Rychlý start: Vytvoření prvního toku dat pro získání a transformaci dat
Toky dat jsou samoobslužná cloudová technologie pro přípravu dat. V tomto článku vytvoříte první tok dat, získáte data pro tok dat a pak data transformujete a publikujete tok dat.
Požadavky
Před spuštěním jsou vyžadovány následující požadavky:
- Účet tenanta Microsoft Fabric s aktivním předplatným. Vytvořte si bezplatný účet.
- Ujistěte se, že máte povolený pracovní prostor Microsoft Fabric: Vytvořte pracovní prostor.
Vytvoření toku dat
V této části vytváříte svůj první tok dat.
Přepněte do prostředí datové továrny .

Přejděte do pracovního prostoru Microsoft Fabric.
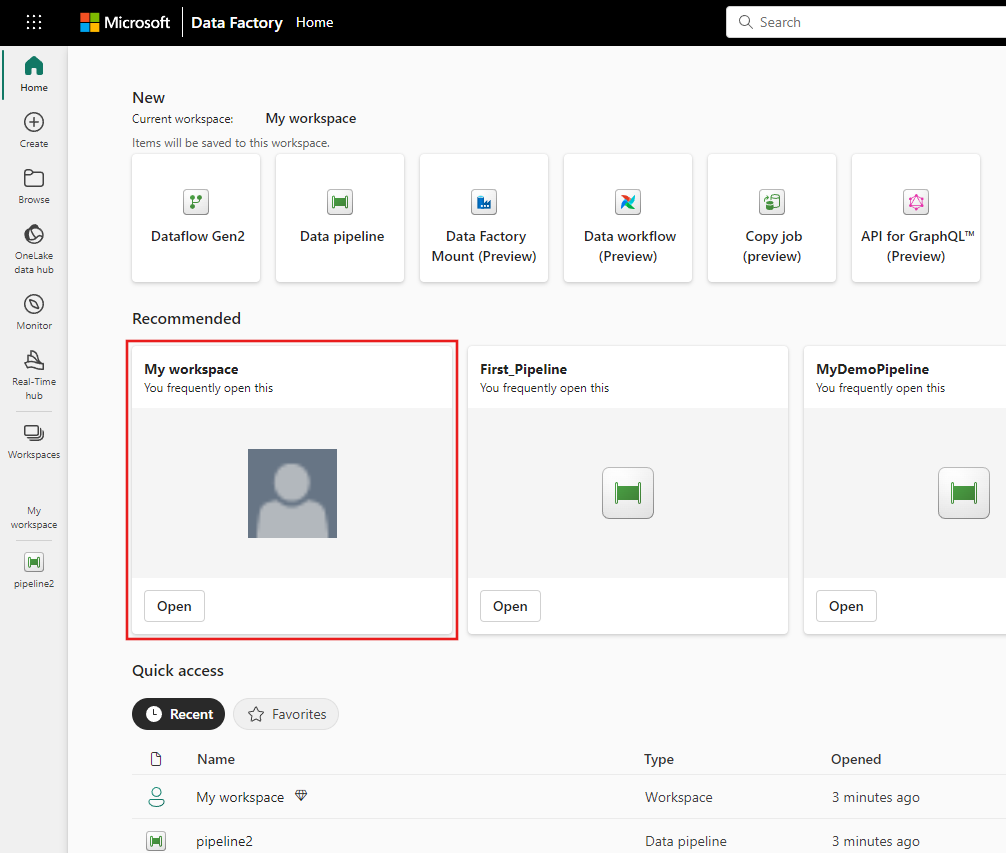
Vyberte Nový a pak vyberte Dataflow Gen2.
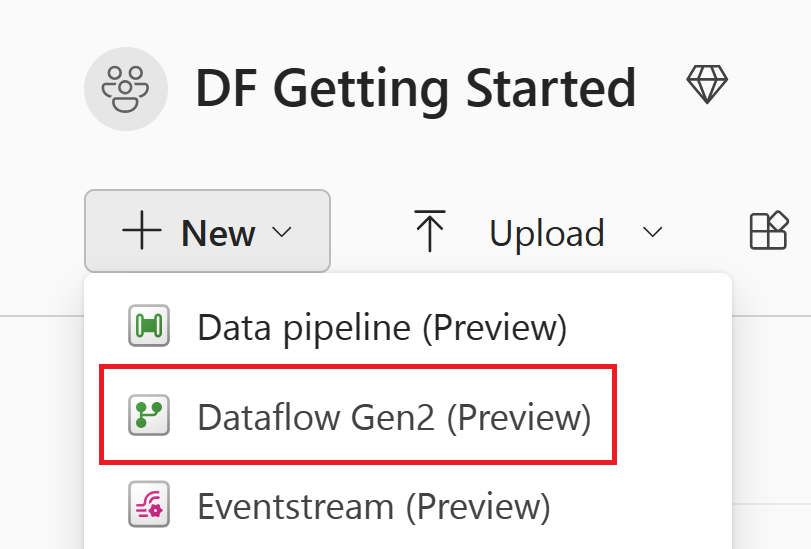

Získat data
Pojďme získat nějaká data. V tomto příkladu získáváte data ze služby OData. K získání dat do toku dat použijte následující postup.
V editoru toku dat vyberte Získat data a pak vyberte Další.
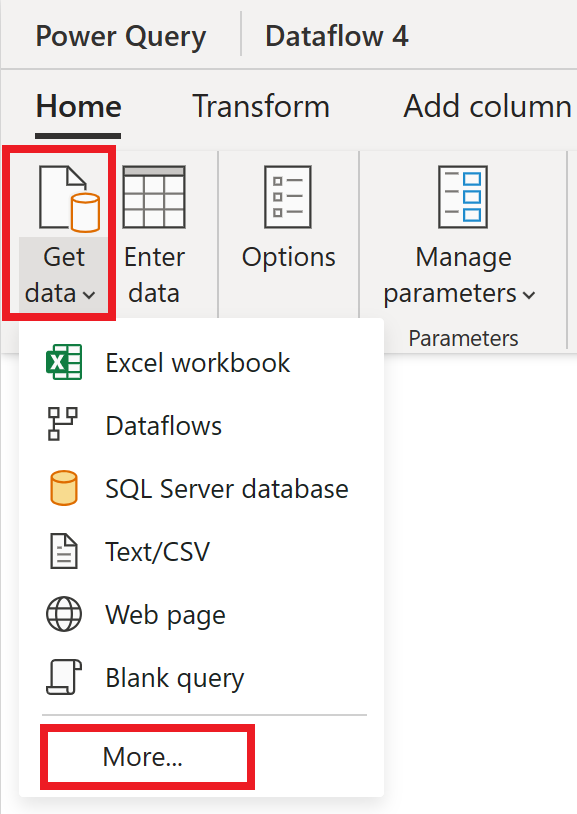
Ve výběru zdroje dat vyberte Zobrazit více.

V části Nový zdroj vyberte jako zdroj dat jiný>objekt OData.

