Použití Apache Pigu s Apache Hadoopem ve službě HDInsight
Naučte se používat Apache Pig se službou HDInsight.
Apache Pig je platforma pro vytváření programů pro Apache Hadoop pomocí procedurálního jazyka známého jako Pig Latin. Pig je alternativou k Javě pro vytváření řešení MapReduce a je součástí Azure HDInsight. Pomocí následující tabulky můžete zjistit různé způsoby použití Pigu se službou HDInsight:
Proč používat Apache Pig
Jedním z problémů při zpracování dat pomocí MapReduce v Hadoopu je implementace logiky zpracování pomocí pouze mapové a redukční funkce. U komplexního zpracování je často nutné rozdělit zpracování na několik operací MapReduce, které jsou zřetězeny dohromady, abyste dosáhli požadovaného výsledku.
Pig umožňuje definovat zpracování jako řadu transformací, kterými data procházejí, aby vznikl požadovaný výstup.
Jazyk Pig Latin umožňuje popsat tok dat z nezpracovaného vstupu prostřednictvím jedné nebo více transformací, aby se vytvořil požadovaný výstup. Programy Pig Latin se řídí tímto obecným vzorem:
Načtení: Čtení dat, která se mají manipulovat ze systému souborů.
Transformace: Manipulace s daty
Výpis nebo uložení: Výstupní data na obrazovku nebo je uložte ke zpracování.
Uživatelem definované funkce
Pig Latin také podporuje uživatelem definované funkce (UDF), které umožňují vyvolat externí komponenty, které implementují logiku, která je obtížné modelovat v Pig Latin.
Další informace o Pig Latin, viz Pig Latin Reference Manual 1 a Pig Latin Reference Manual 2.
Příklad dat
HDInsight poskytuje různé ukázkové datové sady, které jsou uložené v /example/data adresářích a /HdiSamples adresářích. Tyto adresáře jsou ve výchozím úložišti vašeho clusteru. Příklad Pig v tomto dokumentu používá soubor log4j z /example/data/sample.log.
Každý protokol v souboru se skládá z řádku polí, která obsahují [LOG LEVEL] pole, které zobrazuje typ a závažnost, například:
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
V předchozím příkladu je úroveň protokolu CHYBA.
Poznámka:
Soubor log4j můžete také vygenerovat pomocí nástroje pro protokolování Apache Log4j a pak tento soubor nahrát do objektu blob. Pokyny najdete v tématu Nahrání dat do SLUŽBY HDInsight . Další informace o tom, jak se objekty blob v úložišti Azure používají se službou HDInsight, najdete v tématu Použití služby Azure Blob Storage se službou HDInsight.
Ukázková úloha
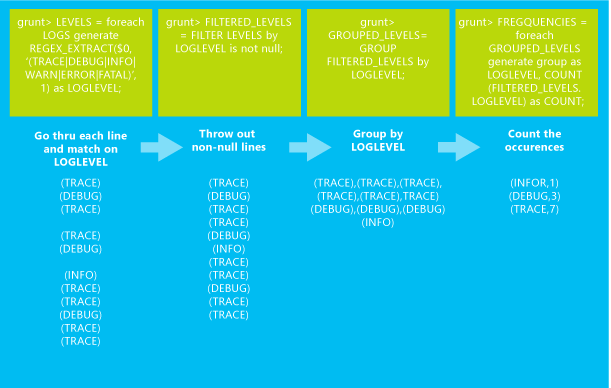
Následující úloha Pig Latin načte sample.log soubor z výchozího úložiště pro váš cluster HDInsight. Pak provede řadu transformací, které mají za následek počet výskytů jednotlivých úrovní protokolu ve vstupních datech. Výsledky se zapisují do stDOUT.
LOGS = LOAD 'wasb:///example/data/sample.log';
LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;
Následující obrázek znázorňuje souhrn toho, co každá transformace dělá s daty.
Spuštění úlohy Pig Latin
HDInsight může spouštět úlohy Pig Latin pomocí různých metod. V následující tabulce se můžete rozhodnout, která metoda je pro vás nejvhodnější, a pak postupujte podle odkazu pro názorný postup.
Pig a SQL Server Integration Services
Ke spuštění úlohy Pig můžete použít službu SQL Server Integration Services (SSIS). Sada Funkcí Azure pro SSIS poskytuje následující komponenty, které pracují s úlohami Pig ve službě HDInsight.
Další informace o sadě Azure Feature Pack pro SSIS najdete tady.
Další kroky
Teď, když jste se naučili používat Pig se službou HDInsight, můžete pomocí následujících odkazů prozkoumat další způsoby práce se službou Azure HDInsight.