Práce se soubory na platformě Azure Databricks
Azure Databricks poskytuje několik nástrojů a rozhraní API pro interakci se soubory v následujících umístěních:
- Svazky katalogu Unity
- Soubory pracovního prostoru
- Cloudové úložiště objektů
- Připojení DBFS a kořen DBFS
- Dočasné úložiště připojené k uzlu ovladače clusteru
Tento článek obsahuje příklady pro interakci se soubory v těchto umístěních pro následující nástroje:
- Apache Spark
- Spark SQL a Databricks SQL
- Databricks systém souborů utitlities (
dbutils.fsnebo%fs) - Databricks CLI
- Databricks REST API
- Příkazy prostředí Bash (
%sh) - Instalace knihoven s vymezeným poznámkovým blokem pomocí
%pip - Pandy
- Nástroje pro správu a zpracování souborů Pythonu v OSS
Důležité
Operace se soubory, které vyžadují přístup fUSE k datům, nemají přímý přístup ke cloudovému úložišti objektů pomocí identifikátorů URI. Databricks doporučuje použít svazky katalogu Unity ke konfiguraci přístupu k těmto umístěním pro FUSE.
Scala nepodporuje FUSE pro svazky katalogu Unity ani soubory pracovních prostorů na výpočetních prostředcích nakonfigurovaných s režimem přístupu jednoho uživatele nebo clustery bez katalogu Unity. Scala podporuje FUSE pro svazky katalogu Unity a soubory pracovních prostorů na výpočetních prostředcích nakonfigurovaných pomocí katalogu Unity a režimu sdíleného přístupu.
Musím pro přístup k datům zadat schéma identifikátoru URI?
Cesty přístupu k datům v Azure Databricks se řídí jedním z následujících standardů:
Cesty ve stylu identifikátoru URI zahrnují schéma identifikátoru URI. Pro řešení přístupu k datům nativních pro Databricks jsou schémata identifikátorů URI volitelná pro většinu případů použití. Při přímém přístupu k datům v cloudovém úložišti objektů musíte zadat správné schéma identifikátoru URI pro typ úložiště.
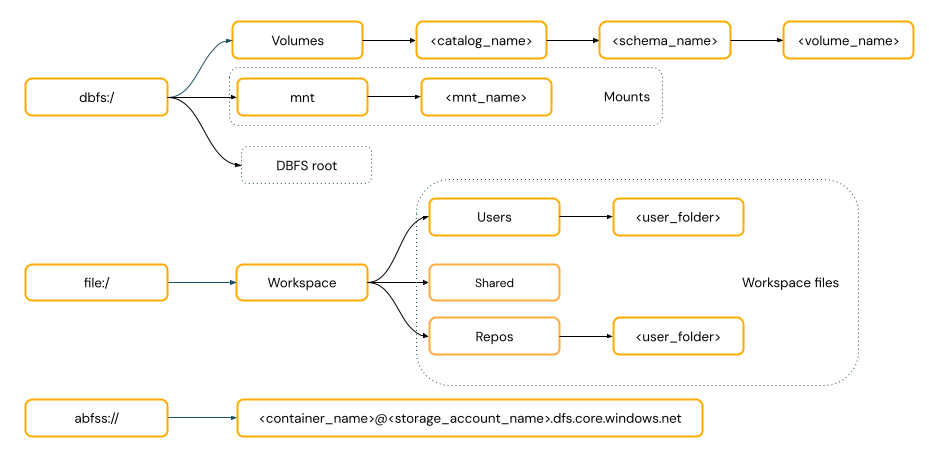
Cesty ve stylu POSIX poskytují přístup k datům vzhledem ke kořenovému adresáři ovladače (
/). Cesty stylu POSIX nikdy nevyžadují schéma. Svazky katalogu Unity nebo připojení DBFS můžete použít k zajištění přístupu k datům ve stylu POSIX v cloudovém úložišti objektů. Mnoho architektur ML a dalších modulů OSS Python vyžaduje FUSE a může používat pouze cesty ve stylu POSIX.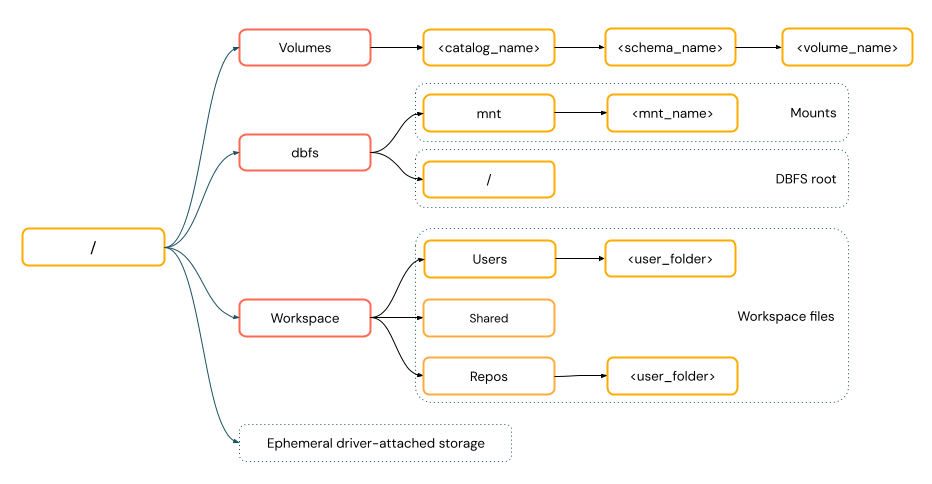
Práce se soubory ve svazcích katalogu Unity
Databricks doporučuje použít svazky katalogu Unity ke konfiguraci přístupu k ne tabulkovým datovým souborům uloženým v cloudovém úložišti objektů. Viz Vytvoření svazků a práce se svazky.
