Import trénovacích dat do nástroje Machine Learning Studio (classic) z různých zdrojů dat
PLATÍ PRO: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Přečtěte si informace o přesunu projektů strojového učení ze sady ML Studio (Classic) do Služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
Pokud chcete použít vlastní data v nástroji Machine Learning Studio (classic) k vývoji a trénování řešení prediktivní analýzy, můžete použít data z:
- Místní soubor – Načtení místních dat předem z pevného disku a vytvoření modulu datové sady v pracovním prostoru
- Online zdroje dat – Použití modulu Import dat k přístupu k datům z jednoho z několika online zdrojů při spuštění experimentu
- Experiment Machine Learning Studio (classic) – Použití dat uložených jako datová sada v nástroji Machine Learning Studio (classic)
- SQL Server databáze – Použití dat z databáze SQL Server bez nutnosti ručního kopírování dat
Poznámka
V nástroji Machine Learning Studio (classic) je k dispozici několik ukázkových datových sad, které můžete použít pro trénovací data. Informace o těchto datových sadách najdete v tématu Použití ukázkových datových sad v nástroji Machine Learning Studio (classic).
Příprava dat
Machine Learning Studio (classic) je navržený tak, aby fungoval s obdélníkovými nebo tabulkovými daty, jako jsou textová data, která jsou oddělená nebo strukturovaná z databáze, i když za určitých okolností se dají použít jiná než obdélníková data.
Nejlepší je, když jsou vaše data relativně čistá, než je naimportujete do studia (classic). Budete se například chtít postarat o problémy, jako jsou nekótované řetězce.
V sadě Studio (classic) jsou ale k dispozici moduly, které umožňují manipulaci s daty v rámci experimentu po importu dat. V závislosti na algoritmech strojového učení, které budete používat, možná budete muset rozhodnout, jak budete zpracovávat strukturální problémy s daty, jako jsou chybějící hodnoty a řídká data, a existují moduly, které s tím můžou pomoct. Podívejte se do části Transformace dat palety modulů pro moduly, které tyto funkce provádějí.
V libovolném okamžiku experimentu můžete zobrazit nebo stáhnout data vytvořená modulem kliknutím na výstupní port. V závislosti na modulu můžou být k dispozici různé možnosti stahování nebo můžete data vizualizovat ve webovém prohlížeči v sadě Studio (classic).
Podporované formáty dat a datové typy
Do experimentu můžete importovat několik datových typů v závislosti na tom, jaký mechanismus používáte k importu dat a odkud pocházejí:
- Prostý text (.txt)
- Hodnoty oddělené čárkami (CSV) se záhlavím (.csv) nebo bez (.nh.csv)
- Hodnoty oddělené tabulátorem (TSV) se záhlavím (.tsv) nebo bez (.nh.tsv)
- Excelové soubory
- Tabulka Azure
- Tabulka Hive
- Tabulka databáze SQL
- Hodnoty OData
- DATA SVMLight (.svmlight) (viz definice SVMLight pro informace o formátu)
- Data formátu souboru relací atributů (ARFF) (.arff) (viz definice ARFF pro informace o formátu)
- Soubor ZIP (.zip)
- Objekt R nebo soubor pracovního prostoru (. RData)
Pokud importujete data ve formátu, jako je ARFF obsahující metadata, použije Studio (classic) tato metadata k definování nadpisu a datového typu každého sloupce.
Pokud importujete data, například formát TSV nebo CSV, který neobsahuje tato metadata, Studio (classic) odvozuje datový typ pro každý sloupec vzorkováním dat. Pokud data také nemají záhlaví sloupců, studio (classic) poskytuje výchozí názvy.
Pomocí modulu Upravit metadata můžete explicitně zadat nebo změnit nadpisy a datové typy sloupců.
Studio (classic) rozpoznává následující datové typy:
- Řetězec
- Integer
- dvojité
- Logická hodnota
- Datum a čas
- TimeSpan
Studio používá k předávání dat mezi moduly interní datový typ označovaný jako datová tabulka . Data můžete explicitně převést do formátu tabulky dat pomocí modulu Převést na datovou sadu .
Jakýkoli modul, který přijímá jiné formáty než tabulka dat, převede data na tabulku dat bezobslužně před předáním do dalšího modulu.
V případě potřeby můžete formát tabulky dat převést zpět na formát CSV, TSV, ARFF nebo SVMLight pomocí jiných převodových modulů. Podívejte se do části Převody formátu dat palety modulů pro moduly, které tyto funkce provádějí.
Datové kapacity
Moduly v nástroji Machine Learning Studio (classic) podporují datové sady až 10 GB hustých číselných dat pro běžné případy použití. Pokud modul přijímá víc než jeden vstup, celková velikost všech vstupních velikostí je 10 GB. Větší datové sady můžete vzorkovat pomocí dotazů z Hive nebo databáze Azure SQL, nebo můžete před importem dat použít učení podle počtu.
