Datové vědy s windows Data Science Virtual Machine
Windows Data Science Virtual Machine (DSVM) je výkonné vývojové prostředí pro datové vědy, ve kterém můžete provádět úlohy zkoumání a modelování dat. Prostředí je již sestavené a součástí několika oblíbených nástrojů pro analýzu dat, které usnadňují zahájení analýzy místních, cloudových nebo hybridních nasazení.
DSVM úzce spolupracuje se službami Azure. Může číst a zpracovávat data, která jsou už uložená v Azure, v Azure Synapse (dříve SQL DW), Azure Data Lake, Azure Storage nebo Azure Cosmos DB. Může také využívat další analytické nástroje, jako je Azure Machine Learning.
V tomto článku se dozvíte, jak používat DSVM k provádění úloh datových věd a interakci s dalšími službami Azure. Tady jsou některé z věcí, které můžete na DSVM dělat:
Pomocí Jupyter Notebook můžete experimentovat s daty v prohlížeči pomocí Pythonu 2, Pythonu 3 a Microsoft R. (Microsoft R je verze jazyka R připravená pro podniky, která je určená pro výkon.)
Prozkoumejte data a vyvíjejte modely místně na DSVM pomocí Microsoft Machine Learning Server a Pythonu.
Spravujte prostředky Azure pomocí Azure Portal nebo PowerShellu.
Rozšiřte prostor úložiště a sdílejte rozsáhlé datové sady a kódy napříč celým týmem tím, že vytvoříte Azure Files sdílenou složku jako připojitelnou jednotku na vašem DSVM.
Sdílejte kód se svým týmem pomocí GitHubu. Získejte přístup k úložišti pomocí předinstalovaných klientů Git: Git Bash a Grafické uživatelské rozhraní Gitu.
Přístup k datovým a analytickým službám Azure, jako je Azure Blob Storage, Azure Cosmos DB, Azure Synapse (dříve SQL DW) a Azure SQL Database.
Sestavy a řídicí panel můžete vytvářet pomocí instance Power BI Desktop, která je předinstalovaná na DSVM, a nasazovat je do cloudu.
Nainstalujte na virtuální počítač další nástroje.
Poznámka
U mnoha služeb úložiště dat a analýz uvedených v tomto článku se účtují další poplatky za využití. Podrobnosti najdete na stránce s cenami Azure .
Požadavky
- Potřebujete předplatné Azure. Můžete si zaregistrovat bezplatnou zkušební verzi.
- Pokyny ke zřízení Data Science Virtual Machine na Azure Portal najdete v tématu Vytvoření virtuálního počítače.
Poznámka
K interakci s Azure doporučujeme použít modul Azure Az PowerShell. Začněte tím, že si projdete téma Instalace Azure PowerShellu. Informace o tom, jak migrovat na modul Az PowerShell, najdete v tématu Migrace Azure PowerShellu z AzureRM na Az.
Použití Jupyter Notebooks
Jupyter Notebook poskytuje integrované vývojové prostředí (IDE) založené na prohlížeči pro zkoumání a modelování dat. V Jupyter Notebook můžete použít Python 2, Python 3 nebo R.
Jupyter Notebook spustíte tak, že v nabídce Start nebo na ploše vyberete ikonu Jupyter Notebook. Na příkazovém řádku DSVM můžete příkaz jupyter notebook spustit také z adresáře, ve kterém máte existující poznámkové bloky nebo kde chcete vytvořit nové poznámkové bloky.
Po spuštění Jupyteru přejděte do /notebooks adresáře, například poznámkové bloky, které jsou předem zabalené do DSVM. Nyní můžete:
- Výběrem poznámkového bloku zobrazíte kód.
- Jednotlivé buňky spusťte tak, že vyberete Shift+Enter.
- Spusťte celý poznámkový blok výběrem možnosti Spustit buňku>.
- Nový poznámkový blok vytvoříte tak, že vyberete ikonu Jupyter (v levém horním rohu), vpravo vyberete tlačítko Nový a pak zvolíte jazyk poznámkového bloku (označovaný také jako jádra).
Poznámka
V současné době se v Jupyteru podporují jádra Python 2.7, Python 3.6, R, Julia a PySpark. Jádro R podporuje programování v opensourcovém jazyce R i Microsoft R.
