Používání externích tabulek se Synapse SQL
Externí tabulka odkazuje na data umístěná v Hadoopu, objektu blob služby Azure Storage nebo Azure Data Lake Storage. Pomocí externích tabulek můžete číst data ze souborů nebo zapisovat data do souborů ve službě Azure Storage.
Pomocí Synapse SQL můžete pomocí externích tabulek číst externí data pomocí vyhrazeného fondu SQL nebo bezserverového fondu SQL.
V závislosti na typu externího zdroje dat můžete použít dva typy externích tabulek:
- Externí tabulky Hadoop, které můžete použít ke čtení a exportu dat v různých datových formátech, jako jsou CSV, Parquet a ORC. Externí tabulky Hadoop jsou dostupné ve vyhrazených fondech SQL, ale nejsou dostupné v bezserverových fondech SQL.
- Nativní externí tabulky , které můžete použít ke čtení a exportu dat v různých datových formátech, jako jsou CSV a Parquet. Nativní externí tabulky jsou dostupné v bezserverových fondech SQL a jsou ve verzi Public Preview ve vyhrazených fondech SQL. Zápis a export dat pomocí CETAS a nativních externích tabulek je k dispozici pouze v bezserverovém fondu SQL, ale ne ve vyhrazených fondech SQL.
Hlavní rozdíly mezi Hadoopem a nativními externími tabulkami:
| Externí typ tabulky | Hadoop | Nativní |
|---|---|---|
| Vyhrazený fond SQL | Dostupné | Ve verzi Public Preview jsou dostupné jenom tabulky Parquet. |
| Bezserverový fond SQL | Není k dispozici | Dostupné |
| Podporované formáty | Oddělovač/CSV, Parquet, ORC, Hive RC a RC | Bezserverový fond SQL: Oddělovač/CSV, Parquet a Delta Lake Vyhrazený fond SQL: Parquet (Preview) |
| Odstranění oddílů složek | No | Odstranění oddílů je k dispozici pouze v dělených tabulkách vytvořených ve formátech Parquet nebo CSV, které se synchronizují z fondů Apache Sparku. U složek s oddíly Parquet můžete vytvářet externí tabulky, ale sloupce dělení jsou nepřístupné a ignorují se, zatímco odstranění oddílu se nepoužije. Nevytvávejte externí tabulky ve složkách Delta Lake, protože nejsou podporované. Pokud potřebujete dotazovat dělená data Delta Lake, použijte rozdílová rozdělená zobrazení . |
| Odstranění souborů (predikát pushdown) | No | Ano v bezserverovém fondu SQL. Pro odsdílení řetězců je potřeba použít Latin1_General_100_BIN2_UTF8 kolaci sloupců VARCHAR , abyste povolili odsdílení. Další informace o kolacích najdete v tématu Typy kolace podporované pro Synapse SQL. |
| Vlastní formát pro umístění | No | Ano, použití zástupných znaků jako /year=*/month=*/day=* pro formáty Parquet nebo CSV. Cesty k vlastním složkám nejsou v Delta Lake k dispozici. V bezserverovém fondu SQL můžete také pomocí rekurzivních zástupných /logs/** znaků odkazovat na soubory Parquet nebo CSV v jakékoli podsložce pod odkazovanou složkou. |
| Rekurzivní prohledávání složek | Ano | Ano. V bezserverových fondech SQL je nutné zadat /** na konci cesty k umístění. Ve vyhrazeném fondu se složky vždy rekurzivně naskenují. |
| Ověřování úložiště | Přístupový klíč úložiště (SAK), předávání Microsoft Entra, spravovaná identita, vlastní identita aplikace Microsoft Entra | Shared Access Signature(SAS), Microsoft Entra passthrough, Managed Identity, Custom application Microsoft Entra identity. |
| Mapování sloupců | Řadový – sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle pozice. | Bezserverový fond: podle názvu. Sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle odpovídajících názvů sloupců. Vyhrazený fond: pořadové porovnávání. Sloupce v definici externí tabulky jsou mapovány na sloupce v podkladových souborech Parquet podle pozice. |
| CETAS (export/transformace) | Ano | CETAS s nativními tabulkami jako cílem funguje pouze v bezserverovém fondu SQL. Vyhrazené fondy SQL nelze použít k exportu dat pomocí nativních tabulek. |
Poznámka:
Nativní externí tabulky jsou doporučeným řešením ve fondech, kde jsou obecně dostupné. Pokud potřebujete přistupovat k externím datům, vždy používejte nativní tabulky v bezserverových fondech. Ve vyhrazených fondech byste měli přepnout na nativní tabulky pro čtení souborů Parquet, jakmile jsou v ga. Tabulky Hadoop použijte pouze v případě, že potřebujete získat přístup k některým typům, které nejsou podporovány v nativních externích tabulkách (například ORC, RC) nebo pokud nativní verze není dostupná.
