Automatizované strojové učení (AutoML)?
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
Automatizované strojové učení, označované také jako automatizované strojové učení nebo AutoML, je proces automatizace časově náročných iterativních úloh vývoje modelů strojového učení. Umožňuje datovým vědcům, analytikům a vývojářům vytvářet modely ML s vysokou škálovatelností, efektivitou a produktivitou při zachování kvality modelu. Automatizované strojové učení ve službě Azure Machine Učení vychází z převratu z naší divize Microsoft Research.
Tradiční vývoj modelů strojového učení je náročný na prostředky a vyžaduje významné znalosti domény a čas k vytváření a porovnávání desítek modelů. Díky automatizovanému strojovému učení urychlíte dobu potřebnou k získání modelů ML připravených pro produkční prostředí s velkou jednoduchostí a efektivitou.
Způsoby použití AutoML ve službě Azure Machine Učení
Azure Machine Učení nabízí následující dvě prostředí pro práci s automatizovaným strojovém učení. Informace o dostupnosti funkcí v jednotlivých prostředích (v1) najdete v následujících částech.
Pro zákazníky se zkušenostmi s kódem azure machine Učení Python SDK. Začínáme s kurzem: Použití automatizovaného strojového učení k predikci jízdného taxíkem (v1)
Pro zákazníky s omezeným/bezkódovým prostředím studio Azure Machine Learning na adrese https://ml.azure.com. Začněte s těmito kurzy:
Nastavení experimentu
Následující nastavení vám umožní nakonfigurovat experiment automatizovaného strojového učení.
| Sada Python SDK | Webové prostředí studia | |
|---|---|---|
| Rozdělení dat do trénovacích/ověřovacích sad | ✓ | ✓ |
| Podporuje úlohy ML: klasifikace, regrese a prognózování | ✓ | ✓ |
| Podporuje úlohy počítačového zpracování obrazu: klasifikace obrázků, rozpoznávání objektů a segmentace instancí. | ✓ | |
| Optimalizace na základě primární metriky | ✓ | ✓ |
| Podpora výpočetních Učení azure machine jako cílového výpočetního objektu | ✓ | ✓ |
| Konfigurovat horizont prognózy, cílové prodlevy a průběžné okno | ✓ | ✓ |
| Nastavit kritéria ukončení | ✓ | ✓ |
| Nastavení souběžných iterací | ✓ | ✓ |
| Přetažení sloupců | ✓ | ✓ |
| Blokové algoritmy | ✓ | ✓ |
| Křížové ověření | ✓ | ✓ |
| Podpora trénování v clusterech Azure Databricks | ✓ | |
| Zobrazení názvů navržených funkcí | ✓ | |
| Souhrn featurizace | ✓ | |
| Featurizace pro svátky | ✓ | |
| Úrovně podrobností souboru protokolu | ✓ |
Nastavení modelu
Tato nastavení se dají použít na nejlepší model v důsledku experimentu automatizovaného strojového učení.
| Sada Python SDK | Webové prostředí studia | |
|---|---|---|
| Nejlepší registrace modelu, nasazení, vysvětlení | ✓ | ✓ |
| Povolení hlasovacích souborů a modelů souborů zásobníku | ✓ | ✓ |
| Zobrazení nejlepšího modelu na základě neprimární metriky | ✓ | |
| Povolení nebo zakázání kompatibility modelů ONNX | ✓ | |
| Otestování modelu | ✓ | – (Preview) |
Nastavení řízení úloh
Tato nastavení umožňují kontrolovat a řídit úlohy experimentu a jeho podřízené úlohy.
| Sada Python SDK | Webové prostředí studia | |
|---|---|---|
| Tabulka souhrnu úloh | ✓ | ✓ |
| Zrušení úloh a podřízených úloh | ✓ | ✓ |
| Získání mantinely | ✓ | ✓ |
| Pozastavení a obnovení úloh | ✓ |
Kdy použít AutoML: klasifikace, regrese, prognózování, počítačové zpracování obrazu a NLP
Automatizované strojové učení použijte, když chcete, aby služba Azure Machine Učení trénování a ladění modelu pomocí vámi zadané cílové metriky. Automatizované strojové učení demokratizuje proces vývoje modelů strojového učení a umožňuje svým uživatelům bez ohledu na znalosti datových věd identifikovat kompletní kanál strojového učení pro všechny problémy.