Když jste v poznámkovém bloku, můžete zkoumat data, sestavit model a otestovat model pomocí knihoven, které si zvolíte.
Zkoumání dat a vývoj modelů pomocí Microsoft Machine Learning Server
Poznámka
Podpora pro Machine Learning Server Standalone skončí 1. července 2021. Odebereme ho z imagí DSVM po 30. červnu. Stávající nasazení budou mít i nadále přístup k softwaru, ale vzhledem k dosažení koncového data podpory pro něj nebude po 1. červenci 2021 žádná podpora.
K analýze dat přímo na DSVM můžete použít jazyky, jako je R a Python.
Pro R můžete použít Nástroje R pro Visual Studio. Společnost Microsoft poskytla další knihovny nad opensourcovou architekturou CRAN R, které umožňují škálovatelnou analýzu a možnost analyzovat data větší, než je velikost paměti povolená při paralelní analýze bloků dat.
Pro Python můžete použít integrované vývojové prostředí (IDE), jako je Visual Studio Community Edition, které má předinstalované rozšíření Python Tools for Visual Studio (PTVS). Ve výchozím nastavení je v PTVS nakonfigurovaný pouze Python 3.6, kořenové prostředí Conda. Pokud chcete povolit Anaconda Python 2.7, proveďte následující kroky:
- Vytvořte vlastní prostředí pro každou verzi tak, že přejdete na Nástroje>Nástroje Python Tools>Prostředí Pythonu a pak v Visual Studio Community Edition vyberete + Vlastní.
- Zadejte popis a nastavte cestu předpony prostředí jako c:\anaconda\envs\python2 pro Anaconda Python 2.7.
- Vyberte Automaticky rozpoznat>použít a uložte prostředí.
Další podrobnosti o vytváření prostředí Pythonu najdete v dokumentaci k PTVS .
Teď jste připraveni vytvořit nový projekt Pythonu. Přejděte na Soubor>Nový>projekt Pythonu> a vyberte typ aplikace v Pythonu, kterou vytváříte. Prostředí Pythonu pro aktuální projekt můžete nastavit na požadovanou verzi (Python 2.7 nebo 3.6) tak, že kliknete pravým tlačítkem na Prostředí Pythonu a pak vyberete Přidat nebo odebrat prostředí Pythonu. Další informace o práci s PTVS najdete v produktové dokumentaci.
Správa prostředků Azure
DsVM neumožňuje vytvářet analytické řešení jenom místně na virtuálním počítači. Umožňuje také přístup ke službám na cloudové platformě Azure. Azure poskytuje několik výpočetních, úložných, analytických a dalších služeb, které můžete spravovat a přistupovat z dsVM.
Pokud chcete spravovat předplatné Azure a cloudové prostředky, máte dvě možnosti:
Použijte prohlížeč a přejděte na Azure Portal.
Použijte skripty PowerShellu. Spusťte Azure PowerShell z zástupce na ploše nebo z nabídky Start. Úplné podrobnosti najdete v dokumentaci k Microsoft Azure PowerShell.
Rozšíření úložiště pomocí sdílených systémů souborů
Datoví vědci můžou v rámci týmu sdílet velké datové sady, kód nebo jiné prostředky. DsVM má k dispozici přibližně 45 GB místa. Pokud chcete rozšířit úložiště, můžete použít Azure Files a buď ho připojit k jedné nebo několika instancím DSVM, nebo k němu přistupovat přes rozhraní REST API. Můžete také použít Azure Portal nebo použít Azure PowerShell k přidání dalších vyhrazených datových disků.
Poznámka
Maximální místo ve sdílené složce Azure Files je 5 TB. Limit velikosti každého souboru je 1 TB.
Tento skript můžete použít v Azure PowerShell k vytvoření sdílené složky Azure Files:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Teď, když jste vytvořili sdílenou složku Azure Files, ji můžete připojit k libovolnému virtuálnímu počítači v Azure. Doporučujeme, abyste virtuální počítač umístili do stejného datacentra Azure jako účet úložiště, abyste se vyhnuli poplatkům za latenci a přenos dat. Tady jsou Azure PowerShell příkazy pro připojení jednotky k DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Teď k této jednotce máte přístup stejně jako k jakékoli normální jednotce na virtuálním počítači.
Sdílení kódu na GitHubu
GitHub je úložiště kódu, kde můžete najít ukázky kódu a zdroje pro různé nástroje pomocí technologií sdílených komunitou vývojářů. Používá Git jako technologii ke sledování a ukládání verzí souborů kódu. GitHub je také platforma, kde můžete vytvořit vlastní úložiště pro ukládání sdíleného kódu a dokumentace vašeho týmu, implementaci správy verzí a kontrolu nad tím, kdo má přístup k zobrazení a přispívání kódu.
Další informace o používání Gitu najdete na stránkách nápovědy GitHubu . GitHub můžete použít jako jeden ze způsobů spolupráce s týmem, použití kódu vyvinutého komunitou a přispívání kódu zpět do komunity.
DSVM se dodává s klientskými nástroji na příkazovém řádku a v grafickém uživatelském rozhraní pro přístup k úložišti GitHub. Nástroj příkazového řádku, který funguje s Gitem a GitHubem, se nazývá Git Bash. Visual Studio je nainstalované na DSVM a má rozšíření Gitu. Ikony pro tyto nástroje najdete v nabídce Start a na ploše.
Ke stažení kódu z úložiště GitHub použijte git clone příkaz . Pokud například chcete stáhnout úložiště datových věd publikované Microsoftem do aktuálního adresáře, můžete v Git Bash spustit následující příkaz:
git clone https://github.com/Azure/DataScienceVM.git
V sadě Visual Studio můžete provést stejnou operaci klonování. Následující snímek obrazovky ukazuje, jak získat přístup k nástrojům Git a GitHub v sadě Visual Studio:
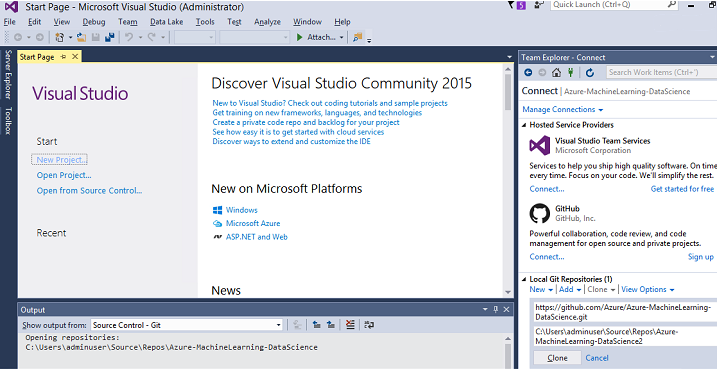
Další informace o použití Gitu k práci s úložištěm GitHub najdete v prostředcích, které jsou k dispozici na github.com. Tahák je užitečný odkaz.
Přístup k datovým a analytickým službám Azure
Azure Blob Storage
Azure Blob Storage je spolehlivá a úsporná služba cloudového úložiště pro velké a malé objemy dat. Tato část popisuje, jak můžete přesunout data do úložiště objektů blob a přistupovat k datům uloženým v objektu blob Azure.
Požadavky
Z Azure Portal vytvořte účet služby Azure Blob Storage.
Ověřte, že je nástroj AzCopy pro příkazový řádek předinstalovaný:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exe. Adresář, který obsahuje azcopy.exe, se již nachází v proměnné prostředí PATH, takže při spuštění tohoto nástroje nemusíte zadávat úplnou cestu k příkazu. Další informace o nástroji AzCopy najdete v dokumentaci k Nástroji AzCopy.Spusťte nástroj Průzkumník služby Azure Storage. Můžete si ho stáhnout z webové stránky Průzkumník služby Storage.

Přesun dat z virtuálního počítače do objektu blob Azure: AzCopy
K přesunu dat mezi místními soubory a úložištěm objektů blob můžete použít AzCopy na příkazovém řádku nebo v PowerShellu:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
Nahraďte C:\myfolder cestou, kde je soubor uložený, mystorageaccount názvem vašeho účtu úložiště objektů blob, mycontainer názvem kontejneru a klíčem účtu úložiště přístupovým klíčem služby Blob Storage. Přihlašovací údaje k účtu úložiště najdete v Azure Portal.
Spusťte příkaz AzCopy v PowerShellu nebo z příkazového řádku. Tady je několik příkladů použití příkazu AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Po spuštění příkazu AzCopy ke zkopírování do objektu blob Azure se soubor zobrazí v Průzkumník služby Azure Storage.

Přesun dat z virtuálního počítače do objektu blob Azure: Průzkumník služby Azure Storage
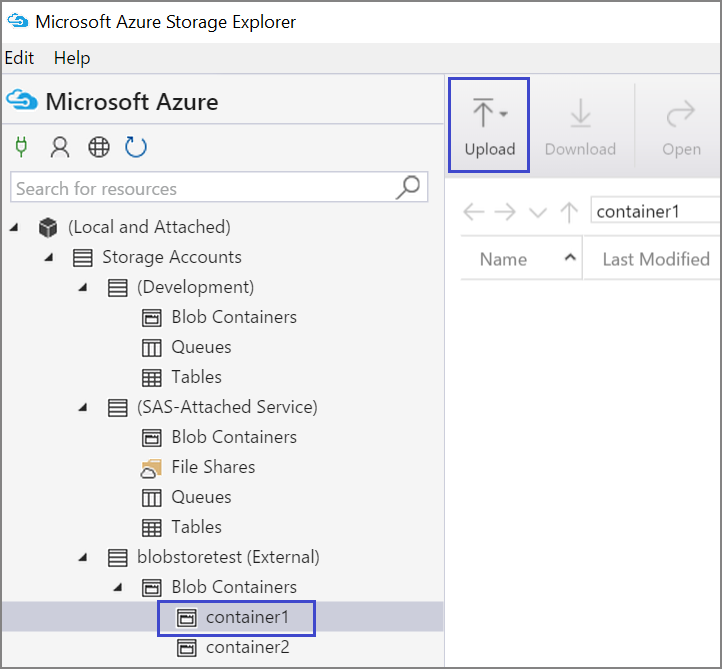
Můžete také nahrát data z místního souboru ve virtuálním počítači pomocí Průzkumník služby Azure Storage:
- Pokud chcete nahrát data do kontejneru, vyberte cílový kontejner a vyberte tlačítko Nahrát.
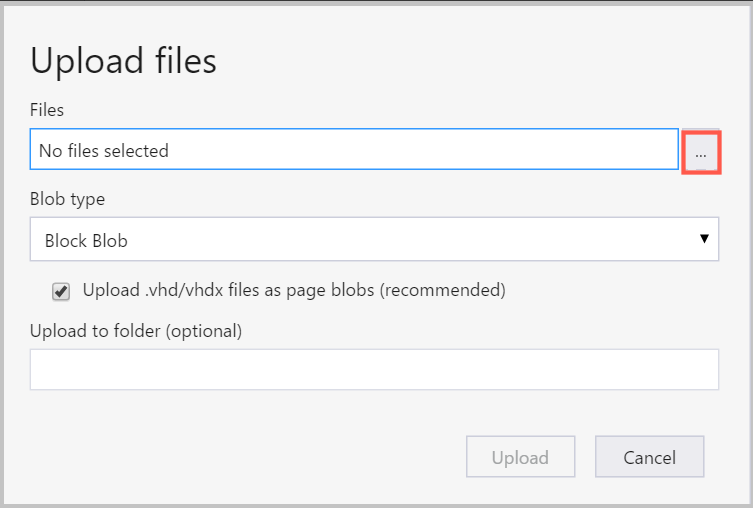
- Vyberte tři tečky (...) napravo od pole Soubory , vyberte jeden nebo více souborů, které chcete nahrát ze systému souborů, a vyberte Nahrát , aby se soubory začaly nahrávat.
Čtení dat z objektu blob Azure: Python ODBC
Pomocí knihovny BlobService můžete číst data přímo z objektu blob v Jupyter Notebook nebo v programu Python.
