Použití knihovny Apache Spark MLlib k vytvoření aplikace strojového učení a analýze datové sady
Naučte se používat Apache Spark MLlib k vytvoření aplikace strojového učení. Aplikace provede prediktivní analýzu otevřené datové sady. Z integrovaných knihoven strojového učení Sparku tento příklad používá klasifikaci prostřednictvím logistické regrese.
Knihovna MLlib je základní knihovna Spark, která poskytuje mnoho nástrojů užitečných pro úlohy strojového učení, například:
- Klasifikace
- Regrese
- Clustering
- Modelování
- Rozklad hodnoty s jednotným číslem (SVD) a analýza hlavních komponent (PCA)
- Testování hypotéz a výpočet vzorové statistiky
Vysvětlení klasifikace a logistické regrese
Klasifikace, oblíbená úloha strojového učení, je proces řazení vstupních dat do kategorií. Je úlohou klasifikačního algoritmu zjistit, jak přiřadit "popisky" vstupním datům, která zadáte. Můžete si například představit algoritmus strojového učení, který přijímá informace o akciích jako vstup. Pak akcie rozdělí do dvou kategorií: akcie, které byste měli prodávat, a akcie, které byste měli zachovat.
Logistická regrese je algoritmus, který používáte pro klasifikaci. Rozhraní API logistické regrese Sparku je užitečné pro binární klasifikaci nebo klasifikaci vstupních dat do jedné ze dvou skupin. Další informace o logistické regresi najdete na Wikipedii.
V souhrnu proces logistické regrese vytváří logistickou funkci. Pomocí funkce můžete předpovědět pravděpodobnost, že vstupní vektor patří do jedné skupiny nebo druhé.
Příklad prediktivní analýzy údajů o kontrole potravin
V tomto příkladu pomocí Sparku provedete prediktivní analýzu údajů o kontrole potravin (Food_Inspections1.csv). Data získaná prostřednictvím datového portálu City of Chicago. Tato datová sada obsahuje informace o kontrolách potravin, které byly provedeny v Chicagu. Včetně informací o každém zařízení, nalezených porušení (pokud existuje) a výsledků kontroly. Datový soubor CSV je již k dispozici v účtu úložiště přidruženém ke clusteru ve složce /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
V následujících krocích vytvoříte model, abyste zjistili, co je potřeba k předání nebo selhání kontroly potravin.
Vytvoření aplikace strojového učení Apache Spark MLlib
Vytvořte poznámkový blok Jupyter pomocí jádra PySpark. Pokyny najdete v tématu Vytvoření souboru Jupyter Notebook.
Importujte typy požadované pro tuto aplikaci. Zkopírujte a vložte následující kód do prázdné buňky a stiskněte kombinaci kláves SHIFT+ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Kvůli jádru PySpark nemusíte explicitně vytvářet žádné kontexty. Kontexty Spark a Hive se automaticky vytvoří při spuštění první buňky kódu.
Vytvoření vstupního datového rámce
Pomocí kontextu Sparku můžete načíst nezpracovaná data CSV do paměti jako nestrukturovaný text. Pak pomocí knihovny CSV Pythonu parsujte každý řádek dat.
Spuštěním následujících řádků vytvořte odolnou distribuovanou datovou sadu (RDD) importem a parsováním vstupních dat.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Spuštěním následujícího kódu načtěte jeden řádek ze sady RDD, abyste se mohli podívat na schéma dat:
inspections.take(1)Výstup je:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Výstup vám poskytne představu o schématu vstupního souboru. Zahrnuje název každé provozovny a typ zařízení. Adresa, údaje o kontrolách a umístění mimo jiné.
Spuštěním následujícího kódu vytvořte datový rámec (df) a dočasnou tabulku (CountResults) s několika sloupci, které jsou užitečné pro prediktivní analýzu.
sqlContextslouží k transformaci strukturovaných dat.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Čtyři sloupce, které mají zájem o datový rámec, jsou ID, název, výsledky a porušení.
Spuštěním následujícího kódu získejte malou ukázku dat:
df.show(5)Výstup je:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Vysvětlení dat
Začněme získat představu o tom, co datová sada obsahuje.
Spuštěním následujícího kódu zobrazte jedinečné hodnoty ve sloupci výsledků :
df.select('results').distinct().show()Výstup je:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Spuštěním následujícího kódu vizualizujete distribuci těchto výsledků:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsMagie
%%sqlnásledovaná-o countResultsdfzajišťuje, že se výstup dotazu zachová místně na serveru Jupyter (obvykle hlavní uzel clusteru). Výstup je trvalý jako datový rámec Pandas se zadaným názvem countResultsdf. Další informace o%%sqlmagii a dalších magických funkcích dostupných s jádrem PySpark naleznete v tématu Jádra dostupná v poznámkových blocích Jupyter s clustery Apache Spark HDInsight.Výstup je:
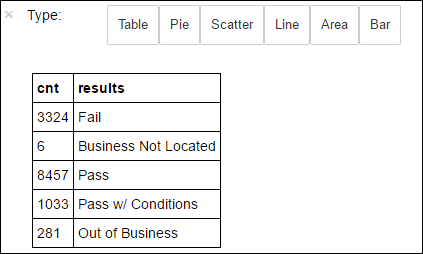
K vytvoření grafu můžete použít také knihovnu Matplotlib, která se používá k vytvoření vizualizace dat. Vzhledem k tomu, že vykreslení musí být vytvořeno z místně trvalého datového rámce countResultsdf , musí fragment kódu začínat magií
%%local. Tato akce zajistí, že se kód spustí místně na serveru Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Pokud chcete předpovědět výsledek kontroly potravin, musíte na základě porušení vyvinout model. Vzhledem k tomu, že logistická regrese je metoda binární klasifikace, dává smysl seskupit výsledná data do dvou kategorií: Fail a Pass:
Úspěšné absolvování
- Úspěšné absolvování
- Pass w/ conditions
Neúspěch
- Neúspěch
Zahodit
- Firma se nenachází
- Mimo firmu
Data s jinými výsledky ("Business Not Located" nebo "Out of Business") nejsou užitečná a přesto tvoří malé procento výsledků.