Odborníci na strojové učení a vývojáři v různých odvětvích můžou automatizované strojové učení používat k:
- Implementace řešení ML bez rozsáhlé znalosti programování
- Úspora času a prostředků
- Využití osvědčených postupů pro datové vědy
- Poskytování agilního řešení problémů
Klasifikace
Klasifikace je běžnou úlohou strojového učení. Klasifikace je typem učení se supervizí, ve kterém se modely učí na trénovacích datech a získané poznatky uplatňují na nová data. Azure Machine Learning nabízí extrakci příznaků speciálně pro tyto úlohy, například nástroje pro extrakci příznaků s využitím hluboké neurální sítě pro účely klasifikace. Přečtěte si další informace o možnostech featurizace (v1).
Hlavním cílem modelů klasifikace je na základě poznatků získaných z trénovacích dat predikovat, do kterých kategorií budou spadat nová data. Mezi běžné příklady klasifikace patří odhalování podvodů, rozpoznávání rukopisu nebo rozpoznávání objektů. Přečtěte si další informace a podívejte se na příklad vytvoření klasifikačního modelu pomocí automatizovaného strojového učení (v1).
Příklady klasifikace a automatizovaného strojového učení v těchto poznámkových blocích Pythonu: Detekce podvodů, marketingová předpověď a klasifikace dat v diskusní skupině
Regrese
Podobně jako klasifikace jsou regresní úlohy také běžným úkolem učení pod dohledem.
Liší se od klasifikace, kde predikované výstupní hodnoty jsou kategorické, regresní modely predikují číselné výstupní hodnoty na základě nezávislých prediktorů. Cílem regrese je pomoct stanovit vztah mezi proměnnými těchto nezávislých ukazatelů tím, že odhaduje, jak se jednotlivé proměnné ovlivňují. Například na cenu automobilu můžou mít vliv vlastnosti, jako jsou spotřeba paliva, hodnocení bezpečnosti atd. Přečtěte si další informace a podívejte se na příklad regrese pomocí automatizovaného strojového učení (v1).
Podívejte se na příklady regrese a automatizovaného strojového učení pro předpovědi v těchto poznámkových blocích Pythonu: Predikce výkonu procesoru,
Předvídání časových řad
Vytváření prognóz je nedílnou součástí každé firmy, ať už se jedná o prognózy výnosů, inventáře, prodejů nebo poptávky zákazníků. S využitím automatizovaného strojového učení můžete kombinovat různé techniky a přístupy, abyste získali doporučené a vysoce kvalitní prognózy časových řad. Další informace najdete v tomto návodu: automatizované strojové učení pro prognózování časových řad (v1).
Automatizovaný experiment časové řady se považuje za problém s multivariátní regresí. Hodnoty minulých časových řad jsou "otočené", aby se staly dalšími dimenzemi regresoru spolu s dalšími prediktory. Tento přístup, na rozdíl od klasických metod časových řad, má výhodu přirozeného začlenění více kontextových proměnných a jejich vztahu k sobě během trénování. Automatizované strojové učení se učí jeden, ale často interně rozvětvený model pro všechny položky v datové sadě a horizontech předpovědí. K dispozici je tedy více dat pro odhad parametrů modelu a zobecnění nezobecněných řad.
Pokročilá konfigurace prognózování zahrnuje:
- Detekce svátků a extrakce příznaků
- time-series and DNN learners (Auto-ARIMA, Prorok, ForecastTCN)
- podpora mnoha modelů prostřednictvím seskupování
- Postupné křížové ověřování původu
- Konfigurovatelné prodlevy
- Agregační funkce posuvného okna
Podívejte se na příklady regrese a automatizovaného strojového učení pro předpovědi v těchto poznámkových blocích Pythonu: Prognózování prodeje, prognózování poptávky a prognózování denních aktivních uživatelů GitHubu.
