Postup nastavení pracovních prostorů strojového učení
Prostředí strojového učení a řízení přístupu na základě role
Vývojová, testovací a produkční prostředí podporují provozní procesy strojového učení.
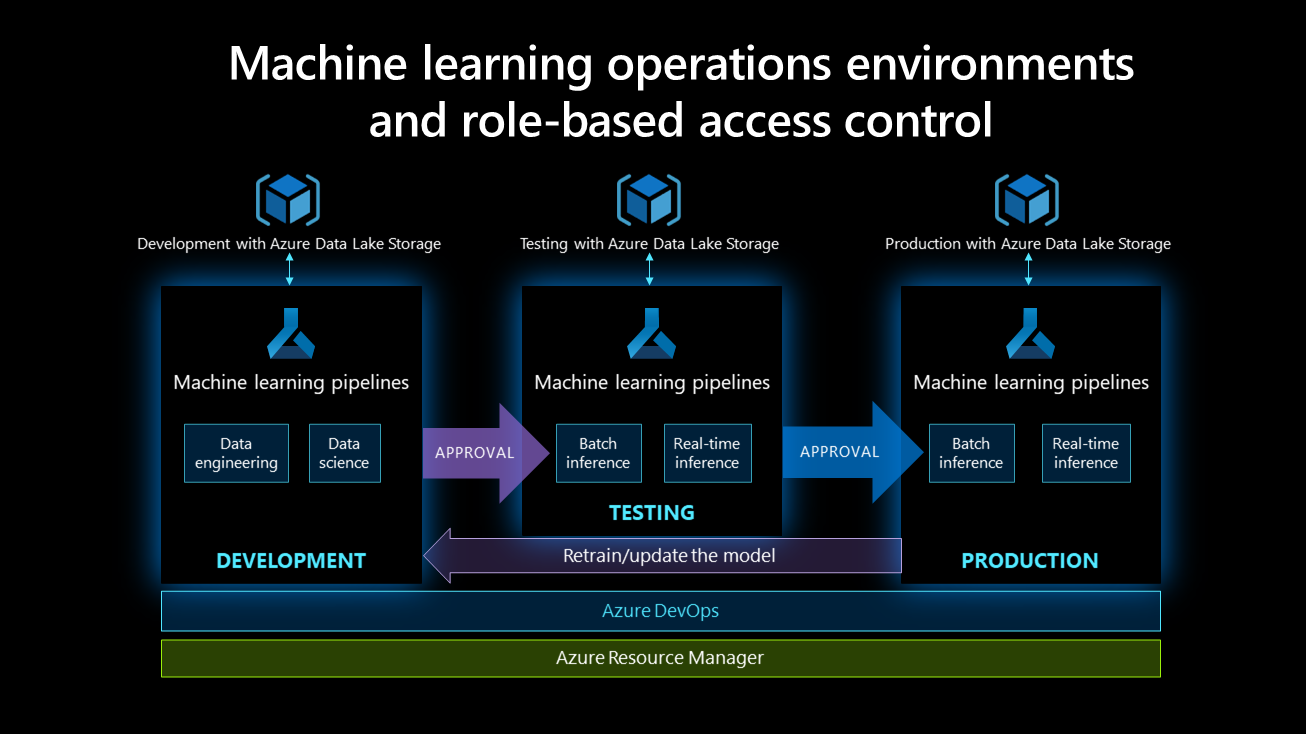
Ve vývojovém prostředí: Kanály strojového učení by měly podporovat datové vědy a technické aktivity prováděné datovými vědci a datovými inženýry. Měli by mít úplná oprávnění související se spouštěním experimentů, jako je zřizování trénovacích clusterů nebo sestavování modelů. Neměli by ale mít oprávnění k aktivitám, jako je odstraňování nebo vytváření pracovních prostorů nebo přidávání nebo odebírání uživatelů pracovních prostorů.
V testovacím prostředí: V prostředí modelu se provádějí různé testy a pro model by se mělo použít buď šampión/ vyzyvatel nebo testování A/B. Testovací prostředí by mělo napodobovat prostředí nasazení a mělo by spouštět testy, jako je zátěžové testování, doba odezvy modelu a další. Datoví vědci a technici mají k tomuto prostředí omezený přístup, především přístup jen pro čtení a některá konfigurační práva. Ruka inženýra DevOps má plný přístup k prostředí. Automatizujte co nejvíce testů. Po dokončení všech testů se pro nasazení v produkčním prostředí vyžaduje schválení účastníka.
V produkčním prostředí: Model se nasadí během dávkového odvozování nebo odvozování v reálném čase. Produkční prostředí je obvykle jen pro čtení; Technik DevOps má však k tomuto prostředí plný přístup a zodpovídá za jeho nepřetržitou podporu a údržbu. Datoví vědci a datoví inženýři mají omezený přístup k prostředí a je jen pro čtení.
Řízení přístupu na základě role pro všechna prostředí je znázorněno v následujícím diagramu:

Tato tabulka ukazuje, že úrovně přístupu datového inženýra a datového vědce se v rámci vyšších prostředí snižují, zatímco přístup techniků DevOps se zvyšuje. Důvodem je to, že inženýr provozu strojového učení sestaví kanál, spojí věci dohromady a nasadí modely v produkčním prostředí. Tato úroveň členitosti se doporučuje pro každou roli.
