Použití nástrojů Spark &Hive pro Visual Studio Code
Naučte se používat nástroje Apache Spark a Hive pro Visual Studio Code. Pomocí nástrojů můžete vytvářet a odesílat dávkové úlohy Apache Hive, interaktivní dotazy Hive a skripty PySpark pro Apache Spark. Nejprve popíšeme, jak nainstalovat nástroje Spark &Hive v editoru Visual Studio Code. Pak si ukážeme, jak odesílat úlohy do nástrojů Spark a Hive.
Nástroje Spark a Hive je možné nainstalovat na platformy podporované nástrojem Visual Studio Code. Všimněte si následujících požadavků pro různé platformy.
Požadavky
K dokončení kroků v tomto článku jsou vyžadovány následující položky:
- Cluster Azure HDInsight. Pokud chcete vytvořit cluster, přečtěte si téma Začínáme se službou HDInsight. Nebo použijte cluster Spark a Hive, který podporuje koncový bod Apache Livy.
- Visual Studio Code.
- Mono. Mono se vyžaduje jenom pro Linux a macOS.
- Interaktivní prostředí PySpark pro Visual Studio Code
- Místní adresář. Tento článek používá C:\HD\HDexample.
Instalace nástrojů Spark a Hive
Jakmile splníte požadavky, můžete nainstalovat Nástroje Spark &Hive pro Visual Studio Code pomocí následujících kroků:
Otevřete Visual Studio Code.
V řádku nabídek přejděte na Zobrazit>rozšíření.
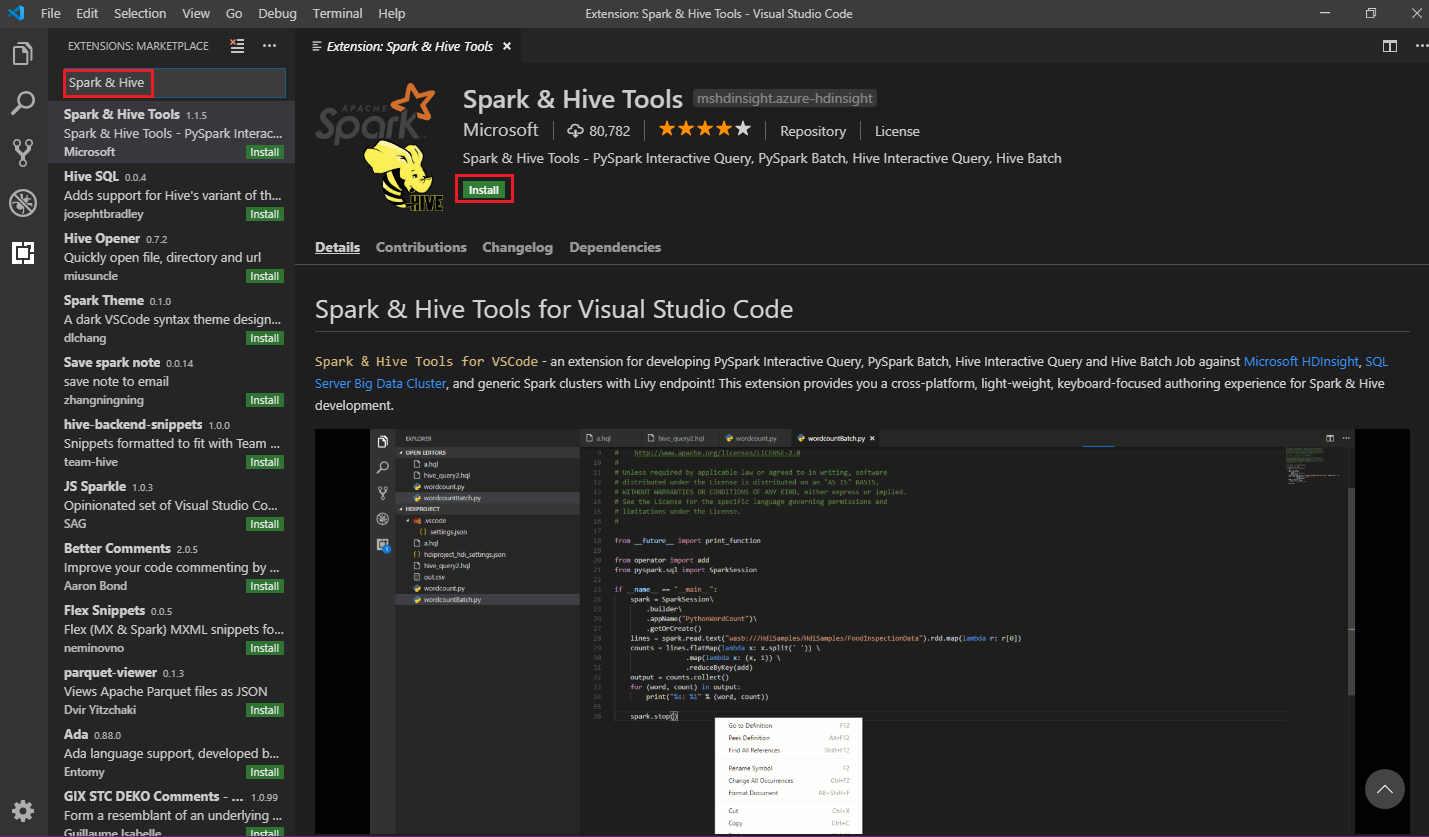
Do vyhledávacího pole zadejte Spark a Hive.
Ve výsledcích hledání vyberte Nástroje Spark a Hive a pak vyberte Nainstalovat:
V případě potřeby vyberte Znovu načíst .
Otevření pracovní složky
Pokud chcete otevřít pracovní složku a vytvořit soubor v editoru Visual Studio Code, postupujte takto:
V řádku nabídek přejděte do složky Otevřít soubor...>>C:\HD\HDexample a pak vyberte tlačítko Vybrat složku. Složka se zobrazí v zobrazení Průzkumníka vlevo.
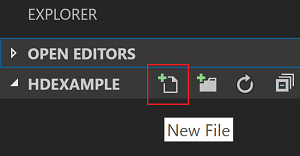
V zobrazení Průzkumníka vyberte složku HDexample a pak vyberte ikonu Nový soubor vedle pracovní složky:
Nový soubor pojmenujte pomocí
.hqlpřípony souboru (dotazy Hive) nebo (skript Sparku.py). Tento příklad používá HelloWorld.hql.