Externí tabulky ve vyhrazeném fondu SQL a bezserverovém fondu SQL
Externí tabulky můžete použít k:
- Dotazování služby Azure Blob Storage a Azure Data Lake Gen2 pomocí příkazů jazyka Transact-SQL
- Výsledky dotazů můžete ukládat do souborů ve službě Azure Blob Storage nebo Azure Data Lake Storage pomocí CETAS.
- Importujte data ze služby Azure Blob Storage a Azure Data Lake Storage a uložte je do vyhrazeného fondu SQL (pouze tabulky Hadoop ve vyhrazeném fondu).
Poznámka:
Pokud se používá ve spojení s příkazem CREATE TABLE AS SELECT, výběr z externí tabulky importuje data do tabulky v rámci vyhrazenéhofondu SQL.
Pokud výkon externích tabulek Hadoop ve vyhrazených fondech nevyhovuje vašim cílům výkonu, zvažte načtení externích dat do tabulek Datawarehouse pomocí příkazu COPY.
Kurz načítání najdete v tématu Použití PolyBase k načtení dat ze služby Azure Blob Storage.
Externí tabulky ve fondech Synapse SQL můžete vytvořit pomocí následujících kroků:
- CREATE EXTERNAL DATA SOURCE to reference an external Azure Storage and specify the credential that be used to access the storage.
- CREATE EXTERNAL FILE FORMAT to describe format of CSV or Parquet files.
- CREATE EXTERNAL TABLE nad soubory umístěné ve zdroji dat se stejným formátem souboru.
Odstranění oddílů složek
Nativní externí tabulky ve fondech Synapse můžou ignorovat soubory umístěné ve složkách, které nejsou pro dotazy relevantní. Pokud jsou vaše soubory uložené v hierarchii složek (například - /year=2020/month=03/day=16) a hodnoty pro yearmonth, a day jsou zpřístupněny jako sloupce, dotazy obsahující filtry, jako year=2020 jsou, budou číst soubory pouze z podsložek umístěných ve year=2020 složce. Soubory a složky umístěné v jiných složkách (year=2021 nebo year=2022) budou v tomto dotazu ignorovány. Tato eliminace se označuje jako odstranění oddílu.
Odstranění oddílů složek je k dispozici v nativních externích tabulkách, které jsou synchronizovány z fondů Synapse Spark. Pokud máte dělenou datovou sadu a chcete využít odstranění oddílů s externími tabulkami, které vytvoříte, použijte místo externích tabulek rozdělená zobrazení .
Odstranění souboru
Některé formáty dat, jako jsou Parquet a Delta, obsahují statistiky souborů pro každý sloupec (například minimální/maximální hodnoty pro každý sloupec). Dotazy, které filtrují data, nebudou číst soubory, ve kterých neexistují požadované hodnoty sloupců. Dotaz nejprve prozkoumá minimální a maximální hodnoty sloupců použitých v predikátu dotazu k vyhledání souborů, které neobsahují požadovaná data. Tyto soubory budou ignorovány a eliminovány z plánu dotazu.
Tato technika se také označuje jako posun predikátu filtru a může zlepšit výkon dotazů. Odsdílení filtru je k dispozici v bezserverových fondech SQL ve formátech Parquet a Delta. Chcete-li využít odsdílení filtru pro typy řetězců, použijte typ VARCHAR s Latin1_General_100_BIN2_UTF8 kolací. Další informace o kolacích najdete v tématu Typy kolace podporované pro Synapse SQL.
Zabezpečení
Uživatel musí mít SELECT oprávnění k externí tabulce ke čtení dat.
K externím tabulkám se přistupuje k podkladovému úložišti Azure pomocí přihlašovacích údajů s vymezeným oborem databáze definovaných ve zdroji dat pomocí následujících pravidel:
- Zdroj dat bez přihlašovacích údajů umožňuje externím tabulkám přístup k veřejně dostupným souborům v úložišti Azure.
- Zdroj dat může mít přihlašovací údaje, které umožňují externím tabulkám přistupovat pouze k souborům v úložišti Azure pomocí tokenu SAS nebo spravované identity pracovního prostoru . Příklady najdete v článku Vývoj souborů úložiště pro řízení přístupu.
Příklad pro VYTVOŘENÍ EXTERNÍHO ZDROJE DAT
Následující příklad vytvoří externí zdroj dat Hadoop ve vyhrazeném fondu SQL pro Azure Data Lake Gen2 odkazující na sadu dat v New Yorku:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Následující příklad vytvoří externí zdroj dat pro Azure Data Lake Gen2 odkazující na veřejně dostupnou sadu dat New Yorku:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Příklad pro CREATE EXTERNAL FILE FORMAT
Následující příklad vytvoří formát externího souboru pro soubory sčítání lidu:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Příklad CREATE EXTERNAL TABLE
Následující příklad vytvoří externí tabulku. Vrátí první řádek:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Vytvoření a dotazování externích tabulek ze souboru v Azure Data Lake
Pomocí možností zkoumání Data Lake v nástroji Synapse Studio teď můžete vytvořit a dotazovat externí tabulku pomocí fondu Synapse SQL jednoduchým kliknutím pravým tlačítkem myši na soubor. Gesto jedním kliknutím pro vytvoření externích tabulek z účtu úložiště ADLS Gen2 je podporováno pouze pro soubory Parquet.
Předpoklady
Musíte mít přístup k pracovnímu prostoru s alespoň
Storage Blob Data Contributorrolí přístupu k účtu ADLS Gen2 nebo seznamům řízení přístupu (ACL), které umožňují dotazovat se na soubory.K vytvoření externí tabulky a dotazování externích tabulek ve fondu Synapse SQL (vyhrazeném nebo bez serveru) musíte mít alespoň oprávnění.
Na panelu Data vyberte soubor, ze kterého chcete vytvořit externí tabulku:
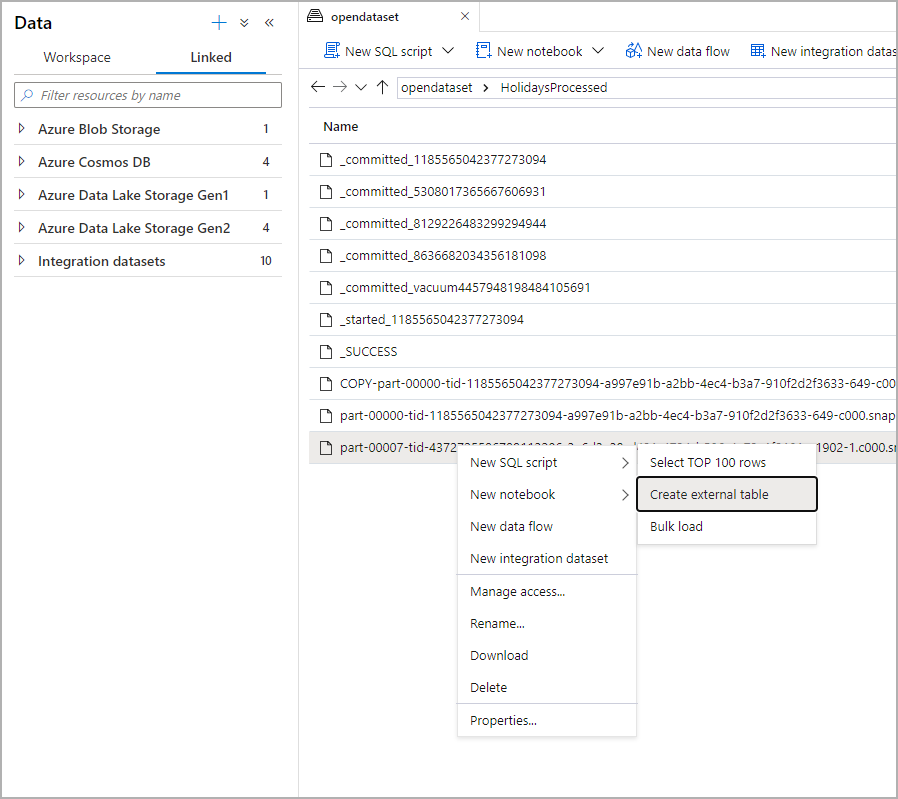
Otevře se dialogové okno. Vyberte vyhrazený fond SQL nebo bezserverový fond SQL, pojmenujte tabulku a vyberte otevřený skript:

Skript SQL je automaticky vygenerován odvození schématu ze souboru:
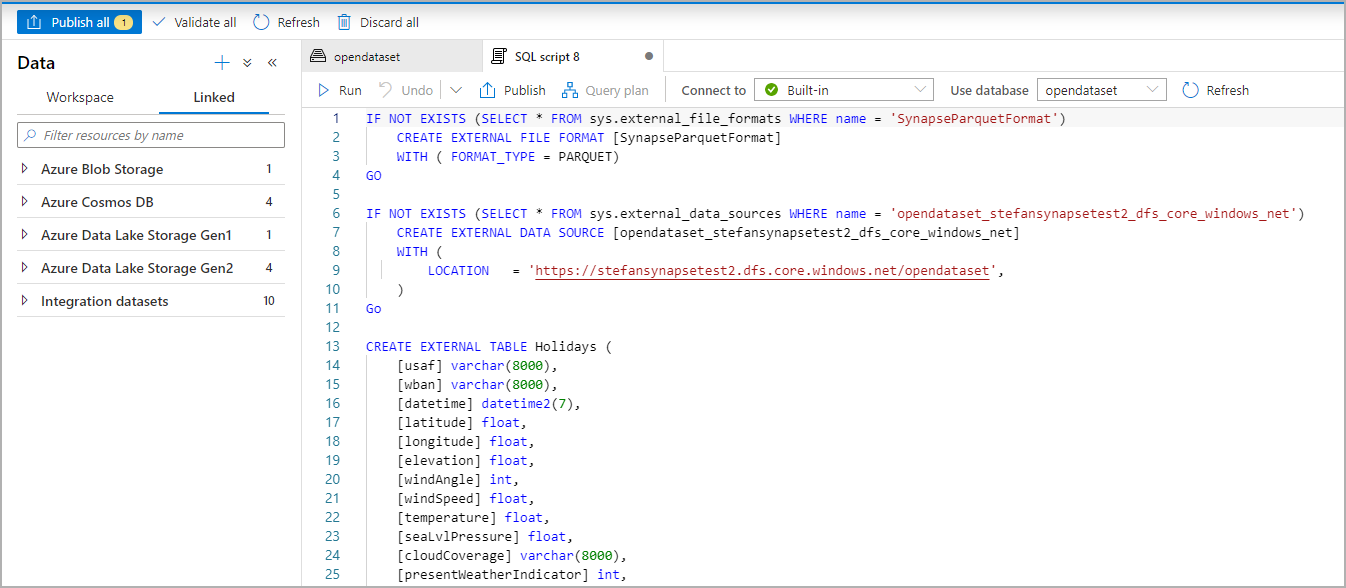
Spusťte skript. Skript automaticky spustí výběr top 100 *.:

Externí tabulka je teď vytvořená pro budoucí zkoumání obsahu této externí tabulky, na kterou se uživatel může dotazovat přímo z podokna Data:
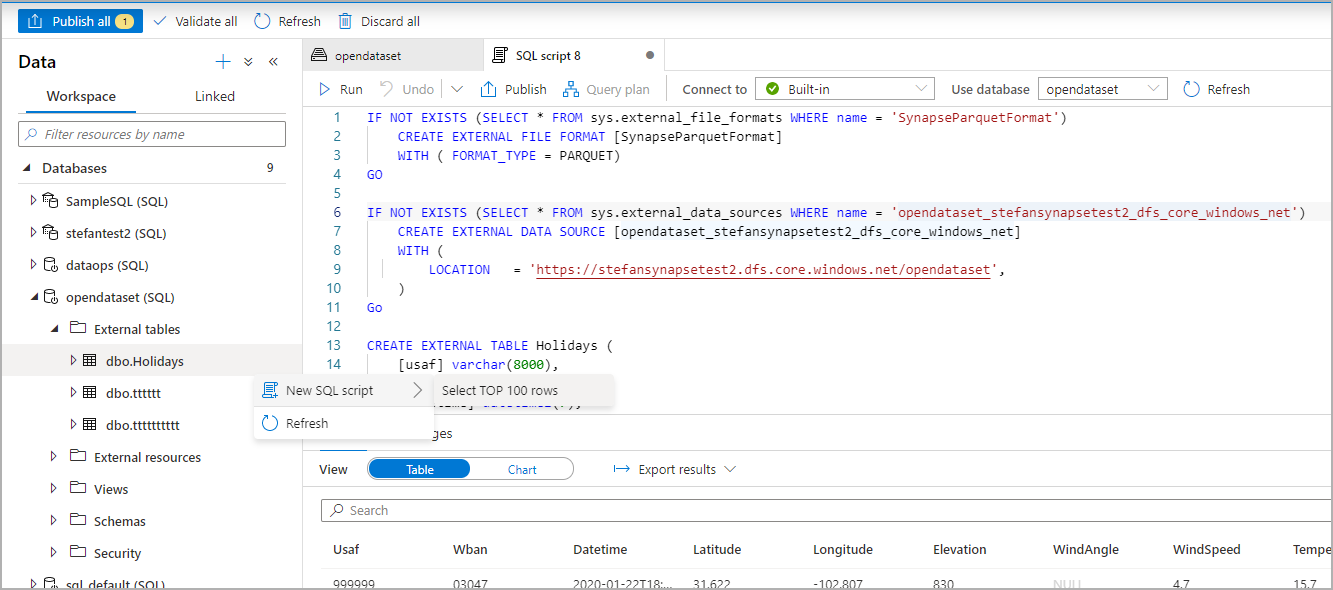
Další kroky
Informace o ukládání výsledků dotazů do externí tabulky ve službě Azure Storage najdete v článku CETAS. Nebo můžete začít dotazovat Apache Spark pro externí tabulky Azure Synapse.