Online koncové body a nasazení pro odvozování v reálném čase
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Azure Machine Učení umožňuje provádět odvozování dat v reálném čase pomocí modelů nasazených do online koncových bodů. Odvozování je proces použití nových vstupních dat na model strojového učení k vygenerování výstupů. I když se tyto výstupy obvykle označují jako "předpovědi", lze použít k vygenerování výstupů pro jiné úlohy strojového učení, jako je klasifikace a clustering.
Online koncové body
Online koncové body nasazují modely na webový server, který může vracet předpovědi v rámci protokolu HTTP. Pomocí online koncových bodů zprovozníte modely pro odvozování v reálném čase v synchronních požadavcích s nízkou latencí. Doporučujeme je používat v následujících případech:
- Máte požadavky na nízkou latenci
- Váš model může na žádost odpovědět v relativně krátkém časovém intervalu.
- Vstupy modelu se vejdou do datové části POŽADAVKU HTTP.
- Potřebujete vertikálně navýšit kapacitu z hlediska počtu požadavků.
Pokud chcete definovat koncový bod, musíte zadat:
- Název koncového bodu: Tento název musí být v oblasti Azure jedinečný. Další informace o pravidlech pojmenování najdete v tématu Omezení koncových bodů.
- Režim ověřování: Pro koncový bod si můžete vybrat z režimu ověřování založeného na klíči, azure machine Učení režimu ověřování na základě tokenu nebo ověřování založeného na tokenu Microsoft Entra (Preview). Další informace o ověřování najdete v tématu Ověřování u online koncového bodu.
Azure Machine Učení poskytuje pohodlí při používání spravovaných online koncových bodů pro nasazování modelů strojového učení na klíč. Toto je doporučený způsob použití online koncových bodů ve službě Azure Machine Učení. Spravované online koncové body pracují s výkonnými procesory a GPU v Azure škálovatelným a plně spravovaným způsobem. Tyto koncové body se také stará o obsluhu, škálování, zabezpečení a monitorování vašich modelů, aby vám uvolnily režii při nastavování a správě základní infrastruktury. Informace o definování spravovaného online koncového bodu najdete v tématu Definování koncového bodu.
Proč zvolit spravované online koncové body přes ACI nebo AKS(v1)?
Použití spravovaných online koncových bodů je doporučeným způsobem použití online koncových bodů ve službě Azure Machine Učení. Následující tabulka uvádí klíčové atributy spravovaných online koncových bodů v porovnání s řešeními Azure Machine Učení SDK/CLI v1 (ACI a AKS(v1)).
| Atributy | Spravované online koncové body (v2) | ACI nebo AKS(v1) |
|---|---|---|
| Zabezpečení nebo izolace sítě | Snadné příchozí nebo odchozí řízení pomocí rychlého přepínače | Virtuální síť není podporovaná nebo vyžaduje složitou ruční konfiguraci |
| Spravovaná služba | – Plně spravované zřizování a škálování výpočetních prostředků - Konfigurace sítě pro prevenci exfiltrace dat – Upgrade hostitelského operačního systému, řízené zavedení místních aktualizací |
– Škálování je omezené ve verzi 1. – Konfigurace nebo upgrade sítě musí být spravována uživatelem. |
| Koncept koncového bodu nebo nasazení | Rozlišení mezi koncovým bodem a nasazením umožňuje složité scénáře, jako je bezpečné zavedení modelů. | Žádný koncept koncového bodu |
| Diagnostika a monitorování | – Ladění místního koncového bodu je možné pomocí Dockeru a editoru Visual Studio Code – Pokročilá analýza metrik a protokolů s grafem nebo dotazem pro porovnání mezi nasazeními – Rozpis nákladů dolů na úroveň nasazení |
Žádné snadné místní ladění |
| Škálovatelnost | Neomezené, elastické a automatické škálování | – ACI není škálovatelná. – AKS (v1) podporuje pouze škálování v clusteru a vyžaduje konfiguraci škálovatelnosti. |
| Připravenost pro podnikové zpracování | Private Link, klíče spravované zákazníkem, ID Microsoft Entra, správa kvót, integrace fakturace, SMLOUVA SLA | Nepodporováno |
| Pokročilé funkce ML | – Shromažďování dat modelu – Monitorování modelů - Model šampion-challenger, bezpečné zavedení, zrcadlení provozu – Zodpovědná rozšiřitelnost umělé inteligence |
Nepodporováno |
Případně pokud dáváte přednost použití Kubernetes k nasazení modelů a obsluhování koncových bodů a jste obeznámeni se správou požadavků na infrastrukturu, můžete použít online koncové body Kubernetes. Tyto koncové body umožňují nasazovat modely a obsluhovat online koncové body v plně nakonfigurovaných a spravovaných clusterech Kubernetes kdekoli s procesory nebo gpu.