Nastavení prostředí Azure
Pro uživatele národního cloudu nejprve nastavte prostředí Azure pomocí následujícího postupu a pak pomocí příkazu Azure: Přihlásit se k Azure:
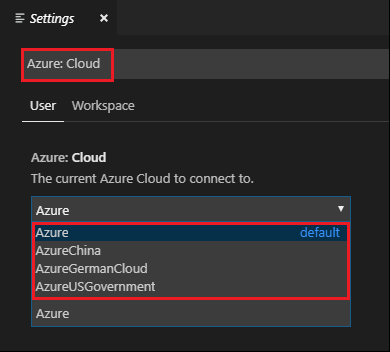
Přejděte do předvoleb> souborů>Nastavení.
Vyhledejte následující řetězec: Azure: Cloud.
Ze seznamu vyberte národní cloud:
Připojení k účtu Azure
Než budete moct odesílat skripty do clusterů ze sady Visual Studio Code, může se uživatel přihlásit k předplatnému Azure nebo propojit cluster HDInsight. Pro připojení ke clusteru HDInsight použijte přihlašovací údaje a heslo nebo přihlašovací údaje připojené k doméně clusteru ESP. Pokud se chcete připojit k Azure, postupujte takto:
Na řádku nabídek přejděte do palety příkazů Zobrazit>... a zadejte Azure: Přihlásit se:
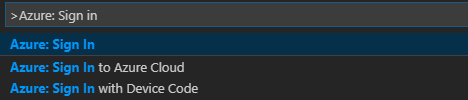
Podle pokynů pro přihlášení se přihlaste k Azure. Po připojení se název vašeho účtu Azure zobrazí na stavovém řádku v dolní části okna editoru Visual Studio Code.
Propojení clusteru
Odkaz: Azure HDInsight
Normální cluster můžete propojit pomocí uživatelského jména spravovaného apache Ambari nebo můžete propojit zabezpečený cluster Hadoop Enterprise Security Pack pomocí uživatelského jména domény (například: user1@contoso.com).
Na řádku nabídek přejděte na Paletu příkazů Zobrazení>... a zadejte Spark / Hive: Propojení clusteru.

Vyberte typ propojeného clusteru Azure HDInsight.
Zadejte adresu URL clusteru HDInsight.
Zadejte své uživatelské jméno Ambari; výchozí hodnota je admin.
Zadejte heslo Ambari.
Vyberte typ clusteru.
Nastavte zobrazovaný název clusteru (volitelné).
Zkontrolujte zobrazení VÝSTUP pro ověření.
Poznámka:
Propojené uživatelské jméno a heslo se použijí, pokud se cluster přihlásí k předplatnému Azure a propojí cluster.
Odkaz: Obecný koncový bod Livy
Na řádku nabídek přejděte na Paletu příkazů Zobrazení>... a zadejte Spark / Hive: Propojení clusteru.
Vyberte typ propojeného clusteru – Obecný koncový bod Livy.
Zadejte obecný koncový bod Livy. Příklad: http://10.172.41.42:18080.
Vyberte typ autorizace Basic nebo None. Pokud vyberete Základní:
Zadejte své uživatelské jméno Ambari; výchozí hodnota je admin.
Zadejte heslo Ambari.
Zkontrolujte zobrazení VÝSTUP pro ověření.
Výpis clusterů
Na řádku nabídek přejděte na Paletu příkazů Zobrazení>... a zadejte Spark / Hive: List Cluster.
Vyberte požadované předplatné.
Zkontrolujte zobrazení VÝSTUP. Toto zobrazení zobrazuje váš propojený cluster (nebo clustery) a všechny clustery v rámci vašeho předplatného Azure:

Nastavení výchozího clusteru
Znovu otevřete složku HDexample, která byla popsána dříve, pokud je zavřená.
Vyberte soubor HelloWorld.hql, který byl vytvořen dříve. Otevře se v editoru skriptů.
Klikněte pravým tlačítkem myši na editor skriptů a pak vyberte Spark / Hive: Nastavit výchozí cluster.
Připojení ke svému účtu Azure nebo pokud jste to ještě neudělali, propojte cluster.
Vyberte cluster jako výchozí cluster pro aktuální soubor skriptu. Nástroje automaticky aktualizují . Konfigurační soubor VSCode\settings.json :
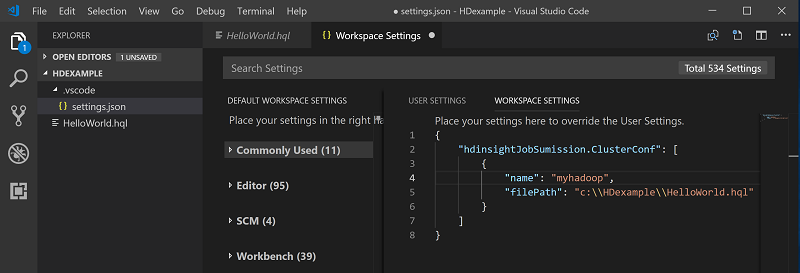
Odesílání interaktivních dotazů Hive a dávkových skriptů Hive
Pomocí nástrojů Spark &Hive pro Visual Studio Code můžete do clusterů odesílat interaktivní dotazy Hive a dávkové skripty Hive.
Znovu otevřete složku HDexample, která byla popsána dříve, pokud je zavřená.
Vyberte soubor HelloWorld.hql, který byl vytvořen dříve. Otevře se v editoru skriptů.
Zkopírujte a vložte následující kód do souboru Hive a uložte ho:
SELECT * FROM hivesampletable;Připojení ke svému účtu Azure nebo pokud jste to ještě neudělali, propojte cluster.
Klikněte pravým tlačítkem na editor skriptů a vyberte Hive: Interaktivní k odeslání dotazu nebo použijte klávesovou zkratku Ctrl+Alt+I. Vyberte Hive: Batch k odeslání skriptu nebo použijte klávesovou zkratku Ctrl+Alt+H.
Pokud jste nezadali výchozí cluster, vyberte cluster. Nástroje také umožňují odeslat blok kódu místo celého souboru skriptu pomocí místní nabídky. Po chvíli se výsledky dotazu zobrazí na nové kartě:
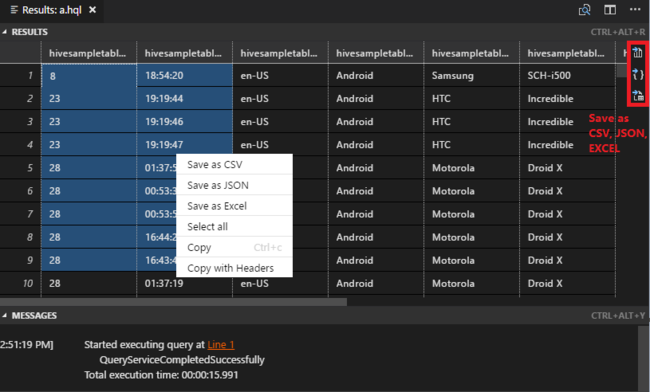
Panel VÝSLEDKŮ : Celý výsledek můžete uložit jako soubor CSV, JSON nebo Excel do místní cesty nebo vybrat několik řádků.
