Několik grafických procesorů a počítačů
1. Úvod
CNTK aktuálně podporuje čtyři paralelní algoritmy SGD:
Požadavky
Pokud chcete spustit paralelní trénování, ujistěte se, že je nainstalovaná implementace rozhraní MPI (Message Passing Interface):
Ve Windows nainstalujte z této stránky ke stažení verzi 7 (7.0.12437.6) rozhraní MICROSOFT MPI (MS-MPI), což je implementace standardu Rozhraní pro předávání zpráv z této stránky, která je v názvu stránky označena jednoduše jako verze 7. Klikněte na tlačítko Stáhnout a pak vyberte čas spuštění (
MSMpiSetup.exe).V Linuxu nainstalujte OpenMPI verze 1.10.x. Postupujte podle zde uvedených pokynů a sestavte si ho sami.
2. Konfigurace paralelního trénování v CNTK v Pythonu
Aby uživatel v Pythonu používal paralelní SGD dat, musí pro trenéra vytvořit a předat mu distribuovanou výuku:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Pro uživatelem definovanou trénovací smyčku (místo training_session) musí uživatelé předat num_data_partitions a metodu MinibatchSource.next_minibatch() tak, aby různé uzly MPI načítaly data z různých datových oddílů (po distributed_afterpartition_index přečtení ukázek).
Upozorňujeme, že by se mělo volat pouze v případě, že Communicator.finalize() se distribuované trénování úspěšně dokončilo. V případě selhání distribuovaného pracovního procesu by tato metoda neměla být volána.
Úplný funkční příklad najdete v příkladu ConvNet.
3. Konfigurace paralelního trénování v CNTK v BrainScriptu
Pokud chcete povolit paralelní trénování v CNTK BrainScriptu, je nejprve nutné zapnout následující přepínač v konfiguračním souboru nebo v příkazovém řádku:
parallelTrain = true
Za druhé by SGD blok v konfiguračním souboru měl obsahovat dílčí blok s názvem ParallelTrain s následujícími argumenty:
parallelizationMethod: (povinné) legitimní hodnoty jsouDataParallelSGD,BlockMomentumSGDaModelAveragingSGD.Určuje, který paralelní algoritmus se má použít.
distributedMBReading: (volitelné) přijímá logickou hodnotu:truenebofalse; výchozí hodnota jefalseDoporučujeme zapnout distribuované čtení minibatchu, aby se minimalizovaly náklady na vstupně-výstupní operace v každém pracovním procesu. Pokud používáte čtečku textového formátu CNTK, čtečku obrázků nebo čtečku složených dat, měla by být distribuovaná funkce MBReading nastavená na hodnotu true.
parallelizationStartEpoch: (volitelné) přijímá celočíselnou hodnotu; výchozí hodnota je 1.Určuje, od jaké epochy se používají paralelní trénovací algoritmy; před tím, než všichni pracovníci, kteří provádějí stejné školení, ale pouze jeden pracovník může model uložit. Tato možnost může být užitečná, pokud paralelní trénování vyžaduje nějakou fázi "teplého zahájení".
syncPerfStats: (volitelné) přijímá celočíselnou hodnotu; výchozí hodnota je 0.Určuje, jak často se budou tisknout statistiky výkonu. Tyto statistiky zahrnují čas strávený komunikací a/nebo výpočty v synchronizačním období, který může být užitečný k pochopení kritických bodů paralelních trénovacích algoritmů.
0 znamená, že se nevytisknou žádné statistiky. Další hodnoty určují, jak často se budou statistiky tisknout. Například znamená,
syncPerfStats=5že se statistika vytiskne po každé 5 synchronizacích.Dílčí blok, který určuje podrobnosti jednotlivých paralelních trénovacích algoritmů. Název dílčího bloku by měl být roven
parallelizationMethod. (povinné)
Python poskytuje větší flexibilitu a využití jsou uvedeny níže pro různé metody paralelizace.
4. Spuštění paralelního trénování pomocí CNTK
Paralelizace v CNTK se implementuje pomocí MPI.
4.1 Spuštění paralelního trénování pomocí BrainScriptu
Pokud máte některou z výše uvedených konfigurací BrainScriptu s paralelním trénováním, můžete k zahájení paralelní úlohy MPI použít následující příkazy:
Paralelní trénování na stejném počítači s Linuxem:
mpiexec --npernode $num_workers $cntk configFile=$configParalelní trénování na stejném počítači s Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Paralelní trénování napříč několika výpočetními uzly s Linuxem:
Krok 1: Vytvoření hostitelského souboru $hostfile pomocí oblíbeného editoru
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Kde name_of_node(n) je jednoduše název DNS nebo IP adresa pracovního uzlu.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Paralelní trénování napříč několika výpočetními uzly s Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
kde $cntk by měl odkazovat na cestu spustitelného souboru CNTK ($x je způsob nahrazení proměnných prostředí Linuxu, ekvivalent v %x% prostředí Windows).
4.2 Spuštění paralelního trénování v Pythonu
Příklady distribuovaného trénování pro CNTK v2 s Pythonem najdete tady:
Vzhledem k skriptu training.py PYTHONu CNTK v2 je možné použít následující příkazy ke spuštění paralelní úlohy MPI:
Paralelní trénování na stejném počítači s Linuxem:
mpiexec --npernode $num_workers python training.pyParalelní trénování na stejném počítači s Windows:
mpiexec -n %num_workers% python training.pyParalelní trénování napříč několika výpočetními uzly s Linuxem:
Krok 1: Vytvoření hostitelského souboru $hostfile pomocí oblíbeného editoru
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Kde name_of_node(n) je jednoduše název DNS nebo IP adresa pracovního uzlu.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Paralelní trénování napříč několika výpočetními uzly s Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel školení s 1bitovou sadou SGD
CNTK implementuje 1bitovou techniku SGD [1]. Tato technika umožňuje distribuovat jednotlivé minibatchy přes K pracovní procesy. Výsledné částečné přechody se pak vyměňují a agregují po každém minibatchu. "1 bit" odkazuje na techniku vyvinutou v Microsoftu pro snížení množství dat, která se vyměňují za každou hodnotu přechodu na jeden bit.
5.1 Algoritmus "1bitový SGD"
Přímá výměna částečných přechodů po každém minibatchu vyžaduje zakázat šířku pásma komunikace. Aby se to vyřešilo, 1bitová SGD agresivně kvantizuje každou hodnotu přechodu... na jednu bitovou hodnotu (!). Prakticky to znamená, že velké přechodové hodnoty jsou oříznuté, zatímco malé hodnoty jsou uměle nafukovány. Úžasně, to neškodí konvergenci, pokud a pouze v případě, že se používá trik .
Trik spočívá v tom, že u každého minibatchu algoritmus porovnává kvantované přechody (které se vyměňují mezi pracovními procesy) s původními hodnotami přechodu (které by měly být vyměňovány). Rozdíl mezi těmito dvěma hodnotami ( chybou kvantizace) se vypočítá a zapamatuje se jako reziduí. Tato rezidua se pak přidá k dalšímu minibatchu.
V důsledku toho se i přes agresivní kvantizaci každá hodnota přechodu nakonec vymění s plnou přesností; jen se zpožděním. Experimenty ukazují, že pokud je tento model kombinován s teplým startem (počáteční model natrénovaný na malé podmnožině trénovacích dat bez paralelizace), ukázala se tato technika vést k žádné nebo velmi malé ztrátě přesnosti a zároveň umožňuje příliš daleko od lineárního (limitující faktor, že GPU se při výpočtu příliš malých dílčích dávek stávají neefektivními).
Pro maximální efektivitu by se technika měla kombinovat s automatickým škálováním minibatchu, kde se vždy a pak trenér snaží zvětšit velikost minibatchu. Při vyhodnocování malé podmnožině nadcházející epochy dat vybere trenér největší velikost minibatchu, která neškodí konvergenci. V tomto případě je užitečné, že CNTK určuje rychlost učení a hyperparametry dynamiky minibatch-size agnostic.
5.2 Použití 1bitového SGD v BrainScriptu
1bitová sada SGD nemá žádný jiný parametr než jeho povolení a po kterém by měla být zahájena epocha. Kromě toho by mělo být povolené automatické škálování minibatchu. Tyto parametry se konfigurují přidáním následujících parametrů do bloku SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Všimněte si, že Data-Parallel SGD lze použít také bez 1bitové kvantizace. V typických scénářích ale zejména scénáře, ve kterých se každý parametr modelu použije jen jednou jako u DNN pro předávání informačního kanálu, to nebude efektivní z důvodu požadavků na velkou šířku pásma komunikace.
Část 2.2.3 níže ukazuje výsledky 1bitového SGD na úlohu řeči, ve srovnání s metodou Block-Momentum SGD, která je popsána dále. Obě metody nemají téměř žádnou ztrátu přesnosti při téměř lineární rychlosti.
5.3 Použití 1bitového SGD v Pythonu
Pokud chcete používat paralelní SGD dat v Pythonu, volitelně s 1bitovou sadou SGD, musí uživatel vytvořit a předat distribuovanému učení trenérovi:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Změna num_quantization_bits na 32 při vytváření distributed_learner používá nevantizované Data-Parallel SGD. V tomto případě není potřeba zahřátý start.
6 Block-Momentum SGD
Block-Momentum SGD je implementace "aktualizace a filtrování modelů", neboli BMUF, algoritmus, krátká bloková dynamika [2].
6.1 Algoritmus Block-Momentum SGD
Následující obrázek shrnuje postup v algoritmu Block-Momentum.

6.2 Konfigurace Block-Momentum SGD v BrainScriptu
Pokud chcete použít Block-Momentum SGD, je nutné mít v bloku podblok BlockMomentumSGDSGD s následujícími možnostmi:
syncPeriod. To se podobásyncPeriodinModelAveragingSGD, což určuje, jak často se provádí synchronizace modelu. Výchozí hodnota jeBlockMomentumSGD120 000.resetSGDMomentum. To znamená, že po každém bodu synchronizace bude plynulý přechod použitý v místní sadě SGD nastaven na hodnotu 0. Výchozí hodnota této proměnné je true.useNesterovMomentum. To znamená, že aktualizace dynamiky ve stylu Nesterov se použije na úrovni bloku. Další podrobnosti najdete v článku [2]. Výchozí hodnota této proměnné je true.
Bloková rychlost a míra blokového učení se obvykle nastavuje automaticky podle počtu použitých pracovníků, tj.
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Naše zkušenosti ukazují, že tato nastavení často přinášejí podobné konvergenční funkce jako standardní algoritmus SGD až do 64 GPU, což je největší experiment, který jsme provedli. Tyto parametry je také možné zadat ručně pomocí následujících možností:
blockMomentumAsTimeConstanturčuje časovou konstantu filtru nízkého průchodu v aktualizaci modelu na úrovni bloku. Vypočítá se takto:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateurčuje míru blokového učení.
Následuje příklad oddílu konfigurace Block-Momentum SGD:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Použití Block-Momentum SGD v BrainScriptu
1. Opětovné ladění parametrů učení
Pokud chcete dosáhnout podobné propustnosti na pracovní proces, je nutné zvýšit počet vzorků v minibatchu úměrně počtu pracovních procesů. Toho lze dosáhnout úpravou
minibatchSizenebonbruttsineachrecurrentiterv závislosti na tom, jestli se používá náhodnost režimu rámce.Není potřeba upravit míru učení (na rozdíl od Model-Averaging SGD, viz níže).