Zadejte adresu URL
https://services.odata.org/v4/northwind/northwind.svc/a pak vyberte Další.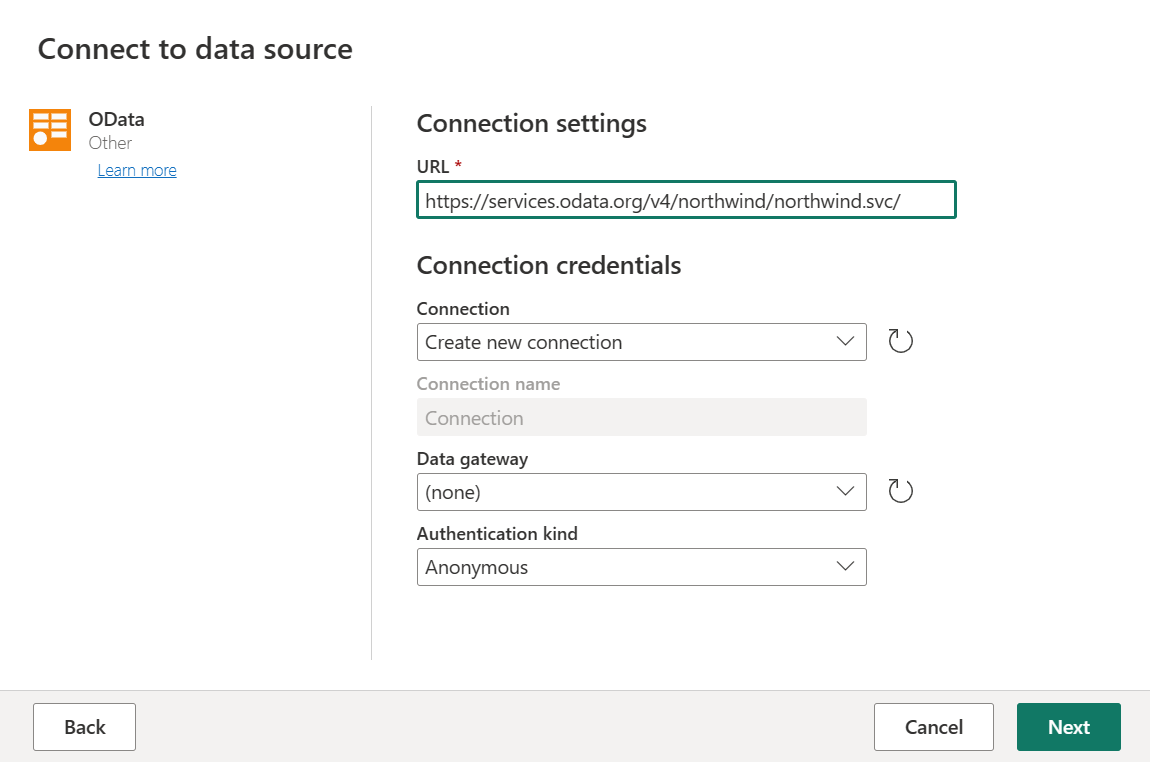
Vyberte tabulky Objednávky a Zákazníci a pak vyberte Vytvořit.




Další informace o možnostech získání dat a funkcí najdete v tématu Získání přehledu dat.
Použití transformací a publikování
Právě jste načetli data do prvního toku dat, blahopřejeme! Teď je čas použít několik transformací, aby se tato data přenesla do požadovaného tvaru.
Tuto úlohu budete dělat v editoru Power Query. Podrobný přehled editoru Power Query najdete v uživatelském rozhraní Power Query.
Při použití transformací a publikování postupujte takto:
Přejděte do globálních možností> Možnosti domovské>stránky a ujistěte se, že jsou povolené nástroje pro profilaci dat.
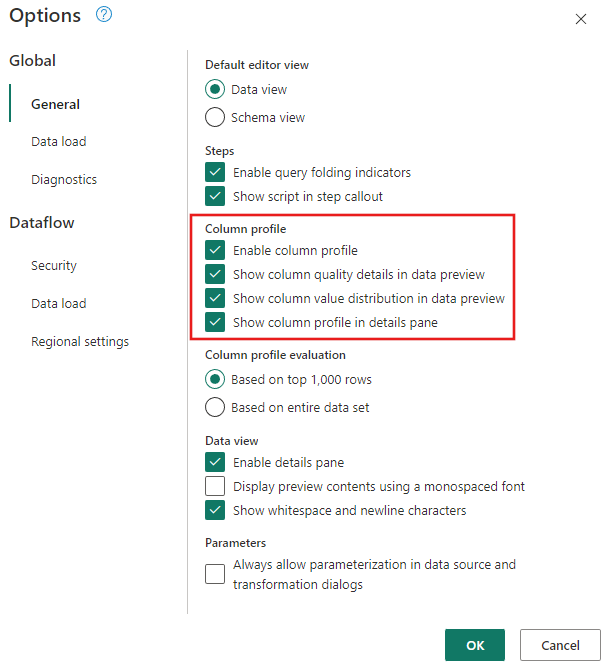
Také se ujistěte, že jste povolili zobrazení diagramu pomocí možností na kartě Zobrazení na pásu karet editoru Power Query nebo výběrem ikony zobrazení diagramu v pravém dolním rohu okna Power Query.
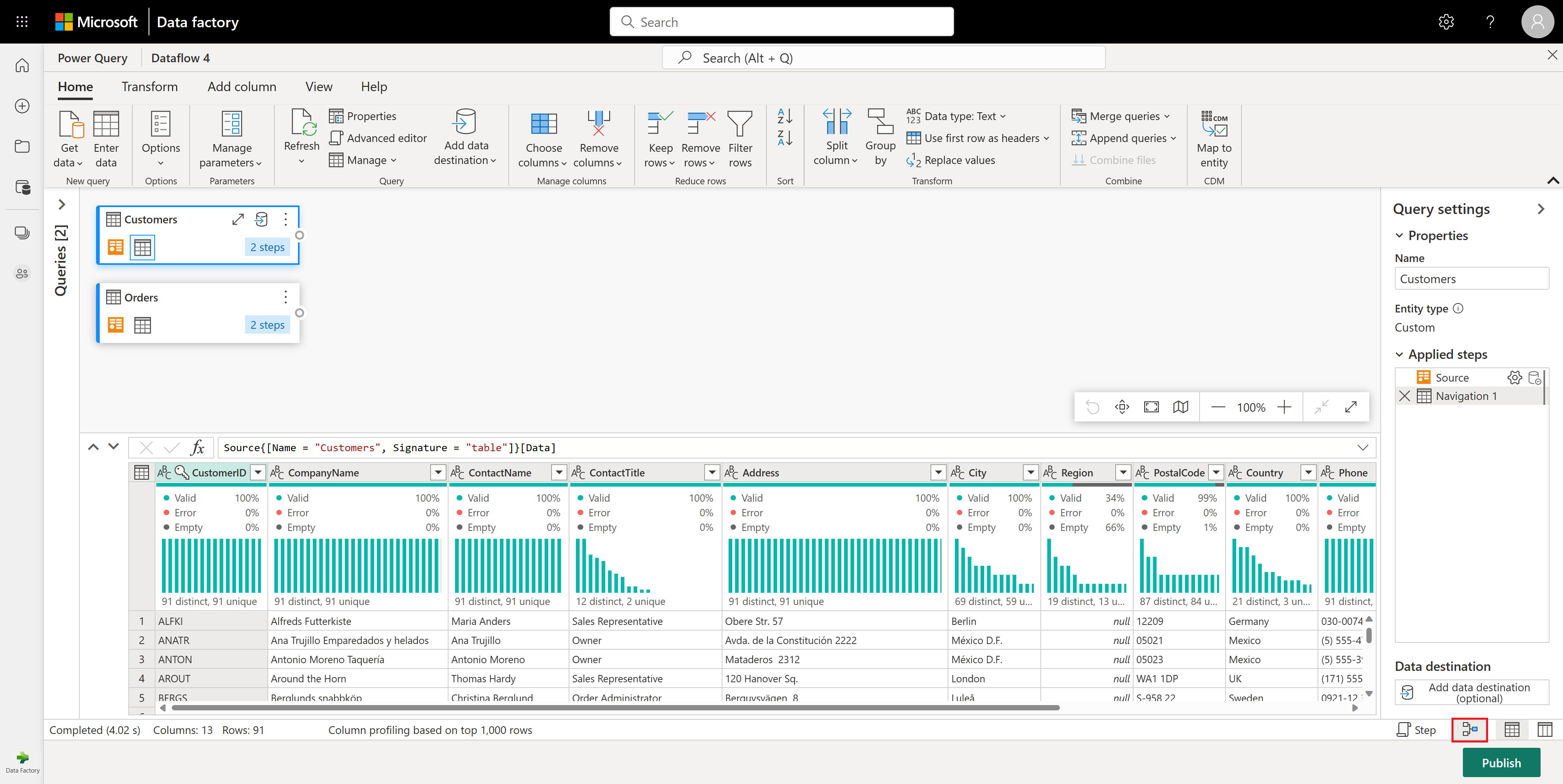
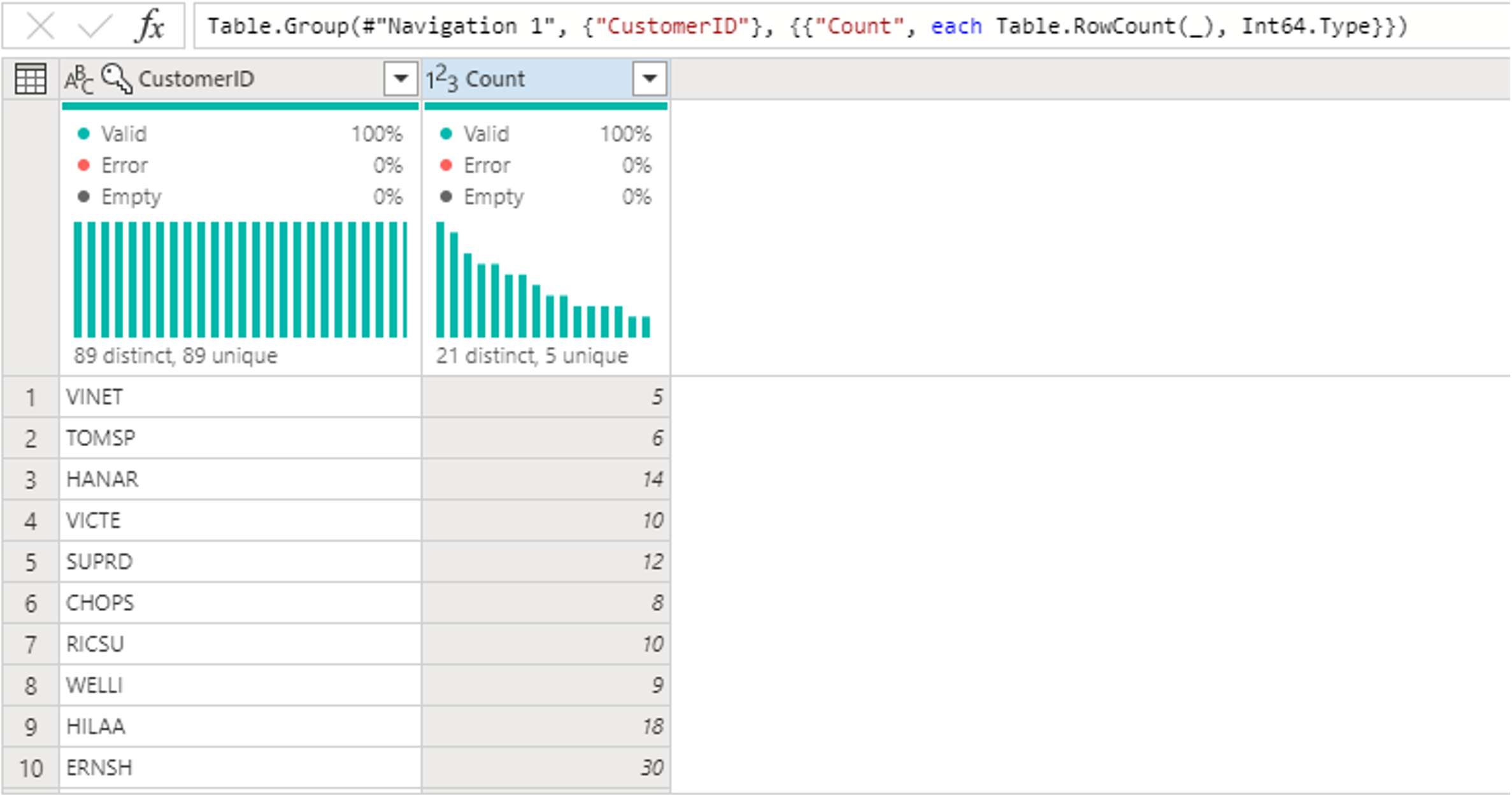
V tabulce Objednávky vypočítáte celkový počet objednávek na zákazníka. Chcete-li dosáhnout tohoto cíle, vyberte sloupec CustomerID v náhledu dat a pak vyberte seskupit podle na kartě Transformace na pásu karet.
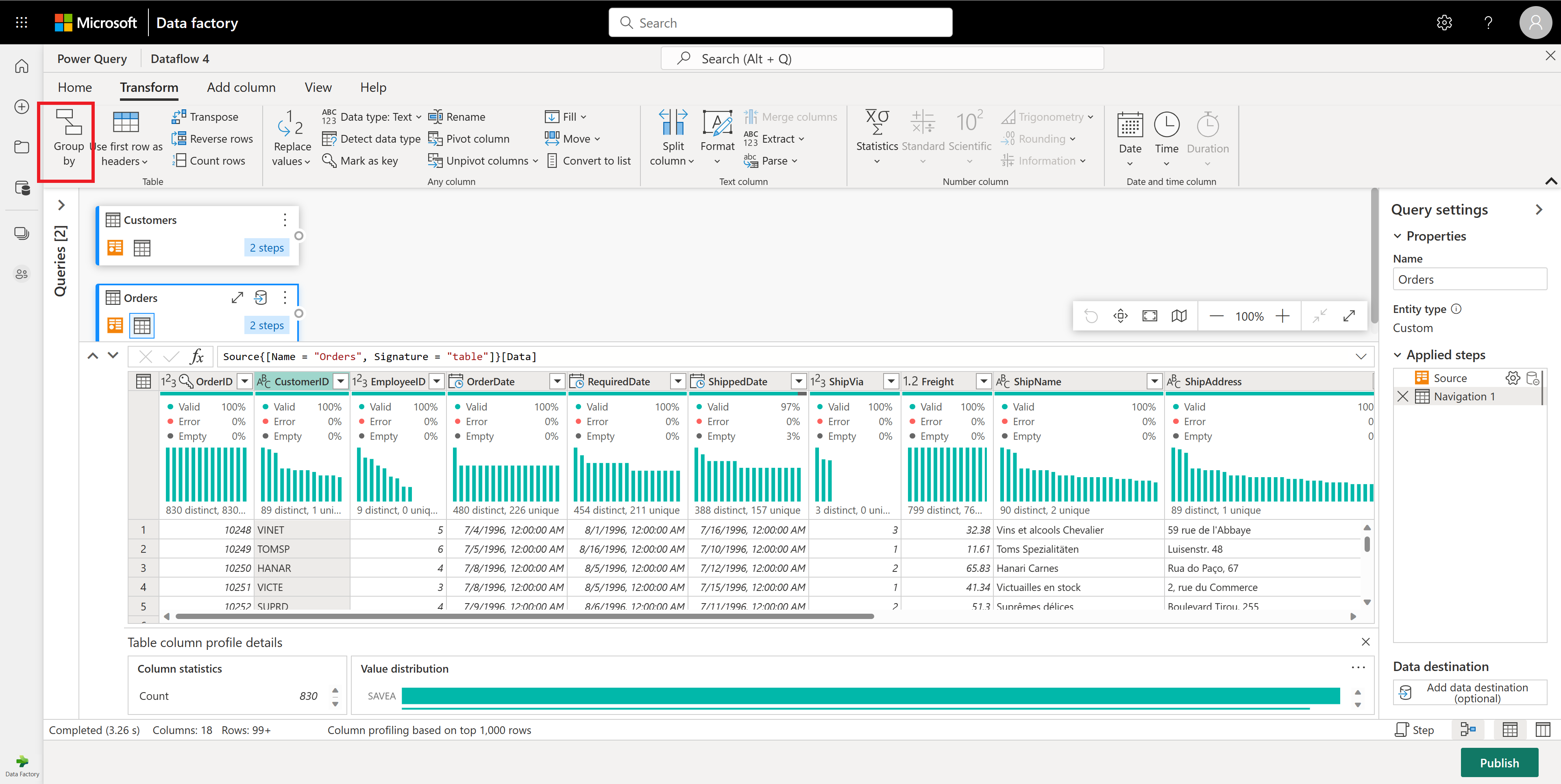
V rámci skupiny podle provedete počet řádků jako agregaci. Další informace o možnostech Seskupit podle najdete v tématu Seskupování nebo shrnutí řádků.
Po seskupení dat v tabulce Objednávky získáme tabulku se dvěma sloupci s ID zákazníka a započítáme jako sloupce.
Dále chcete zkombinovat data z tabulky Zákazníci s počtem objednávek na zákazníka. Pokud chcete zkombinovat