Velikosti virtuálních počítačů řady HBv2
Platí pro: ✔️ Virtuální počítače s Windows s Linuxem ✔️ ✔️ – Flexibilní škálovací sady Uniform Scale Sets ✔️
Na virtuálních počítačích s velikostí HBv2-series bylo spuštěno několik testů výkonu. Následuje několik výsledků tohoto testování výkonnosti.
| Úloha | HBv2 |
|---|---|
| STREAM Triad | 350 GB/s (21–23 GB/s na CCX) |
| Vysoce výkonný Linpack (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| Latence RDMA a šířka pásma | 1,2 mikrosekundy, 190 Gb/s |
| FIO na místním disku NVMe SSD | 2,7 GB/s čtení, 1,1 GB/s zápisy; 102k IOPS čtení, 115 zápisů IOPS |
| IOR na 8 * Azure Premium SSD (P40 Spravované disky, RAID0)** | 1,3 GB/s čtení, 2,5 GB/zápis; Čtení 101k IOPS, 105k IOPS zápisy |
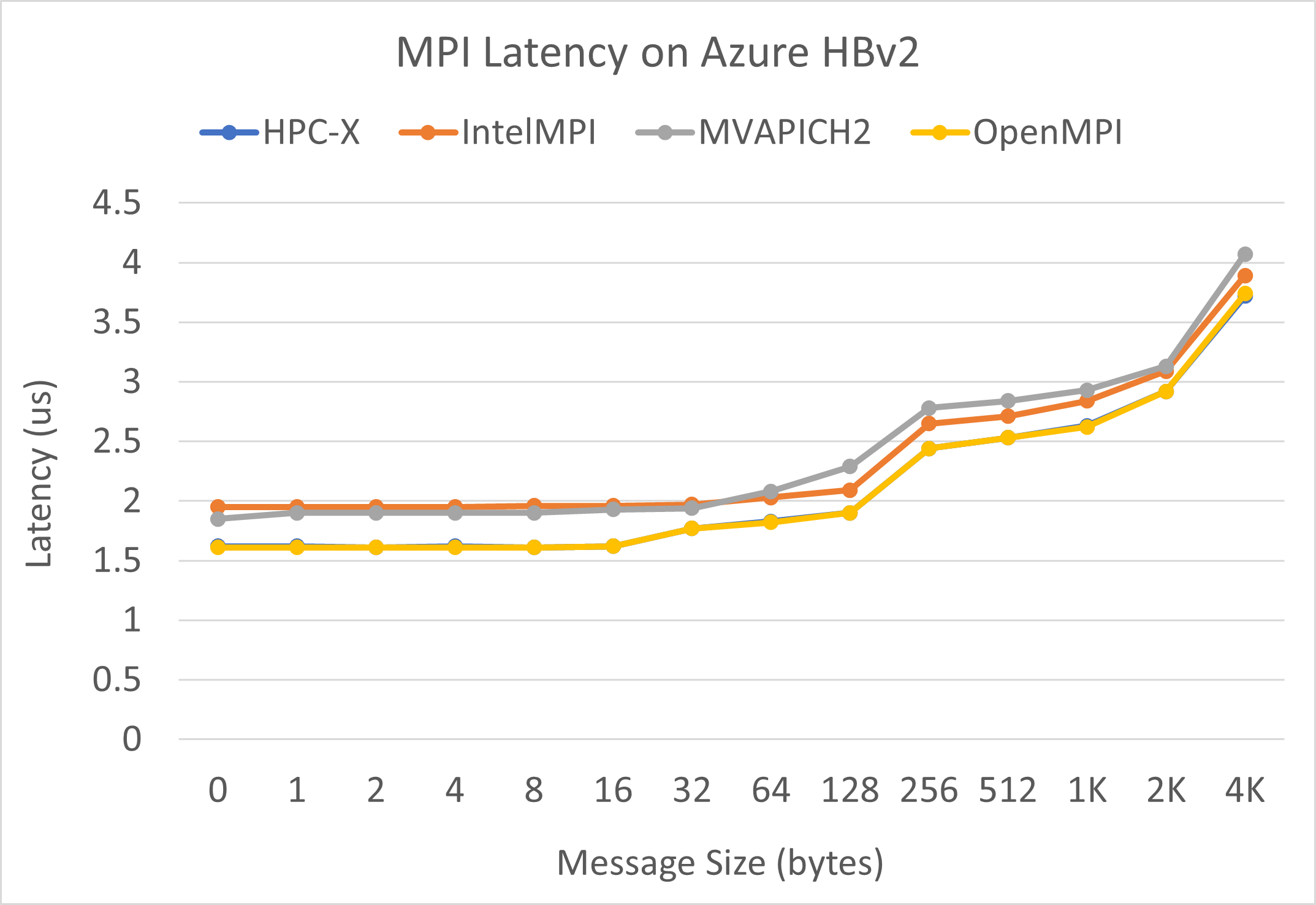
Latence MPI
Spustí se test latence MPI ze sady mikrobenchmarků OSU. Ukázkové skripty jsou na GitHubu.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
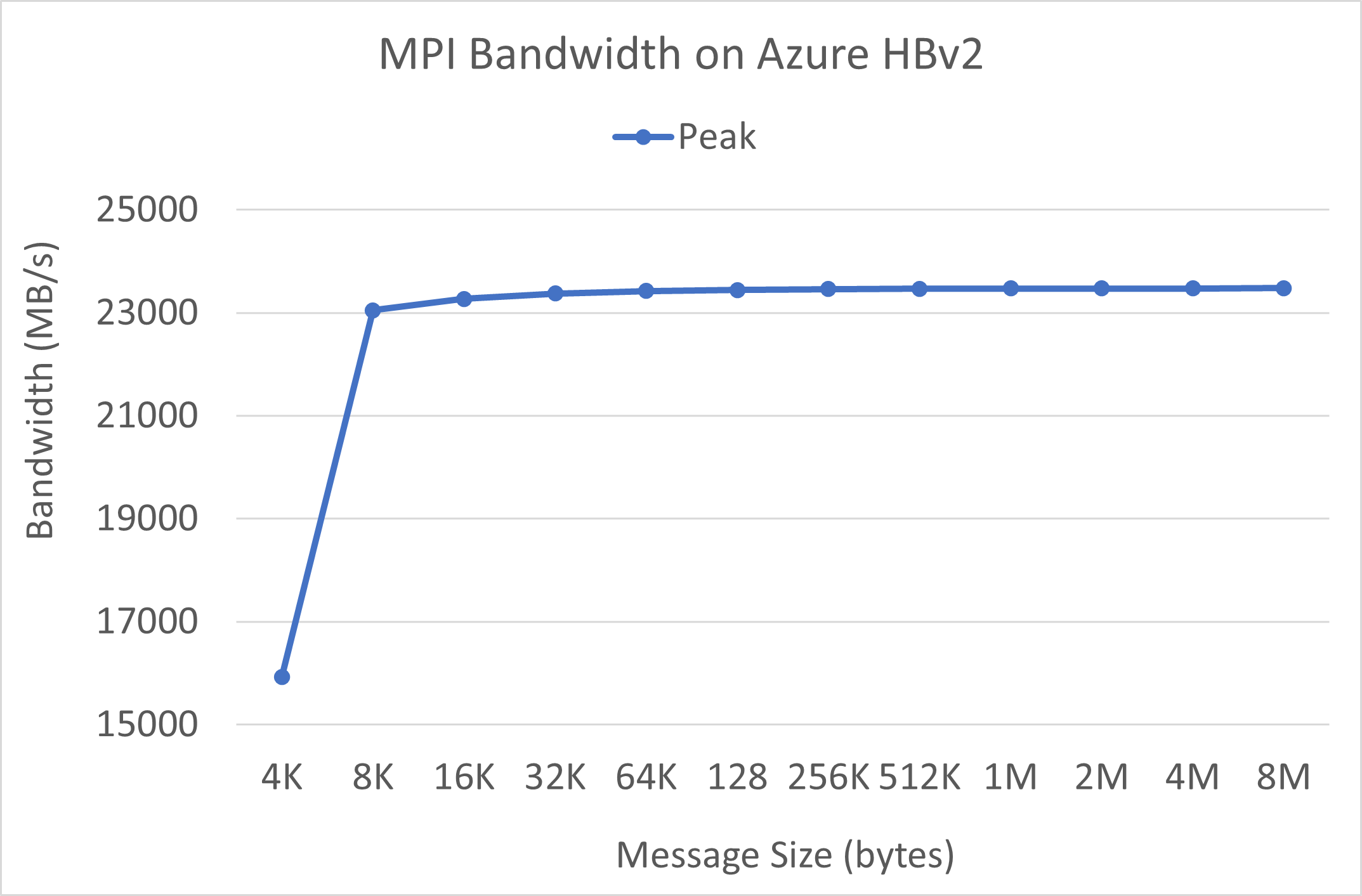
Šířka pásma MPI
Spustí se test šířky pásma MPI ze sady mikrobenchmarkŮ OSU. Ukázkové skripty jsou na GitHubu.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
Balíček Mellanox Perftest má mnoho testů InfiniBand, jako je latence (ib_send_lat) a šířka pásma (ib_send_bw). Příklad příkazu je uvedený níže.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Další kroky
- Přečtěte si o nejnovějších oznámeních, příkladech úloh PROSTŘEDÍ HPC a výsledcích výkonu na blogech technické komunity Azure Compute.
- Přehled architektury vyšší úrovně spouštění úloh PROSTŘEDÍ HPC najdete v tématu Vysokovýkonné výpočetní prostředí (HPC) v Azure.