| Nástroj | Příklad |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL a Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Nástroje systému souborů Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Příkazy prostředí Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Instalace knihoven | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandy | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Poznámka:
Schéma dbfs:/ se vyžaduje při práci s rozhraním příkazového řádku Databricks.
Omezení svazků
Svazky mají následující omezení:
Přímé nebo nesekvenční (náhodné) zápisy, například zápis souborů ZIP a Excelu, nejsou podporovány. U úloh přímého připojení nebo náhodného zápisu nejprve proveďte operace na místním disku a pak výsledky zkopírujte do svazků katalogu Unity. Příklad:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')Řídké soubory nejsou podporovány. Pokud chcete kopírovat řídké soubory, použijte
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
Práce se soubory pracovního prostoru
Soubory pracovního prostoru Databricks jsou sadou souborů v pracovním prostoru, který nejsou poznámkovými bloky. Soubory pracovního prostoru můžete použít k ukládání a přístupu k datům a dalším souborům uloženým společně s poznámkovými bloky a dalšími prostředky pracovního prostoru. Vzhledem k tomu, že soubory pracovního prostoru mají omezení velikosti, databricks doporučuje ukládat jenom malé datové soubory, a to především pro vývoj a testování.
| Nástroj | Příklad |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL a Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Nástroje systému souborů Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Příkazy prostředí Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Instalace knihoven | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandy | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Poznámka:
Schéma file:/ se vyžaduje při práci s nástroji Databricks, Apache Sparkem nebo SQL.
Omezení souborů pracovního prostoru
Soubory pracovního prostoru mají následující omezení:
Velikost souboru pracovního prostoru je omezená na 500 MB z uživatelského rozhraní. Maximální povolená velikost souboru při zápisu z clusteru je 256 MB.
Pokud váš pracovní postup používá zdrojový kód umístěný ve vzdáleném úložišti Git, nemůžete zapisovat do aktuálního adresáře nebo zapisovat pomocí relativní cesty. Zapisujte data do jiných možností umístění.
Příkazy nelze použít
gitpři ukládání do souborů pracovního prostoru. Vytváření adresářů.gitnení v souborech pracovního prostoru povolené.Z výpočetních prostředků bez serveru existuje omezená podpora operací se soubory pracovního prostoru.
Exekutory nemohou zapisovat do souborů pracovního prostoru.
Symlinky nejsou podporovány.
K souborům pracovního prostoru nelze přistupovat z uživatelem definovaných funkcí (UDF) v clusterech s režimem sdíleného přístupu.
Kde jsou odstraněné soubory pracovního prostoru?
Odstraněním souboru pracovního prostoru se odešle do koše. Soubory můžete obnovit nebo trvale odstranit z koše pomocí uživatelského rozhraní.
Viz Odstranění objektu.
Práce se soubory v cloudovém úložišti objektů
Databricks doporučuje používat svazky katalogu Unity ke konfiguraci zabezpečeného přístupu k souborům v cloudovém úložišti objektů. Pokud se rozhodnete přímo přistupovat k datům v cloudovém úložišti objektů pomocí identifikátorů URI, musíte nakonfigurovat oprávnění. Viz Správa externích umístění, externích tabulek a externích svazků.
Následující příklady používají identifikátory URI pro přístup k datům v cloudovém úložišti objektů:
| Nástroj | Příklad |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL a Databricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| Nástroje systému souborů Databricks | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| Databricks CLI | Nepodporováno |
| Databricks REST API | Nepodporováno |
| Příkazy prostředí Bash | Nepodporováno |
| Instalace knihoven | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandy | Nepodporováno |
| OSS Python | Nepodporováno |
Poznámka:
Cloudové úložiště objektů nepodporuje předávání přihlašovacích údajů.
Práce se soubory v připojeních DBFS a kořenovém adresáři DBFS
Připojení DBFS se nedají zabezpečit pomocí katalogu Unity a databricks už nedoporučují. Data uložená v kořenovém adresáři DBFS jsou přístupná všem uživatelům v pracovním prostoru. Databricks doporučuje ukládat jakýkoli citlivý nebo produkční kód nebo data do kořenového adresáře DBFS. Podívejte se, co je systém souborů Databricks (DBFS)?
| Nástroj | Příklad |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL a Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Nástroje systému souborů Databricks | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| Databricks CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Příkazy prostředí Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Instalace knihoven | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandy | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
Poznámka:
Schéma dbfs:/ se vyžaduje při práci s rozhraním příkazového řádku Databricks.
Práce se soubory v dočasném úložišti připojeném k uzlu ovladače
Šifrované úložiště připojené k uzlu ovladače je blokové úložiště s nativním přístupem k cestě založené na POSIX. Všechna data uložená v tomto umístění zmizí, když se cluster ukončí nebo restartuje.
| Nástroj | Příklad |
|---|---|
| Apache Spark | Nepodporováno |
| Spark SQL a Databricks SQL | Nepodporováno |
| Nástroje systému souborů Databricks | dbutils.fs.ls("file:/path") %fs ls file:/path |
| Databricks CLI | Nepodporováno |
| Databricks REST API | Nepodporováno |
| Příkazy prostředí Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Instalace knihoven | Nepodporováno |
| Pandy | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
Poznámka:
Schéma file:/ se vyžaduje při práci s nástroji Databricks.
Přesun dat z dočasného úložiště do svazků
Možná budete chtít přistupovat k datům staženým nebo uloženým do dočasného úložiště pomocí Apache Sparku. Vzhledem k tomu, že dočasné úložiště je připojené k ovladači a Spark je distribuovaný modul pro zpracování, ne všechny operace můžou přímo přistupovat k datům. Pokud potřebujete přesunout data ze systému souborů ovladače do svazků katalogu Unity, můžete kopírovat soubory pomocí příkazů magic nebo nástrojů Databricks, jako v následujících příkladech:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro