Co je Apache Flink® ve službě Azure HDInsight v AKS? (Preview)
Důležité
Tato funkce je aktuálně dostupná jako ukázková verze. Doplňkové podmínky použití pro Microsoft Azure Preview obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi Preview nebo ještě nejsou vydány v obecné dostupnosti. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight o službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás o dalších aktualizacích v komunitě Azure HDInsight.
Apache Flink je architektura a distribuovaný modul pro zpracování stavových výpočtů přes nevázané a vázané datové proudy. Flink byl navržen tak, aby běžel ve všech běžných prostředích clusteru, prováděl výpočty a stavové streamované aplikace s rychlostí v paměti a v jakémkoli měřítku. Aplikace se paralelizují do tisíců úloh, které se distribuují a souběžně spouští v clusteru. Aplikace proto může používat neomezené množství vCPU, hlavní paměti, disku a vstupně-výstupních operací sítě. Flink navíc snadno udržuje velký stav aplikace. Jeho asynchronní a přírůstkový kontrolní algoritmus zajišťuje minimální vliv na latence zpracování a současně zaručuje přesně jednou konzistenci stavu.
Apache Flink je široce škálovatelný analytický modul pro zpracování datových proudů.
Mezi klíčové funkce, které Flink nabízí, patří:
- Operace s ohraničenými a nevázanými datovými proudy
- Výkon paměti
- Schopnost streamování i dávkových výpočtů
- Nízká latence, operace s vysokou propustností
- Přesně jednou za zpracování
- Vysoká dostupnost
- Odolnost proti stavu a chybám
- Plně kompatibilní s ekosystémem Hadoop
- Sjednocená rozhraní SQL API pro stream i batch
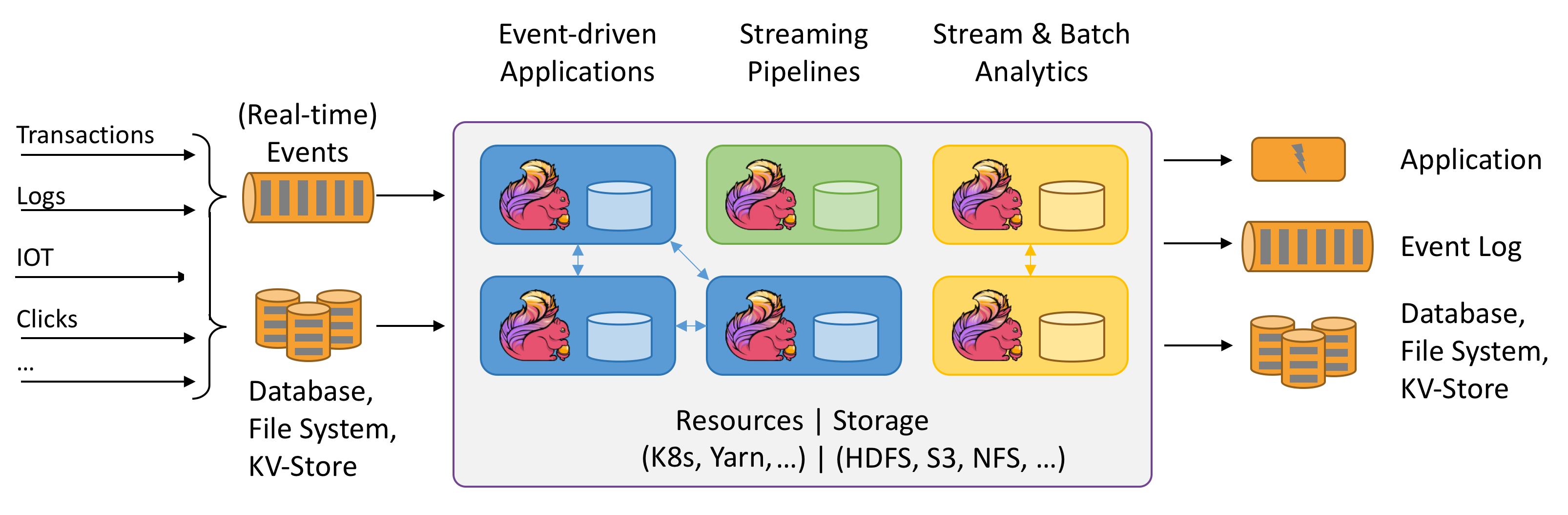
Proč Apache Flink?
