaly rozšíření Durable v2.3.0 nebo vyšší.
Scénář 2 – Výpočetní prostředky s vyrovnáváním zatížení s regionálním úložištěm
Předchozí scénář se zabývá pouze případem selhání ve výpočetní infrastruktuře. Pokud služba úložiště selže, způsobí to výpadek aplikace funkcí. Aby se zajistil nepřetržitý provoz trvalých funkcí, používá tento scénář místní účet úložiště v každé oblasti, do které jsou aplikace funkcí nasazené.

Tento přístup přidává vylepšení předchozího scénáře:
- Pokud aplikace funkcí selže, Traffic Manager se postará o převzetí služeb při selhání do sekundární oblasti. Vzhledem k tomu, že aplikace funkcí spoléhá na vlastní účet úložiště, budou odolné funkce dál fungovat.
- Během převzetí služeb při selhání nedochází k žádné další latenci v oblasti převzetí služeb při selhání, protože aplikace funkcí a účet úložiště jsou společně umístěné.
- Selhání vrstvy úložiště způsobí selhání trvalých funkcí, což zase aktivuje přesměrování do oblasti převzetí služeb při selhání. Opět platí, že vzhledem k tomu, že aplikace funkcí a úložiště jsou izolované pro každou oblast, budou odolné funkce dál fungovat.
Důležité informace pro tento scénář:
- Pokud je aplikace funkcí nasazená pomocí vyhrazeného plánu App Service, replikace výpočetní infrastruktury v datacentru s podporou převzetí služeb při selhání zvýší náklady.
- Aktuální stav neproběhl při selhání, což znamená, že existující orchestrace a entity budou efektivně pozastavené a nedostupné, dokud se primární oblast neobnoví.
Stručně řečeno, kompromis mezi prvním a druhým scénářem spočívá v tom, že se zachová latence a náklady na výchozí přenos dat se minimalizují, ale během výpadku nebudou k dispozici existující orchestrace a entity. To, jestli jsou tyto kompromisy přijatelné, závisí na požadavcích aplikace.
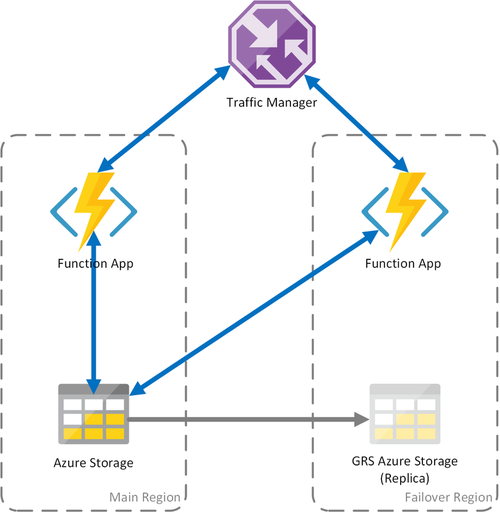
Scénář 3 – Výpočetní prostředky s vyrovnáváním zatížení se sdíleným úložištěm GRS
Tento scénář je úpravou oproti prvnímu scénáři, který implementuje sdílený účet úložiště. Hlavní rozdíl spočívá v tom, že účet úložiště je vytvořený s povolenou geografickou replikací. Funkčně tento scénář poskytuje stejné výhody jako scénář 1, ale nabízí další výhody obnovení dat:
- Geograficky redundantní úložiště (GRS) a GRS (RA-GRS) maximalizují dostupnost vašeho účtu úložiště.
- Pokud dojde k regionálnímu výpadku služby Storage, můžete ručně zahájit převzetí služeb při selhání sekundární repliky. V extrémních případech, kdy dojde ke ztrátě oblasti kvůli významné havárii, může Microsoft iniciovat převzetí služeb při selhání v oblasti. V takovém případě není nutná žádná akce z vaší strany.
- Když dojde k převzetí služeb při selhání, stav trvalých funkcí se zachová až do poslední replikace účtu úložiště, ke které obvykle dochází každých několik minut.
Stejně jako u ostatních scénářů jsou důležité aspekty:
- Převzetí služeb při selhání repliky může nějakou dobu trvat. Dokud se převzetí služeb při selhání dokončí a nebudou aktualizovány záznamy DNS služby Azure Storage, dojde k výpadku aplikace funkcí.
- Používání geograficky replikovaných účtů úložiště se zvyšuje.
- Replikace GRS asynchronně kopíruje data. Některé z nejnovějších transakcí mohou být ztraceny kvůli latenci procesu replikace.
Poznámka
Jak je popsáno ve scénáři 1, důrazně doporučujeme, aby aplikace funkcí nasazené v rámci této strategie používaly rozšíření Durable Functions verze 2.3.0 nebo vyšší.
Další informace najdete v dokumentaci k zotavení po havárii a převzetí služeb při selhání účtu úložiště ve službě Azure Storage .