Během normalizace funkcí je možné následující typy dat rozšířit do větších datových sad. Tyto typy jsou omezené na méně než 10 GB:
- Řídké
- Kategorické
- Řetězce
- Binární data
Následující moduly jsou omezené na datové sady menší než 10 GB:
- Doporučené moduly
- Modul SMOTE (Synthetic Minority Oversampling Technique)
- Skriptovací moduly: R, Python, SQL
- Moduly, kde velikost výstupních dat může být větší než velikost vstupních dat, třeba Join nebo Feature Hashing
- Pro velmi velký počet iterací Cross-validation, Tune Model Hyperparameters, Ordinal Regression a One-vs-All Multiclass
U datových sad, které jsou větší než několik GB, nahrajte data do služby Azure Storage nebo do databáze Azure SQL, nebo místo nahrávání přímo z místního souboru použijte Azure HDInsight.
Informace o datech obrázků najdete v referenčních informacích k modulu Import imagí .
Import z místního souboru
Datový soubor můžete nahrát z pevného disku, který se použije jako trénovací data v sadě Studio (classic). Při importu datového souboru vytvoříte modul datové sady připravený k použití v experimentech ve vašem pracovním prostoru.
Pokud chcete importovat data z místního pevného disku, postupujte takto:
- V dolní části okna Studia (classic) klikněte na +NOVÝ .
- Vyberte DATOVOU SADU a Z MÍSTNÍHO SOUBORU.
- V dialogovém okně Nahrát novou datovou sadu přejděte k souboru, který chcete nahrát.
- Zadejte název, identifikujte datový typ a volitelně zadejte popis. Doporučuje se popis – umožňuje zaznamenávat jakékoli charakteristiky dat, která si chcete zapamatovat při použití dat v budoucnu.
- Zaškrtávací políčko Toto je nová verze existující datové sady , která umožňuje aktualizovat existující datovou sadu s novými daty. Uděláte to tak, že kliknete na toto políčko a zadáte název existující datové sady.
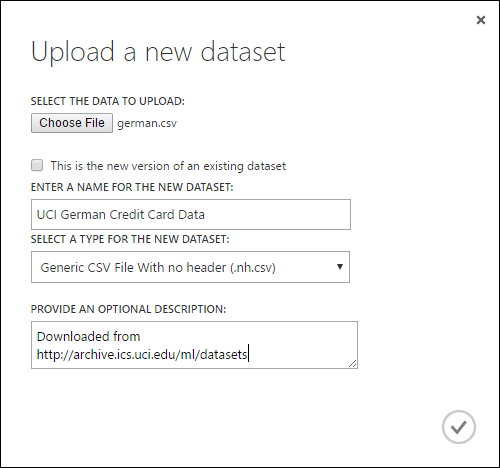
Doba nahrávání závisí na velikosti dat a rychlosti připojení ke službě. Pokud víte, že soubor bude trvat dlouho, můžete dělat další věci uvnitř studia (classic) během čekání. Zavření prohlížeče před dokončením nahrávání dat ale způsobí selhání nahrávání.
Po nahrání dat se uloží do modulu datové sady a je k dispozici pro jakýkoli experiment ve vašem pracovním prostoru.
Při úpravách experimentu najdete datové sady, které jste nahráli, v seznamu Moje datové sady v seznamu Uložené datové sady v paletě modulů. Datovou sadu můžete přetáhnout na plátno experimentu, když chcete datovou sadu použít k další analýze a strojovému učení.
Import z online zdrojů dat
Pomocí modulu Importovat data můžete experiment importovat data z různých online zdrojů dat během spuštění experimentu.
Poznámka
Tento článek obsahuje obecné informace o modulu Import dat . Podrobnější informace o typech dat, ke které máte přístup, formáty, parametry a odpovědi na běžné otázky, najdete v referenčním tématu modulu pro modul Import dat .
Pomocí modulu Importovat data můžete získat přístup k datům z jednoho z několika online zdrojů dat během spuštění experimentu:
- Webová adresa URL pomocí protokolu HTTP
- Hadoop s využitím HiveQL
- Azure Blob Storage
- Tabulka Azure
- Azure SQL Database SQL Managed Instance nebo SQL Server
- Poskytovatel datového kanálu, OData v současné době
- Azure Cosmos DB
Vzhledem k tomu, že k trénovacím datům se přistupuje během spuštění experimentu, je k dispozici pouze v tomto experimentu. V porovnání jsou data uložená v modulu datové sady dostupná pro jakýkoli experiment ve vašem pracovním prostoru.