Faktory, které ovlivňují pracovní prostory strojového učení
Způsob nastavení pracovních prostorů strojového učení může ovlivnit několik faktorů, které vám můžou pomoct určit nejlepší strukturu a ovládací prvky pro každý typ pracovního prostoru:
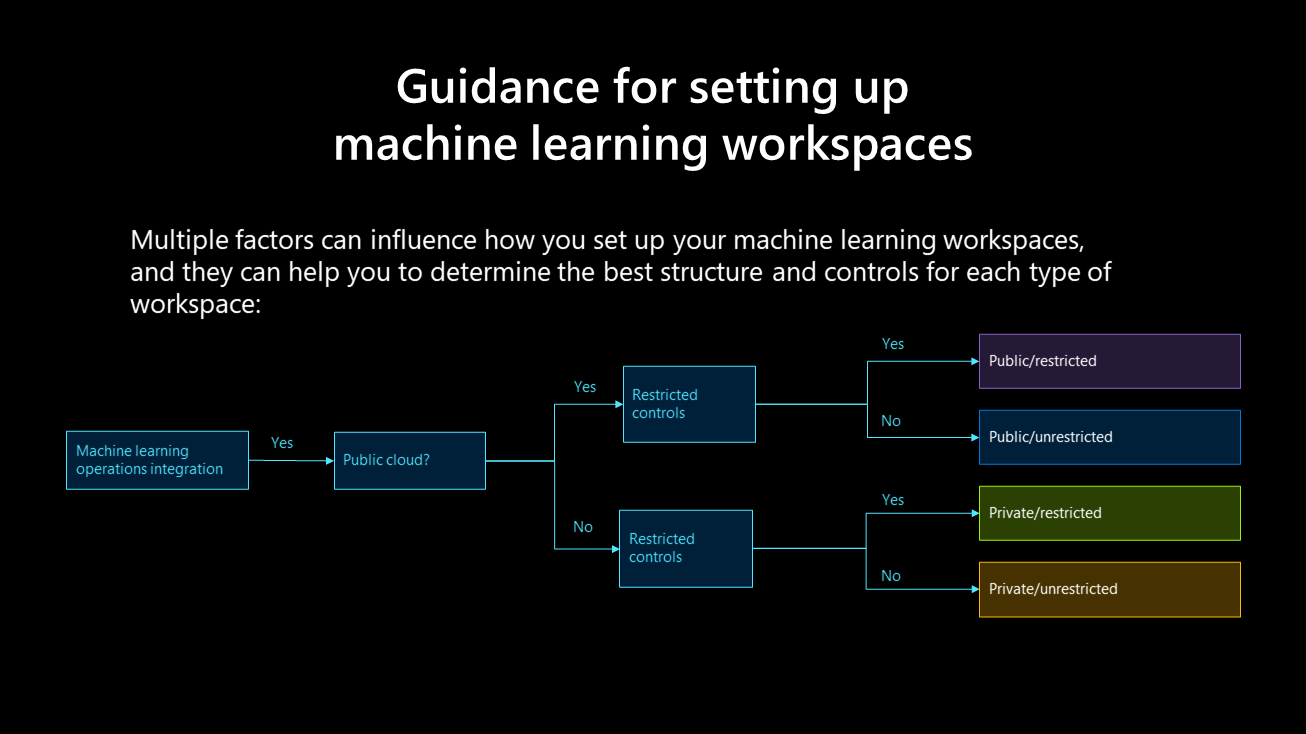
Veřejné, omezené:
- Vývoj, testování a produkční pracovní prostor
- Vlastní role: datový vědec
- Integrace Gitu pro správu verzí a kontinuální integraci / průběžný vývoj (CI/CD)
Veřejné, neomezené:
- Vývoj, testování a produkční pracovní prostor
- Role: přispěvatel
- Integrace Gitu pro správu verzí a CI/CD
Soukromé, omezené:
- Vývoj, testování a produkční pracovní prostor
- Private Link povoleno
- Vlastní role: datový vědec
- Integrace Gitu pro správu verzí a CI/CD
Soukromé, neomezené:
- Vývoj, testování a produkční pracovní prostor
- Private Link povoleno
- Role: přispěvatel
- Integrace Gitu pro správu verzí a CI/CD
Všechny pracovní prostory:
- Jeden studio Azure Machine Learning pracovní prostor na projekt
- Jedna výpočetní instance na datového vědce
- Jeden výpočetní cluster na velikost virtuálního počítače sdílené s datovými vědci pro vývoj
- Jeden výpočetní cluster na produkční kanál
- Pokud chcete snížit náklady, nastavením minimální velikosti uzlu výpočetního clusteru na hodnotu 0
- Pokyn uživatelům, aby po použití ručně vypnuli výpočetní instance
- Vlastní role správce pracovního prostoru s přístupem k vytváření výpočetních instancí a clusterů
- Vlastní role datového vědce, která vyžaduje, aby veškerou infrastrukturu nastavil jiný uživatel, než datový vědec může začít pracovat.
Další kroky
Přečtěte si další informace o tom, jak vytvořit a spravovat pracovní prostor ve službě Azure Machine Learning.
Pomocí sady Python SDK vytvořte pracovní prostor ve vývojovém prostředí.
Během životního cyklu vývoje použijte poznámkové bloky Azure Portal a Jupyter k nastavení vývojového prostředí Azure Machine Learning a trénování modelu.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro