Správa nákladů pro bezserverový fond SQL v Azure Synapse Analytics
Tento článek vysvětluje, jak můžete odhadnout a spravovat náklady na bezserverový fond SQL v Azure Synapse Analytics:
- Odhad množství zpracovaných dat před vydáním dotazu
- Nastavení rozpočtu pomocí funkce řízení nákladů
Mějte na paměti, že náklady na bezserverový fond SQL v Azure Synapse Analytics představují pouze část měsíčních nákladů na faktuře za Azure. Pokud používáte jiné služby Azure, budou se vám účtovat všechny služby a prostředky Azure použité ve vašem předplatném Azure, včetně služeb třetích stran. Tento článek vysvětluje, jak plánovat a spravovat náklady na bezserverový fond SQL v Azure Synapse Analytics.
Zpracovaná data
Zpracovávaná data jsou množství dat, která systém dočasně ukládá při spuštění dotazu. Zpracovávaná data se skládají z následujících množství:
- Množství dat načtených z úložiště. Tato částka zahrnuje:
- Data čtená při čtení dat.
- Data čtená při čtení metadat (pro formáty souborů, které obsahují metadata, například Parquet).
- Množství dat v průběžných výsledcích. Během spuštění dotazu se tato data přenášejí mezi uzly. Zahrnuje přenos dat do koncového bodu v nekomprimované podobě.
- Množství dat zapsaných do úložiště Pokud použijete CETAS k exportu sady výsledků do úložiště, pak se množství zapsaných dat přidá k množství dat zpracovaných pro část CETAS SELECT.
Čtení souborů z úložiště je vysoce optimalizované. Proces používá:
- Předběžné načítání, což může částečně náležit k množství přečtených dat. Pokud dotaz přečte celý soubor, není to nijak náročné. Pokud se soubor čte částečně, například v dotazech TOP N, pak se pomocí předběžného načtení přečte o něco více dat.
- Analyzátor optimalizovaných hodnot oddělených čárkami (CSV). Pokud ke čtení souborů CSV použijete PARSER_VERSION='2.0', objem dat přečtených z úložiště se mírně zvýší. Optimalizovaný analyzátor CSV čte soubory paralelně v blocích stejné velikosti. Bloky dat nemusí nutně obsahovat celé řádky. Aby se zajistilo, že se analyzují všechny řádky, načte optimalizovaný analyzátor sdíleného svazku clusteru také malé fragmenty sousedních bloků dat. Tento proces přidává malou režii.
Statistika
Optimalizátor dotazů fondu SQL bez serveru spoléhá při generování optimálních plánů provádění dotazů na statistiky. Statistiky můžete vytvářet ručně. V opačném případě je bezserverový fond SQL vytvoří automaticky. V každém případě se statistiky vytvoří spuštěním samostatného dotazu, který vrátí konkrétní sloupec se zadanou vzorkovací frekvencí. K tomuto dotazu je přidruženo množství zpracovaných dat.
Pokud spustíte stejný nebo jakýkoli jiný dotaz, který by mohl využít vytvořené statistiky, pak se statistiky znovu použijí, pokud je to možné. Pro vytváření statistik se nezpracovávají žádná další data.
Při vytváření statistik pro sloupec Parquet se ze souborů načítá jenom příslušný sloupec. Při vytváření statistik pro sloupec CSV se čtou a analyzují celé soubory.
Zaokrouhlení
Množství zpracovaných dat se zaokrouhlí nahoru na nejbližší MB na dotaz. Každý dotaz má minimálně 10 MB zpracovaných dat.
Co zpracovaná data nezahrnují
- Metadata na úrovni serveru (například přihlašovací údaje, role a přihlašovací údaje na úrovni serveru).
- Databáze, které vytvoříte v koncovém bodu. Tyto databáze obsahují pouze metadata (například uživatele, role, schémata, zobrazení, vložené funkce s hodnotou tabulky [TVF], uložené procedury, přihlašovací údaje s oborem databáze, externí zdroje dat, externí formáty souborů a externí tabulky).
- Pokud použijete odvozování schématu, čtou se fragmenty souborů, které odvozují názvy sloupců a datové typy, a množství přečtených dat se přičte k objemu zpracovávaných dat.
- Příkazy jazyka DDL (Data Definition Language), s výjimkou příkazu CREATE STATISTICS, protože zpracovávají data z úložiště na základě zadaného procenta vzorku.
- Dotazy jenom na metadata.
Snížení množství zpracovávaných dat
Můžete optimalizovat množství zpracovávaných dat pro jednotlivé dotazy a zlepšit výkon tím, že data rozdělíte a převedete do komprimovaného formátu založeného na sloupcích, jako je Parquet.
Příklady
Představte si tři tabulky.
- Tabulka population_csv je 5 TB souborů CSV. Soubory jsou uspořádané do pěti stejně velkých sloupců.
- Tabulka population_parquet obsahuje stejná data jako tabulka population_csv. Podporuje ho 1 TB souborů Parquet. Tato tabulka je menší než předchozí, protože data se komprimují ve formátu Parquet.
- Tabulka very_small_csv je 100 kB souborů CSV.
Dotaz 1: SELECT SUM(population) FROM population_csv
Tento dotaz čte a parsuje celé soubory, aby získal hodnoty pro sloupec základního souboru. Uzly zpracovávají fragmenty této tabulky a mezi uzly se přenáší součet základního souboru pro každý fragment. Konečný součet se přenese do vašeho koncového bodu.