Nejprve naimportujte požadované balíčky:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Pak připojte přihlašovací údaje účtu úložiště blob a načtěte data z objektu blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
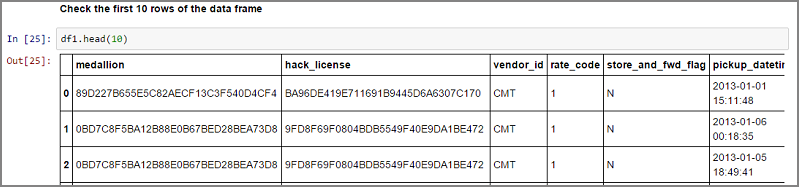
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Data se čtou jako datový rámec:
Azure Synapse Analytics a databáze
Azure Synapse Analytics je elastický datový sklad jako služba s prostředím SQL Server podnikové úrovně.
Azure Synapse Analytics můžete zřídit podle pokynů v tomto článku. Po zřízení Azure Synapse Analytics můžete tento názorný postup použít k nahrávání, zkoumání a modelování dat pomocí dat v rámci Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB je databáze NoSQL v cloudu. Můžete ho použít k práci s dokumenty, jako je JSON, a k ukládání a dotazování dokumentů.
Pokud chcete získat přístup ke službě Azure Cosmos DB z DSVM, postupujte následovně:
Sada Python SDK služby Azure Cosmos DB je už na DSVM nainstalovaná. Pokud ho chcete aktualizovat, spusťte
pip install pydocumentdb --upgradeho z příkazového řádku.Z Azure Portal vytvořte účet a databázi Azure Cosmos DB.
Stáhněte si nástroj pro migraci dat Azure Cosmos DB z webu Microsoft Download Center a extrahujte ho do libovolného adresáře.
Importujte data JSON (sopečná data) uložená ve veřejném objektu blob do služby Azure Cosmos DB pomocí následujících parametrů příkazu do nástroje pro migraci. (Použijte dtui.exe z adresáře, do kterého jste nainstalovali nástroj pro migraci dat služby Azure Cosmos DB.) Zadejte zdrojové a cílové umístění s těmito parametry:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Po importu dat můžete přejít do Jupyteru a otevřít poznámkový blok s názvem DocumentDBSample. Obsahuje kód Pythonu pro přístup ke službě Azure Cosmos DB a k základnímu dotazování. Další informace o službě Azure Cosmos DB najdete na stránce dokumentace ke službě.
Použití sestav a řídicích panelů Power BI
Soubor JSON Volcano z předchozího příkladu služby Azure Cosmos DB můžete vizualizovat v Power BI Desktop, abyste získali vizuální přehled o datech. Podrobný postup najdete v článku o Power BI. Tady jsou základní kroky:
- Otevřete Power BI Desktop a vyberte Načíst data. Zadejte adresu URL takto:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Měli byste vidět záznamy JSON naimportované jako seznam. Převeďte seznam na tabulku, aby s ním Power BI mohl pracovat.
- Rozbalte sloupce výběrem ikony rozbalení (šipka).
- Všimněte si, že umístěním je pole Záznam . Rozbalte záznam a vyberte pouze souřadnice. Souřadnice je sloupec seznamu.
- Přidejte nový sloupec, který převede sloupec souřadnic seznamu na sloupec LatLong oddělený čárkami. Zřetězení dvou prvků v poli seznamu souřadnic pomocí vzorce
Text.From([coordinates]{1})&","&Text.From([coordinates]{0}). - Převeďte sloupec Elevation (Zvýšení oprávnění ) na decimal (Desetinné číslo) a vyberte tlačítka Close (Zavřít ) a Apply (Použít ).
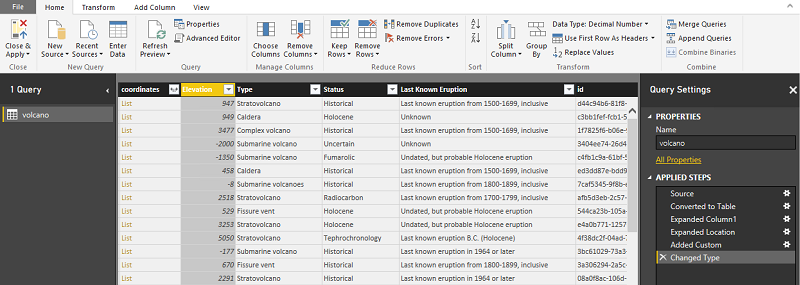
Místo předchozích kroků můžete vložit následující kód. Skriptuje kroky použité v Rozšířený editor v Power BI k zápisu transformací dat v dotazovacím jazyce.
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Teď máte data v datovém modelu Power BI. Instance Power BI Desktop by měla vypadat takto:
Pomocí datového modelu můžete začít vytvářet sestavy a vizualizace. Sestavu můžete vytvořit podle kroků v tomto článku o Power BI .
Dynamické škálování DSVM
Virtuální počítač DSVM můžete vertikálně navýšit nebo snížit podle potřeb vašeho projektu. Pokud virtuální počítač nepotřebujete používat večer nebo o víkendech, můžete ho vypnout z Azure Portal.
Poznámka
Pokud pro operační systém na virtuálním počítači použijete pouze tlačítko pro vypnutí, budou se vám účtovat poplatky za výpočetní prostředky. Místo toho byste měli uvolnit dsvm pomocí Azure Portal nebo Cloud Shell.
Možná budete muset provést rozsáhlé analýzy a budete potřebovat větší kapacitu procesoru, paměti nebo disku. Pokud ano, můžete si vybrat velikosti virtuálních počítačů z hlediska jader procesoru, instancí gpu pro hloubkové učení, kapacity paměti a typů disků (včetně jednotek SSD), které splňují vaše výpočetní a rozpočtové požadavky. Úplný seznam virtuálních počítačů spolu s hodinovými cenami výpočetních prostředků je k dispozici na stránce s cenami azure Virtual Machines.
Přidání dalších nástrojů
Nástroje předem vytvořené v DSVM můžou řešit řadu běžných potřeb analýzy dat. To vám ušetří čas, protože nemusíte instalovat a konfigurovat prostředí jedno po druhém. Zároveň ušetříte peníze, protože platíte jenom za prostředky, které využijete.
K vylepšení analytického prostředí můžete použít další datové a analytické služby Azure profilované v tomto článku. V některých případech můžete potřebovat další nástroje, včetně některých proprietárních partnerských nástrojů. K virtuálnímu počítači máte úplný přístup pro správu, abyste mohli nainstalovat nové nástroje, které potřebujete. V Pythonu a R můžete také nainstalovat další balíčky, které nejsou předinstalované. Pro Python můžete použít nebo condapip. Pro R můžete použít install.packages() v konzole R nebo použít integrované vývojové prostředí (IDE) a vybrat Packages InstallPackages (Balíčky >Nainstalovat balíčky).
Hloubkové učení
Kromě ukázek založených na architektuře můžete získat sadu komplexních návodů, které byly ověřeny na DSVM. Tyto názorné postupy vám pomůžou rychle začít s vývojem aplikací hlubokého učení v oblastech, jako je porozumění obrázkům a textu nebo jazyku.
Spouštění neurálních sítí v různých architekturách: Tento názorný postup ukazuje, jak migrovat kód z jedné architektury do jiné. Také ukazuje, jak porovnávat modely a výkon modulu runtime napříč architekturami.
Návod k vytvoření komplexního řešení pro detekci produktů v obrázcích: Detekce obrázků je technika, která umí najít a klasifikovat objekty v obrázcích. Tato technologie má potenciál přinést obrovské odměny v mnoha reálných obchodních oblastech. Prodejci můžou například pomocí této techniky určit, který produkt si zákazník vyzvedl z police. Tyto informace zase pomáhají obchodům spravovat inventář produktů.
Hloubkové učení pro zvuk: Tento kurz ukazuje, jak trénovat model hloubkového učení pro detekci zvukových událostí na datové sadě městských zvuků. Poskytuje také přehled práce se zvukovými daty.
Klasifikace textových dokumentů: Tento názorný postup ukazuje, jak vytvořit a vytrénovat dvě architektury neurální sítě: Hierarchical Attention Network a síť LSTM (Long Short Term Memory). Tyto neurální sítě používají rozhraní Keras API pro hloubkové učení ke klasifikaci textových dokumentů.
Souhrn
Tento článek popisuje některé věci, které můžete na Data Science Virtual Machine Microsoftu dělat. Existuje mnoho dalších věcí, které můžete udělat z DSVM efektivní analytické prostředí.