PANEL ZPRÁVY : Když vyberete číslo řádku , přejde na první řádek spuštěného skriptu.
Odesílání interaktivních dotazů PySpark
Předpoklad pro interaktivní Pyspark
Všimněte si zde, že verze rozšíření Jupyter (ms-jupyter): v2022.1.1001614873 a verze rozšíření Pythonu (ms-python): v2021.12.1559732655, Python 3.6.x a 3.7.x jsou vyžadovány pro interaktivní dotazy PySpark hdInsight.
Uživatelé můžou PySpark interaktivně provádět následujícími způsoby.
Použití interaktivního příkazu PySpark v souboru PY
Pomocí interaktivního příkazu PySpark odešlete dotazy takto:
Znovu otevřete složku HDexample, která byla popsána dříve, pokud je zavřená.
Vytvořte nový soubor HelloWorld.py podle předchozích kroků.
Zkopírujte a vložte následující kód do souboru skriptu:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Výzva k instalaci jádra PySpark/Synapse Pyspark se zobrazí v pravém dolním rohu okna. Kliknutím na tlačítko Nainstalovat můžete pokračovat pro instalace PySpark/Synapse Pyspark. Nebo můžete kliknout na tlačítko Přeskočit a tento krok přeskočit.
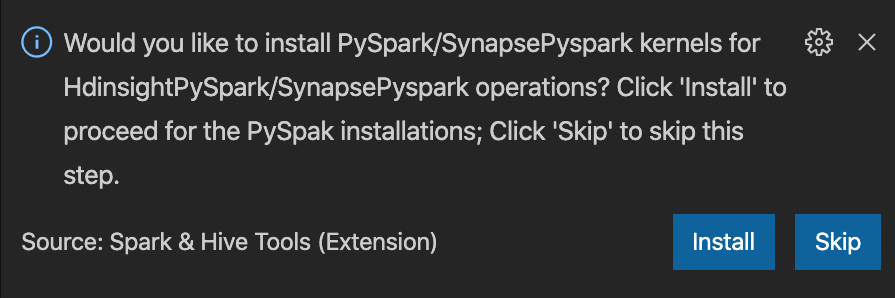
Pokud ho budete potřebovat nainstalovat později, můžete přejít na Předvolbu> souborů>Nastavení a pak zrušit zaškrtnutí políčka HDInsight: Povolit přeskočit instalaci Pyspark v nastavení.
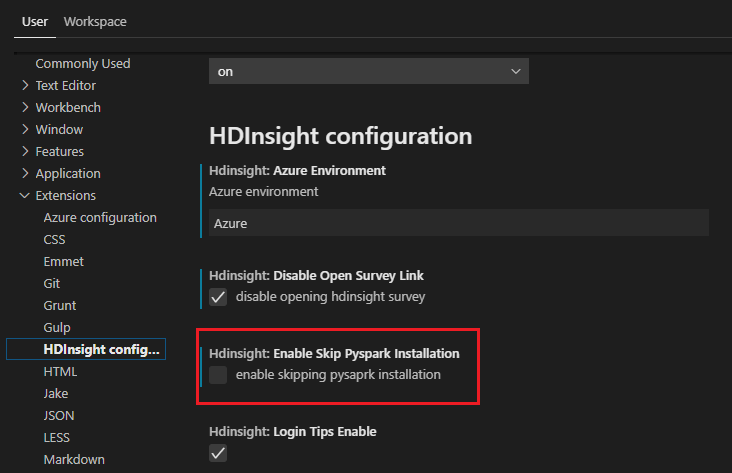
Pokud je instalace úspěšná v kroku 4, zobrazí se v pravém dolním rohu okna okno se zprávou "PySpark nainstalováno úspěšně". Kliknutím na tlačítko Znovu načíst okno.

Na řádku nabídek přejděte na Paletu příkazů zobrazení>... nebo použijte klávesovou zkratku Shift + Ctrl + P a zadejte Python: Vyberte interpret a spusťte Jupyter Server.

Níže vyberte možnost Pythonu.

Na řádku nabídek přejděte na Paletu příkazů zobrazení>... nebo použijte klávesovou zkratku Shift + Ctrl + P a zadejte Vývojář: Znovu načíst okno.

Připojení ke svému účtu Azure nebo pokud jste to ještě neudělali, propojte cluster.
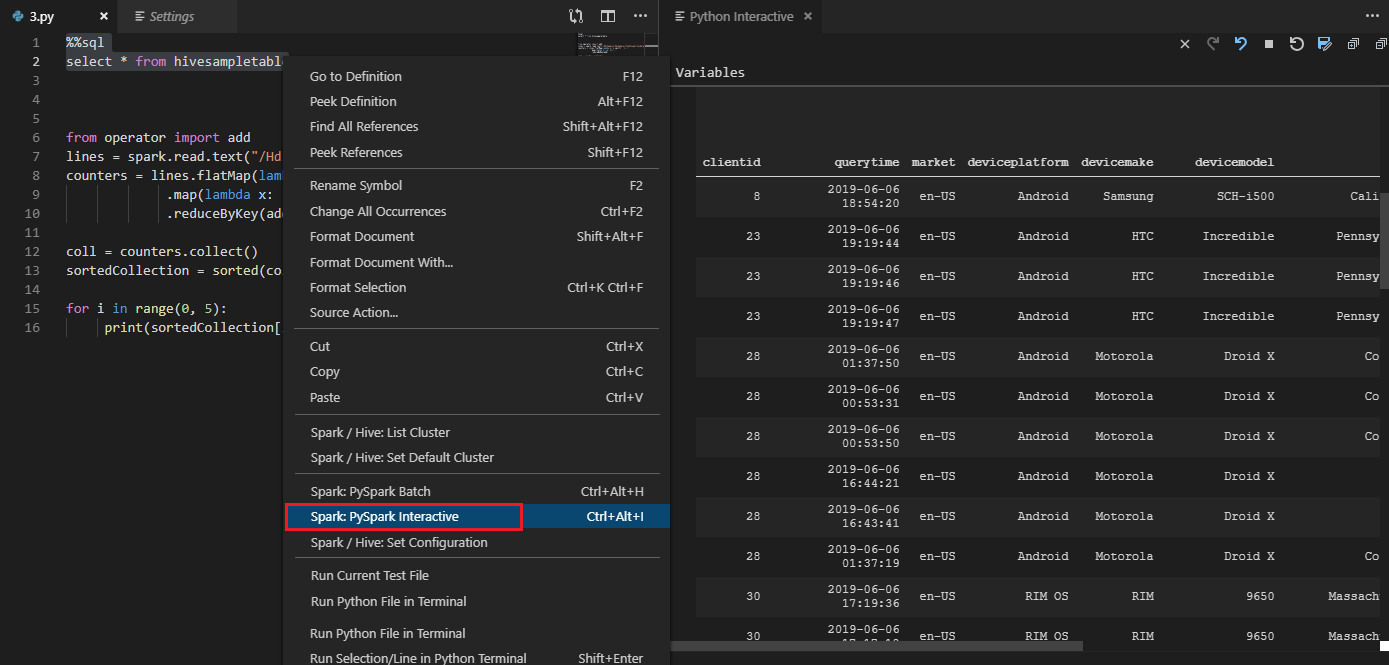
Vyberte veškerý kód, klikněte pravým tlačítkem na editor skriptů a vyberte Spark: PySpark Interactive / Synapse: Pyspark Interactive a odešlete dotaz.