data, vyberte dotaz Zákazníci v zobrazení diagramu a pomocí nabídky "⋮" otevřete dotazy sloučení jako novou transformaci.
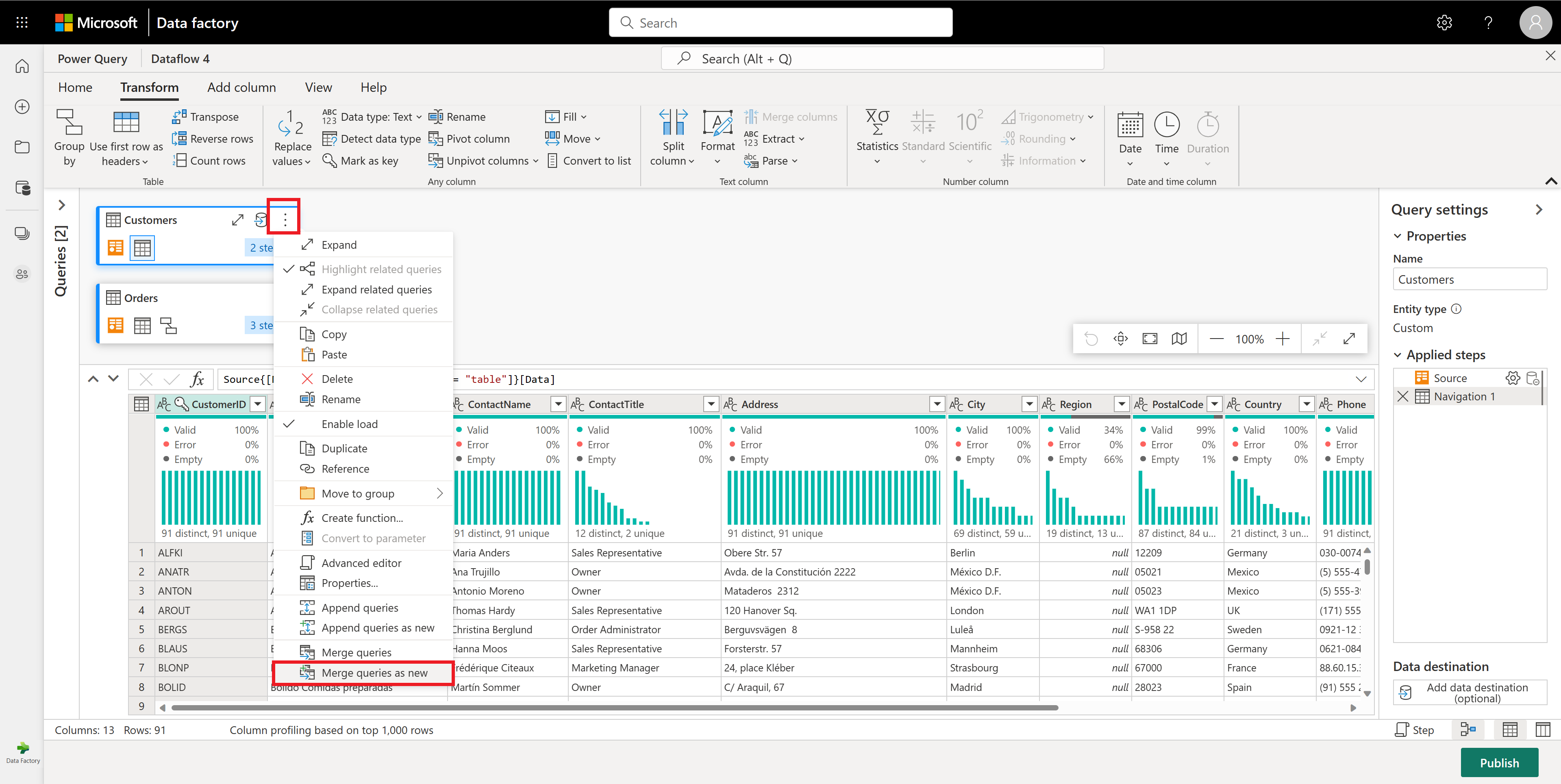
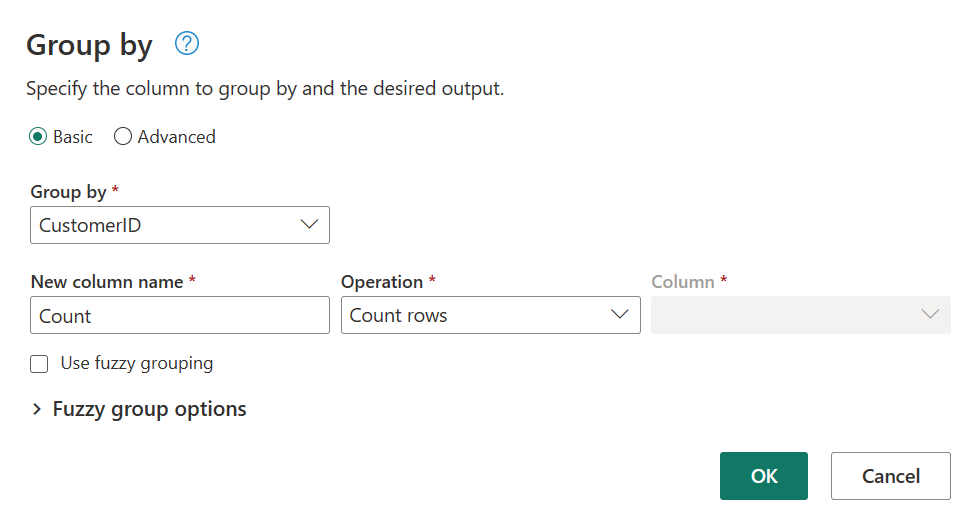
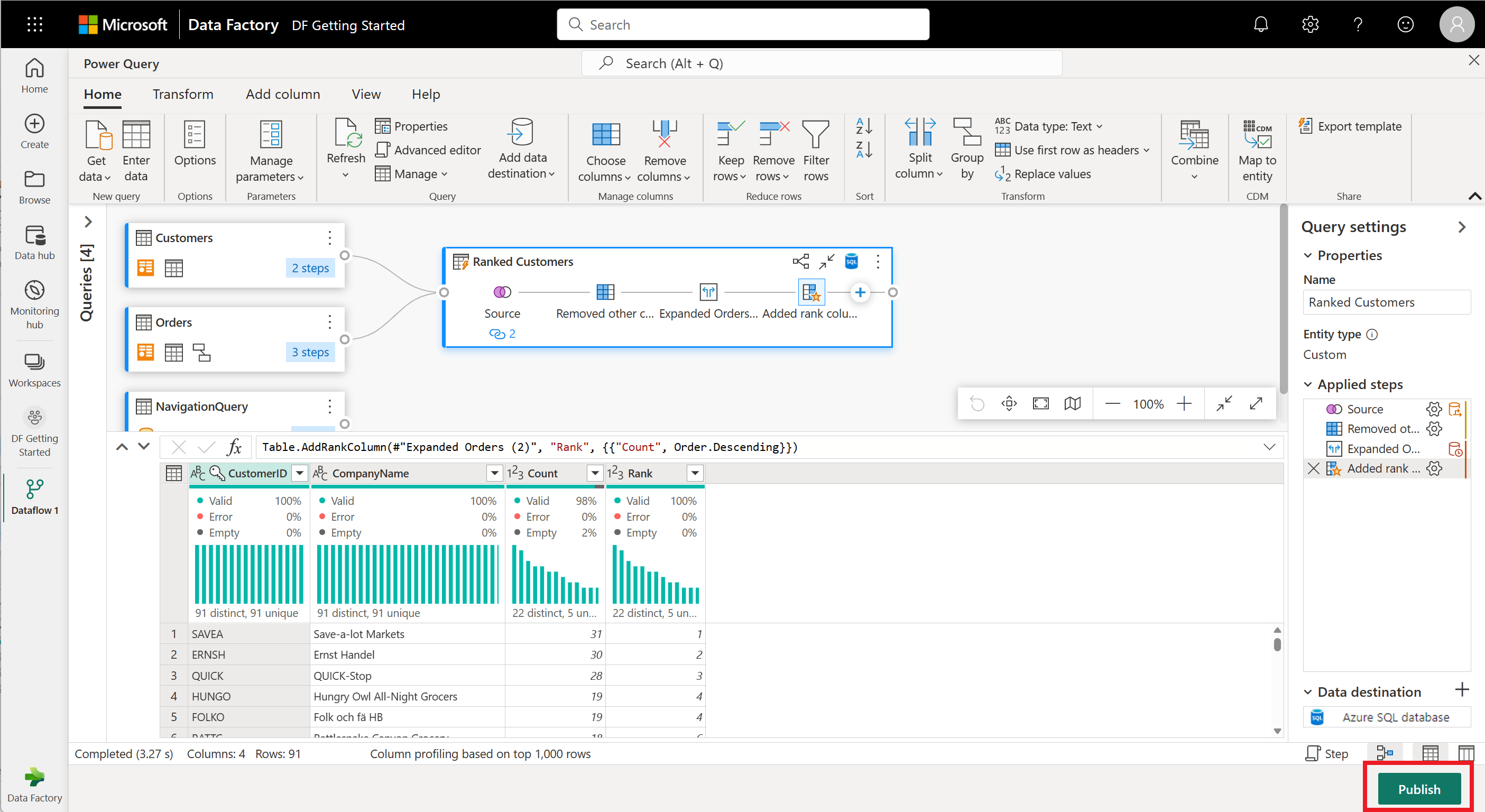
Nakonfigurujte operaci sloučení, jak je znázorněno na následujícím snímku obrazovky, a to tak, že jako odpovídající sloupec v obou tabulkách vyberete CUSTOMERID. Pak vyberte OK.