Počítačové zpracování obrazu
Podpora úloh počítačového zpracování obrazu umožňuje snadno generovat modely natrénované na datech obrázků pro scénáře, jako je klasifikace obrázků a detekce objektů.
Díky této funkci můžete:
- Bezproblémová integrace s možností popisování dat Učení Azure Machine
- Použití označených dat pro generování modelů obrázků
- Optimalizujte výkon modelu zadáním algoritmu modelu a laděním hyperparametrů.
- Stáhněte nebo nasaďte výsledný model jako webovou službu ve službě Azure Machine Učení.
- Zprovoznění ve velkém měřítku s využitím možností Azure Machine Učení MLOps a KANÁLŮ ML (v1).
Vytváření modelů AutoML pro úlohy zpracování obrazu se podporuje prostřednictvím sady Azure Machine Učení Python SDK. Výsledné úlohy experimentování, modely a výstupy jsou přístupné z uživatelského rozhraní studio Azure Machine Learning.
Zjistěte, jak nastavit trénování AutoML pro modely počítačového zpracování obrazu.

Automatizované strojové učení pro obrázky podporuje následující úlohy počítačového zpracování obrazu:
| Úkol | Popis |
|---|---|
| Klasifikace obrázků s více třídami | Úlohy, ve kterých se obrázky klasifikují s použitím pouze jednoho popisku ze sady tříd – např. když se jednotlivé obrázky klasifikují jako obrázek kočky, psa nebo kachny |
| Klasifikace obrázků s více popisky | Úlohy, ve kterých můžou mít obrázky jeden nebo více popisků ze sady popisků – např. když obrázek může být označený jako obrázek kočky i psa |
| Detekce objektů | Úlohy identifikace objektů na obrázku a označení jednotlivých objektů ohraničujícím rámečkem, např. vyhledání všech psů a koček na obrázku a jejich označení ohraničujícím rámečkem |
| Segmentace instancí | Úlohy identifikace objektů na obrázku na úrovni pixelů a označení jednotlivých objektů na obrázku ohraničujícím mnohoúhelníkem |
Zpracování přirozeného jazyka: NLP
Podpora úloh zpracování přirozeného jazyka (NLP) v automatizovaném strojovém učení umožňuje snadno generovat modely natrénované na textových datech pro klasifikaci textu a pojmenované scénáře rozpoznávání entit. Vytváření automatizovaných modelů strojového učení trénovaných NLP se podporuje prostřednictvím sady Azure Machine Učení Python SDK. Výsledné úlohy experimentování, modely a výstupy jsou přístupné z uživatelského rozhraní studio Azure Machine Learning.
Funkce NLP podporuje:
- Kompletní trénování NLP hluboké neurální sítě s nejnovějšími předem natrénovanými modely BERT
- Bezproblémová integrace se službou Azure Machine Učení popisky dat
- Použití označených dat pro generování modelů NLP
- Podpora vícejazyčných jazyků s 104 jazyky
- Distribuované trénování s využitím Horovodu
Zjistěte, jak nastavit trénování AutoML pro modely NLP (v1).
Jak funguje automatizované strojové učení
Během trénování azure machine Učení vytvoří paralelně řadu kanálů, které za vás vyzkouší různé algoritmy a parametry. Služba iteruje prostřednictvím algoritmů ML spárovaných s výběry funkcí, kde každá iterace vytvoří model s trénovacím skóre. Čím vyšší je skóre, tím lépe se model považuje za "fit" vaše data. Jakmile dosáhne kritérií ukončení definovaných v experimentu, zastaví se.
Pomocí služby Azure Machine Učení můžete navrhnout a spustit experimenty automatizovaného trénování ML pomocí těchto kroků:
Identifikujte problém ML, který se má vyřešit: klasifikace, prognózování, regrese nebo počítačové zpracování obrazu.
Zvolte, jestli chcete použít sadu Python SDK nebo webové prostředí studia: Přečtěte si o paritě mezi sadou Python SDK a webovým prostředím studia.
- V případě omezeného nebo žádného prostředí kódu vyzkoušejte webové prostředí studio Azure Machine Learning na adrese
https://ml.azure.com - Pro vývojáře v Pythonu se podívejte na sadu Azure Machine Učení Python SDK (v1).
- V případě omezeného nebo žádného prostředí kódu vyzkoušejte webové prostředí studio Azure Machine Learning na adrese
Zadejte zdroj a formát trénovacích dat s popiskem: pole Numpy nebo datový rámec Pandas.
Nakonfigurujte cílový výpočetní objekt pro trénování modelů, jako je místní počítač, azure machine Učení computes, vzdálené virtuální počítače nebo Azure Databricks se sadou SDK v1.
Nakonfigurujte parametry automatizovaného strojového učení, které určují, kolik iterací v různých modelech, nastavení hyperparametrů, pokročilé předběžné zpracování/featurizace a jaké metriky se mají při určování nejlepšího modelu podívat.
Odešlete trénovací úlohu.
Kontrola výsledků
Tento proces znázorňuje následující diagram.
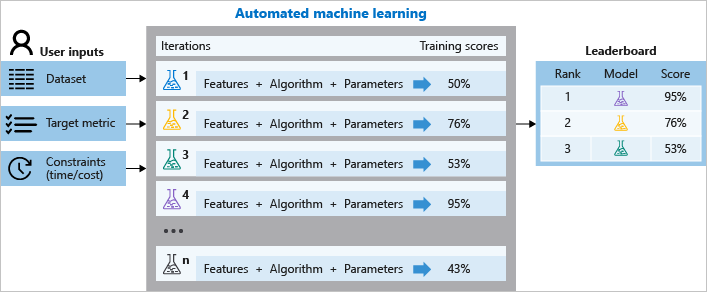
Můžete také zkontrolovat informace o protokolované úloze, které obsahují metriky shromážděné během úlohy. Trénovací úloha vytvoří serializovaný objekt Pythonu (.pkl soubor), který obsahuje předzpracování modelu a dat.
I když je sestavování modelů automatizované, můžete se také dozvědět, jak důležité nebo relevantní funkce jsou pro vygenerované modely.
Pokyny k místním a vzdáleným spravovaným cílovým výpočetním objektům ML
Webové rozhraní automatizovaného strojového učení vždy používá vzdálený cílový výpočetní objekt. Při použití sady Python SDK ale zvolíte místní výpočetní nebo vzdálený cílový výpočetní objekt pro automatizované trénování strojového učení.
- Místní výpočetní prostředky: Trénování probíhá na místním přenosném počítači nebo výpočetním prostředí virtuálního počítače.
- Vzdálené výpočty: Trénování probíhá na počítačích Učení výpočetních clusterech.
Volba cílového výpočetního objektu
Při výběru cílového výpočetního objektu zvažte tyto faktory:
- Zvolte místní výpočetní prostředky: Pokud se váš scénář týká počátečních průzkumů nebo ukázek pomocí malých dat a krátkých vlaků (tj. sekund nebo pár minut na podřízenou úlohu), může být lepší volbou trénování na místním počítači. Není čas nastavení, prostředky infrastruktury (váš počítač nebo virtuální počítač) jsou přímo dostupné.
- Zvolte výpočetní cluster vzdáleného strojového učení: Pokud trénujete s většími datovými sadami, jako je třeba v produkčním trénování, které potřebují delší trénování, vzdálený výpočetní výkon zajistí mnohem lepší výkon na konci, protože
AutoMLbude paralelizovat trénování v uzlech clusteru. Na vzdáleném výpočetním prostředí se doba spuštění interní infrastruktury přidá přibližně 1,5 minuty na podřízenou úlohu a další minuty pro infrastrukturu clusteru, pokud virtuální počítače ještě nejsou spuštěné.
Výhody a nevýhody
Při volbě použití místních a vzdálených výhod zvažte tyto výhody a nevýhody.
| Výhody (výhody) | Nevýhody (Handicapy) | |
|---|---|---|
| Místní cílový výpočetní objekt | ||
| Výpočetní clustery vzdáleného strojového učení |
Dostupnost funkcí
Při použití vzdáleného výpočetního prostředí jsou k dispozici další funkce, jak je znázorněno v následující tabulce.
| Funkce | Vzdálené | Místní |
|---|---|---|
| Streamování dat (podpora velkých dat, až 100 GB) | ✓ | |
| DNN-BERT-based text featurization and training | ✓ | |
| Předem nácvik podpory GPU (trénování a odvozování) | ✓ | |
| Podpora klasifikace obrázků a popisků | ✓ | |
| Modely Auto-ARIMA, Prorok a ForecastTCN pro prognózování | ✓ | |
| Paralelní několik úloh nebo iterací | ✓ | |
| Vytváření modelů s interpretovatelností v uživatelském rozhraní webového prostředí AutoML Studio | ✓ | |
| Přizpůsobení funkcí v uživatelském rozhraní webového prostředí studia | ✓ | |
| Ladění hyperparametrů Učení Azure Machine | ✓ | |
| Podpora pracovního postupu azure Machine Učení Pipeline | ✓ | |
| Pokračovat v úloze | ✓ | |
| Prognostika | ✓ | ✓ |
| Vytváření a spouštění experimentů v poznámkových blocích | ✓ | ✓ |
| Registrace a vizualizace informací a metrik experimentu v uživatelském rozhraní | ✓ | ✓ |
| Mantinely dat | ✓ | ✓ |
Trénování, ověřování a testování dat
Pomocí automatizovaného strojového učení poskytujete trénovací data pro trénování modelů ML a můžete určit, jaký typ ověření modelu se má provést. Automatizované strojové učení provádí ověření modelu jako součást trénování. To znamená, že automatizované strojové učení používá ověřovací data k ladění hyperparametrů modelu na základě použitého algoritmu za účelem nalezení nejlepší kombinace, která nejlépe vyhovuje trénovacím datům. Stejná ověřovací data se ale používají pro každou iteraci ladění, která zavádí předsudky vyhodnocení modelu, protože model stále vylepšuje a odpovídá ověřovacím datům.
Automatizované strojové učení podporuje použití testovacích dat k vyhodnocení konečného modelu, který automatizované strojové učení na konci experimentu doporučuje. Když jako součást konfigurace experimentu AutoML zadáte testovací data, tento doporučený model se ve výchozím nastavení testuje na konci experimentu (Preview).
Důležité
Testování modelů pomocí testovací datové sady pro vyhodnocení vygenerovaných modelů je funkce preview. Tato funkce je experimentální funkce ve verzi Preview a může se kdykoli změnit.
Zjistěte, jak nakonfigurovat experimenty AutoML tak, aby používaly testovací data (Preview) se sadou SDK (v1) nebo s studio Azure Machine Learning.
Můžete také otestovat jakýkoli existující automatizovaný model ML (Preview) (v1)), včetně modelů z podřízených úloh, poskytnutím vlastních testovacích dat nebo zrušením části trénovacích dat.
Příprava atributů
Příprava funkcí je proces použití znalostí domény k vytváření funkcí, které pomáhají algoritmům STROJOVÉho učení lépe se učit. Ve službě Azure Machine Učení se pro usnadnění přípravy funkcí použijí techniky škálování a normalizace. Souhrnně se tyto techniky a inženýrství funkcí označují jako featurizace.
U experimentů automatizovaného strojového učení se featurizace použije automaticky, ale dá se také přizpůsobit na základě vašich dat. Přečtěte si další informace o tom, co je součástí funkce (v1) a jak AutoML pomáhá zabránit nadměrnému přizpůsobení a nevyváženým datům ve vašich modelech.
Poznámka:
Kroky automatického featurizace strojového učení (normalizace funkcí, zpracování chybějících dat, převod textu na číselný atd.) se stanou součástí základního modelu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky featurizace použité během trénování.
Přizpůsobení featurizace
K dispozici jsou také další techniky přípravy funkcí, jako je kódování a transformace.
Povolte toto nastavení pomocí:
studio Azure Machine Learning: Povolení Automatická featurace v části Zobrazit další konfiguraci pomocí těchto kroků (v1).
Python SDK: Zadejte
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'v objektu AutoMLConfig . Další informace o povolení featurizace (v1)
Souborové modely
Automatizované strojové učení podporuje modely souborů, které jsou ve výchozím nastavení povolené. Souborové učení zlepšuje výsledky strojového učení a prediktivní výkon kombinováním více modelů na rozdíl od použití jednotlivých modelů. Iterace souboru se zobrazí jako konečné iterace vaší úlohy. Automatizované strojové učení používá pro kombinování modelů hlasovací i skládanou sadu metod:
- Hlasování: předpovídá na základě váženého průměru predikovaných pravděpodobností tříd (pro klasifikační úkoly) nebo predikovaných regresních cílů (pro regresní úkoly).
- Stacking: Stacking kombinuje heterogenní modely a trénuje metamodel založený na výstupu jednotlivých modelů. Aktuální výchozí metamodely jsou LogisticRegression pro úlohy klasifikace a ElasticNet pro regresní a prognózovací úlohy.
Algoritmus výběru souboru Caruana s inicializací seřazeného souboru se používá k rozhodnutí, které modely se mají použít v rámci souboru. Na vysoké úrovni tento algoritmus inicializuje soubor až s pěti modely s nejlepším individuálním skóre a ověří, že tyto modely jsou v rámci 5% prahové hodnoty nejlepšího skóre, aby se zabránilo špatnému počátečnímu souboru. Pak se pro každou iteraci souboru přidá nový model do existujícího souboru a výsledná skóre se vypočítá. Pokud nový model vylepšil stávající skóre souboru, soubor se aktualizuje tak, aby zahrnoval nový model.
Informace o změně výchozího nastavení souboru v automatizovaném strojovém učení najdete v návodu (v1 ).
AutoML &ONNX
Pomocí služby Azure Machine Učení můžete pomocí automatizovaného strojového učení sestavit model Pythonu a převést ho na formát ONNX. Jakmile jsou modely ve formátu ONNX, je možné je spustit na různých platformách a zařízeních. Přečtěte si další informace o urychlení modelů ML pomocí ONNX.
V tomto příkladu poznámkového bloku Jupyter se dozvíte, jak převést na formát ONNX. Zjistěte, které algoritmy jsou podporovány v ONNX (v1).
Modul runtime ONNX také podporuje jazyk C#, takže model vytvořený automaticky v aplikacích jazyka C# můžete používat bez nutnosti překódování nebo jakékoli latence sítě, které zavádí koncové body REST. Přečtěte si další informace o použití modelu AutoML ONNX v aplikaci .NET s ML.NET a odvozování modelů ONNX pomocí rozhraní API modulu runtime ONNX v jazyce C#.
Další kroky
K dispozici je několik prostředků, které vám pomůžou začít používat AutoML.
Kurzy / postupy
Kurzy jsou kompletní úvodní příklady scénářů AutoML.
Pro první zkušenosti s kódem postupujte podle kurzu: Trénování regresního modelu pomocí AutoML a Pythonu (v1).
Pokud máte zkušenosti s nízkými nebo bez kódu, přečtěte si kurz: Trénování klasifikačního modelu bez kódu AutoML v studio Azure Machine Learning.
Informace o použití AutoML k trénování modelů počítačového zpracování obrazu najdete v kurzu: Trénování modelu rozpoznávání objektů pomocí AutoML a Pythonu (v1).
Články s postupy poskytují další podrobnosti o funkcích, které automatizované strojové učení nabízí. Příklad:
Konfigurace nastavení pro experimenty automatického trénování
Naučte se trénovat modely prognózování s daty časových řad (v1).
Naučte se trénovat modely počítačového zpracování obrazu pomocí Pythonu (v1).
Zjistěte, jak zobrazit vygenerovaný kód z automatizovaných modelů ML.
Ukázky poznámkového bloku Jupyter
Podrobné příklady kódu a případy použití najdete v ukázkách automatizovaného strojového učení v úložišti poznámkových bloků na GitHubu.
Referenční informace o sadě Python SDK
Prohlubte své znalosti vzorů návrhu sady SDK a specifikací tříd pomocí referenční dokumentace ke třídám AutoML.
Poznámka:
Funkce automatizovaného strojového učení jsou k dispozici také v jiných řešeních Microsoftu, jako jsou ML.NET, HDInsight, Power BI a SQL Server.