Verze a sledování datových sad azure Machine Učení
PLATÍ PRO: Python SDK azureml v1
Python SDK azureml v1
V tomto článku se dozvíte, jak z důvodu reprodukovatelnosti verzí a sledováním datových sad azure Machine Učení. Správa verzí datové sady záložky pro konkrétní stavy vašich dat, abyste mohli použít konkrétní verzi datové sady pro budoucí experimenty.
V těchto typických scénářích můžete chtít vytvořit verzi prostředků azure machine Učení:
- Jakmile budou nová data k dispozici pro opětovné natrénování
- Když použijete různé přístupy přípravy dat nebo přípravy funkcí
Požadavky
Sada Azure Machine Učení SDK pro Python Tato sada SDK zahrnuje balíček azureml-datasets .
Pracovní prostor Učení Azure Machine. Vytvořte nový pracovní prostor nebo načtěte existující pracovní prostor pomocí této ukázky kódu:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()Datová sada Učení azure machine
Registrace a načtení verzí datové sady
Registrovanou datovou sadu můžete v rámci experimentů a s kolegy sdílet, znovu použít a sdílet. Můžete zaregistrovat více datových sad pod stejným názvem a načíst konkrétní verzi podle názvu a čísla verze.
Registrace verze datové sady
Tento vzorový kód nastaví create_new_version parametr titanic_ds datové sady na True, aby se zaregistrovala nová verze této datové sady. Pokud pracovní prostor nemá zaregistrovanou žádnou datovou titanic_ds sadu, vytvoří kód novou datovou sadu s názvem titanic_dsa nastaví její verzi na 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Načtení datové sady podle názvu
Ve výchozím nastavení Dataset vrátí metoda třídy get_by_name() nejnovější verzi datové sady zaregistrované v pracovním prostoru.
Tento kód vrátí verzi 1 titanic_ds datové sady.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Osvědčený postup správy verzí
Při vytváření verze datové sady nevytáčíte další kopii dat s pracovním prostorem. Vzhledem k tomu, že datové sady jsou odkazy na data ve vaší službě úložiště, máte jediný zdroj pravdy spravovaný službou úložiště.
Důležité
Pokud se data, na která odkazuje vaše datová sada, přepíšou nebo odstraní, volání konkrétní verze datové sady se nezmění .
Při načítání dat z datové sady se aktuální datový obsah odkazovaný datovou sadou vždy načte. Pokud chcete mít jistotu, že je každá verze datové sady reprodukovatelná, doporučujeme vyhnout se úpravám datového obsahu, na který odkazuje verze datové sady. Když se objeví nová data, uložte nové datové soubory do samostatné složky dat a pak vytvořte novou verzi datové sady, která bude obsahovat data z této nové složky.
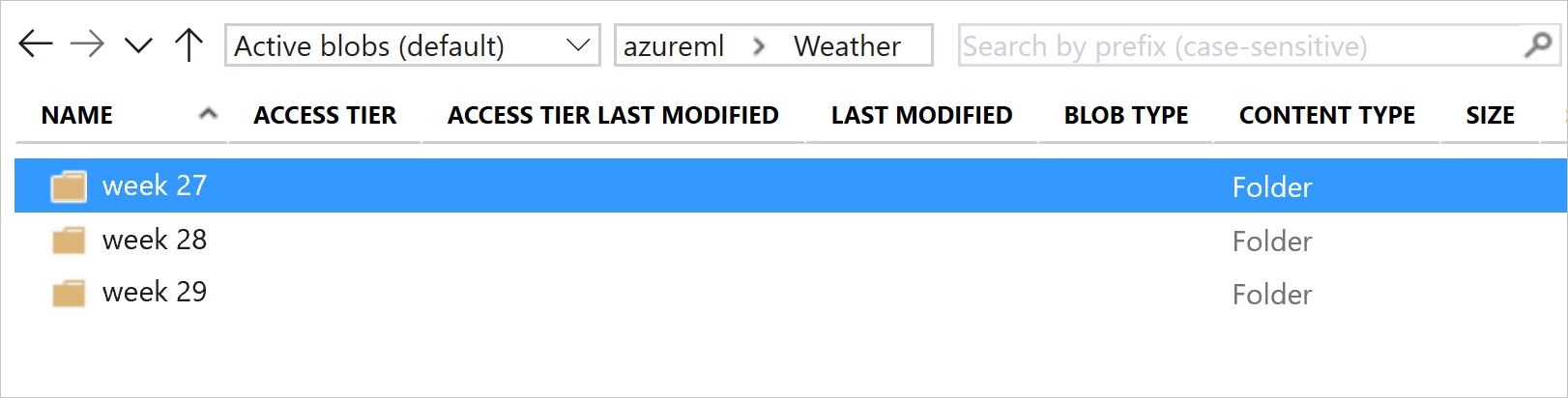
Tento obrázek a ukázkový kód ukazují doporučený způsob strukturování datových složek a vytvoření verzí datových sad, které odkazují na tyto složky:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Verze výstupní datové sady kanálu ML
Datovou sadu můžete použít jako vstup a výstup každého kroku kanálu ML. Při opětovném spuštění kanálů se výstup každého kroku kanálu zaregistruje jako nová verze datové sady.
