Čtení a zápisy streamovaných tabulek Delta
Delta Lake je hluboce integrovaná se strukturovaným streamováním Sparku prostřednictvím readStream a writeStream. Delta Lake překonává řadu omezení, která jsou obvykle spojena se systémy a soubory streamování, včetně těchto:
- Shodování malých souborů vytvořených ingestováním s nízkou latencí
- Udržování zpracování "přesně jednou" s více než jedním datovým proudem (nebo souběžnými dávkovými úlohami).
- Efektivní zjišťování nových souborů při použití souborů jako zdroje datového proudu
Poznámka:
Tento článek popisuje použití tabulek Delta Lake jako zdrojů streamování a jímek. Informace o načtení dat pomocí streamovaných tabulek v Databricks SQL najdete v tématu Načítání dat pomocí streamovaných tabulek v Databricks SQL.
Tabulka Delta jako zdroj
Strukturované streamování přírůstkově čte tabulky Delta. Zatímco streamovací dotaz je aktivní vůči tabulce Delta, nové záznamy se zpracovávají idempotentním způsobem jako nové verze tabulek, které se potvrdí do zdrojové tabulky.
Následující příklady kódu ukazují konfiguraci čtení streamování pomocí názvu tabulky nebo cesty k souboru.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Důležité
Pokud se schéma tabulky Delta změní po zahájení čtení streamování s tabulkou, dotaz selže. U většiny změn schématu můžete datový proud restartovat, abyste vyřešili neshodu schématu a pokračovali ve zpracování.
V Databricks Runtime 12.2 LTS a níže nelze streamovat z tabulky Delta s povoleným mapováním sloupců, u kterého došlo k vývoji nesoudatného schématu, jako je přejmenování nebo vyřazení sloupců. Další informace najdete v článku Streamování s mapováním sloupců a změnami schématu.
Omezení vstupní rychlosti
Pro řízení mikrodávek jsou k dispozici následující možnosti:
maxFilesPerTrigger: Kolik nových souborů se má brát v úvahu v každé mikrodávce. Výchozí hodnota je 1 000.maxBytesPerTrigger: Kolik dat se zpracuje v každé mikrodávce. Tato možnost nastaví "soft max", což znamená, že dávkové procesy zpracovávají přibližně toto množství dat a můžou zpracovávat více než limit, aby se dotaz streamování v případech, kdy je nejmenší vstupní jednotka větší než tento limit. Tato možnost není ve výchozím nastavení nastavená.
Pokud používáte maxBytesPerTrigger ve spojení s maxFilesPerTrigger, mikrodávkové zpracovává data, dokud nedosáhnete limitu nebo maxBytesPerTrigger limitumaxFilesPerTrigger.
Poznámka:
V případech, kdy jsou transakce zdrojové tabulky vyčištěny z důvodu logRetentionDurationkonfigurace a streamovací dotaz se pokusí zpracovat tyto verze, dotaz ve výchozím nastavení se nezdaří zabránit ztrátě dat. Můžete nastavit možnost failOnDataLossfalse ignorovat ztracená data a pokračovat ve zpracování.
Streamování kanálu CDC (Delta Lake Change Data Capture)
Rozdílové změny záznamů datového kanálu Delta, včetně aktualizací a odstranění, se změní v tabulce Delta. Pokud je tato možnost povolená, můžete streamovat z datového kanálu změn a zapisovat logiku pro zpracování vkládání, aktualizací a odstraňování do podřízených tabulek. I když se výstup dat datového kanálu změn mírně liší od tabulky Delta, která popisuje, poskytuje řešení pro šíření přírůstkových změn do podřízených tabulek v architektuře medailiónu.
Důležité
V Databricks Runtime 12.2 LTS a níže nemůžete streamovat z datového kanálu změn pro tabulku Delta s povoleným mapováním sloupců, u kterého došlo k vývoji nesoudatného schématu, jako je přejmenování nebo vyřazení sloupců. Viz Streamování s mapováním sloupců a změnami schématu.
Ignorování aktualizací a odstranění
Strukturované streamování nezpracuje vstup, který není připojením, a vyvolá výjimku, pokud dojde k nějakým změnám v tabulce, která se používá jako zdroj. Existují dvě hlavní strategie pro řešení změn, které nelze automaticky rozšířit do podřízeného procesu:
- Výstup a kontrolní bod můžete odstranit a restartovat stream od začátku.
- Můžete nastavit jednu z těchto dvou možností:
ignoreDeletes: Ignorujte transakce, které odstraňují data na hranicích oddílů.skipChangeCommits: ignorujte transakce, které odstraňují nebo upravují existující záznamy.skipChangeCommitszahrnujeignoreDeletes.
Poznámka:
Ve službě Databricks Runtime 12.2 LTS a novějších skipChangeCommits je předchozí nastavení ignoreChangeszastaralé . V Databricks Runtime 11.3 LTS a nižší ignoreChanges je jedinou podporovanou možností.
Sémantika pro ignoreChanges se výrazně liší od skipChangeCommits. Pokud je ignoreChanges povolená, přepsané datové soubory ve zdrojové tabulce se znovu vysílají po operaci změny dat, jako je UPDATE, MERGE INTO, DELETE (v rámci oddílů) nebo OVERWRITE. Nezměněné řádky se často generují společně s novými řádky, takže podřízení příjemci musí být schopni zpracovávat duplicity. Odstranění se nešíří v podřízené části. ignoreChanges zahrnuje ignoreDeletes.
skipChangeCommits zcela ignoruje operace změny souborů. Datové soubory, které jsou přepsány ve zdrojové tabulce kvůli operaci změny dat, jako jsou UPDATE, MERGE INTO, DELETEa OVERWRITE jsou zcela ignorovány. Pokud chcete odrážet změny v nadřazených zdrojových tabulkách, musíte implementovat samostatnou logiku šíření těchto změn.
Úlohy nakonfigurované ignoreChanges tak, aby nadále fungovaly pomocí známé sémantiky, ale Databricks doporučuje používat skipChangeCommits pro všechny nové úlohy. Migrace úloh, které používají ignoreChanges k tomu, aby skipChangeCommits vyžadovaly logiku refaktoringu
Příklad
Předpokládejme například, že máte tabulku user_events s date, user_emaila action sloupce, které jsou rozděleny podle date. Streamujete z user_events tabulky a potřebujete z ní odstranit data z důvodu GDPR.
Když odstraníte hranice oddílů (to znamená, že se WHERE nachází ve sloupci oddílu), soubory jsou už segmentované podle hodnoty, takže odstranění tyto soubory jenom zahodí z metadat. Když odstraníte celý oddíl dat, můžete použít následující:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
Pokud odstraníte data v několika oddílech (v tomto příkladu filtrování user_email), použijte následující syntaxi:
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
Pokud aktualizujete user_email příkaz, UPDATE soubor obsahující danou user_email otázku se přepíše. Slouží skipChangeCommits k ignorování změněně datových souborů.
Zadat počáteční pozici
Pomocí následujících možností můžete určit výchozí bod zdroje streamování Delta Lake bez zpracování celé tabulky.
startingVersion: Verze Delta Lake, od které se má začít. Databricks doporučuje tuto možnost vynechat pro většinu úloh. Pokud není nastavený, datový proud začíná od nejnovější dostupné verze, včetně kompletního snímku tabulky v tuto chvíli.Pokud je zadaný, datový proud přečte všechny změny v tabulce Delta počínaje zadanou verzí (včetně). Pokud už zadaná verze není dostupná, stream se nespustí. Verze potvrzení můžete získat ze
versionsloupce výstupu příkazu DESCRIBE HISTORY .Chcete-li vrátit pouze nejnovější změny, zadejte
latest.startingTimestamp: Časové razítko, od které se má začít. Všechny změny tabulky potvrzené v časovém razítku (včetně) přečte čtenář streamování. Pokud zadané časové razítko předchází všem potvrzením tabulky, čtení streamování začíná nejstarším dostupným časovým razítkem. Jedna z těchto možností:- Řetězec časového razítka. Například
"2019-01-01T00:00:00.000Z". - Řetězec kalendářního data. Například
"2019-01-01".
- Řetězec časového razítka. Například
Obě možnosti nelze nastavit současně. Projeví se pouze při spuštění nového streamovacího dotazu. Pokud se spustil dotaz streamování a průběh se zaznamenal ve svém kontrolním bodu, tyto možnosti se ignorují.
Důležité
I když zdroj streamování můžete spustit ze zadané verze nebo časového razítka, schéma zdroje streamování je vždy nejnovější schéma tabulky Delta. Po zadané verzi nebo časovém razítku je nutné zajistit, aby nedošlo k žádné nekompatibilní změně schématu tabulky Delta. Jinak může zdroj streamování vrátit nesprávné výsledky při čtení dat s nesprávným schématem.
Příklad
Předpokládejme například, že máte tabulku user_events. Pokud chcete číst změny od verze 5, použijte:
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
Pokud chcete číst změny od 10. 10. 2018, použijte:
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
Zpracování počátečního snímku bez vyřazení dat
Poznámka:
Tato funkce je dostupná pro Databricks Runtime 11.3 LTS a vyšší. Tato funkce je ve verzi Public Preview.
Při použití tabulky Delta jako zdroje datového proudu dotaz nejprve zpracuje všechna data, která jsou v tabulce. Tabulka Delta v této verzi se nazývá počáteční snímek. Ve výchozím nastavení se datové soubory tabulky Delta zpracovávají na základě toho, který soubor byl naposledy změněn. Čas poslední změny však nemusí nutně představovat pořadí času události záznamu.
Ve stavovém streamovacím dotazu s definovaným vodoznakem může zpracování souborů časem úprav vést ke zpracování záznamů v nesprávném pořadí. To by mohlo vést k zahození záznamů o pozdních událostech vodoznakem.
Problém s odstraněním dat se můžete vyhnout povolením následující možnosti:
- withEventTimeOrder: Určuje, zda má být počáteční snímek zpracován s časovým pořadím událostí.
Pokud je povolené časové pořadí událostí, časový rozsah počátečních dat snímků je rozdělený do časových intervalů. Každá mikrodávka zpracovává kbelík filtrováním dat v rámci časového rozsahu. Možnosti konfigurace maxFilesPerTrigger a maxBytesPerTrigger se stále vztahují k řízení velikosti mikrobatchu, ale pouze přibližným způsobem kvůli povaze zpracování.
Následující obrázek ukazuje tento proces:
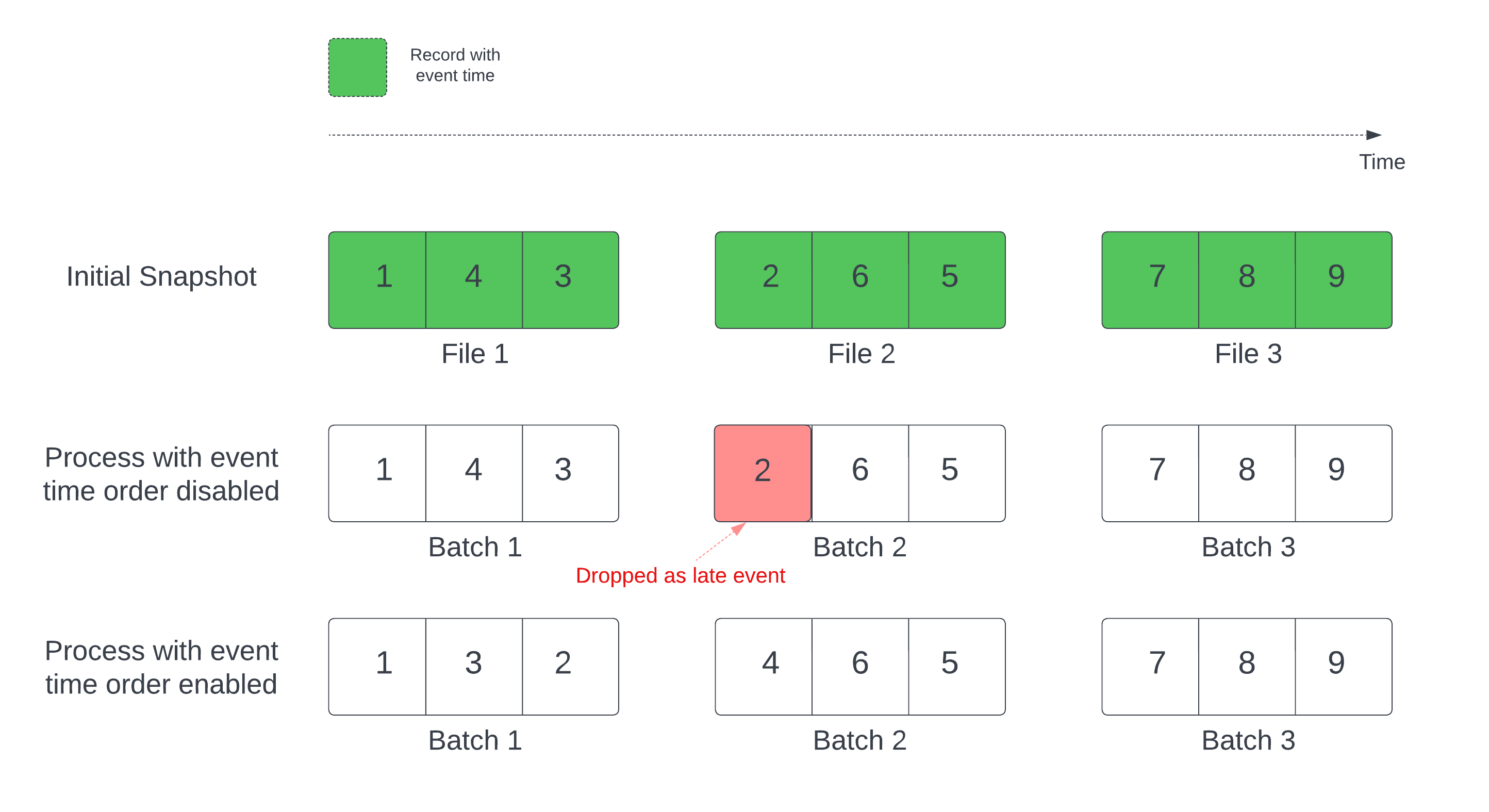
Důležité informace o této funkci:
- K problému s poklesem dat dochází pouze v případě, že se ve výchozím pořadí zpracuje počáteční snímek stavového streamovacího dotazu.
- Po spuštění dotazu streamu nelze změnit
withEventTimeOrder, když se počáteční snímek stále zpracovává. Pokud chcete restartovat změnywithEventTimeOrder, musíte kontrolní bod odstranit. - Pokud spouštíte dotaz streamu s povoleným parametremEventTimeOrder, nemůžete ho downgradovat na verzi DBR, která tuto funkci nepodporuje, dokud se počáteční zpracování snímku nedokončí. Pokud potřebujete downgradovat, můžete počkat na dokončení počátečního snímku nebo odstranit kontrolní bod a restartovat dotaz.
- Tato funkce není podporována v následujících neobvyklých scénářích:
- Sloupec čas události je vygenerovaný sloupec a mezi zdrojem Delta a vodoznakem existují transformace bez projekce.
- V dotazu streamu je vodoznak, který obsahuje více než jeden zdroj Delta.