Pokud chcete získat přístup k online zdrojům dat v experimentu Studio (classic), přidejte do experimentu modul Importovat data . Potom v části Vlastnosti vyberte Průvodce importem dat, kde najdete podrobné pokyny k výběru a konfiguraci zdroje dat. Alternativně můžete ručně vybrat zdroj dat v části Vlastnosti a zadat parametry potřebné pro přístup k datům.
Online zdroje dat, které jsou podporovány, jsou uvedeny v následující tabulce. Tato tabulka také shrnuje formáty souborů, které jsou podporované a parametry používané pro přístup k datům.
Důležité
Moduly Import dat a export dat v současné době můžou číst a zapisovat data jenom z úložiště Azure vytvořeného pomocí modelu nasazení Classic. Jinými slovy, nový typ účtu Azure Blob Storage, který nabízí horkou úroveň přístupu k úložišti nebo studenou úroveň přístupu k úložišti, ještě není podporován.
Obecně platí, že na všechny účty úložiště Azure, které jste mohli vytvořit dříve, než bude tato možnost služby dostupná, by to nemělo mít vliv. Pokud potřebujete vytvořit nový účet, vyberte Classic pro model nasazení nebo použijte Resource Manager a místo úložiště objektů blob pro typ účtu vyberte Obecné účely.
Další informace najdete v tématu Azure Blob Storage: Horká a studená úroveň úložiště.
Podporované online zdroje dat
Modul Pro import dat nástroje Machine Learning Studio (Classic) podporuje následující zdroje dat:
| Zdroj dat | Description | Parametry |
|---|---|---|
| Webová adresa URL přes HTTP | Čte data ve formátech hodnot oddělených čárkami (CSV), hodnot oddělených tabulátorem (TSV), formátu souboru relačního atributu (ARFF) a formátech SVM (Support Vector Machines) z libovolné webové adresy URL, která používá PROTOKOL HTTP. | Adresa URL: Určuje úplný název souboru, včetně adresy URL webu a názvu souboru s libovolnou příponou. Formát dat: Určuje jeden z podporovaných formátů dat: CSV, TSV, ARFF nebo SVM-light. Pokud data obsahují řádek záhlaví, slouží k přiřazení názvů sloupců. |
| Hadoop/HDFS | Čte data z distribuovaného úložiště v Hadoopu. Data, která chcete zadat, zadáte pomocí HiveQL, dotazovacího jazyka podobného SQL. HiveQL se dá použít také k agregaci dat a k filtrování dat před přidáním dat do studia (classic). | Dotaz databáze Hive: Určuje dotaz Hive použitý k vygenerování dat. Identifikátor URI serveru HCatalog : Zadejte název clusteru pomocí formátu <název> clusteru.azurehdinsight.net. Uživatelské jméno účtu Hadoop: Určuje název uživatelského účtu Hadoop použitý ke zřízení clusteru. Heslo uživatelského účtu Hadoop : Určuje přihlašovací údaje použité při zřizování clusteru. Další informace najdete v tématu Vytváření clusterů Hadoop ve službě HDInsight. Umístění výstupních dat: Určuje, jestli jsou data uložená v distribuovaném systému souborů Hadoop (HDFS) nebo v Azure.
Pokud ukládáte výstupní data v Azure, musíte zadat název účtu úložiště Azure, přístupový klíč úložiště a název kontejneru úložiště. |
| Databáze SQL | Načte data uložená v databázi Azure SQL, SQL Managed Instance nebo v databázi SQL Server spuštěné na virtuálním počítači Azure. | Název databázového serveru: Určuje název serveru, na kterém je databáze spuštěná.