Kanály počítače Učení naplní výstup každého kroku do nové složky při každém opětovném spuštění kanálu. Výstupní datové sady s verzí se pak stanou reprodukovatelnými. Další informace najdete v datových sadách v kanálech.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Sledování dat v experimentech
Azure Machine Učení sleduje data v rámci experimentu jako vstupní a výstupní datové sady. V těchto scénářích se vaše data sledují jako vstupní datová sada:
DatasetConsumptionConfigJako objekt prostřednictvím objektuinputsneboargumentsparametru objektuScriptRunConfigpři odesílání úlohy experimentuKdyž skript volá určité metody (
get_by_name()neboget_by_id()– například). Název přiřazený k datové sadě v okamžiku, kdy jste tuto datovou sadu zaregistrovali do pracovního prostoru, je zobrazovaný název.
V těchto scénářích se vaše data sledují jako výstupní datová sada:
Předání objektu
OutputFileDatasetConfigbuď pomocí parametruoutputs,argumentskdyž odešlete úlohu experimentu.OutputFileDatasetConfigobjekty mohou také uchovávat data mezi kroky kanálu. Další informace najdete v tématu Přesun dat mezi kroky kanálu ML.Zaregistrujte datovou sadu ve skriptu. Název přiřazený k datové sadě při registraci do pracovního prostoru je zobrazený název. V této ukázce