- Pokud je povolené časové pořadí událostí, může být výkon počátečního zpracování snímků Delta pomalejší.
- Každá mikro batch prohledá počáteční snímek a vyfiltruje data v odpovídajícím časovém rozsahu událostí. Pokud chcete zrychlit akci filtrování, doporučujeme jako čas události použít sloupec zdroje Delta, aby bylo možné použít přeskočení dat (zkontrolujte , jestli se data přeskočí pro Delta Lake , pokud je to možné). Kromě toho může dělení tabulky ve sloupci času události dále urychlit zpracování. Můžete zkontrolovat uživatelské rozhraní Sparku a zjistit, kolik rozdílových souborů se kontroluje pro konkrétní mikrodávku.
Příklad
Předpokládejme, že máte tabulku user_events se sloupcem event_time . Dotaz streamování je agregační dotaz. Pokud chcete zajistit, aby během počátečního zpracování snímků nedošlo k žádnému poklesu dat, můžete použít:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
Poznámka:
Můžete to také povolit pomocí konfigurace Sparku v clusteru, který bude platit pro všechny dotazy streamování: spark.databricks.delta.withEventTimeOrder.enabled true
Tabulka Delta jako jímka
Data můžete také zapisovat do tabulky Delta pomocí strukturovaného streamování. Transakční protokol umožňuje službě Delta Lake zaručit přesně jedno zpracování, a to i v případě, že v tabulce běží souběžně jiné streamy nebo dávkové dotazy.
Poznámka:
Funkce Delta Lake VACUUM odebere všechny soubory, které nespravuje Delta Lake, ale přeskočí všechny adresáře, které začínají _. Kontrolní body můžete bezpečně ukládat společně s dalšími daty a metadaty pro tabulku Delta pomocí adresářové struktury, jako <table-name>/_checkpointsje například .
Metriky
Počet bajtů a počet souborů, které se ještě mají zpracovat v procesu dotazu streamování, můžete zjistit jako metriky numBytesOutstanding a numFilesOutstanding počet bajtů. Mezi další metriky patří:
numNewListedFiles: Počet souborů Delta Lake, které byly uvedeny pro výpočet backlogu pro tuto dávku.backlogEndOffset: Verze tabulky použitá k výpočtu backlogu.
Pokud stream spouštíte v poznámkovém bloku, můžete tyto metriky zobrazit na kartě Nezpracovaná data na řídicím panelu průběhu dotazu streamování:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Režim připojení
Ve výchozím nastavení se datové proudy spouští v režimu připojení, který přidává nové záznamy do tabulky.
Můžete použít metodu cesty:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
nebo metodu, a to toTable následujícím způsobem:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Režim dokončení
Pomocí strukturovaného streamování můžete také nahradit celou tabulku každou dávkou. Jedním z příkladů použití je výpočet souhrnu pomocí agregace:
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
Předchozí příklad průběžně aktualizuje tabulku, která obsahuje agregovaný počet událostí podle zákazníka.
U aplikací s vyššími požadavky na latenci můžete ušetřit výpočetní prostředky pomocí jednorázových aktivačních událostí. Tyto možnosti slouží k aktualizaci souhrnných agregačních tabulek podle daného plánu a zpracování pouze nových dat, která přišla od poslední aktualizace.
Provádění statických spojení datových proudů
Při provádění statických spojení streamů můžete spoléhat na transakční záruky a protokol správy verzí Delta Lake. Statické spojení streamu spojuje nejnovější platnou verzi tabulky Delta (statická data) s datovým proudem pomocí bezstavového spojení.