Apache Flink je skvělou volbou pro vývoj a spouštění mnoha různých typů aplikací z důvodu rozsáhlé sady funkcí. Funkce Flinku zahrnují podporu pro zpracování datových proudů a dávek, sofistikovanou správu stavu, sémantiku zpracování času událostí a přesně jednou záruku konzistence pro stav. Flink nemá jediný bod selhání. Flink se ukázalo, že škáluje na tisíce jader a terabajtů stavu aplikace, zajišťuje vysokou propustnost a nízkou latenci a využívá některé z nejnáročnějších aplikací pro zpracování datových proudů na světě.
- Detekce podvodů: Flink se dá použít k detekci podvodných transakcí nebo aktivit v reálném čase pomocí složitých pravidel a modelů strojového učení na streamovaných datech.
- Detekce anomálií: Flink se dá použít k identifikaci odlehlých hodnot nebo neobvyklých vzorů v streamovaných datech, jako jsou čtení snímačů, síťový provoz nebo chování uživatelů.
- Upozorňování na základě pravidel: Flink se dá použít k aktivaci výstrah nebo oznámení na základě předdefinovaných podmínek nebo prahových hodnot streamovaných dat, jako je teplota, tlak nebo ceny akcií.
- Monitorování obchodních procesů: Flink je možné použít ke sledování a analýze stavu a výkonu obchodních procesů nebo pracovních postupů v reálném čase, například k plnění objednávky, doručení nebo zákaznické službě.
- Webová aplikace (sociální síť):Flink lze použít k napájení webových aplikací, které vyžadují zpracování dat generovaných uživatelem v reálném čase, jako jsou zprávy, lajky, komentáře nebo doporučení.
Další informace o běžných případech použití popsaných v případech použití Apache Flink
Clustery Apache Flink ve službě HDInsight v AKS jsou plně spravovaná služba. Tady jsou uvedené výhody vytvoření clusteru Flink ve službě HDInsight v AKS.
| Funkce | Popis |
|---|---|
| Snadné vytvoření | Pomocí webu Azure Portal, Azure PowerShellu nebo sady SDK můžete vytvořit nový cluster Flink v HDInsight v řádu minut. Viz Začínáme s clusterem Apache Flink ve službě HDInsight v AKS. |
| Jednoduché používání | Mezi clustery Flink ve službě HDInsight v AKS patří správa konfigurace založená na portálu a škálování. Kromě toho s rozhraním API pro správu úloh používáte rozhraní REST API nebo Azure Portal ke správě úloh. |
| Rozhraní REST API | Clustery Flink ve službě HDInsight v AKS zahrnují rozhraní API pro správu úloh, metodu odeslání úlohy Flink založené na rozhraní REST API pro vzdálené odesílání a monitorování úloh na webu Azure Portal. |
| Typ nasazení | Flink může spouštět aplikace v režimu relace nebo v režimu aplikace. HdInsight v AKS v současné době podporuje pouze clustery relací. V clusteru relací můžete spustit více úloh Flink. Režim aplikace je v plánu pro HDInsight v clusterech AKS. |
| Podpora metastoru | Clustery Flink ve službě HDInsight v AKS můžou podporovat katalogy s Metastorem Hive v různých otevřených formátech souborů se vzdálenými kontrolními body do Azure Data Lake Storage Gen2. |