Proč zvolit spravované online koncové body přes AKS(v2)?
Spravované online koncové body vám můžou pomoct zjednodušit proces nasazení a poskytovat následující výhody pro online koncové body Kubernetes:
Spravovaná infrastruktura
- Automaticky zřídí výpočetní prostředky a hostuje model (stačí zadat typ virtuálního počítače a nastavení škálování).
- Automatické aktualizace a opravy základní image hostitelského operačního systému
- Automaticky provede obnovení uzlu, pokud dojde k selhání systému.
Monitorování a protokoly
- Monitorování dostupnosti, výkonu a smlouvy SLA modelu s využitím nativní integrace se službou Azure Monitor
- Ladění nasazení pomocí protokolů a nativní integrace se službou Azure Log Analytics
Zobrazení nákladů
- Spravované online koncové body umožňují monitorovat náklady na úrovni koncového bodu a nasazení.

Poznámka:
Spravované online koncové body jsou založené na výpočetních Učení azure. Při použití spravovaného online koncového bodu platíte poplatky za výpočetní prostředky a síťové poplatky. Za příplatek není žádný příplatek. Další informace o cenách najdete v cenové kalkulačce Azure.
Pokud používáte virtuální síť Azure Machine Učení k zabezpečení odchozího provozu ze spravovaného online koncového bodu, budou se vám účtovat pravidla odchozích přenosů azure a plně kvalifikovaných názvů domén, která používá spravovaná virtuální síť. Další informace najdete v tématu Ceny pro spravovanou virtuální síť.


Spravované online koncové body vs. online koncové body Kubernetes
Následující tabulka uvádí hlavní rozdíly mezi spravovanými online koncovými body a online koncovými body Kubernetes.
| Spravované online koncové body | Online koncové body Kubernetes (AKS(v2)) | |
|---|---|---|
| Doporučení uživatelé | Uživatelé, kteří chtějí spravované nasazení modelu a vylepšené prostředí MLOps | Uživatelé, kteří preferují Kubernetes a mohou si sami spravovat požadavky na infrastrukturu |
| Zřizování uzlů | Zřizování, aktualizace, odebrání spravovaného výpočetního prostředí | Odpovědnost uživatelů |
| Údržba uzlů | Aktualizace imagí spravovaného hostitelského operačního systému a posílení zabezpečení | Odpovědnost uživatelů |
| Změna velikosti clusteru (škálování) | Spravované ruční a automatické škálování, které podporuje zřizování dalších uzlů | Ruční a automatické škálování, které podporuje škálování počtu replik v rámci pevných hranic clusteru |
| Typ výpočetních prostředků | Spravováno službou | Cluster Kubernetes spravovaný zákazníkem (Kubernetes) |
| Spravovaná identita | Podporuje se | Podporováno |
| Virtuální síť (VNet). | Podporováno prostřednictvím spravovaná izolace sítě | Odpovědnost uživatelů |
| Průběžné monitorování a protokolování | Azure Monitor a Log Analytics využívají (včetně klíčových metrik a tabulek protokolů pro koncové body a nasazení) | Odpovědnost uživatelů |
| Protokolování pomocí Přehledy aplikace (starší verze) | Podporováno | Podporováno |
| Zobrazení nákladů | Podrobné informace o úrovni koncového bodu nebo nasazení | Úroveň clusteru |
| Náklady použité na | Virtuální počítače přiřazené k nasazením | Virtuální počítače přiřazené ke clusteru |
| Zrcadlený provoz | Podporuje se | Nepodporované |
| Nasazení bez kódu | Podporované (modely MLflow a Triton ) | Podporované (modely MLflow a Triton ) |
Online nasazení
Nasazení je sada prostředků a výpočetních prostředků potřebných k hostování modelu, který provádí skutečné odvozování. Jeden koncový bod může obsahovat více nasazení s různými konfiguracemi. Toto nastavení pomáhá oddělit rozhraní prezentované koncovým bodem od podrobností implementace , které jsou přítomné v nasazení. Online koncový bod má mechanismus směrování, který může směrovat požadavky na konkrétní nasazení v koncovém bodu.
Následující diagram znázorňuje online koncový bod se dvěma nasazeními, modrými a zelenými. Modré nasazení používá virtuální počítače se skladovou jednotkou procesoru a používá verzi 1 modelu. Zelené nasazení používá virtuální počítače se skladovou jednotkou GPU a používá verzi 2 modelu. Koncový bod je nakonfigurovaný tak, aby směroval 90 % příchozího provozu do modrého nasazení, zatímco zelené nasazení přijímá zbývajících 10 %.