V případě SQL serveru hostovaného na virtuálním počítači Azure zadejte tcp:<Název> DNS virtuálního počítače 1433 Název databáze : Určuje název databáze na serveru. Název uživatelského účtu serveru: Určuje uživatelské jméno účtu, který má oprávnění k přístupu k databázi. Heslo uživatelského účtu serveru: Určuje heslo pro uživatelský účet. Databázový dotaz:Zadejte příkaz SQL, který popisuje data, která chcete přečíst. |
| Místní databáze SQL | Načte data uložená v databázi SQL. | Brána dat: Určuje název brány Správa dat nainstalované na počítači, kde má přístup k vaší databázi SQL Server. Informace o nastavení brány najdete v tématu Provádění pokročilých analýz pomocí nástroje Machine Learning Studio (classic) s využitím dat ze serveru SQL. Název databázového serveru: Určuje název serveru, na kterém je databáze spuštěná. Název databáze : Určuje název databáze na serveru. Název uživatelského účtu serveru: Určuje uživatelské jméno účtu, který má oprávnění k přístupu k databázi. Uživatelské jméno a heslo: Kliknutím na Zadat hodnoty zadejte přihlašovací údaje k databázi. Integrované ověřování systému Windows nebo ověřování SQL Server můžete použít v závislosti na tom, jak je nakonfigurované SQL Server. Databázový dotaz:Zadejte příkaz SQL, který popisuje data, která chcete přečíst. |
| Tabulka Azure | Načte data ze služby Table Service ve službě Azure Storage. Pokud čtete velké objemy dat zřídka, použijte službu Azure Table Service. Poskytuje flexibilní, nerelační (NoSQL), široce škálovatelné, levné a vysoce dostupné řešení úložiště. |
Možnosti importu dat se mění v závislosti na tom, jestli přistupujete k veřejným informacím nebo k účtu privátního úložiště, který vyžaduje přihlašovací údaje. Určuje to typ ověřování , který může mít hodnotu PublicOrSAS nebo Account, z nichž každá má vlastní sadu parametrů. Identifikátor URI veřejného nebo sdíleného přístupového podpisu (SAS): Parametry jsou:
Určuje řádky, které se mají vyhledat názvy vlastností: Hodnoty jsou TopN pro kontrolu zadaného počtu řádků nebo ScanAll pro získání všech řádků v tabulce. Pokud jsou data homogenní a předvídatelná, doporučujeme vybrat TopN a zadat číslo pro N. U velkých tabulek to může vést k rychlejšímu čtení. Pokud jsou data strukturovaná se sadami vlastností, které se liší podle hloubky a umístění tabulky, zvolte možnost ScanAll a zkontrolujte všechny řádky. Tím zajistíte integritu výsledné vlastnosti a převodu metadat.
Klíč účtu: Určuje klíč úložiště přidružený k účtu. Název tabulky : Určuje název tabulky, která obsahuje data ke čtení. Řádky pro vyhledávání názvů vlastností: Hodnoty jsou TopN pro kontrolu zadaného počtu řádků nebo ScanAll pro získání všech řádků v tabulce. Pokud jsou data homogenní a předvídatelná, doporučujeme vybrat TopN a zadat číslo pro N. U velkých tabulek to může vést k rychlejšímu čtení. Pokud jsou data strukturovaná se sadami vlastností, které se liší podle hloubky a umístění tabulky, zvolte možnost ScanAll a zkontrolujte všechny řádky. Tím zajistíte integritu výsledné vlastnosti a převodu metadat. |
| Azure Blob Storage | Čte data uložená ve službě Blob Service ve službě Azure Storage, včetně obrázků, nestrukturovaného textu nebo binárních dat. Službu Blob můžete použít k veřejnému zveřejnění dat nebo k privátnímu ukládání dat aplikací. K datům můžete přistupovat odkudkoli pomocí připojení HTTP nebo HTTPS. |
Možnosti modulu Import dat se mění v závislosti na tom, jestli přistupujete k veřejným informacím nebo k účtu privátního úložiště, který vyžaduje přihlašovací údaje. Určuje se to typem ověřování , který může mít hodnotu PublicOrSAS nebo Account. Identifikátor URI veřejného nebo sdíleného přístupového podpisu (SAS): Parametry jsou:
Formát souboru: Určuje formát dat ve službě Blob Service. Podporované formáty jsou CSV, TSV a ARFF.
Klíč účtu: Určuje klíč úložiště přidružený k účtu. Cesta k kontejneru, adresáři nebo objektu blob : Určuje název objektu blob, který obsahuje data ke čtení. Formát souboru objektu blob: Určuje formát dat ve službě blob. Podporované formáty dat jsou CSV, TSV, ARFF, CSV se zadaným kódováním a Excelem.
Pomocí možnosti Excel můžete číst data z excelových sešitů. V možnosti formát dat aplikace Excel určete, jestli jsou data v oblasti excelového listu nebo v excelové tabulce. V excelovém listu nebo vložené tabulce zadejte název listu nebo tabulky, ze které chcete číst. |
| Zprostředkovatel datového kanálu | Čte data od podporovaného poskytovatele informačního kanálu. V současné době se podporuje pouze formát OData (Open Data Protocol). | Datový typ obsahu: Určuje formát OData. Zdrojová adresa URL: Určuje úplnou adresu URL datového kanálu. Například následující adresa URL přečte z ukázkové databáze Northwind: https://services.odata.org/northwind/northwind.svc/ |
Import z jiného experimentu
Někdy budete chtít vzít zprostředkující výsledek z jednoho experimentu a použít ho jako součást jiného experimentu. Uděláte to tak, že modul uložíte jako datovou sadu:
- Klikněte na výstup modulu, který chcete uložit jako datovou sadu.
- Klikněte na Uložit jako datovou sadu.
- Po zobrazení výzvy zadejte název a popis, který vám umožní snadno identifikovat datovou sadu.
- Klikněte na značku zaškrtnutí OK .
Po dokončení uložení bude datová sada dostupná pro použití v jakémkoli experimentu ve vašem pracovním prostoru. Najdete ho v seznamu Uložené datové sady v paletě modulů.