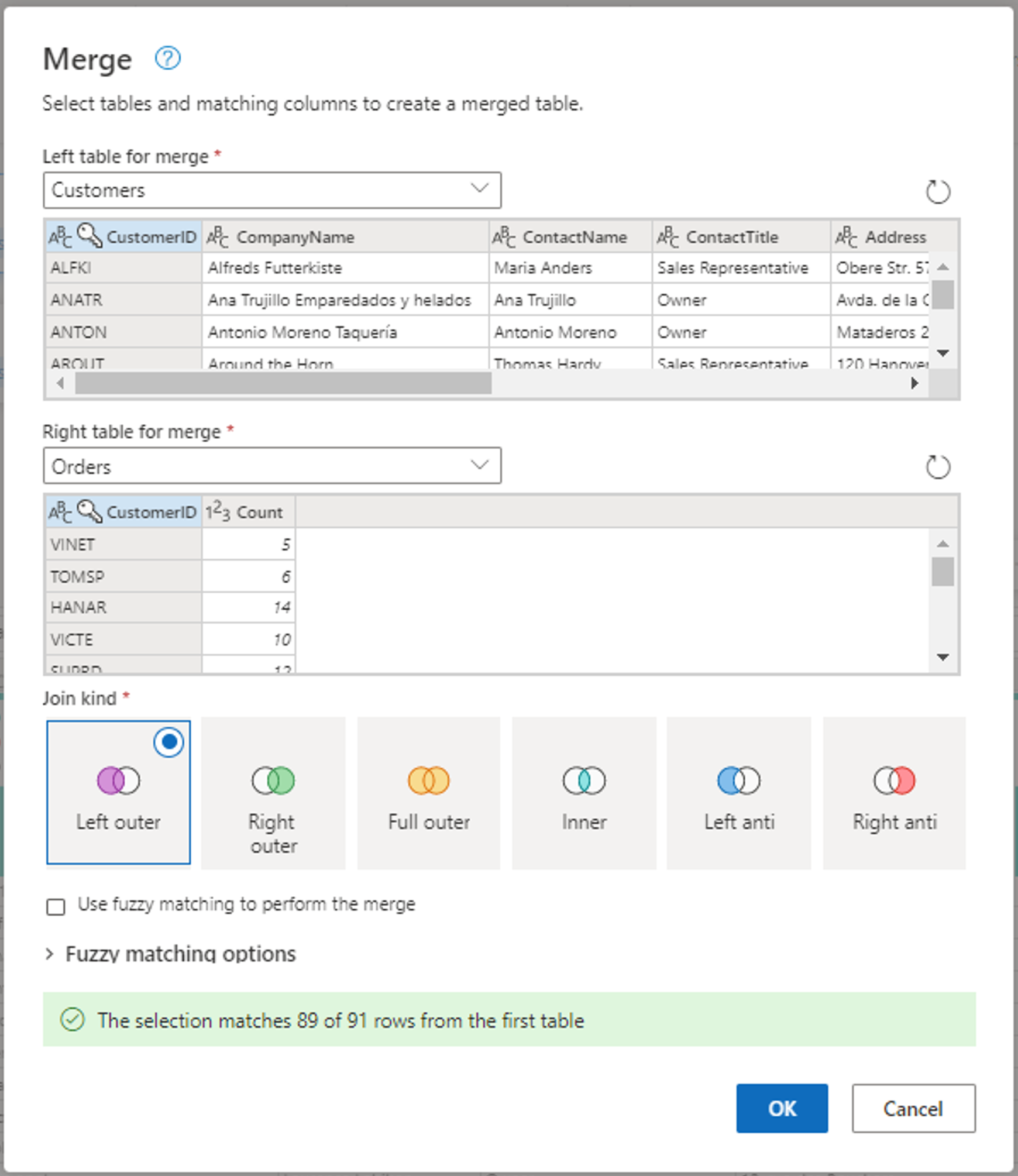
Snímek obrazovky s oknem Sloučit s levou tabulkou pro sloučení nastavenou na tabulku Customers (Zákazníci) a pravou tabulkou pro sloučení nastavenou na tabulku Orders (Objednávky). Sloupec CustomerID (ID zákazníka) je vybraný pro tabulky Customers (Zákazníci) i Orders (Objednávky). Typ spojení je také nastaven na levý vnější. Všechny ostatní výběry jsou nastavené na výchozí hodnotu.
Při provádění slučovacích dotazů jako nové operace získáte nový dotaz se všemi sloupci z tabulky Zákazníci a jedním sloupcem s vnořenými daty z tabulky Objednávky.
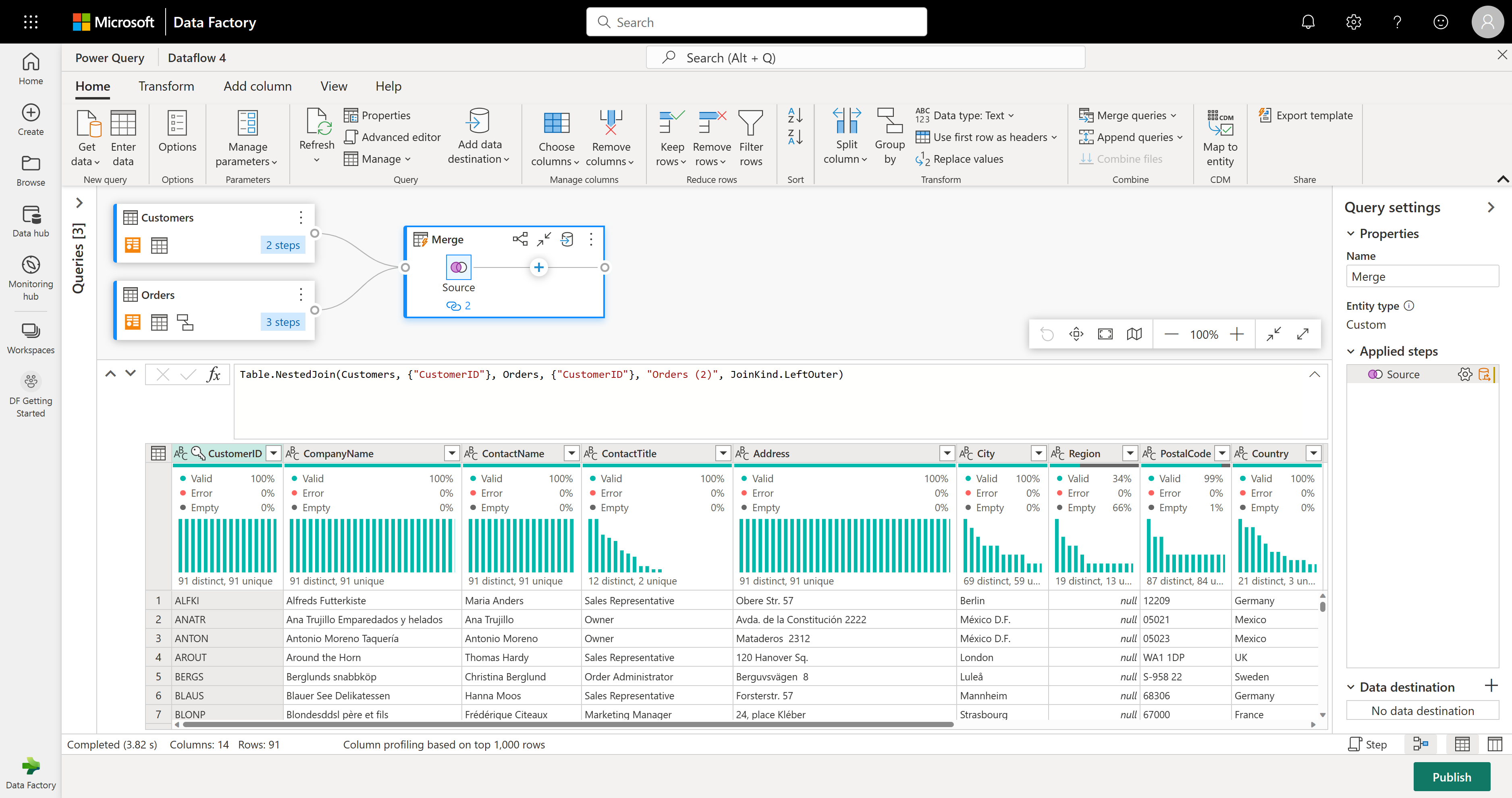
V tomto příkladu vás zajímá jenom podmnožina sloupců v tabulce Zákazníci. Tyto sloupce vyberete pomocí zobrazení schématu. V pravém dolním rohu editoru toků dat povolte zobrazení schématu v přepínacím tlačítku.
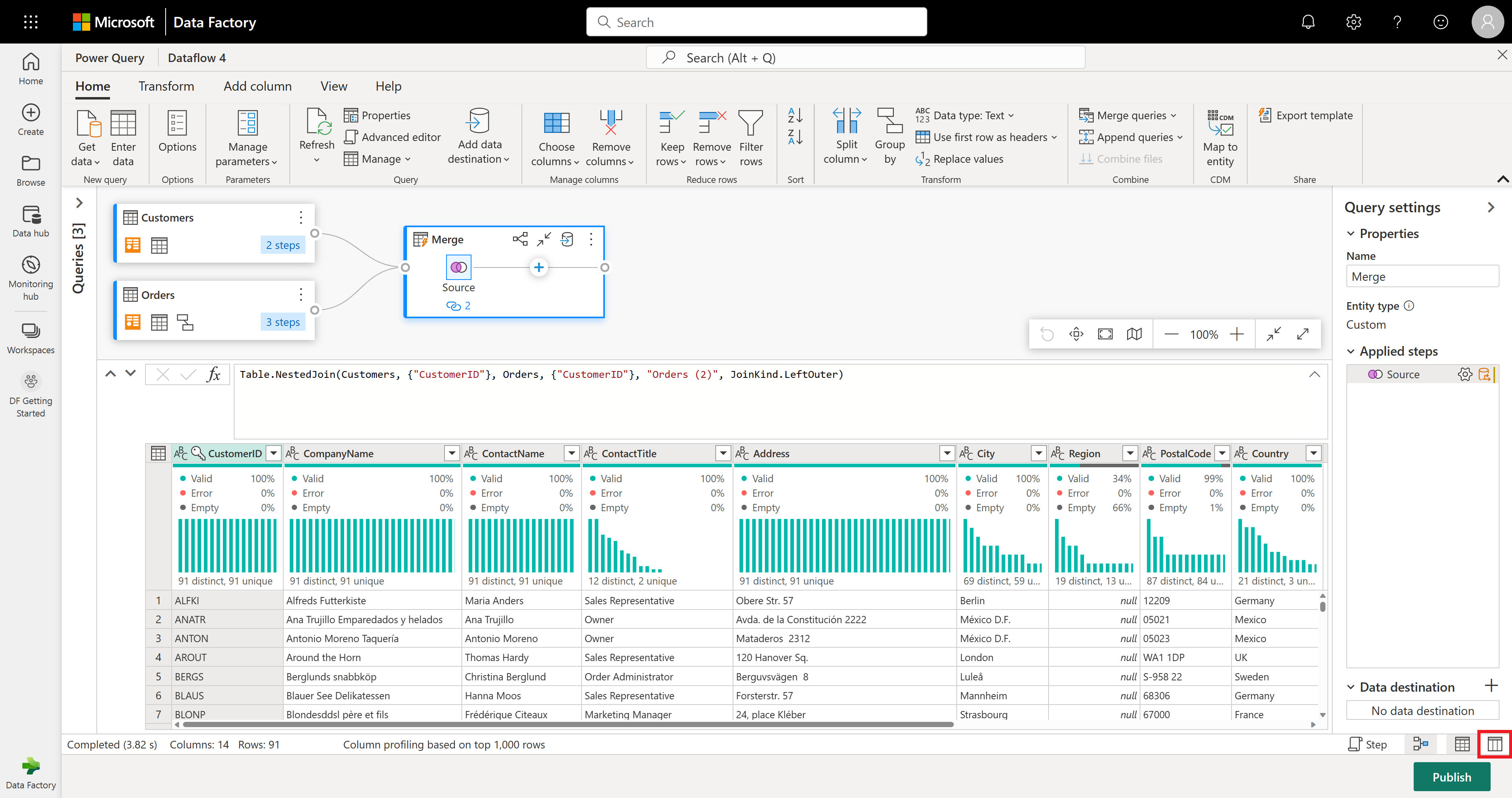
Zobrazení schématu poskytuje prioritní zobrazení informací o schématu tabulky, včetně názvů sloupců a datových typů. Zobrazení schématu obsahuje sadu nástrojů schématu, které jsou k dispozici prostřednictvím kontextové karty pásu karet. V tomto scénáři vyberete sloupce CustomerID( CompanyName) a Orders (2), pak vyberete tlačítko Odebrat sloupce a pak vyberete Odebrat další sloupce na kartě Nástroje schématu.
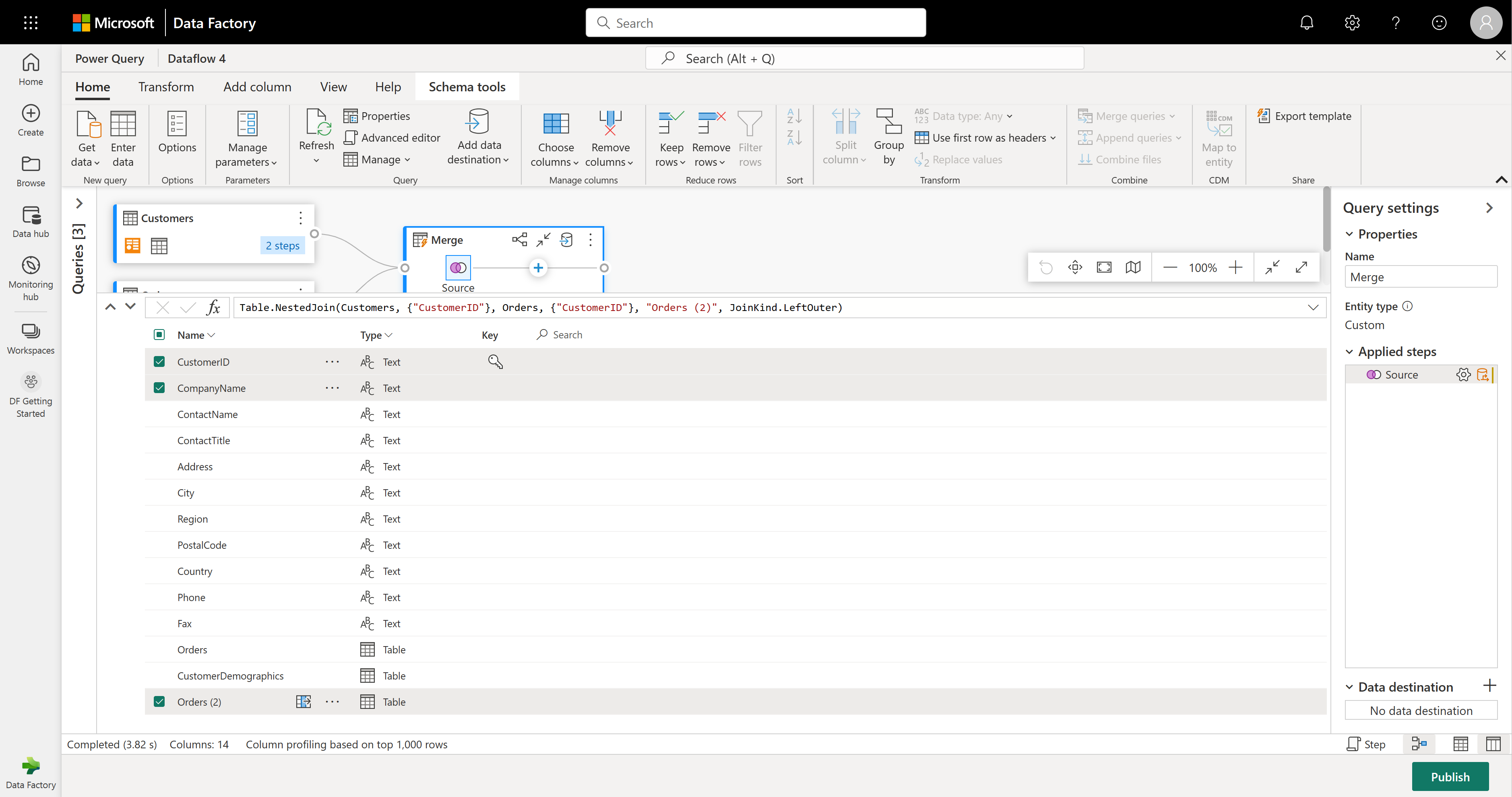

Sloupec Objednávky (2) obsahuje vnořené informace vyplývající z operace sloučení, kterou jste provedli před několika kroky. Teď přepněte zpět do zobrazení dat tak , že vyberete tlačítko Zobrazit zobrazení dat vedle tlačítka Zobrazit zobrazení schématu v pravém dolním rohu uživatelského rozhraní. Potom pomocí transformace Rozbalit sloupec v záhlaví sloupce Objednávky (2) vyberte sloupec Count .