training_dskódu je zobrazovaný název:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Odeslání podřízené úlohy se neregistrovanou datovou sadou ve skriptu Výsledkem tohoto odeslání je anonymní uložená datová sada.
Trasování datových sad v úlohách experimentů
Pro každý experiment Učení počítače můžete trasovat vstupní datové sady objektu experimentuJob. Tento vzorový kód používá metodu get_details() ke sledování vstupních datových sad používaných při spuštění experimentu:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
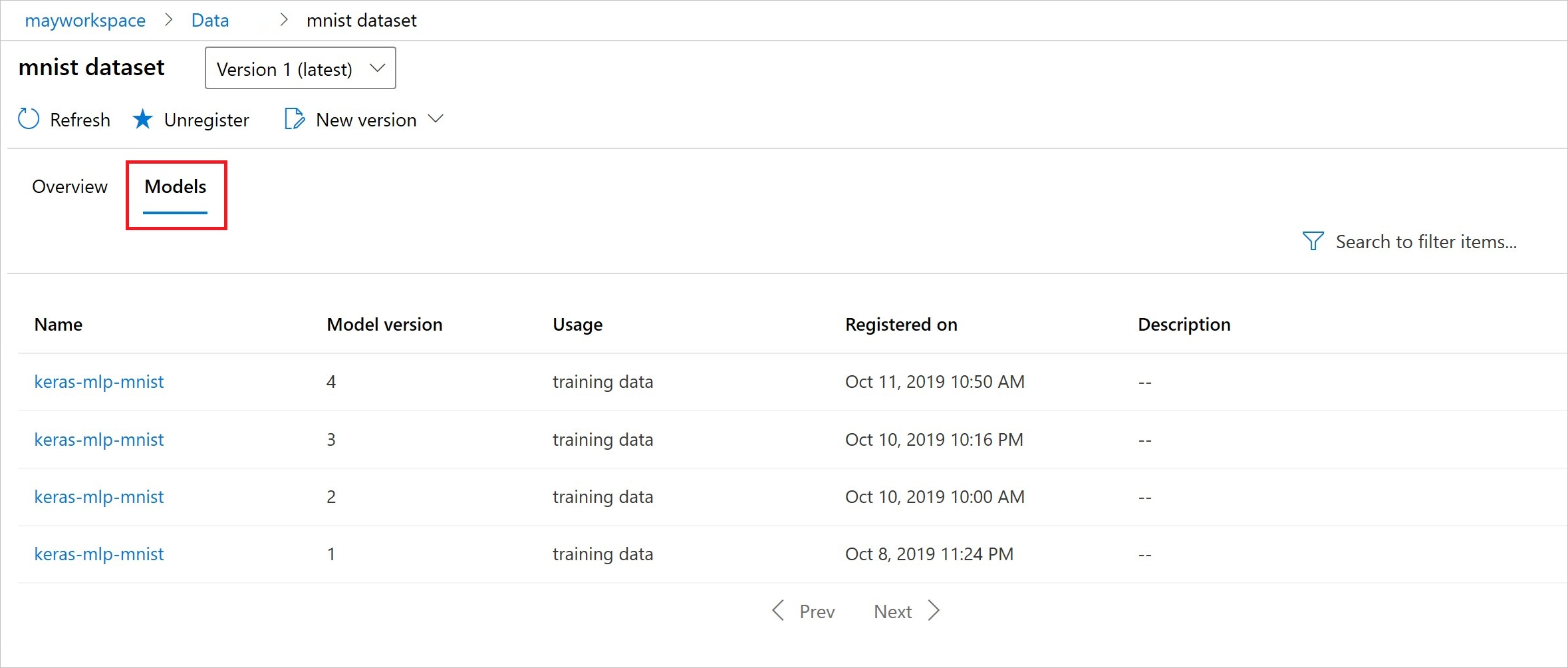
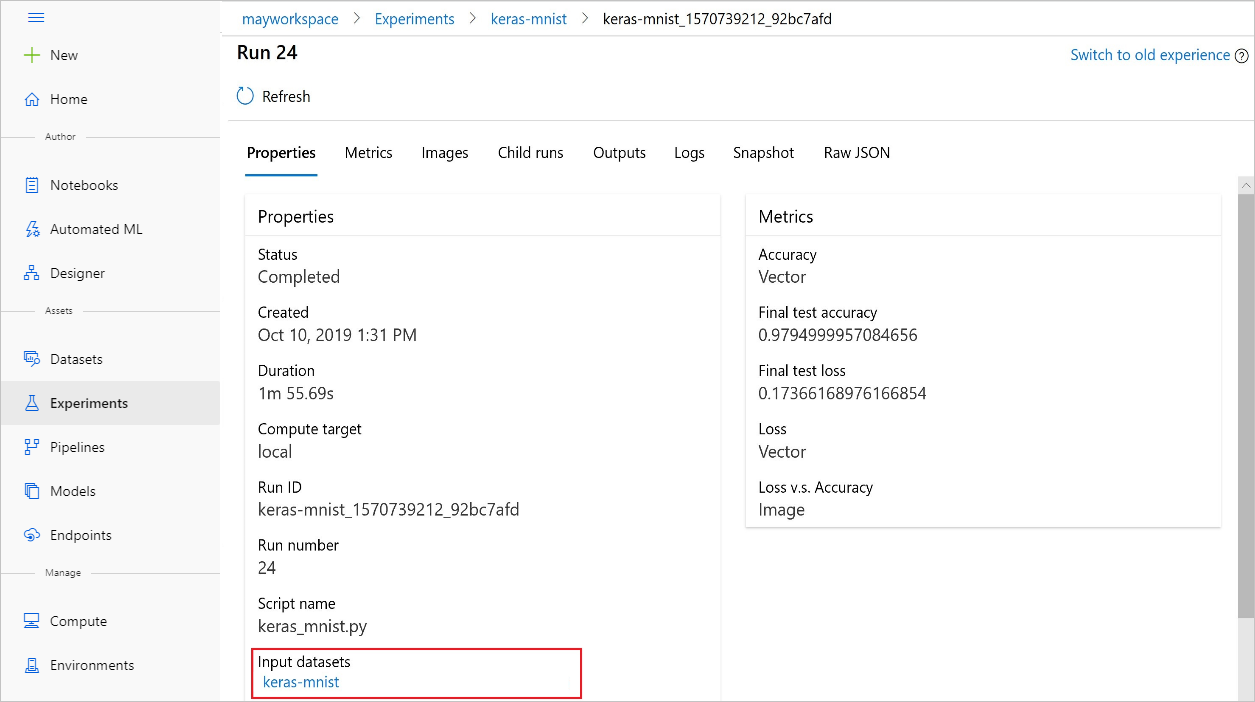
S studio Azure Machine Learning najdete také input_datasets experimenty z experimentů.
Tento snímek obrazovky ukazuje, kde najít vstupní datovou sadu experimentu na studio Azure Machine Learning. V tomto příkladu začněte v podokně Experimenty a otevřete kartu Vlastnosti pro konkrétní spuštění experimentu . keras-mnist
Tento kód registruje modely s datovými sadami:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
Po registraci můžete zobrazit seznam modelů registrovaných v datové sadě pomocí Pythonu nebo studia.
Snímek obrazovky Thia je z podokna Datové sady v části Prostředky. Vyberte datovou sadu a pak vyberte kartu Modely pro seznam modelů zaregistrovaných v datové sadě.