Pokud chcete nasadit model, musíte mít:
- Soubory modelu (nebo název a verze modelu, který je už zaregistrovaný ve vašem pracovním prostoru).
- Bodovací skript, tj. kód, který spouští model na daném vstupním požadavku. Bodovací skript obdrží data odeslaná do nasazené webové služby a předá je do modelu. Skript pak spustí model a vrátí jeho odpověď klientovi. Bodovací skript je specifický pro váš model a musí rozumět datům, která model očekává jako vstup a vrací jako výstup.
- Prostředí, ve kterém model běží. Prostředí může být image Dockeru se závislostmi Conda nebo souborem Dockerfile.
- Nastavení určit typ instance a kapacitu škálování.
Klíčové atributy nasazení
Následující tabulka popisuje klíčové atributy nasazení:
| Atribut | Popis |
|---|---|
| Name | Název nasazení. |
| Název koncového bodu | Název koncového bodu pro vytvoření nasazení v části. |
| Model1 | Model, který se má použít pro nasazení. Tato hodnota může být odkazem na existující model verze v pracovním prostoru nebo specifikace vloženého modelu. Další informace o sledování a určení cesty k modelu naleznete v tématu Identifikace cesty modelu s ohledem na AZUREML_MODEL_DIR. |
| Cesta kódu | Cesta k adresáři v místním vývojovém prostředí, který obsahuje veškerý zdrojový kód Pythonu pro bodování modelu. Můžete použít vnořené adresáře a balíčky. |
| Bodovací skript | Relativní cesta k souboru bodování v adresáři zdrojového kódu. Tento kód Pythonu init() musí mít funkci a run() funkci. Funkce init() bude volána po vytvoření nebo aktualizaci modelu (můžete ji použít k uložení modelu do mezipaměti, například). Funkce run() se volá při každém vyvolání koncového bodu, aby se udělalo skutečné bodování a předpověď. |
| Prostředí1 | Prostředí pro hostování modelu a kódu. Tato hodnota může být odkazem na existující prostředí s verzí v pracovním prostoru nebo specifikaci vloženého prostředí. Poznámka: Microsoft pravidelně opravuje základní image kvůli známým ohrožením zabezpečení. Abyste mohli použít opravenou image, budete muset znovu nasadit koncový bod. Pokud zadáte vlastní image, zodpovídáte za její aktualizaci. Další informace najdete v tématu Opravy obrázků. |
| Typ instance | Velikost virtuálního počítače, která se má použít pro nasazení. Seznam podporovaných velikostí najdete v seznamu skladových položek spravovaných online koncových bodů. |
| Počet instancí | Početinstancích Založte hodnotu na očekávané úloze. Pro zajištění vysoké dostupnosti doporučujeme nastavit hodnotu alespoň 3na hodnotu . Pro provádění upgradů si vyhrazujeme dalších 20 %. Další informace najdete v tématu Přidělení kvóty virtuálních počítačů pro nasazení. |
1 Několik věcí, které je potřeba si uvědomit o modelu a prostředí:
- Na image modelu a kontejneru (jak je definováno v prostředí) můžete kdykoli znovu odkazovat nasazením, když instance za nasazením procházejí opravami zabezpečení nebo jinými operacemi obnovení. Pokud k nasazení použijete zaregistrovaný model nebo image kontejneru ve službě Azure Container Registry a odeberete model nebo image kontejneru, nasazení, která se na tyto prostředky spoléhají, může při opětovném vytvoření image selhat. Pokud model nebo image kontejneru odeberete, ujistěte se, že jsou závislá nasazení znovu vytvořena nebo aktualizována pomocí alternativního modelu nebo image kontejneru.
- Registr kontejneru, na který prostředí odkazuje, může být privátní pouze v případě, že identita koncového bodu má oprávnění k přístupu k němu prostřednictvím ověřování Microsoft Entra a Azure RBAC. Z stejného důvodu se privátní registry Dockeru jiné než Azure Container Registry nepodporují.
Informace o nasazení online koncových bodů pomocí šablony CLI, SADY SDK, studia a ARM najdete v tématu Nasazení modelu ML s online koncovým bodem.
Identifikace cesty modelu s ohledem na AZUREML_MODEL_DIR
Při nasazování modelu do služby Azure Machine Učení je potřeba zadat umístění modelu, který chcete nasadit jako součást konfigurace nasazení. V Učení Azure Machine se cesta k vašemu AZUREML_MODEL_DIR modelu sleduje pomocí proměnné prostředí. Když identifikujete cestu modelu s ohledem na AZUREML_MODEL_DIR, můžete nasadit jeden nebo více modelů, které jsou uložené místně na vašem počítači, nebo nasadit model zaregistrovaný ve vašem pracovním prostoru Azure Machine Učení.
Pro ilustraci odkazujeme na následující místní strukturu složek pro první dva případy, kdy nasadíte jeden model nebo nasadíte více modelů, které jsou uložené místně:

Použití jednoho místního modelu v nasazení
Pokud chcete použít jeden model, který máte na místním počítači v nasazení, zadejte path hodnotu model YAML v nasazení. Tady je příklad YAML nasazení s cestou /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Po vytvoření nasazení bude proměnná AZUREML_MODEL_DIR prostředí odkazovat na umístění úložiště v Rámci Azure, kde je váš model uložený. Například /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 bude obsahovat model sample_m1.pkl.
V bodovacím skriptu (score.py) můžete načíst model (v tomto příkladusample_m1.pklinit()) ve funkci:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "sample_m1.pkl")
model = joblib.load(model_path)
Použití více místních modelů v nasazení
Přestože Azure CLI, Python SDK a další klientské nástroje umožňují v definici nasazení zadat pouze jeden model na jedno nasazení, můžete v nasazení stále používat více modelů registrací složky modelu, která obsahuje všechny modely jako soubory nebo podadresáře.
V předchozí ukázkové struktuře složek si všimnete, že ve models složce je více modelů. V nasazení YAML můžete zadat cestu ke models složce následujícím způsobem:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Po vytvoření nasazení bude proměnná AZUREML_MODEL_DIR prostředí odkazovat na umístění úložiště v Azure, kde jsou vaše modely uložené. Například /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 bude obsahovat modely a strukturu souborů.
V tomto příkladu AZUREML_MODEL_DIR bude obsah složky vypadat takto:

V bodovacím skriptu (score.py) můžete načíst modely ve init() funkci. Následující kód načte sample_m1.pkl model:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "models","model_1","v1", "sample_m1.pkl ")
model = joblib.load(model_path)
Příklad nasazení více modelů do jednoho nasazení najdete v tématu Nasazení více modelů do jednoho nasazení (příklad rozhraní příkazového řádku) a nasazení více modelů do jednoho nasazení (příklad sady SDK).
Tip
Pokud máte k registraci více než 1500 souborů, zvažte komprimaci souborů nebo podadresářů jako .tar.gz při registraci modelů. Pokud chcete používat modely, můžete z bodovacího skriptu zrušit dekomprimace souborů nebo podadresářů ve init() funkci. Alternativně, když zaregistrujete modely, nastavte azureml.unpack vlastnost na True, automaticky rozbalte soubory nebo podadresáře. V obou případech se v inicializační fázi stane nekomprimace.
Použití modelů zaregistrovaných v pracovním prostoru Azure Machine Učení v nasazení
Pokud chcete použít jeden nebo více modelů, které jsou zaregistrované ve vašem pracovním prostoru Azure Machine Učení, zadejte v nasazení název registrovaných modelů v YAML nasazení. Například následující konfigurace YAML nasazení určuje registrovaný model název takto azureml:local-multimodel:3:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:local-multimodel:3
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
V tomto příkladu zvažte, že local-multimodel:3 obsahuje následující artefakty modelu, které lze zobrazit na kartě Modely v studio Azure Machine Learning:

Po vytvoření nasazení bude proměnná AZUREML_MODEL_DIR prostředí odkazovat na umístění úložiště v Azure, kde jsou vaše modely uložené. Například /var/azureml-app/azureml-models/local-multimodel/3 bude obsahovat modely a strukturu souborů. AZUREML_MODEL_DIR bude odkazovat na složku obsahující kořen artefaktů modelu.
Na základě tohoto příkladu AZUREML_MODEL_DIR bude obsah složky vypadat takto:

V bodovacím skriptu (score.py) můžete načíst modely ve init() funkci. Například načtěte diabetes.sav model:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR"), "models", "diabetes", "1", "diabetes.sav")
model = joblib.load(model_path)
Přidělení kvóty virtuálních počítačů pro nasazení
U spravovaných online koncových bodů si Azure Machine Učení 20 % výpočetních prostředků pro provádění upgradů u některých skladových položek virtuálních počítačů. Pokud v nasazení požadujete určitý počet instancí pro tyto skladové položky virtuálních počítačů, musíte mít k dispozici kvótu, ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU abyste se vyhnuli chybě. Pokud například v nasazení požadujete 10 instancí virtuálního počítače Standard_DS3_v2 (se čtyřmi jádry), měli byste mít kvótu pro 48 jader (12 instances * 4 cores) k dispozici. Tato dodatečná kvóta je vyhrazená pro operace iniciované systémem, jako jsou upgrady operačního systému a obnovení virtuálního počítače, a pokud tyto operace neběží, nebudou se vám účtovat žádné poplatky.
Existují určité skladové položky virtuálních počítačů, které jsou vyloučené z rezervace extra kvót. Úplný seznam zobrazíte v seznamu skladových položek spravovaných online koncových bodů.
Pokud chcete zobrazit navýšení kvóty využití a žádosti, přečtěte si téma Zobrazení využití a kvót na webu Azure Portal. Pokud chcete zobrazit náklady na provoz spravovaného online koncového bodu, přečtěte si téma Zobrazení nákladů na spravovaný online koncový bod.
Azure Machine Učení poskytuje fond sdílených kvót, ze kterého mají všichni uživatelé přístup k kvótě, aby mohli provádět testování po omezenou dobu. Když pomocí studia nasadíte modely Llama (z katalogu modelů) do spravovaného online koncového bodu, azure machine Učení vám umožní získat přístup k této sdílené kvótě po krátkou dobu.
Pokud chcete nasadit model chatu Llama-2-2-70b nebo Llama-2-70b, musíte ale mít předplatné smlouva Enterprise, než budete moct nasadit sdílenou kvótu. Další informace o tom, jak používat sdílenou kvótu pro nasazení online koncových bodů, najdete v tématu Nasazení základních modelů pomocí studia.
Další informace o kvótách a omezeních pro prostředky ve službě Azure Machine Učení najdete v tématu Správa a zvýšení kvót a omezení prostředků pomocí služby Azure Machine Učení.
Nasazení pro codery a jiné než codery
Azure Machine Učení podporuje nasazení modelu do online koncových bodů pro codery a jiné než codery, a to tím, že poskytuje možnosti nasazení bez kódu, nasazení s nízkým kódem a nasazení byOC (Bring Your Own Container).
- Nasazení bez kódu poskytuje odvozování předem pro běžné architektury (například scikit-learn, TensorFlow, PyTorch a ONNX) prostřednictvím MLflow a Tritonu.
- Nasazení s minimem kódu umožňuje poskytnout minimální kód společně s modelem strojového učení pro nasazení.
- Nasazení BYOC umožňuje prakticky přenést všechny kontejnery ke spuštění vašeho online koncového bodu. Ke správě kanálů MLOps můžete použít všechny funkce platformy Azure Machine Učení, jako je automatické škálování, GitOps, ladění a bezpečné zavedení.
Následující tabulka uvádí klíčové aspekty možností online nasazení:
| Bez kódu | Nízký kód | BYOC | |
|---|---|---|---|
| Souhrn | Používá integrované odvozování pro oblíbené architektury, jako jsou scikit-learn, TensorFlow, PyTorch a ONNX, prostřednictvím MLflow a Triton. Další informace najdete v tématu Nasazení modelů MLflow do online koncových bodů. | Používá zabezpečené a veřejně publikované kurátorované image pro oblíbené architektury s aktualizacemi každých dva týdny k řešení ohrožení zabezpečení. Zadáte hodnoticí skript nebo závislosti Pythonu. Další informace najdete v tématu Azure Machine Učení kurátorovaná prostředí. | Kompletní zásobník poskytnete prostřednictvím podpory služby Azure Machine Učení pro vlastní image. Další informace najdete v tématu Použití vlastního kontejneru k nasazení modelu do online koncového bodu. |
| Vlastní základní image | Ne, kurátorované prostředí to poskytne pro snadné nasazení. | Ano a Ne, můžete použít kurátorovaný obrázek nebo přizpůsobený obrázek. | Ano, přineste přístupné umístění image kontejneru (například docker.io, Azure Container Registry (ACR) nebo Microsoft Container Registry (MCR) nebo soubor Dockerfile, který můžete sestavit nebo odeslat pomocí ACR pro váš kontejner. |
| Vlastní závislosti | Ne, kurátorované prostředí to poskytne pro snadné nasazení. | Ano, přineste prostředí Azure Machine Učení, ve kterém model běží, buď image Dockeru se závislostmi Conda, nebo soubor dockerfile. | Ano, tato možnost bude zahrnuta v imagi kontejneru. |
| Vlastní kód | Ne, bodovací skript se automaticky vygeneruje pro snadné nasazení. | Ano, přineste svůj bodovací skript. | Ano, tato možnost bude zahrnuta v imagi kontejneru. |
Poznámka:
AutoML spustí automaticky bodovací skript a závislosti pro uživatele, takže můžete nasadit libovolný model AutoML bez vytváření dalšího kódu (pro nasazení bez kódu) nebo můžete upravit automaticky generované skripty pro potřeby vaší firmy (pro nasazení s minimem kódu). Informace o nasazení pomocí modelů AutoML najdete v tématu Nasazení modelu AutoML s online koncovým bodem.
Ladění online koncových bodů
Důrazně doporučujeme , abyste koncový bod testovali místně, abyste před nasazením do Azure ověřili a ladili kód a konfiguraci. Azure CLI a Python SDK podporují místní koncové body a nasazení, zatímco studio Azure Machine Learning a šablona ARM ne.
Azure Machine Učení poskytuje různé způsoby, jak ladit online koncové body místně a pomocí protokolů kontejnerů.
- Místní ladění pomocí počítače Azure Učení odvozování serveru HTTP
- Místní ladění pomocí místního koncového bodu
- Místní ladění pomocí místního koncového bodu a editoru Visual Studio Code
- Ladění s využitím protokolů kontejneru
Místní ladění pomocí počítače Azure Učení odvozování serveru HTTP
Skript bodování můžete ladit místně pomocí počítače Azure Učení odvozování serveru HTTP. Server HTTP je balíček Pythonu, který zpřístupňuje funkci bodování jako koncový bod HTTP a zabalí kód serveru Flask a závislosti do jednotného balíčku. Je součástí předem připravených imagí Dockeru pro odvozování, které se používají při nasazování modelu se službou Azure Machine Učení. Pomocí samotného balíčku můžete model nasadit místně pro produkční prostředí a také snadno ověřit bodovací (vstupní) skript v místním vývojovém prostředí. Pokud dojde k potížím se skriptem bodování, server vrátí chybu a umístění, kde k chybě došlo. Visual Studio Code můžete také použít k ladění pomocí azure machine Učení odvozování serveru HTTP.
Tip
K místnímu ladění hodnoticího skriptu bez Modulu Dockeru můžete použít balíček Python pro odvozování serveru HTTP Učení odvozování. Ladění pomocí serveru odvozování vám pomůže ladit bodovací skript před nasazením do místních koncových bodů, abyste mohli ladit bez ovlivnění konfigurací kontejneru nasazení.
Další informace o ladění pomocí serveru HTTP najdete v tématu Ladění hodnoticí skript pomocí azure machine Učení odvozování serveru HTTP.
Místní ladění pomocí místního koncového bodu
Pro místní ladění potřebujete místní nasazení. To znamená model, který je nasazený do místního prostředí Dockeru. Toto místní nasazení můžete použít k testování a ladění před nasazením do cloudu. Pokud chcete nasadit místně, musíte mít nainstalovaný a spuštěný Modul Dockeru . Azure Machine Učení pak vytvoří místní image Dockeru, která napodobuje image azure machine Učení. Azure Machine Učení sestaví a spustí nasazení pro vás místně a uloží image do mezipaměti pro rychlé iterace.
Tip
Modul Dockeru se obvykle spustí při spuštění počítače. Pokud ne, můžete řešit potíže s Docker Enginem. K ladění toho, co se stane v kontejneru, můžete použít nástroje na straně klienta, jako je Docker Desktop .
Mezi kroky místního ladění obvykle patří:
- Kontrola úspěšného místního nasazení
- Vyvolání místního koncového bodu pro odvozování
- Kontrola výstupu operace vyvolání v protokolech
Poznámka:
Místní koncové body mají následující omezení:
- Nepodporují pravidla provozu, ověřování ani nastavení sondy.
- Podporují pouze jedno nasazení na koncový bod.
- Podporují soubory místního modelu a prostředí pouze s místním souborem conda. Pokud chcete testovat zaregistrované modely, nejdřív si je stáhněte pomocí rozhraní příkazového řádku nebo sady SDK a pak v definici nasazení použijte
pathodkaz na nadřazenou složku. Pokud chcete testovat registrovaná prostředí, zkontrolujte kontext prostředí v studio Azure Machine Learning a připravte místní soubor conda, který se má použít.
Další informace o místním ladění najdete v tématu Místní nasazení a ladění pomocí místního koncového bodu.
Místní ladění pomocí místního koncového bodu a editoru Visual Studio Code (Preview)
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Stejně jako u místního ladění musíte mít nejprve nainstalovaný a spuštěný modul Dockeru a pak nasadit model do místního prostředí Dockeru. Jakmile budete mít místní nasazení, Azure Machine Učení místní koncové body používají vývojové kontejnery Dockeru a Visual Studio Code (vývojové kontejnery) k sestavení a konfiguraci místního prostředí ladění. S vývojovými kontejnery můžete využívat funkce editoru Visual Studio Code, jako je interaktivní ladění, z kontejneru Dockeru.
Další informace o interaktivním ladění online koncových bodů v editoru VS Code najdete v tématu Místní ladění online koncových bodů v editoru Visual Studio Code.
Ladění s využitím protokolů kontejneru
Pro nasazení nemůžete získat přímý přístup k virtuálnímu počítači, na kterém je model nasazený. Můžete ale získat protokoly z některých kontejnerů, které jsou na tomto virtuálním počítači spuštěné. Existují dva typy kontejnerů, ze které můžete protokoly získat:
- Server odvozování: Protokoly zahrnují protokol konzoly (ze serveru odvozování), který obsahuje výstup funkcí tisku/protokolování ze skriptu bodování (
score.pykód). - Inicializátor úložiště: Protokoly obsahují informace o tom, jestli se data kódu a modelu úspěšně stáhla do kontejneru. Kontejner se spustí před spuštěním kontejneru serveru pro odvození.
Další informace o ladění pomocí protokolů kontejneru najdete v tématu Získání protokolů kontejneru.
Směrování provozu a zrcadlení do online nasazení
Vzpomeňte si, že jeden online koncový bod může mít více nasazení. Když koncový bod přijímá příchozí provoz (nebo požadavky), může směrovat procenta provozu do každého nasazení, jak se používá v nativní strategii nasazení s modrou/zelenou barvou. Může také zrcadlit (nebo kopírovat) provoz z jednoho nasazení do jiného, označovaného také jako zrcadlení provozu nebo stínování.
Směrování provozu pro modré/zelené nasazení
Modré/zelené nasazení je strategie nasazení, která umožňuje zavést nové nasazení (zelené nasazení) pro malou podmnožinu uživatelů nebo požadavků, než ho úplně zpřístupníte. Koncový bod může implementovat vyrovnávání zatížení, aby každému nasazení přidělil určité procento provozu, přičemž celkové přidělení napříč všemi nasazeními sčítá až 100 %.
Tip
Požadavek může obejít nakonfigurované vyrovnávání zatížení provozu zahrnutím hlavičky azureml-model-deploymentHTTP . Nastavte hodnotu hlavičky na název nasazení, do kterého se má požadavek směrovat.
Následující obrázek ukazuje nastavení v studio Azure Machine Learning pro přidělování provozu mezi modrým a zeleným nasazením.

Toto přidělení provozu směruje provoz, jak je znázorněno na následujícím obrázku, přičemž 10 % provozu přejde do zeleného nasazení a 90 % provozu přejde do modrého nasazení.
Zrcadlení provozu do online nasazení
Koncový bod může také zrcadlit (nebo kopírovat) provoz z jednoho nasazení do jiného nasazení. Zrcadlení provozu (označované také jako stínové testování) je užitečné, když chcete otestovat nové nasazení s produkčním provozem, aniž by to mělo vliv na výsledky, které zákazníci dostávají z existujících nasazení. Například při implementaci modrého/zeleného nasazení, kde se 100 % provozu směruje na modrou a 10 % se zrcadlí se zeleným nasazením, výsledky zrcadleného provozu do zeleného nasazení se nevrátí klientům, ale metriky a protokoly se zaznamenávají.

Informace o používání zrcadlení provozu najdete v tématu Sejf zavedení pro online koncové body.
Další možnosti online koncových bodů ve službě Azure Machine Učení
Ověřování a šifrování
- Ověřování: Klíče a tokeny azure machine Učení
- Spravovaná identita: Přiřazené uživatelem a přiřazený systém
- Ve výchozím nastavení ssl pro vyvolání koncového bodu
Automatické škálování
Automatické škálování automaticky spustí správné množství prostředků ke zvládnutí zatížení u vaší aplikace. Spravované koncové body podporují automatické škálování prostřednictvím integrace s funkcí automatického škálování služby Azure Monitor. Můžete nakonfigurovat škálování na základě metrik (například využití >procesoru 70 %), škálování na základě plánu (například pravidla škálování pro špičku pracovní doby) nebo kombinaci.

Informace o tom, jak nakonfigurovat automatické škálování, najdete v tématu Postup automatického škálování online koncových bodů.
Izolace spravované sítě
Při nasazování modelu strojového učení do spravovaného online koncového bodu můžete zabezpečit komunikaci s online koncovým bodem pomocí privátních koncových bodů.
Zabezpečení příchozích žádostí o bodování a odchozí komunikace s pracovním prostorem a dalšími službami můžete nakonfigurovat samostatně. Příchozí komunikace používá privátní koncový bod pracovního prostoru Azure Machine Učení. Odchozí komunikace používá privátní koncové body vytvořené pro spravovanou virtuální síť pracovního prostoru.
Další informace najdete v tématu Izolace sítě se spravovanými online koncovými body.
Monitorování online koncových bodů a nasazení
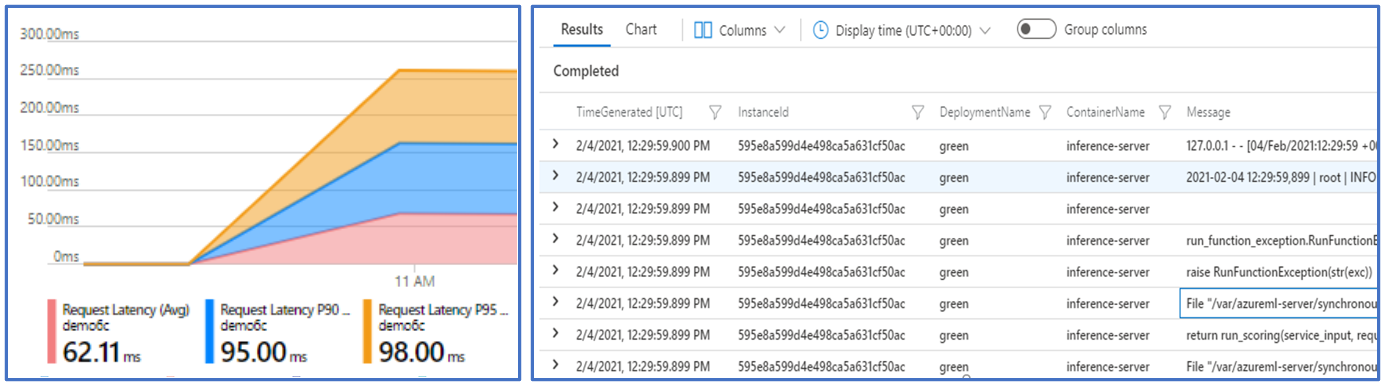
Monitorování koncových bodů služby Azure Machine Učení je možné prostřednictvím integrace se službou Azure Monitor. Tato integrace umožňuje zobrazit metriky v grafech, konfigurovat výstrahy, dotazovat se z tabulek protokolů, používat application Přehledy k analýze událostí z kontejnerů uživatelů atd.
Metriky: Pomocí služby Azure Monitor můžete sledovat různé metriky koncových bodů, jako je latence požadavků, a přejít k podrobnostem na úrovni nasazení nebo stavu. Můžete také sledovat metriky na úrovni nasazení, jako je využití procesoru nebo GPU, a přejít k podrobnostem na úrovni instance. Azure Monitor umožňuje sledovat tyto metriky v grafech a nastavit řídicí panely a výstrahy pro další analýzu.
Protokoly: Odesílání metrik do pracovního prostoru služby Log Analytics, kde můžete dotazovat protokoly pomocí syntaxe dotazu Kusto. Metriky můžete také odesílat do účtu úložiště nebo do služby Event Hubs pro další zpracování. Kromě toho můžete použít vyhrazené tabulky protokolů pro události, přenosy a protokoly kontejnerů související s online koncovým bodem. Dotaz Kusto umožňuje složitou analýzu spojování více tabulek.
Application Insights: Kurátorovaná prostředí zahrnují integraci s Přehledy aplikace a při vytváření online nasazení ji můžete povolit nebo zakázat. Integrované metriky a protokoly se odesílají do Application Insights a k další analýze můžete použít její integrované funkce, jako jsou živé metriky, vyhledávání transakcí, selhání a výkon.
Další informace o monitorování najdete v tématu Monitorování online koncových bodů.
Injektáž tajných kódů v online nasazeních (Preview)
Injektáž tajných kódů v kontextu online nasazení je proces načítání tajných kódů (například klíčů rozhraní API) z úložišť tajných kódů a jejich vložení do kontejneru uživatele, který běží uvnitř online nasazení. Tajné kódy budou nakonec přístupné prostřednictvím proměnných prostředí, což zajistí bezpečný způsob, jak je využívat server pro odvozování, který spouští váš bodovací skript nebo zásobník odvozování, který přinášíte s přístupem nasazení BYOC (přineste si vlastní kontejner).
Tajné kódy můžete vkládat dvěma způsoby. Tajné kódy můžete vkládat sami, používat spravované identity nebo můžete použít funkci injektáže tajných kódů. Další informace o způsobech vkládání tajných kódů najdete v tématu Injektáž tajných kódů v online koncových bodech (Preview).
Další kroky
- Nasazení online koncových bodů pomocí Azure CLI a sady Python SDK
- Nasazení dávkových koncových bodů pomocí Azure CLI a sady Python SDK
- Použití izolace sítě se spravovanými online koncovými body
- Nasazení modelů pomocí REST
- Monitorování spravovaných online koncových bodů
- Zobrazení nákladů na spravované online koncové body
- Správa a navýšení kvót pro prostředky s využitím služby Azure Machine Learning.