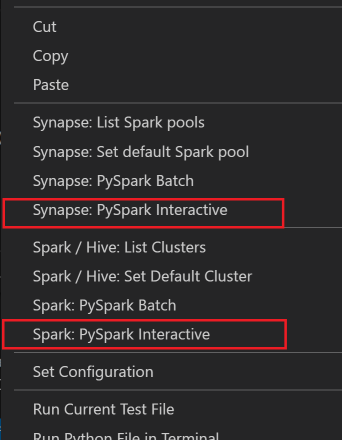
Vyberte cluster, pokud jste nezadali výchozí cluster. Po chvíli se interaktivní výsledky Pythonu zobrazí na nové kartě. Kliknutím na PySpark přepněte jádro na PySpark / Synapse Pyspark a kód se úspěšně spustí. Pokud chcete přepnout na jádro Synapse Pyspark, doporučujeme zakázat automatické nastavení na webu Azure Portal. V opačném případě může trvat delší dobu, než se cluster probudí a poprvé se použije jádro Synapse. Pokud nástroje také umožňují odeslat blok kódu místo celého souboru skriptu pomocí místní nabídky:
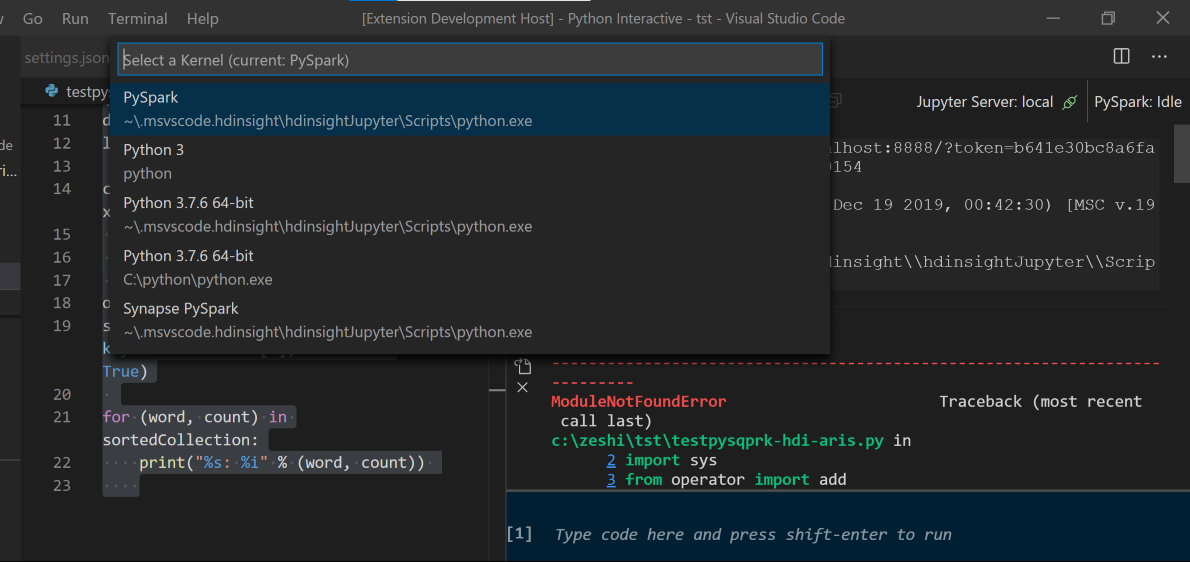
Zadejte %%info a stisknutím shift+Enter zobrazte informace o úloze (volitelné):
Nástroj také podporuje dotaz Spark SQL :
Provádění interaktivních dotazů v souboru PY pomocí komentáře #%%
Přidejte #%% před kód Py, abyste získali prostředí poznámkového bloku.
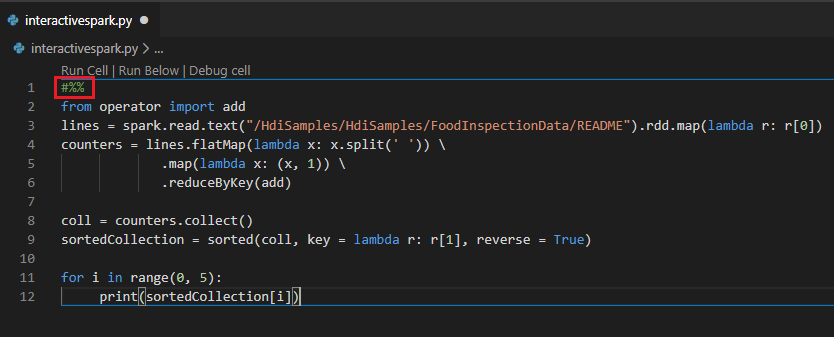
Klikněte na Spustit buňku. Po chvíli se interaktivní výsledky Pythonu zobrazí na nové kartě. Kliknutím na PySpark přepněte jádro na PySpark/Synapse PySpark a potom znovu klikněte na Spustit buňku a kód se úspěšně spustí.
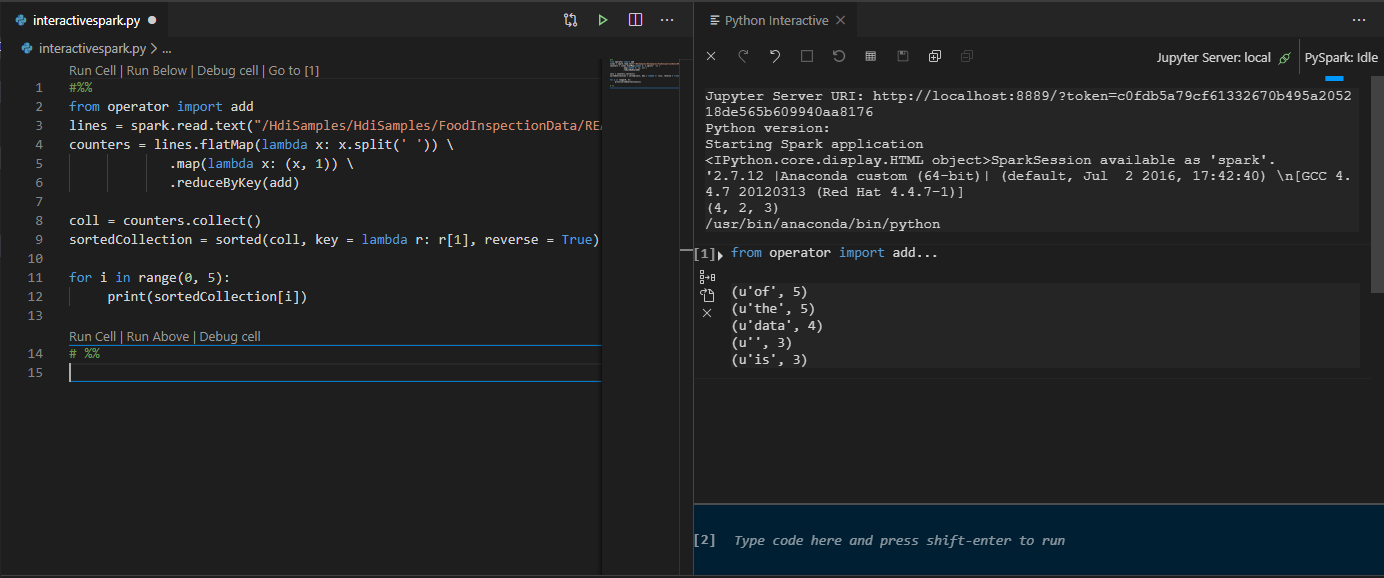
Využití podpory IPYNB z rozšíření Pythonu
Poznámkový blok Jupyter můžete vytvořit příkazem z palety příkazů nebo vytvořením nového souboru .ipynb ve vašem pracovním prostoru. Další informace najdete v tématu Práce s poznámkovými bloky Jupyter v editoru Visual Studio Code.
Klikněte na tlačítko Spustit buňku , postupujte podle pokynů k nastavení výchozího fondu Spark (důrazně doporučujeme nastavit výchozí cluster nebo fond pokaždé před otevřením poznámkového bloku) a pak znovu načíst okno.
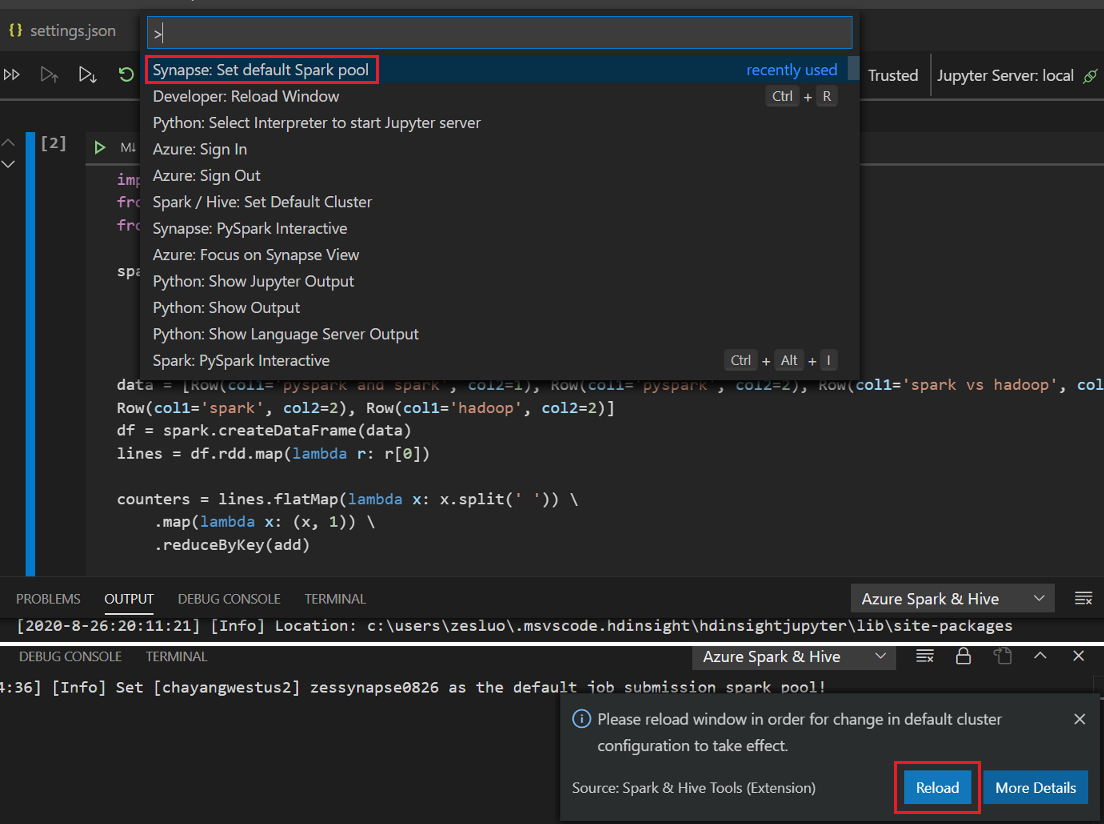
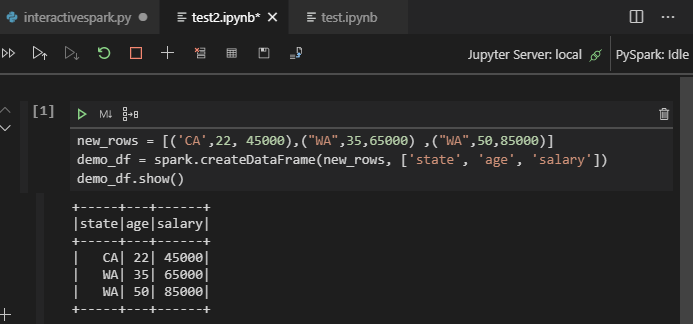
Kliknutím na PySpark přepněte jádro na PySpark / Synapse Pyspark a po chvíli se zobrazí výsledek.
Poznámka:
U chyby instalace Synapse PySpark, protože její závislost už nebude udržována jiným týmem, už nebude zachována. Pokud se pokoušíte používat Synapse Pyspark interactive, přepněte místo toho na azure Synapse Analytics . A je to dlouhodobá změna.
Odeslání dávkové úlohy PySpark
Znovu otevřete složku HDexample, kterou jste probrali dříve, pokud je zavřená.
Pomocí předchozích kroků vytvořte nový soubor BatchFile.py.
Zkopírujte a vložte následující kód do souboru skriptu:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Připojení ke svému účtu Azure nebo pokud jste to ještě neudělali, propojte cluster.
Klikněte pravým tlačítkem myši na editor skriptů a vyberte Spark: PySpark Batch nebo Synapse: PySpark Batch*.
Výběrem fondu clusteru nebo Sparku odešlete úlohu PySpark do:
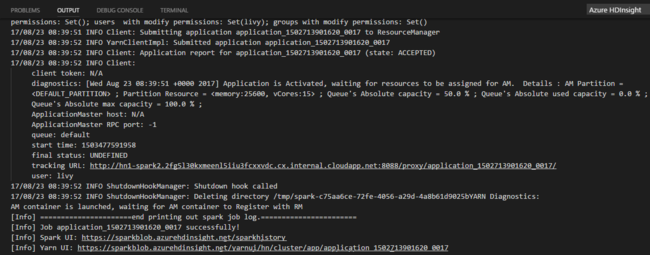
Po odeslání úlohy Pythonu se v okně VÝSTUP v editoru Visual Studio Code zobrazí protokoly odeslání. Zobrazí se také adresa URL uživatelského rozhraní Sparku a adresa URL uživatelského rozhraní Yarn. Pokud odešlete dávkovou úlohu do fondu Apache Sparku, zobrazí se také adresa URL uživatelského rozhraní historie Sparku a adresa URL uživatelského rozhraní aplikace úloh Sparku. Adresu URL můžete otevřít ve webovém prohlížeči a sledovat stav úlohy.
Integrace se zprostředkovatelem identit HDInsight (HIB)
Připojení do clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB)
Pokud se chcete připojit ke clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB), můžete se přihlásit k předplatnému Azure podle normálních kroků. Po přihlášení se v Azure Exploreru zobrazí seznam clusterů. Další pokyny najdete v tématu Připojení ke clusteru HDInsight.
Spuštění úlohy Hive/PySpark v clusteru HDInsight ESP se zprostředkovatelem ID (HIB)
Pro spuštění úlohy Hive můžete postupovat podle normálních kroků a odeslat úlohu do clusteru HDInsight ESP s zprostředkovatelem ID (HIB). Další pokyny najdete v tématu Odesílání interaktivních dotazů Hive a dávkových skriptů Hive.
Pro spuštění interaktivní úlohy PySpark můžete úlohu odeslat do clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB). Projděte si interaktivní dotazy PySpark.
Pro spuštění dávkové úlohy PySpark můžete úlohu odeslat do clusteru HDInsight ESP pomocí zprostředkovatele ID (HIB). Další pokyny najdete v části Odeslání dávkové úlohy PySpark.
Konfigurace Apache Livy
Podporuje se konfigurace Apache Livy . Můžete ho nakonfigurovat v souboru . VSCode\settings.json soubor ve složce pracovního prostoru. Konfigurace Livy v současné době podporuje pouze skript Pythonu. Další informace naleznete v tématu Livy README.
Metoda 1
- V řádku nabídek přejděte na Předvolby> souborů>Nastavení.
- Do pole Nastavení hledání zadejte odeslání úlohy HDInsight: Livy Conf.
- Vyberte Upravit v settings.json pro příslušný výsledek hledání.
Metoda 2
Odešlete soubor a všimněte si, že se .vscode složka automaticky přidá do pracovní složky. Konfiguraci Livy zobrazíte tak , že vyberete .vscode\settings.json.
Nastavení projektu:
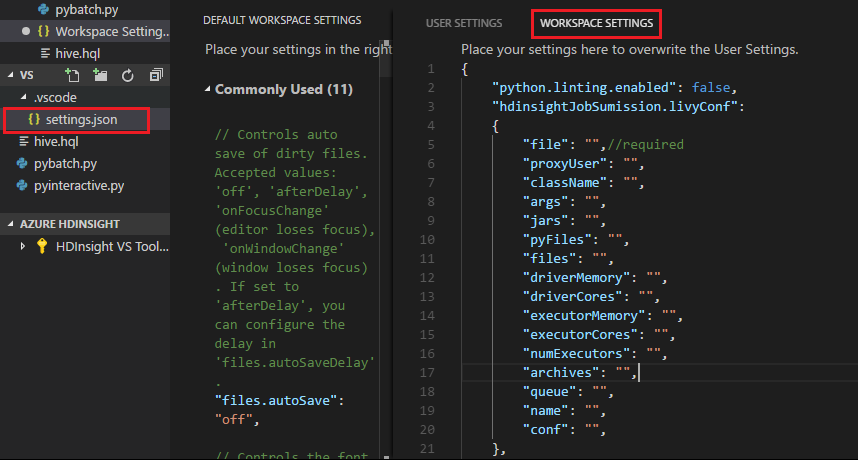
Poznámka:
Pro nastavení driverMemory a executorMemory nastavte hodnotu a jednotku. Příklad: 1g nebo 1024m.
Podporované konfigurace Livy:
POST /batches
Text požadavku
name description type soubor Soubor obsahující aplikaci, která se má provést Cesta (povinné) proxyUser Uživatel, který se při spuštění úlohy zosobní String Classname Hlavní třída Application Java/Spark String args Argumenty příkazového řádku pro aplikaci Seznam řetězců Sklenice Jars, které se mají použít v této relaci Seznam řetězců pyFiles Soubory Pythonu, které se mají použít v této relaci Seznam řetězců files Soubory, které se mají použít v této relaci Seznam řetězců driverMemory Množství paměti, které se má použít pro proces ovladače String driverCores Počet jader, která se mají použít pro proces ovladače Int executorMemory Množství paměti pro jednotlivé procesy exekutoru String executorCores Počet jader, která se mají použít pro každý exekutor Int numExecutors Počet spuštění exekutorů pro tuto relaci Int Archiv Archivy, které se mají použít v této relaci Seznam řetězců fronta Název fronty YARN, do které se má odeslat String name Název této relace String Conf Vlastnosti konfigurace Sparku Mapa klíče=val Text odpovědi: Vytvořený objekt Batch.
name description type ID ID relace Int appId ID aplikace této relace String appInfo Podrobné informace o aplikaci Mapa klíče=val protokol Řádky protokolu Seznam řetězců state Stav dávky String Poznámka:
Přiřazená konfigurace Livy se při odeslání skriptu zobrazí v podokně výstupu.
Integrace se službou Azure HDInsight z Exploreru
Tabulku Hive ve svých clusterech můžete zobrazit ve verzi Preview přímo prostřednictvím Průzkumníka Azure HDInsight :
Připojení k vašemu účtu Azure, pokud jste to ještě neudělali.
Vyberte ikonu Azure ze sloupce úplně vlevo.
V levém podokně rozbalte AZURE: HDINSIGHT. Jsou uvedena dostupná předplatná a clustery.
Rozbalením clusteru zobrazíte databázi metadat Hive a schéma tabulky.
Klikněte pravým tlačítkem myši na tabulku Hive. Příklad: hivesampletable. Vyberte Náhled.
Otevře se okno Náhled výsledků :
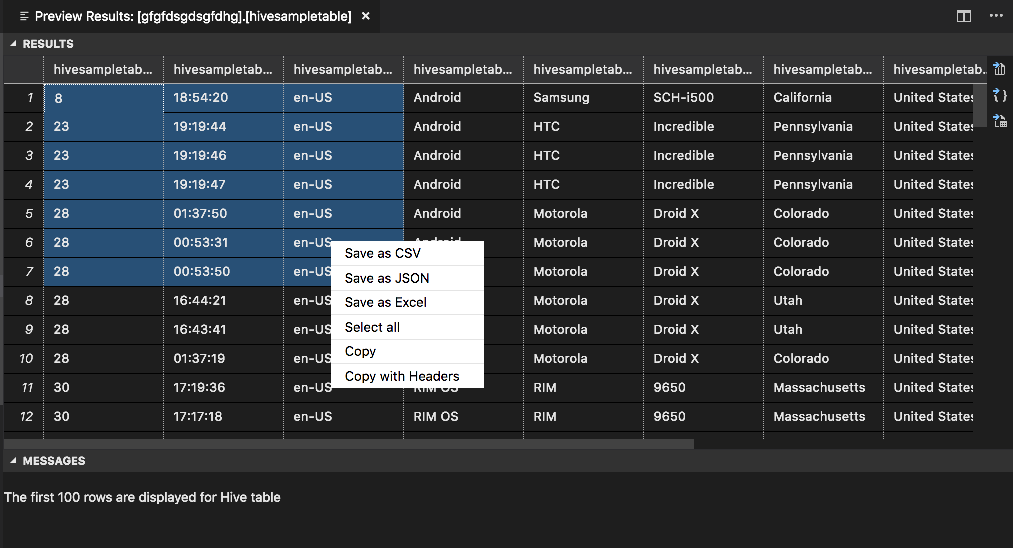
PANEL VÝSLEDKY
Celý výsledek můžete uložit jako soubor CSV, JSON nebo Excel do místní cesty nebo vybrat několik řádků.
Panel ZPRÁVY
Pokud je počet řádků v tabulce větší než 100, zobrazí se následující zpráva: Prvních 100 řádků se zobrazí pro tabulku Hive.
Pokud je počet řádků v tabulce menší nebo roven 100, zobrazí se následující zpráva: "Pro tabulku Hive se zobrazí 60 řádků".
Pokud v tabulce není žádný obsah, zobrazí se následující zpráva: "
0 rows are displayed for Hive table."Poznámka:
V Linuxu nainstalujte xclip, abyste povolili data copy-table.

Další funkce
Spark &Hive pro Visual Studio Code také podporuje následující funkce:
Automatické dokončování IntelliSense Návrhy se zobrazí pro klíčová slova, metody, proměnné a další programovací prvky. Různé ikony představují různé typy objektů:
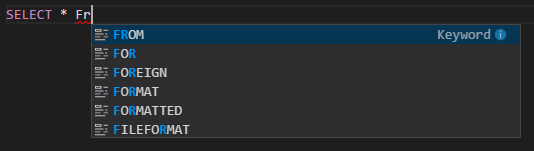
Značka chyby IntelliSense Služba jazyka podtrhuje chyby úprav ve skriptu Hive.
Zvýrazní se syntaxe. Služba jazyka používá různé barvy k rozlišení proměnných, klíčových slov, datového typu, funkcí a dalších programovacích prvků:

Role jen pro čtení
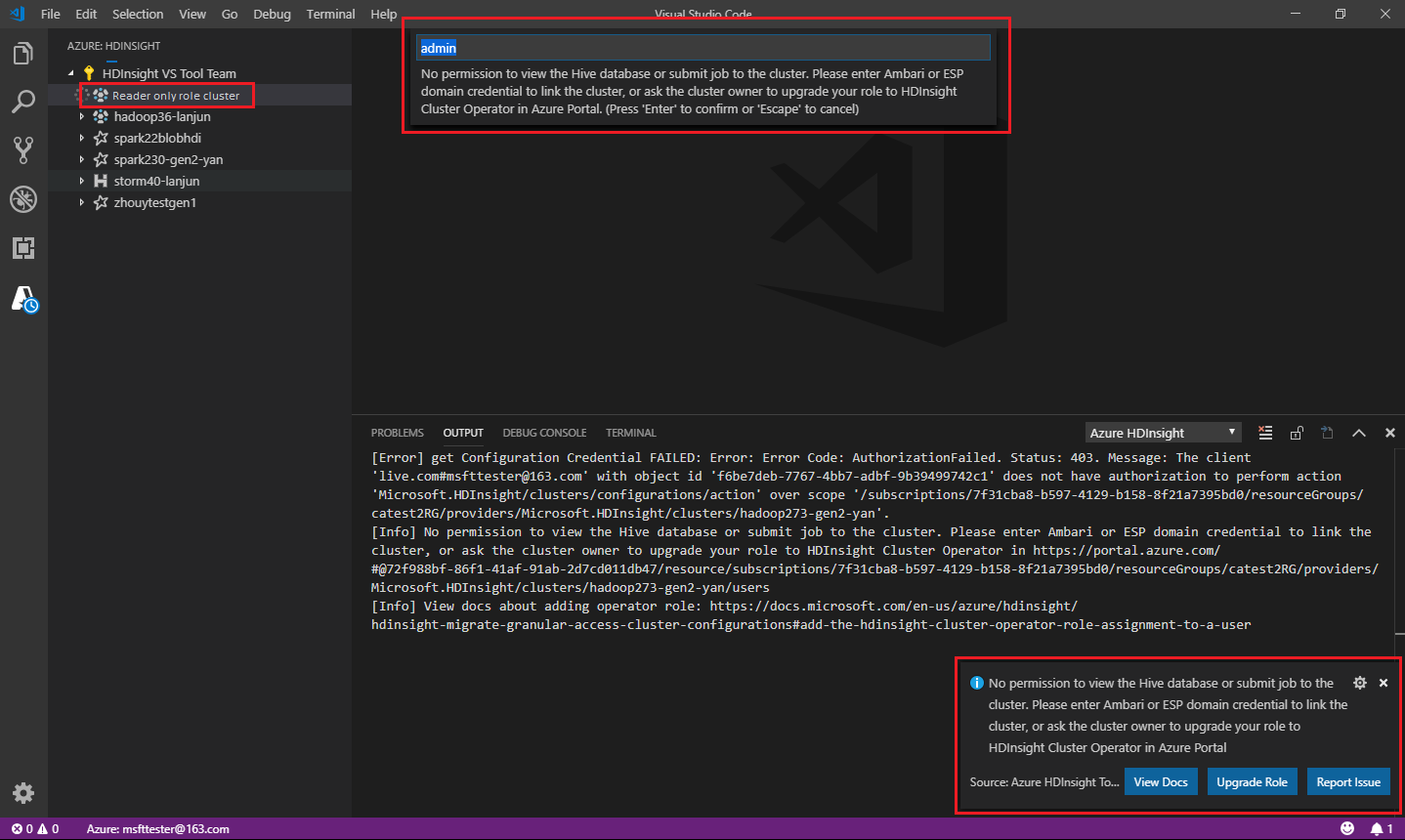
Uživatelé, kteří mají přiřazenou roli jen pro čtení clusteru, nemůžou odesílat úlohy do clusteru HDInsight ani zobrazit databázi Hive. Požádejte správce clusteru, aby vaši roli upgradoval na operátora clusteru HDInsight na webu Azure Portal. Pokud máte platné přihlašovací údaje Ambari, můžete cluster propojit ručně pomocí následujících doprovodných materiálů.
Procházení clusteru HDInsight
Když vyberete Průzkumníka Azure HDInsight a rozbalíte cluster HDInsight, zobrazí se výzva k propojení clusteru, pokud máte pro cluster roli jen pro čtení. Pomocí následující metody se připojte ke clusteru pomocí přihlašovacích údajů Ambari.
Odeslání úlohy do clusteru HDInsight
Při odesílání úlohy do clusteru HDInsight se zobrazí výzva k propojení clusteru, pokud jste v roli jen pro čtení clusteru. Pomocí následujících kroků propojte cluster pomocí přihlašovacích údajů Ambari.
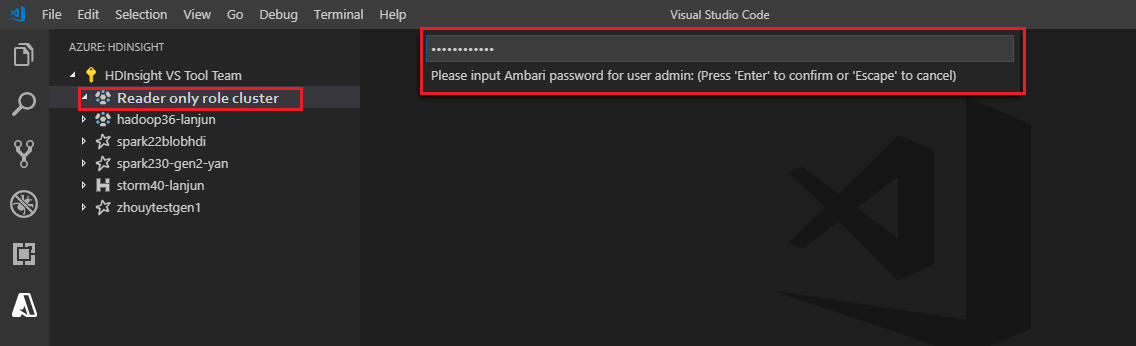
Propojení s clusterem
Zadejte platné uživatelské jméno Ambari.
Zadejte platné heslo.
Poznámka:
Můžete použít
Spark / Hive: List Clusterke kontrole propojeného clusteru:
Azure Data Lake Storage Gen2
Procházení účtu Data Lake Storage Gen2
Výběrem průzkumníka Azure HDInsight rozbalte účet Data Lake Storage Gen2. Pokud váš účet Azure nemá přístup k úložišti Gen2, zobrazí se výzva k zadání přístupového klíče úložiště. Po ověření přístupového klíče se účet Data Lake Storage Gen2 automaticky rozbalí.
Odesílání úloh do clusteru HDInsight pomocí Data Lake Storage Gen2
Odešlete úlohu do clusteru HDInsight pomocí Data Lake Storage Gen2. Pokud váš účet Azure nemá přístup k úložišti Gen2, zobrazí se výzva k zadání přístupového klíče k úložišti Úložiště Gen2. Po ověření přístupového klíče se úloha úspěšně odešle.

Poznámka:
Přístupový klíč pro účet úložiště můžete získat z webu Azure Portal. Další informace najdete v tématu Správa přístupových klíčů účtu úložiště.
Zrušení propojení clusteru
Na řádku nabídek přejděte na Paletu příkazů Zobrazení>a zadejte Spark / Hive: Odpojte cluster.
Vyberte cluster, který chcete odpojit.
Pro ověření se podívejte do zobrazení VÝSTUP .
Odhlásit se
Na řádku nabídek přejděte na Paletu příkazů Zobrazení>a zadejte Azure: Odhlásit se.
Známé problémy
Chyba instalace Synapse PySpark
U chyby instalace Synapse PySpark, protože její závislost už nebude udržována jiným týmem, už se neudržuje. Pokud se pokoušíte používat Synapse Pyspark interactive, použijte místo toho Azure Synapse Analytics . A je to dlouhodobá změna.
Další kroky
Video, které ukazuje použití Sparku a Hivu pro Visual Studio Code, najdete v tématu Spark &Hive pro Visual Studio Code.