Kurz: Vytvoření aplikace strojového učení Apache Spark ve službě Azure HDInsight
V tomto kurzu se naučíte používat Jupyter Notebook k vytvoření aplikace strojového učení Apache Spark pro Azure HDInsight.
MLlib je přizpůsobitelná knihovna strojového učení Sparku, která se skládá z běžných algoritmů učení a nástrojů. (Klasifikace, regrese, clustering, filtrování spolupráce a redukce dimenzí. Také základní primitivy optimalizace.)
V tomto kurzu se naučíte:
- Vývoj aplikace strojového učení Apache Sparku
Požadavky
Cluster Apache Spark ve službě HDInsight. Viz Vytvoření clusteru Apache Spark.
Znalost používání poznámkových bloků Jupyter se Sparkem ve službě HDInsight. Další informace najdete v tématu Načtení dat a spouštění dotazů pomocí Apache Sparku ve službě HDInsight.
Vysvětlení datové sady
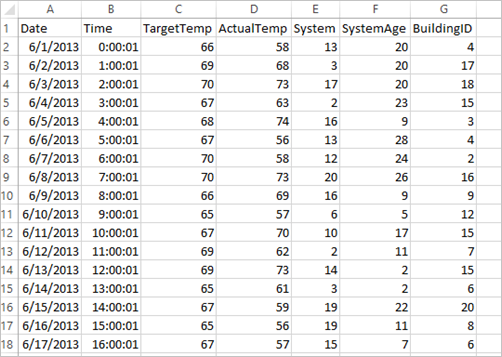
Aplikace používá ukázková HVAC.csv data, která jsou ve výchozím nastavení dostupná ve všech clusterech. Soubor se nachází na \HdiSamples\HdiSamples\SensorSampleData\hvacadrese . Data ukazují cílovou teplotu a skutečnou teplotu několika budov s nainstalovanými systémy HVAC. Sloupec System představuje ID systému a sloupec SystemAge představuje počet let, kolik je systém HVAC v budově umístěný. Na základě cílové teploty, podle ID systému a stáří systému můžete předpovědět, jestli bude budova horká nebo chladnější.
Vývoj aplikace strojového učení Sparku pomocí knihovny Spark MLlib
Tato aplikace používá ke klasifikaci dokumentů kanál Spark ML. Kanály ML poskytují jednotnou sadu rozhraní API vysoké úrovně postavená na datových rámcích. Datové rámce pomáhají uživatelům vytvářet a ladit praktické kanály strojového učení. V kanálu rozdělíte dokument na slova, převedete slova na vektory číselné funkce a nakonec pomocí vektorů číselné funkce a popisků sestavíte prediktivní model. Pomocí následujícího postupu vytvořte aplikaci.
Vytvořte poznámkový blok Jupyter pomocí jádra PySpark. Pokyny najdete v tématu Vytvoření souboru Jupyter Notebook.
Naimportujte typy potřebné pro tento scénář. Do prázdné buňky vložte následující fragment kódu a pak stiskněte SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayNačtěte data (ze souboru hvac.csv), proveďte jejich parsování a použijte je k natrénování modelu.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Ve fragmentu kódu definujete funkci, která porovnává skutečnou teplotu s cílovou teplotou. Pokud je skutečná teplota vyšší, budova je teplá a označí se hodnotou 1.0. V opačném případě je budova studená a označí se hodnotou 0.0.
Nakonfigurujte kanál strojového učení Sparku, který se skládá ze tří fází:
tokenizer,hashingTFalr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Další informace o kanálu a jeho fungování najdete v tématu Kanál strojového učení Apache Sparku.
Přizpůsobte kanál pro trénovací dokument.
model = pipeline.fit(training)Ověřte trénovací dokument a zkontrolujte pokrok s aplikací.
training.show()Výstup je podobný tomuto:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Porovnejte výstup s nezpracovaným souborem CSV. Například první řádek souboru CSV obsahuje tato data:

Všimněte si, že skutečná teplota je nižší než cílová teplota. To značí, že je budova studená. Hodnota popisku v prvním řádku je 0,0, což znamená, že budova není horká.
Připravte datovou sadu, pro kterou chcete natrénovaný model spustit. Uděláte to tak, že předáte ID systému a věk systému (označuje se jako SystemInfo ve výstupu trénování). Model předpovídá, jestli bude budova s tímto ID systému a věkem systému horká (označená 1,0) nebo chladičem (označená 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Nakonec na základě testovacích dat vytvořte předpovědi.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Výstup je podobný tomuto:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Sledujte první řádek předpovědi. V případě systému TVK s ID 20 a věkem systému 25 let je budova horká (předpověď=1,0). První hodnota DenseVector (0.49999) odpovídá předpovědi 0.0 a druhá hodnota (0.5001) odpovídá předpovědi 1.0. Přestože je druhá hodnota pouze nepatrně vyšší, model ve výstupu zobrazí prediction=1.0.
Vypněte poznámkový blok a uvolněte tak prostředky. Provedete to tak, že v nabídce Soubor poznámkového bloku vyberete Zavřít a zastavit. Tato akce poznámkový blok vypne a zavře.
Použití knihovny Anaconda scikit-learn pro strojové učení Sparku
Clustery Apache Spark ve službě HDInsight obsahují knihovny Anaconda. Jejich součástí je také knihovna scikit-learn pro strojové učení. Knihovna obsahuje také různé datové sady, které můžete použít k vytváření ukázkových aplikací přímo z aplikace Jupyter Notebook. Příklady použití knihovny scikit-learn najdete tady: https://scikit-learn.org/stable/auto_examples/index.html.
Vyčištění prostředků
Pokud nebudete tuto aplikaci dál používat, odstraňte cluster, který jste vytvořili, pomocí následujícího postupu:
Přihlaste se k portálu Azure.
Do vyhledávacího pole v horní části zadejte HDInsight.
V části Služby vyberte clustery HDInsight.
V seznamu clusterů HDInsight, které se zobrazí, vyberte ... vedle clusteru, který jste vytvořili pro účely tohoto kurzu.
Vyberte Odstranit. Vyberte Ano.
Další kroky
V tomto kurzu jste se dozvěděli, jak pomocí Jupyter Notebook vytvořit aplikaci strojového učení Apache Spark pro Azure HDInsight. V dalším kurzu se dozvíte, jak používat IntelliJ IDEA pro úlohy Sparku.