Doporučuje se používat Block-Momentum SGD s teplým modelem. Při našich úkolech rozpoznávání řeči je dosaženo přiměřené konvergence při zahájení od počátečních modelů natrénovaných na 24 hodin (8,6 milionů vzorků) na 120 hodin (43,2 milionu vzorků) pomocí standardních SGD.
2. Experimenty ASR
Použili jsme algoritmy SGD Block-Momentum a Data-Parallel (1bitová) SGD k trénování sítí DNN a LSTM na 2600 hodin rozpoznávání řeči a porovnávali přesnost rozpoznávání slov vs. faktory zrychlení. Následující tabulky a obrázky ukazují výsledky (*).
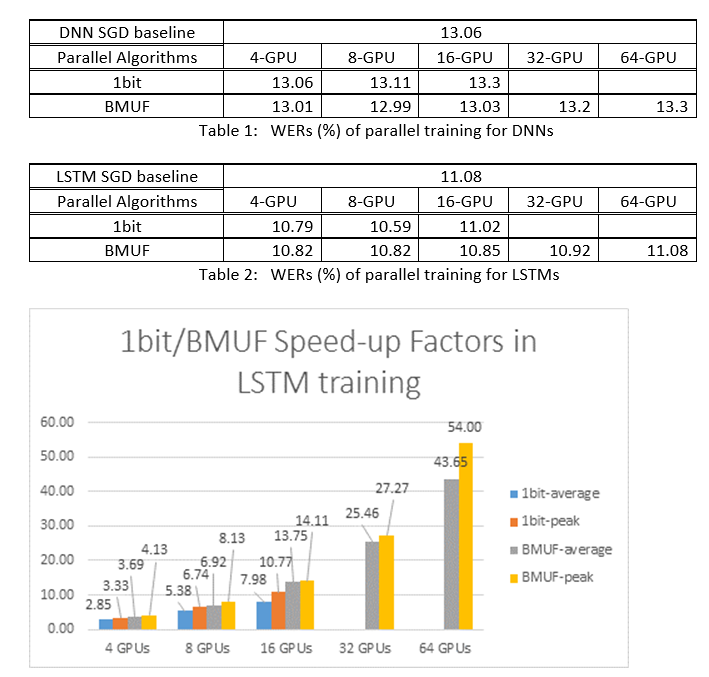
(*): Faktor zrychlení špičky: u 1bitového SGD měřeného maximálním faktorem zrychlení (ve srovnání se směrným plánem SGD) dosaženým v jedné minibatch; pro blokovou dynamiku měřenou maximální rychlostí dosaženo v jednom bloku; Průměrný faktor zrychlení: uplynulý čas v směrném plánu směrného plánu SGD dělený pozorovaným časem. Tyto dvě metriky jsou zavedeny kvůli latenci vstupně-výstupních operací může výrazně ovlivnit průměrné měření faktoru zrychlení, zejména pokud se synchronizace provádí na úrovni mini dávky. Současně je maximální rychlost-up faktor relativně robustní.
3. Upozornění
Doporučuje se nastavit
resetSGDMomentumna true, jinak často vede k rozdílnosti trénovacího kritéria. Resetování dynamiky SGD na 0 po každé synchronizaci modelů v podstatě snižuje příspěvek od posledních minibatch. Proto se nedoporučuje používat velkou dynamiku SGD. Například usyncPeriod120 000 pozorujeme významnou ztrátu přesnosti, pokud je dynamika použitá pro SGD 0,99. Snížení dynamiky SGD na 0,9, 0,5 nebo jeho úplné zakázání poskytuje podobné přesnosti, jak toho lze dosáhnout standardním algoritmem SGD.Block-Momentum zpoždění SGD a distribuuje aktualizace modelu z jednoho bloku mezi další bloky. Proto je nutné zajistit, aby se synchronizace modelů prováděla často v trénování. Rychlá kontrola spočívá v použití
blockMomentumAsTimeConstant. Doporučuje se, aby počet jedinečných trénovacích vzorkůN, měl by splňovat následující rovnici:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
Aproximace vychází z následujících faktů: (1) Bloková dynamika je často nastavena jako (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Použití Block-Momentum v Pythonu
Aby bylo možné povolit Block-Momentum v Pythonu, podobně jako 1bitová SGD, musí uživatel vytvořit a předat učiteli distribuovanou blokovou dynamiku:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Plně funkční příklad najdete v příkladu ConvNet.
7 Model-Averaging SGD
Model-Averaging SGD je implementace modelu průměrovací algoritmus podrobně popsaný v [3,4] bez použití přirozeného přechodu. Cílem je umožnit každému pracovnímu procesu zpracování podmnožinu dat, ale průměrování parametrů modelu z každého pracovního procesu po zadaném období.
Model-Averaging SGD obecně konverguje pomaleji a k horšímu optimálnímu, v porovnání s 1bitovou sadou SGD a Block-Momentum SGD, takže se už nedoporučuje.
Pokud chcete použít Model-Averaging SGD, je nutné mít v bloku podblok s ModelAveragingSGDSGD následujícími možnostmi:
syncPeriodurčuje počet vzorků, které každý pracovní proces musí zpracovat před provedením modelu. Výchozí hodnota je 40 000.
7.1 Použití Model-Averaging SGD v BrainScriptu
Aby bylo Model-Averaging SGD maximálně efektivní a efektivní, musí uživatelé ladit některé hyper-parametry:
minibatchSizenebonbruttsineachrecurrentiter: Předpokládejme, že se pracovnícinúčastní konfigurace Model-Averaging SGD, aktuální implementace distribuovaného čtení načte1/ndo každého pracovního procesu minibatch. Proto je nutné, aby každý pracovní proces vytvořil stejnou propustnost jako standardní SGD, je nutné zvětšit velikostnminibatchu -fold. U modelů, které jsou natrénovány pomocí náhodnosti v režimu rámečku, to lze dosáhnout zvětšenímminibatchSizepodlenčasu. U modelů se trénují pomocí náhodného pořadí režimu, jako jsou RNN, někteří čtenáři místo toho vyžadují zvýšenínbruttsineachrecurrentiteron.learningRatesPerSample. Naše zkušenosti ukazují, že pokud chcete získat podobnou konvergenci jako standardní SGD, je nutné zvýšit časylearningRatesPerSamplen. Vysvětlení najdete v [2]. Vzhledem k tomu, že se zvyšuje míra učení, je potřeba další péče, aby se školení nerozlišovala – a to je ve skutečnosti hlavní upozornění Model-Averaging SGD. NastaveníAutoAdjustmůžete použít k opětovnému načtení předchozího nejlepšího modelu, pokud je pozorováno zvýšení kritéria trénování.zahřátý start. Zjistilo se, že Model-Averaging SGD obvykle konverguje lépe, pokud je spuštěn z počátečního modelu, který je trénován standardním algoritmem SGD (bez paralelizace). Při našich úkolech rozpoznávání řeči je dosaženo přiměřené konvergence při zahájení od počátečních modelů natrénovaných na 24 hodin (8,6 milionů vzorků) na 120 hodin (43,2 milionu vzorků) pomocí standardních SGD.
Tady je příklad oddílu ModelAveragingSGD konfigurace:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Použití Model-Averaging SGD v Pythonu
Na tomto seznamu stále pracujeme.
