Transformace dat spuštěním aktivity Jar v Azure Databricks
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Aktivita Jar Azure Databricks v kanálu spouští sparkový jar v clusteru Azure Databricks. Tento článek vychází z článku o aktivitách transformace dat, který představuje obecný přehled transformace dat a podporovaných transformačních aktivit. Azure Databricks je spravovaná platforma pro spouštění Apache Sparku.
Jedenáctiminutové představení a ukázku této funkce najdete v tomto videu:
Přidání aktivity Jar pro Azure Databricks do kanálu pomocí uživatelského rozhraní
Pokud chcete v kanálu použít aktivitu Jar pro Azure Databricks, proveďte následující kroky:
Vyhledejte jar v podokně Aktivity kanálu a přetáhněte aktivitu Jar na plátno kanálu.
Vyberte novou aktivitu Jar na plátně, pokud ještě není vybraná.
Výběrem karty Azure Databricks vyberte nebo vytvořte novou propojenou službu Azure Databricks, která spustí aktivitu Jar.
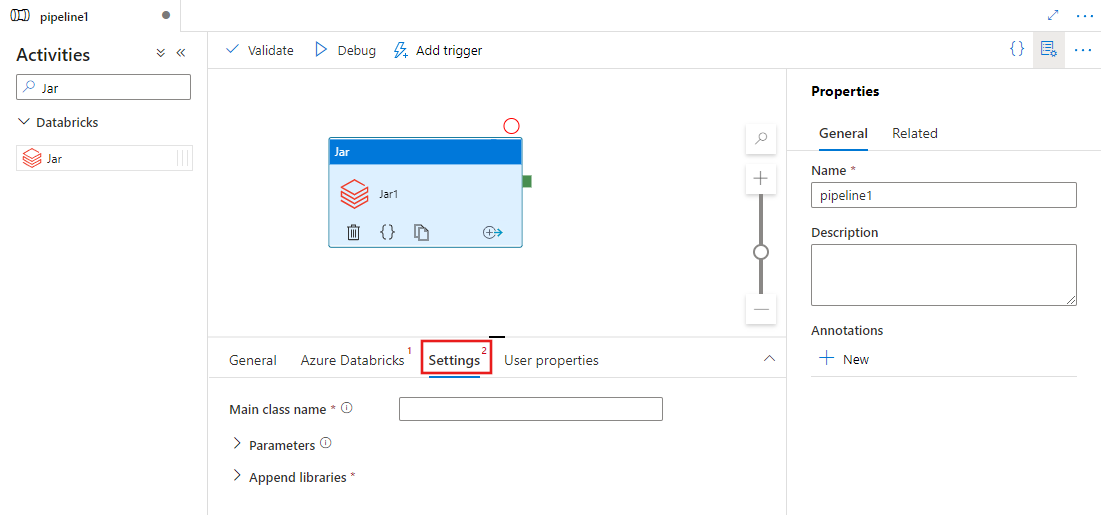
Vyberte kartu Nastavení a zadejte název třídy, který se má spustit v Azure Databricks, volitelné parametry, které se mají předat do jar, a knihovny, které se mají nainstalovat do clusteru, aby se úloha spustila.
Definice aktivity Jar databricks
Tady je ukázková definice JSON aktivity Jar databricks:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Vlastnosti aktivity Jar databricks
Následující tabulka popisuje vlastnosti JSON použité v definici JSON:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| name | Název aktivity v kanálu | Ano |
| description | Text popisující, co aktivita dělá. | No |
| type | Pro aktivitu Jar Databricks je typ aktivity DatabricksSparkJar. | Ano |
| linkedServiceName | Název propojené služby Databricks, na které se aktivita Jar spouští. Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| mainClassName | Úplný název třídy obsahující hlavní metodu, která se má provést. Tato třída musí být obsažena v souboru JAR poskytnutém jako knihovna. Soubor JAR může obsahovat více tříd. Každá z tříd může obsahovat hlavní metodu. | Ano |
| parameters | Parametry, které se předají hlavní metodě. Tato vlastnost je pole řetězců. | No |
| knihovny | Seznam knihoven, které se mají nainstalovat do clusteru, který spustí úlohu. Může to být pole řetězce, objektu <.> | Ano (alespoň jeden obsahující metodu mainClassName) |
Poznámka:
Známý problém – při použití stejného interaktivního clusteru pro spouštění souběžných aktivit Databricks Jar (bez restartování clusteru) existuje známý problém v Databricks, kdy se parametry první aktivity budou používat také následujícími aktivitami. Výsledkem je předání nesprávných parametrů následným úlohům. Pokud chcete tento problém zmírnit, použijte místo toho cluster úloh.
Podporované knihovny pro aktivity Databricks
V předchozí definici aktivity Databricks jste zadali tyto typy knihoven: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Další informace najdete v dokumentaci k Databricks pro typy knihoven.
Jak nahrát knihovnu v Databricks
Můžete použít uživatelské rozhraní pracovního prostoru:
Použití uživatelského rozhraní pracovního prostoru Databricks
K získání cesty dbfs knihovny přidané pomocí uživatelského rozhraní můžete použít Rozhraní příkazového řádku Databricks.
Knihovny Jar se obvykle ukládají v souboru dbfs:/FileStore/jars při používání uživatelského rozhraní. Seznam všech prostřednictvím rozhraní příkazového řádku: databricks fs ls dbfs:/FileStore/job-jars
Nebo můžete použít rozhraní příkazového řádku Databricks:
Postupujte podle pokynů ke kopírování knihovny pomocí rozhraní příkazového řádku Databricks.
Použití rozhraní příkazového řádku Databricks (kroky instalace)
Například zkopírování souboru JAR do dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Související obsah
Na jedenáctminutový úvod a ukázku této funkce se podívejte na video.