Když Azure Databricks zpracuje mikrodávku dat ve statickém spojení streamu, nejnovější platná verze dat ze statické tabulky Delta se spojí se záznamy, které jsou přítomné v aktuální mikrodávce. Vzhledem k tomu, že spojení je bezstavové, nemusíte konfigurovat vodoznaky a zpracovávat výsledky s nízkou latencí. Data ve statické tabulce Delta použitá ve spojení by se měla pomalu měnit.
streamingDF = spark.readStream.table("orders")
staticDF = spark.read.table("customers")
query = (streamingDF
.join(staticDF, streamingDF.customer_id==staticDF.id, "inner")
.writeStream
.option("checkpointLocation", checkpoint_path)
.table("orders_with_customer_info")
)
Upsertování ze streamovaných dotazů pomocí foreachBatch
Pomocí kombinace merge a foreachBatch zápisu složitých upsertů z streamovaného dotazu do tabulky Delta. Viz Použití příkazu foreachBatch k zápisu do libovolných datových jímek.
Tento model má mnoho aplikací, včetně následujících:
- Zápis agregací streamování v režimu aktualizace: Je to mnohem efektivnější než úplný režim.
- Zápis datového proudu změn databáze do tabulky Delta: Slučovací dotaz pro zápis dat změn lze použít
foreachBatchk nepřetržitému použití datového proudu změn v tabulce Delta. - Zápis datového proudu do tabulky Delta s odstraněním duplicitních dat: K průběžnému zápisu dat (s duplicitami) do tabulky Delta s automatickým odstraněním duplicitních dat se dá použít
foreachBatchslučovací dotaz jen pro vložení.
Poznámka:
- Ujistěte se, že příkaz
mergeuvnitřforeachBatchje idempotentní jako restartování streamovacího dotazu může operaci použít ve stejné dávce dat vícekrát. - Při
mergepoužití vforeachBatchsestavě může být vstupní rychlost dat streamovaného dotazu (hlášenáStreamingQueryProgressa viditelná v grafu rychlosti poznámkového bloku) hlášena jako násobek skutečné rychlosti, s jakou se data generují ve zdroji. Je to proto, žemergeněkolikrát přečte vstupní data, což způsobuje násobení vstupních metrik. Pokud se jedná o kritický bod, můžete datový rámec dávky uložit do mezipaměti předmergea pomergeuložení do mezipaměti zrušit.
Následující příklad ukazuje, jak můžete k provedení této úlohy použít SQL foreachBatch :
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Můžete se také rozhodnout použít rozhraní Delta Lake API k provádění přenosů streamování, jak je znázorněno v následujícím příkladu:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Zápisy do idempotentní tabulky foreachBatch
Poznámka:
Databricks doporučuje nakonfigurovat samostatný zápis streamování pro každou jímku, kterou chcete aktualizovat. Použití foreachBatch k zápisu do více tabulek serializuje zápisy, což snižuje paralelizaci a zvyšuje celkovou latenci.
Rozdílové tabulky podporují následující DataFrameWriter možnosti, které umožňují zápisy do více tabulek v rámci foreachBatch idempotentní:
txnAppId: Jedinečný řetězec, který můžete předat každému zápisu datového rámce. Můžete například použít ID StreamingQuery jakotxnAppId.txnVersion: Monotonicky rostoucí číslo, které funguje jako verze transakce.
Delta Lake používá kombinaci duplicitních txnAppId zápisů a txnVersion k jejich identifikaci a ignorování.
Pokud dojde k přerušení dávkového zápisu selháním, opětovným spuštěním dávky se použije stejná aplikace a ID dávky, aby modul runtime správně identifikoval duplicitní zápisy a ignoroval je. ID aplikace (txnAppId) může být libovolný jedinečný řetězec vygenerovaný uživatelem a nemusí souviset s ID datového proudu. Viz Použití příkazu foreachBatch k zápisu do libovolných datových jímek.
Upozorňující
Pokud odstraníte kontrolní bod streamování a restartujete dotaz s novým kontrolním bodem, musíte zadat jiný txnAppId. Nové kontrolní body začínají id dávky 0. Delta Lake používá ID dávky a txnAppId jako jedinečný klíč a přeskočí dávky s již viditelnými hodnotami.
Následující příklad kódu ukazuje tento vzor:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}