8 Data-Parallel trénování pomocí parametrového serveru
Parametrický server je široce používanou architekturou v distribuovaném strojovém učení [5][6][7]. Nejdůležitější výhodou, která přináší, je asynchronní paralelní trénování s mnoha pracovními procesy. Zavádí server parametrů jako distribuované úložiště modelů. Místo přímého využití primitiv AllReduce k synchronizaci aktualizací parametrů mezi pracovními procesy poskytuje architektura serveru parametrů uživatelům rozhraní, jako je "Add" a "Get", aby místní pracovníci mohli aktualizovat a načíst globální parametry ze serveru parametrů. Tímto způsobem nemusí místní pracovníci čekat na sebe během procesu trénování, což šetří spoustu času, zejména když je číslo pracovního procesu velké.
Vzhledem k tomu, že servery parametrů představují distribuovanou architekturu, která ukládá parametry modelu, můžou pracovníci tyto parametry načíst jenom během procesu trénování mini-batch, což přináší velmi dobrou flexibilitu při návrhu distribuované trénovací metody a také zvyšuje efektivitu při trénování s řídkými aktualizacemi modelu. V této verzi se nejprve zaměříme na asynchronní paralelní trénování, později poskytneme další úvod k využití architektury serveru parametrů pro efektivní trénování modelů s řídkými aktualizacemi.
8.1 Použití Data-Parallel ASGD
- Pokud chcete použít parametrové servery pro asynchronní SGD (abbr. as ASGD), měli byste sestavit CNTK s podporou Multiverso, Multiverso je obecná architektura serveru parametrů pro distribuovanou úlohu strojového učení vyvinutou týmem Microsoft Research Asia.
Clone Code: Naklonujte kód v kořenové složce CNTK pomocí:
git submodule update --init Source/Multiverso
Linux: Sestavte--asgd=yesv procesu konfigurace.Windows: PřidejteCNTK_ENABLE_ASGDprosím do systémového prostředí a nastavte hodnotu natrue
- zahřátý start. V některýchpřípadechch modelech je lepší začít trénovat z počátečního modelu (který je trénován standardním algoritmem SGD). Asynchronní SGD v určitém smyslu přináší větší šum pro trénování kvůli zpožděným aktualizacím zesynchronismu mezi pracovními procesy. Některé modely jsou velmi citlivé na takový šum na začátku, což může vést k rozbíhající se trénování modelů. Za takových okolností je potřeba teplý start .
8.2 Konfigurace Data-Parallel ASGD v BrainScriptu
Pokud chcete použít Data-Parallel ASGD v CNTK, je nutné mít v bloku SGD dílčí blok DataParallelASGD s následujícími možnostmi.
-
syncPeriodPerWorkers. Určuje počet vzorků, které každý pracovní proces musí zpracovat před komunikací se servery parametrů. Výchozí hodnota je 256. Doporučuje se jako velikost minibatchu. Je zřejmé, že časté synchronizace povede k významným vysokým nákladům na komunikaci. V našem testu není nutné nastavit hodnotu na hodnotu 1 ve většině případů.
-
usePipeline. Určuje, jestli zapnete kanál načítání modelu a místní výpočty. Zapnutí kanálu výrazně zvýší celkovou propustnost trénování, protože skryje některé nebo všechny náklady na komunikaci. Někdy se ale může zpomalit konverge frekvence, protože další zpoždění bude zavedeno přidáním kanálu. Celkový čas se uloží ve většině případů s kanálem.
-
AdjustLearningRateAtBeginning. Podle nedávno publikovaného dokumentu [5] je trénování ASGD méně stabilní a vyžaduje použití mnohem menší rychlosti učení, aby se zabránilo občasným výbuchům ztráty trénování, proto se proces učení stává méně efektivním. Zjistili jsme ale, že pro všechny úkoly není vyžadováno použití nižší míry učení. A pro tyto úkoly citlivé na začátku zahájíme trénování s malou mírou učení a postupně ho zvětšíme na začátku procesu trénování, dokud nedosáhne počáteční míry učení použité v normálníM SGD. Tímto způsobem bude konečná přesnost odpovídat SGD, zatímco rychlost ASGD. Takže tuto možnost poskytujeme uživatelům ASGD, aby tento trik využili. Jedná se o dílčí blok v DataParallelASGD se dvěma parametry: adjustCoefficient a adjustNBMiniBatch. Logika spočívá v tom, že míra učení začíná od úpravyCoefficient počáteční rychlosti učení SGD a zvýšením možnosti upravitCoefficient počátečního učení SGD každé upravované mini-dávkyNBMiniBatch .
Tady je příklad oddílu DataParallelASGD konfigurace:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Konfigurace Data-Parallel ASGD v Pythonu
Na tomto seznamu stále pracujeme.
8.4 Experimenty
Následující obrázek znázorňuje experimenty pro testování ASGD s datovou sadou CIFAR-10. Model použitý v tomto experimentu je 20vrstvé sítě ResNet. Asynchronní algoritmus snižuje náklady na čekání na všechny pracovní uzly. ASGD je v tomto případě jasně rychlejší než synchronní algoritmy, jako je MA a SSGD. *V experimentech synchronizují všechny paralelní režimy parametry každé iterace (mini-batch update). A pro SSGD jsme použili 32bitové aktualizace parametrů. Asynchronní algoritmus získává významnou výhodu z hlediska trénovací propustnosti měřené rychlostí zpracování vzorku, zejména v případě, že číslo pracovního uzlu klesne až na 16.
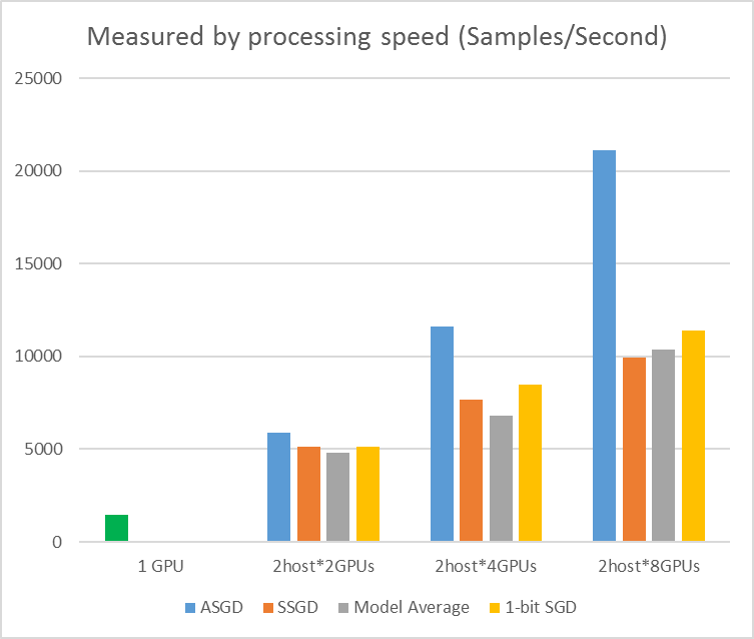 Obrázek 2.4 Zrychlení různých metod trénování
Obrázek 2.4 Zrychlení různých metod trénování
Reference
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li a Dong Yu, "1-bit stochastic gradientní sestup a jeho aplikace na data-paralelně distribuované trénování řeči DNNs", v Proceedings of Interspeech, 2014.
[2] K. Chen a Q. Huo, "Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering" in Proceedings of ICASSP, 2016.
[3] M. Zinkjevič, M. Weimer, L. Li a A. J. Smola, "Paralelizovaný stochastický gradientní sestup", v proceedings of Advances in NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. Zhang a S. Khudanpur, "Paralelní trénování DNN s přirozeným přechodem a průměrováním parametrů", v proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Sync SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Rozsáhlé distribuované hluboké sítě. V předstihu v neurálních informačních systémech, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen a Alexander Smola. "Server parametrů pro distribuované strojové učení" In Big Learning NIPS Workshop, vol. 6, p. 2. 2013.