Tento dotaz zpracovává 5 TB dat a malou režii pro přenos součtů fragmentů.
Dotaz 2: SELECT SUM(population) FROM population_parquet
Při dotazování komprimovaných a sloupcových formátů, jako je Parquet, se přečte méně dat než v dotazu 1. Tento výsledek se zobrazí, protože bezserverový fond SQL čte jeden komprimovaný sloupec místo celého souboru. V tomto případě se čte 0,2 TB. (Pět stejně velkých sloupců má velikost 0,2 TB.) Uzly zpracovávají fragmenty této tabulky a mezi uzly se přenáší součet základního souboru pro každý fragment. Konečný součet se přenese do vašeho koncového bodu.
Tento dotaz zpracovává 0,2 TB plus malou část režie na přenos součtů fragmentů.
Dotaz 3: SELECT * FROM population_parquet
Tento dotaz přečte všechny sloupce a přenese všechna data v nekomprimované podobě. Pokud je formát komprese 5:1, dotaz zpracuje 6 TB, protože čte 1 TB a přenáší 5 TB nekomprimovaných dat.
Dotaz 4: VYBERTE POČET(*) Z very_small_csv
Tento dotaz čte celé soubory. Celková velikost souborů v úložišti pro tuto tabulku je 100 kB. Uzly zpracovávají fragmenty této tabulky a součet jednotlivých fragmentů se přenáší mezi uzly. Konečný součet se přenese do vašeho koncového bodu.
Tento dotaz zpracovává o něco více než 100 kB dat. Množství dat zpracovaných pro tento dotaz se zaokrouhlí nahoru na 10 MB, jak je uvedeno v části Zaokrouhlování tohoto článku.
Řízení nákladů
Funkce řízení nákladů v bezserverovém fondu SQL umožňuje nastavit rozpočet pro množství zpracovávaných dat. Rozpočet můžete nastavit v TB dat zpracovaných za den, týden nebo měsíc. Zároveň můžete mít nastavených více rozpočtů. Ke konfiguraci řízení nákladů pro bezserverový fond SQL můžete použít Synapse Studio nebo T-SQL.
Konfigurace řízení nákladů pro bezserverový fond SQL v Synapse Studio
Pokud chcete nakonfigurovat řízení nákladů pro bezserverový fond SQL v Synapse Studio v nabídce na levé straně přejděte na Spravovat položku a vyberte položku fondu SQL v části Fondy analýzy. Při najetí myší na bezserverový fond SQL si všimnete ikony pro řízení nákladů – klikněte na tuto ikonu.

Po kliknutí na ikonu řízení nákladů se zobrazí boční panel:
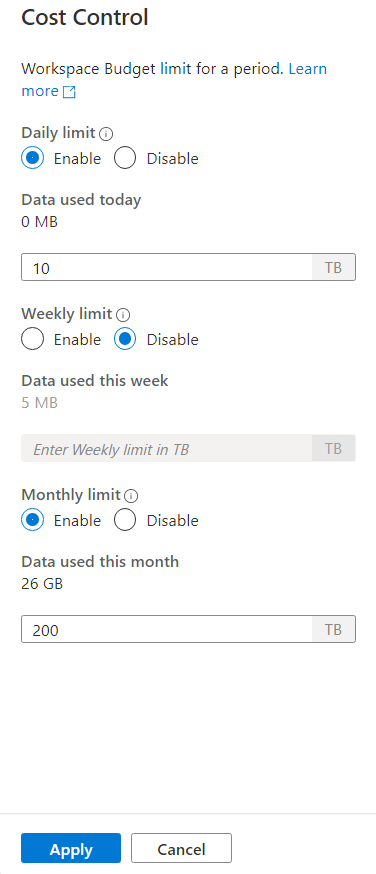
Pokud chcete nastavit jeden nebo více rozpočtů, klikněte nejprve na přepínač Povolit pro rozpočet, který chcete nastavit, a potom zadejte celočíselnou hodnotu do textového pole. Jednotkou pro hodnotu je TB. Po nakonfigurování požadovaných rozpočtů klikněte na tlačítko Použít v dolní části bočního panelu. To je vše, rozpočet je teď nastavený.
Konfigurace řízení nákladů pro bezserverový fond SQL v T-SQL
Pokud chcete nakonfigurovat řízení nákladů pro bezserverový fond SQL v T-SQL, musíte spustit jednu nebo více následujících uložených procedur.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Pokud chcete zobrazit aktuální konfiguraci, spusťte následující příkaz T-SQL:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Pokud chcete zjistit, kolik dat se zpracovalo během aktuálního dne, týdne nebo měsíce, spusťte následující příkaz T-SQL:
SELECT * FROM sys.dm_external_data_processed
Překročení limitů definovaných v řízení nákladů
V případě, že během provádění dotazu dojde k překročení jakéhokoli limitu, dotaz se neukončí.
Při překročení limitu se nový dotaz odmítne s chybovou zprávou, která obsahuje podrobnosti týkající se období, definovaného limitu pro toto období a dat zpracovaných pro toto období. Například v případě spuštění nového dotazu, kdy je týdenní limit nastavený na 1 TB a byl překročen, se zobrazí chybová zpráva:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Další kroky
Informace o optimalizaci dotazů z hlediska výkonu najdete v tématu Osvědčené postupy pro bezserverový fond SQL.