| Podpora pro Azure Storage | Clustery Flink ve službě HDInsight můžou jako jímku souborů používat Azure Data Lake Storage Gen2. Další informace o Data Lake Storage Gen2 najdete v tématu Azure Data Lake Storage Gen2. |
| Integrace se službami Azure | Cluster Flink ve službě HDInsight v AKS se dodává s integrací do Kafka spolu se službou Azure Event Hubs a Azure HDInsight. Streamované aplikace můžete vytvářet pomocí služby Event Hubs nebo HDInsight. |
| Přizpůsobivost | HDInsight v AKS umožňuje škálovat uzly clusteru Flink na základě plánu pomocí funkce automatického škálování. Viz Automatické škálování Azure HDInsight v clusterech AKS. |
| Back-end stavu | HDInsight v AKS používá RocksDB jako výchozí StateBackend. RocksDB je vložené trvalé úložiště klíč-hodnota pro rychlé úložiště. |
| Kontrolní body | Ve službě HDInsight je ve výchozím nastavení v clusterech AKS povolené vytváření kontrolních bodů. Výchozí nastavení ve službě HDInsight v AKS udržuje posledních pět kontrolních bodů v trvalém úložišti. V případě selhání úlohy je možné úlohu restartovat z nejnovějšího kontrolního bodu. |
| Přírůstkové kontrolní body | RocksDB podporuje přírůstkové kontrolní body. Doporučujeme používat přírůstkové kontrolní body pro velký stav, musíte tuto funkci povolit ručně. Nastavení výchozího nastavení ve vašich flink-conf.yaml: state.backend.incremental: true povoleních přírůstkových kontrolních bodů, pokud aplikace toto nastavení v kódu nepřepíše. Tento příkaz je ve výchozím nastavení pravdivý. Tuto hodnotu můžete nakonfigurovat přímo v kódu (přepíše výchozí nastavení konfigurace). EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); Ve výchozím nastavení zachováváme posledních pět kontrolních bodů v nakonfigurované dir kontrolním bodu. Tuto hodnotu lze změnit změnou konfigurace v části správa konfigurace. state.checkpoints.num-retained: 5 |
Mezi clustery Apache Flink ve službě HDInsight v AKS patří následující komponenty, které jsou ve výchozím nastavení dostupné v clusterech.
Podívejte se na plán , co připravujeme.
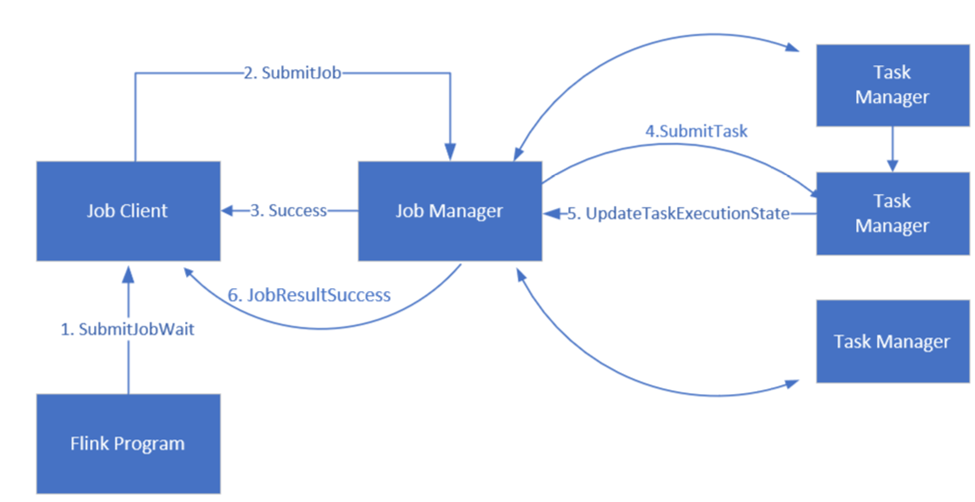
Správa úloh Apache Flink
Flink plánuje úlohy pomocí tří distribuovaných komponent, správce úloh, správce úloh a klienta úloh, které jsou nastaveny v modelu leader-follower.
Flink Job: Úloha nebo program Flink se skládá z více úkolů. Úkoly jsou základní jednotkou provádění v Flinku. Každá úloha Flink má více instancí v závislosti na úrovni paralelismu a každá instance se provádí v TaskManageru.
Správce úloh: Správce úloh funguje jako plánovač a plánuje úkoly na manažerech úkolů.
Správce úloh: Správci úkolů mají jeden nebo více slotů pro paralelní spouštění úkolů.
Klient úlohy: Klient úlohy komunikuje se správcem úloh za účelem odeslání úloh Flink.
Webové uživatelské rozhraní Flink: Flink nabízí webové uživatelské rozhraní pro kontrolu, monitorování a ladění spuštěných aplikací.
Reference
- Web Apache Flink
- Názvy apache, Apache Kafka, Kafka, Apache Flink, Flink a přidružených opensourcových projektů jsou ochranné známky Apache Software Foundation (ASF).