Spuštěním následujícího kódu převeďte existující datový rámec(
df) na nový datový rámec, ve kterém je každá kontrola reprezentována jako dvojice porušení popisků. V tomto případě popisek0.0představuje selhání, popisek1.0představuje úspěch a popisek-1.0představuje některé výsledky kromě těchto dvou výsledků.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Spuštěním následujícího kódu zobrazte jeden řádek označených dat:
labeledData.take(1)Výstup je:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Vytvoření modelu logistické regrese ze vstupního datového rámce
Posledním úkolem je převést označená data. Převeďte data do formátu analyzovaného logistickou regresí. Vstup do logistického regresního algoritmu potřebuje sadu dvojic vektorů funkce popisku. Kde "vektor funkce" je vektor čísel, který představuje vstupní bod. Proto je potřeba převést sloupec "porušení", který je částečně strukturovaný a obsahuje mnoho komentářů ve volném textu. Převeďte sloupec na pole skutečných čísel, kterým počítač snadno rozumí.
Jedním ze standardních přístupů strojového učení pro zpracování přirozeného jazyka je přiřazení jednotlivých slov indexu. Pak předejte vektor algoritmu strojového učení. Hodnota každého indexu obsahuje relativní frekvenci tohoto slova v textovém řetězci.
MLlib poskytuje snadný způsob, jak tuto operaci provést. Nejprve "tokenizujte" každý řetězec porušení, abyste získali jednotlivá slova v každém řetězci. Potom pomocí funkce HashingTF převeďte každou sadu tokenů na vektor funkce, který pak lze předat algoritmu logistické regrese k vytvoření modelu. Všechny tyto kroky provedete postupně pomocí kanálu.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Vyhodnocení modelu pomocí jiné datové sady
Model, který jste vytvořili dříve, můžete použít k predikci výsledků nových kontrol. Předpovědi jsou založeny na pozorovaných porušeních. Tento model jste vytrénovali na Food_Inspections1.csv datové sady. K vyhodnocení síly tohoto modelu u nových dat můžete použít druhou datovou sadu Food_Inspections2.csv. Tato druhá datová sada (Food_Inspections2.csv) je ve výchozím kontejneru úložiště přidruženém ke clusteru.
Spuštěním následujícího kódu vytvořte nový datový rámec, predictionsDf obsahující predikci vygenerovanou modelem. Fragment kódu také vytvoří dočasnou tabulku s názvem Predictions (Předpovědi) na základě datového rámce.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsMěl by se zobrazit výstup podobný následujícímu textu:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Podívejte se na jednu z předpovědí. Spusťte tento fragment kódu:
predictionsDf.take(1)V testovací sadě dat je předpověď pro první položku.
Metoda
model.transform()použije stejnou transformaci na všechna nová data se stejným schématem a dorazí na předpověď, jak klasifikovat data. Pomocí statistik můžete získat představu o tom, jak byly předpovědi:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Výstup vypadá jako následující text:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success ratePoužití logistické regrese se Sparkem poskytuje model vztahu mezi popisy porušení v angličtině. A jestli daná firma projde nebo selžou kontrolu potravin.
Vytvoření vizuální reprezentace předpovědi
Teď můžete vytvořit konečnou vizualizaci, která vám pomůže zdůvodnění výsledků tohoto testu.
Začnete extrahováním různých předpovědí a výsledků z dočasné tabulky Predictions vytvořené dříve. Následující dotazy rozdělí výstup jako true_positive, false_positive, true_negative a false_negative. V následujících dotazech vypnete vizualizaci pomocí
-qa uložíte výstup (pomocí )-ojako datové rámce, které se pak dají použít s%%localmagií.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Nakonec pomocí následujícího fragmentu kódu vygenerujte graf pomocí knihovny Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Měl by se zobrazit následující výstup:
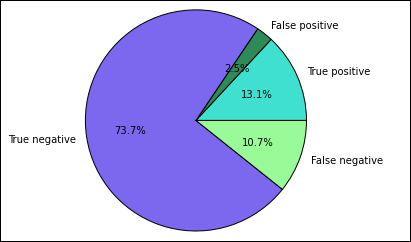
V tomto grafu "pozitivní" výsledek odkazuje na neúspěšnou kontrolu potravin, zatímco negativní výsledek odkazuje na úspěšnou kontrolu.
Vypnutí poznámkového bloku
Po spuštění aplikace byste měli poznámkový blok vypnout a uvolnit prostředky. Provedete to tak, že v nabídce Soubor poznámkového bloku vyberete Zavřít a zastavit. Tato akce poznámkový blok vypne a zavře.