Dostupnost SAP HANA napříč oblastmi Azure
Tento článek popisuje scénáře související s dostupností SAP HANA v různých oblastech Azure. Vzhledem k vzdálenosti mezi oblastmi Azure zahrnuje nastavení dostupnosti SAP HANA ve více oblastech Azure zvláštní aspekty.
Proč nasazovat napříč několika oblastmi Azure
Oblasti Azure jsou často oddělené velkými vzdálenostmi. V závislosti na geopolitické oblasti může být vzdálenost mezi oblastmi Azure stovky kilometrů nebo dokonce několik tisíc kilometrů, jako je v USA. Kvůli vzdálenosti dochází k významné latenci odezvy sítě mezi prostředky nasazenými ve dvou různých oblastech Azure. Latence je dostatečně důležitá, aby se vyloučila synchronní výměna dat mezi dvěma instancemi SAP HANA v rámci typických úloh SAP.
Na druhou stranu organizace často mají požadavky na vzdálenost mezi umístěním primárního datacentra a sekundárním datacentrem. Požadavek na vzdálenost pomáhá zajistit dostupnost, pokud dojde k přírodní katastrofě v širší geografické lokalitě. Příkladem jsou hurikány, které v září a říjnu 2017 zasáhly Karibskou oblast a Floridu. Vaše organizace může mít alespoň minimální požadavek na vzdálenost. Pro většinu zákazníků Azure vyžaduje definice minimální vzdálenosti, abyste navrhli dostupnost napříč oblastmi Azure. Vzhledem k tomu, že vzdálenost mezi dvěma oblastmi Azure je příliš velká, aby bylo možné použít synchronní režim replikace HANA, můžou vás požadavky na RTO a RPO vynutit nasazení konfigurací dostupnosti v jedné oblasti a pak doplnit další nasazení v druhé oblasti.
Dalším aspektem, který je potřeba vzít v úvahu v tomto scénáři, je převzetí služeb při selhání a přesměrování klienta. Předpokladem je, že převzetí služeb při selhání mezi instancemi SAP HANA ve dvou různých oblastech Azure je vždy ruční převzetí služeb při selhání. Vzhledem k tomu, že režim replikace systému SAP HANA je nastavený na asynchronní, existuje potenciál, že data potvrzená v primární instanci HANA ještě nepřišla do sekundární instance HANA. Proto automatické převzetí služeb při selhání není možností pro konfigurace, kde je replikace asynchronní. I v případě ručně řízeného převzetí služeb při selhání musíte přijmout opatření k zajištění toho, aby se všechna potvrzená data na primární straně přesunula do sekundární instance, než se ručně přesunete do druhé oblasti Azure.
Azure Virtual Network používá jiný rozsah IP adres. IP adresy se nasadí ve druhé oblasti Azure. Proto je potřeba změnit konfiguraci klienta SAP HANA, nebo pokud možno, musíte vytvořit kroky pro změnu překladu ip adres. Klienti se tak přesměrují na IP adresu serveru nové sekundární lokality. Další informace najdete v článku O obnovení připojení klienta po převzetí.
Jednoduchá dostupnost mezi dvěma oblastmi Azure
Můžete se rozhodnout, že konfiguraci dostupnosti neuložíte do jedné oblasti, ale přesto budete chtít, aby úloha byla obsluhována, pokud dojde k havárii. Typické případy takových scénářů jsou neprodukční systémy. I když je systém po dobu půl dne nebo dokonce i den udržitelný, nemůžete povolit, aby byl systém nedostupný po dobu 48 hodin nebo déle. Pokud chcete nastavit méně nákladné, spusťte na virtuálním počítači jiný systém, který je ještě méně důležitý. Druhý systém funguje jako cíl. Můžete také velikost virtuálního počítače v sekundární oblasti zmenšit a zvolit, aby se data předem nenačítá. Vzhledem k tomu, že převzetí služeb při selhání je ruční a zahrnuje mnoho dalších kroků pro převzetí služeb při selhání kompletního zásobníku aplikací, další čas vypnutí virtuálního počítače, jeho změna velikosti a následné restartování virtuálního počítače je přijatelná.
Pokud používáte scénář sdílení cíle zotavení po havárii se systémem pro kontrolu kvality na jednom virtuálním počítači, musíte vzít v úvahu tyto aspekty:
- Existují dva režimy operací s delta_datashipping a logreplay, které jsou k dispozici pro takový scénář.
- Oba režimy operací mají různé požadavky na paměť bez předběžného načtení dat.
- Delta_datashipping může vyžadovat výrazně méně paměti bez možnosti předběžného načtení, než by mohlo vyžadovat protokolování. Viz kapitola 4.3 dokumentu SAP How To Perform System Replication for SAP HANA
- Požadavek na paměť režimu operace logreplay bez předběžného načtení není deterministický a závisí na načtených strukturách columnstore. V extrémních případech můžete vyžadovat 50 % paměti primární instance. Paměť pro režim operace logreplay je nezávislá na tom, jestli jste se rozhodli mít předem načtená data, nebo ne.
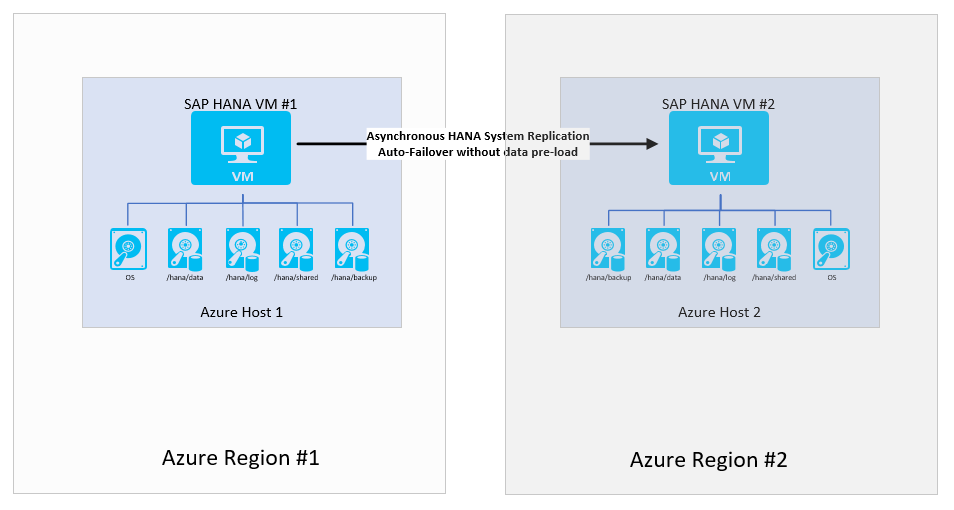
Poznámka:
V této konfiguraci nemůžete zadat RPO=0, protože režim replikace systému HANA je asynchronní. Pokud potřebujete zadat RPO=0, tato konfigurace není zvolená konfigurace.
Malou změnou, kterou můžete v konfiguraci provést, může být konfigurace dat před načtením. Vzhledem k ruční povaze převzetí služeb při selhání a skutečnosti, že vrstvy aplikace musí také přejít do druhé oblasti, nemusí mít smysl předem načíst data.
Kombinování dostupnosti v rámci jedné oblasti a napříč oblastmi
Kombinace dostupnosti v rámci oblastí a napříč oblastmi může být řízena těmito faktory:
- Požadavek RPO=0 v rámci oblasti Azure
- Organizace není ochotná ani nemůže mít globální operace ovlivněné velkou přírodní katastrofou, která ovlivňuje větší oblast. To byl případ některých hurikánů, které v posledních několika letech zasáhly Karibskou oblast.
- Předpisy, které vyžadují vzdálenosti mezi primárními a sekundárními lokalitami, které jsou jasně nad rámec toho, co zóny dostupnosti Azure mohou poskytovat.
V těchto případech můžete nastavit, co SAP volá vícevrstvé konfiguraci replikace systému SAP HANA pomocí systémové replikace HANA. Architektura by vypadala takto:
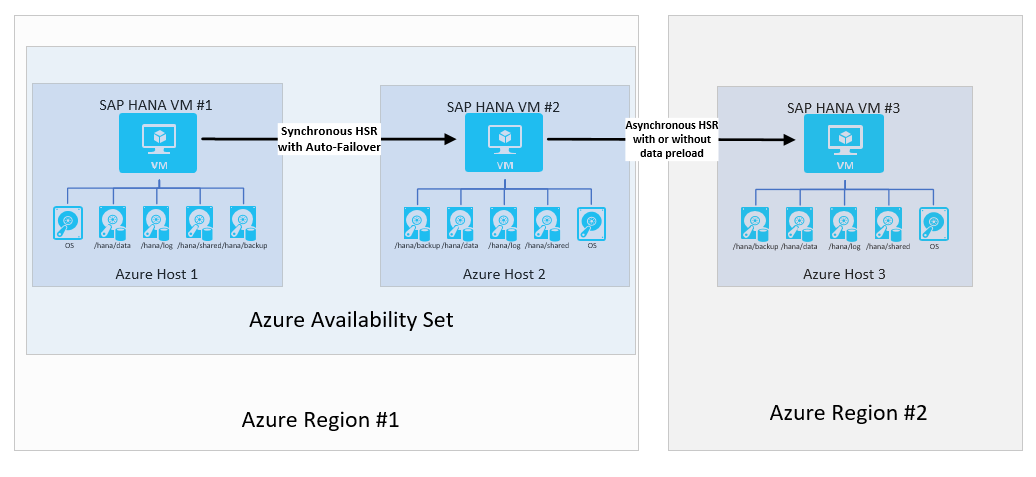
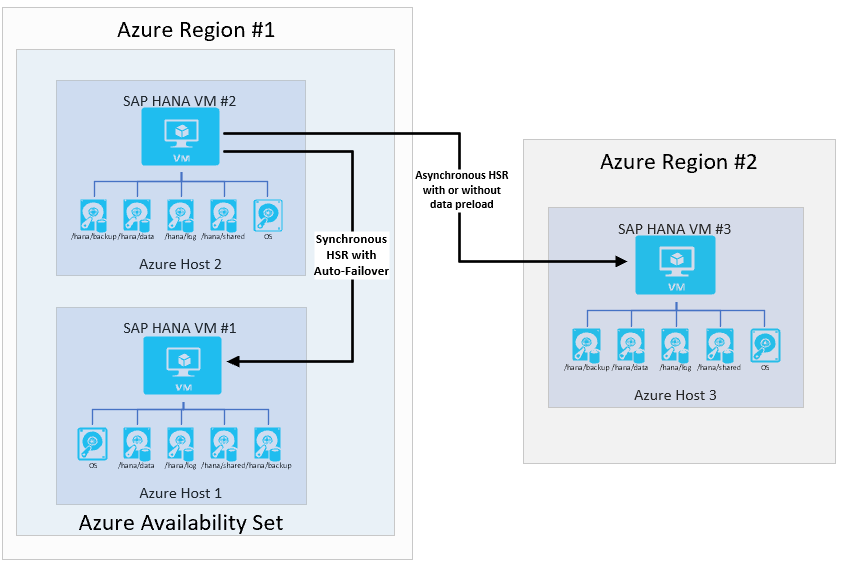
SAP zavedl replikaci systému s více cíli s HANA 2.0 SPS3. Replikace systému s více cíli přináší určité výhody ve scénářích aktualizací. Například lokalita zotavení po havárii (Oblast 2) nemá vliv, když sekundární lokalita vysoké dostupnosti přestane být v případě údržby nebo aktualizací. Další informace o replikaci systému s více cíli HANA najdete na portálu nápovědy SAP. Možná architektura s replikací s více cíli by vypadala takto:
Pokud má organizace požadavky na připravenost na vysokou dostupnost v druhé oblasti Azure (DR), architektura by vypadala takto:
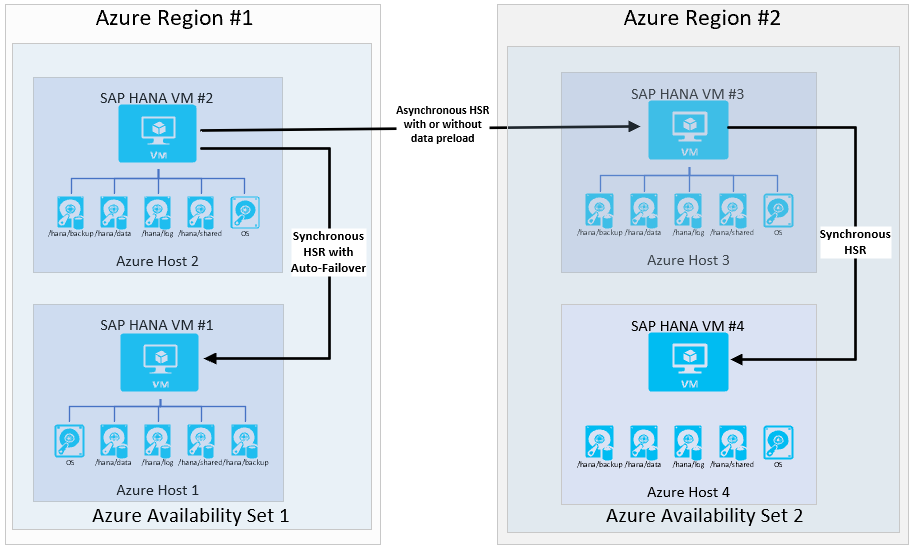
Při použití logreplay jako provozního režimu tato konfigurace poskytuje cíl bodu obnovení (RPO= 0) s nízkou rto v primární oblasti. Konfigurace také poskytuje slušný cíl bodu obnovení, pokud se jedná o přesun do druhé oblasti. Časy RTO ve druhé oblasti závisí na tom, jestli se data předem načtou. Řada zákazníků používá virtuální počítač v sekundární oblasti ke spuštění testovacího systému. V takovém případě není možné data předem načíst.
Důležité
Režimy operací mezi různými úrovněmi musí být homogenní. Logreplay nemůžete použít jako provozní režim mezi vrstvou 1 a vrstvou 2 a delta_datashipping k poskytování vrstvy 3. Můžete zvolit jenom jeden nebo druhý režim operace, který musí být konzistentní pro všechny úrovně. Vzhledem k tomu, že delta_datashipping není vhodný k poskytnutí cíle bodu obnovení (RPO=0), zůstává jediný rozumný provozní režim pro takovou konfiguraci s více vrstvami stále v protokolu. Podrobnosti o režimech operací a některých omezeních najdete v článku Provozní režimy SAP pro replikaci systému SAP HANA.
Další kroky
Podrobné pokyny k nastavení těchto konfigurací v Azure najdete tady: