Binární soubor
Databricks Runtime podporuje binární souborový zdroj dat, který čte binární soubory a převádí každý soubor na jeden záznam, který obsahuje nezpracovaný obsah a metadata souboru. Zdroj dat binárního souboru vytvoří datový rámec s následujícími sloupci a případně i sloupci oddílů:
path (StringType): Cesta k souboru.modificationTime (TimestampType): Čas změny souboru. V některých implementacích Systému souborů Hadoop může být tento parametr nedostupný a hodnota by byla nastavena na výchozí hodnotu.length (LongType): Délka souboru v bajtech.content (BinaryType): Obsah souboru.
Chcete-li číst binární soubory, zadejte zdroj format dat jako binaryFile.
Obrázky
Databricks doporučuje, abyste k načtení dat obrázků použili zdroj dat binárního souboru.
Funkce Databricks display podporuje zobrazení dat obrázků načtených pomocí binárního zdroje dat.
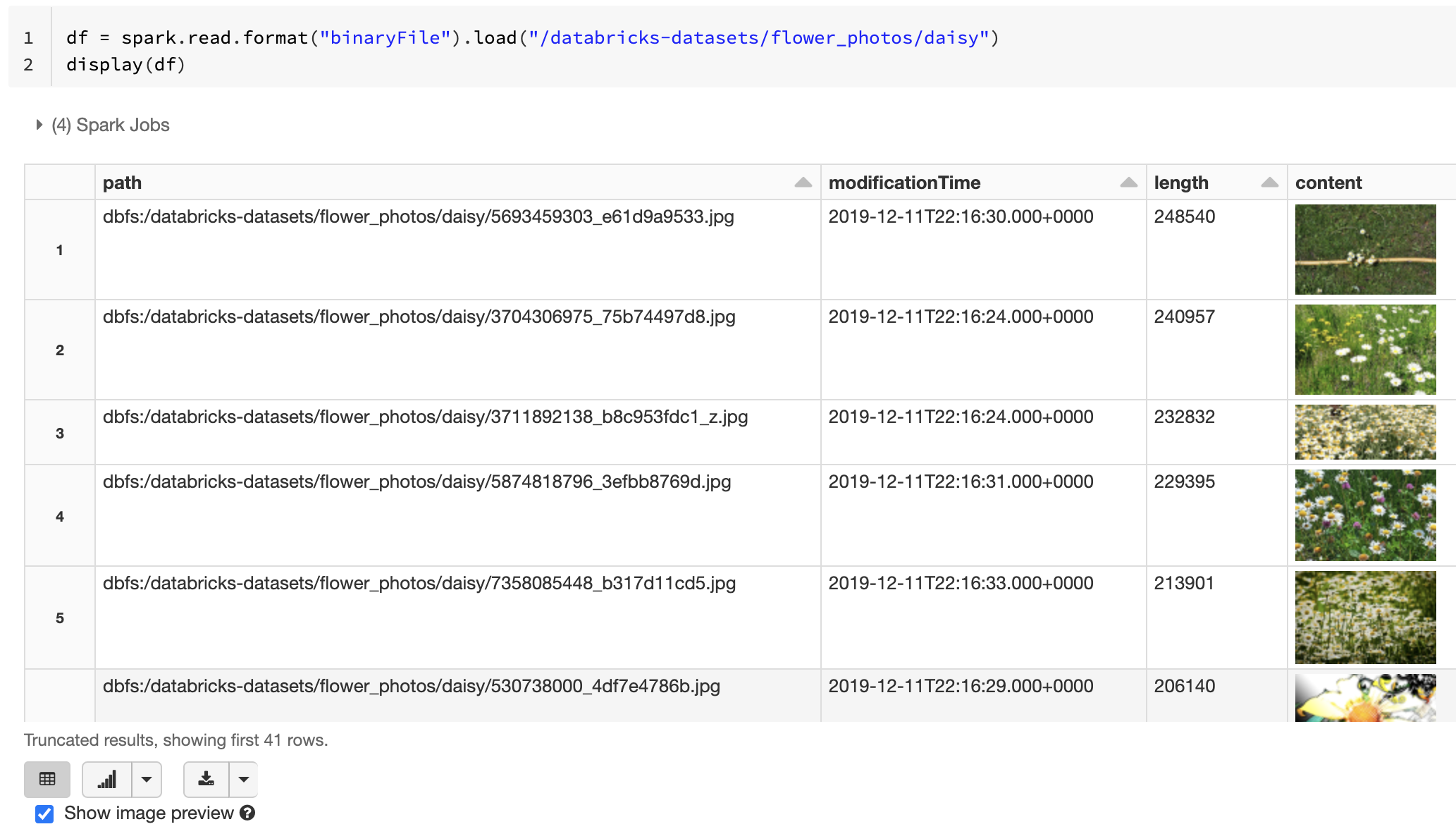
Pokud mají všechny načtené soubory název souboru s příponou obrázku, je náhled obrázku automaticky povolen:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
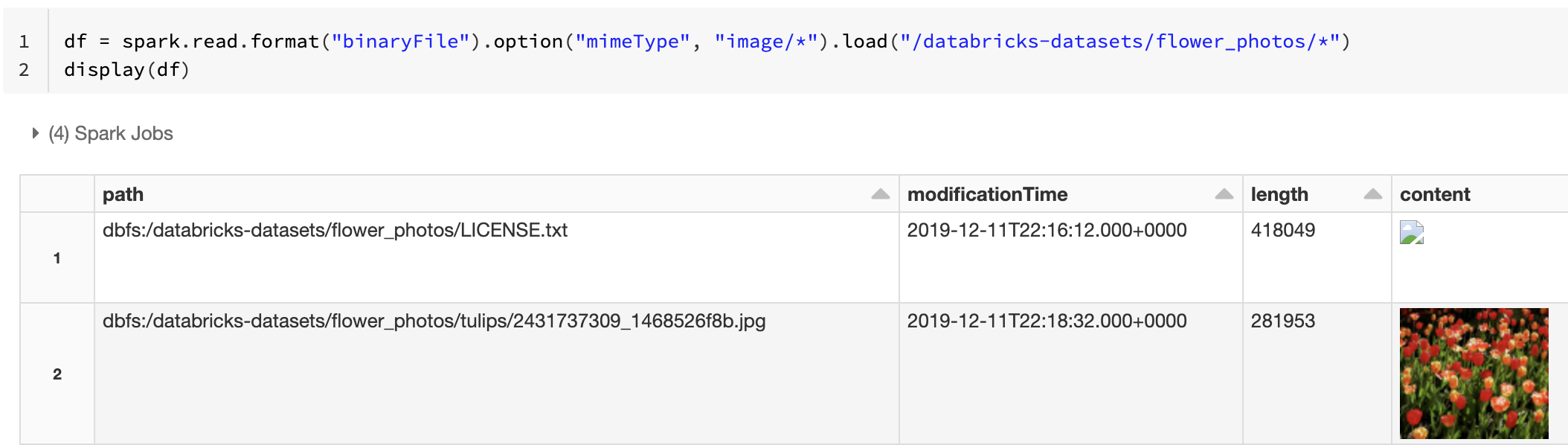
Alternativně můžete funkci náhledu obrázku vynutit pomocí mimeType možnosti s řetězcovou hodnotou "image/*" pro přidání poznámek k binárnímu sloupci. Obrázky jsou dekódovány na základě informací o formátu v binárním obsahu. Podporované typy obrázků jsou bmp, gif, jpega png. Nepodporované soubory se zobrazují jako ikona poškozeného obrázku.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Viz Referenční řešení pro aplikace obrázků pro doporučené pracovní postupy pro zpracování dat obrázků.
Možnosti
Pokud chcete načíst soubory s cestami odpovídajícími danému vzoru globu při zachování chování zjišťování oddílů, můžete použít pathGlobFilter tuto možnost. Následující kód načte všechny soubory JPG ze vstupního adresáře se zjišťováním oddílů:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Pokud chcete ignorovat zjišťování oddílů a rekurzivně prohledávat soubory ve vstupním adresáři, použijte tuto recursiveFileLookup možnost. Tato možnost vyhledává prostřednictvím vnořených adresářů, i když jejich názvy nedodržují schéma pojmenování oddílů, jako je date=2019-07-01.
Následující kód načte všechny soubory JPG rekurzivně ze vstupního adresáře a ignoruje zjišťování oddílů:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Podobná rozhraní API existují pro Scala, Javu a R.
Poznámka:
Pokud chcete zvýšit výkon čtení při načítání dat zpět, Azure Databricks doporučuje vypnout kompresi při ukládání dat načtených z binárních souborů:
spark.conf.set("spark.sql.parquet.compression.codec", "uncompressed")
df.write.format("delta").save("<path-to-table>")