Jako konečnou operaci chcete seřadit zákazníky na základě jejich počtu objednávek. Vyberte sloupec Počet a pak na pásu karet vyberte tlačítko Sloupec pořadí na kartě Přidat sloupec.
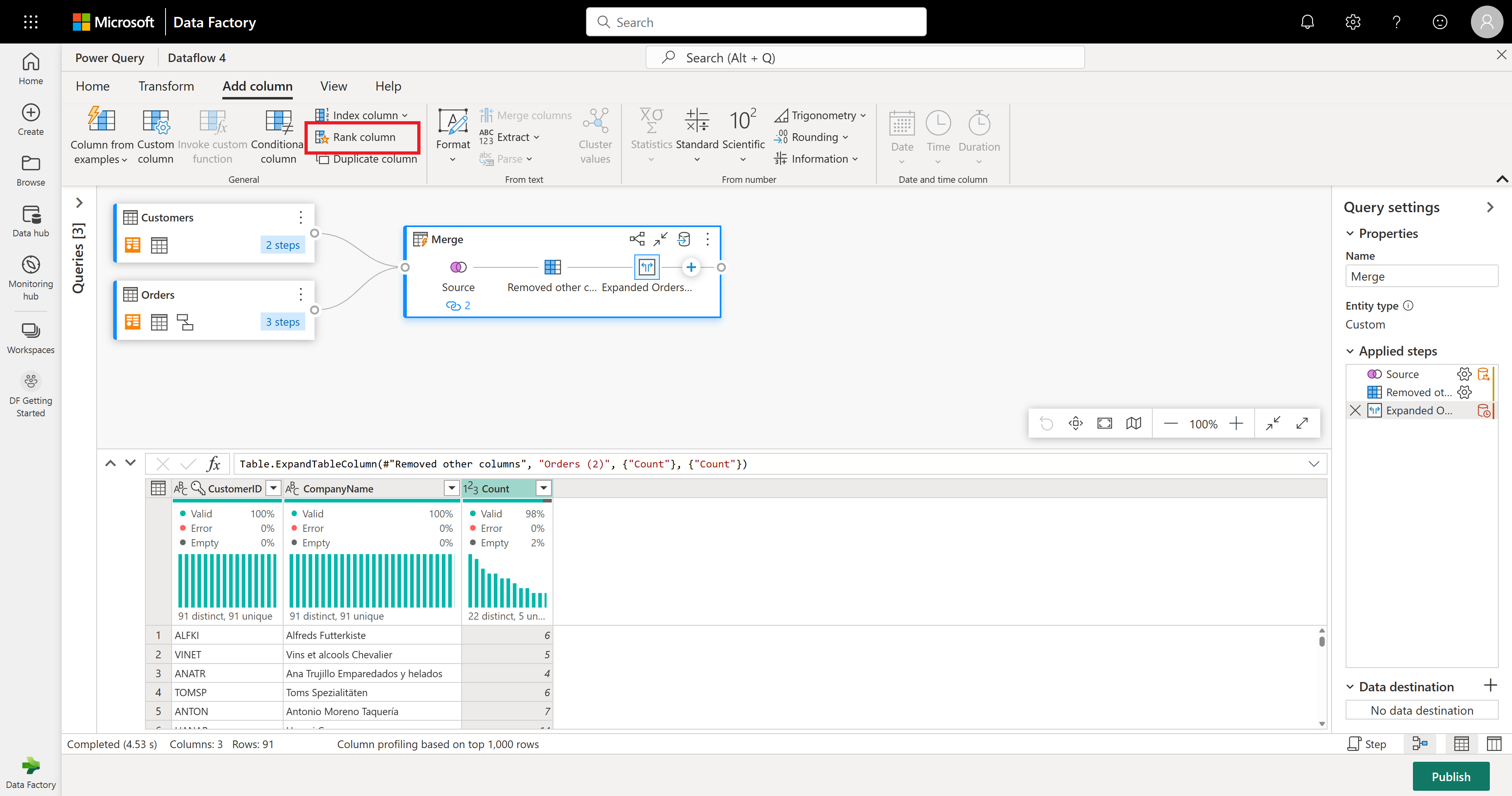
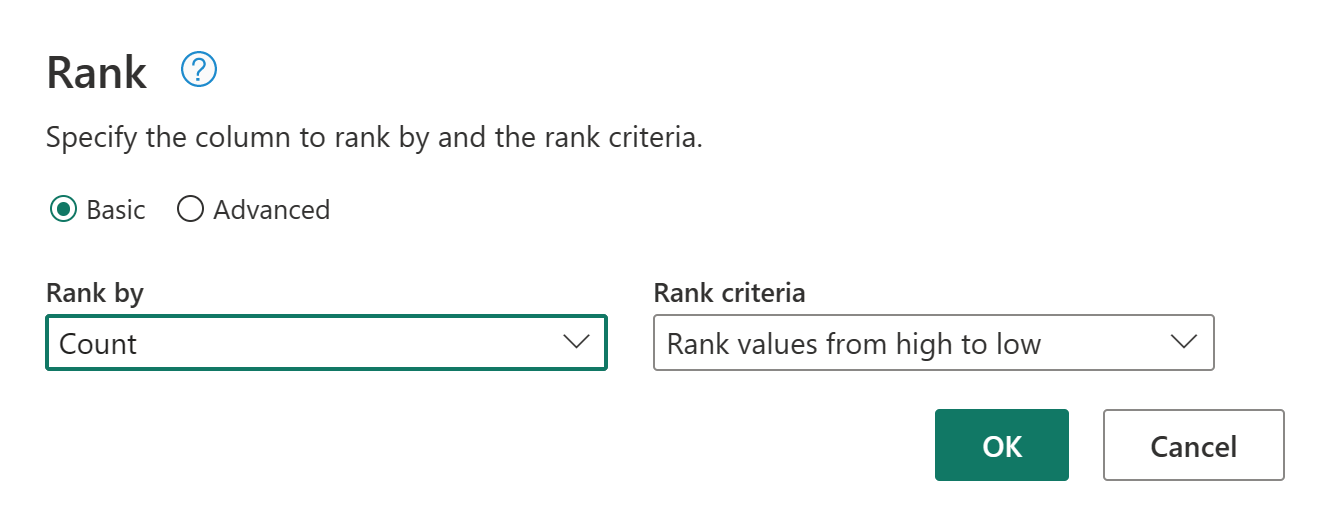
Ponechte výchozí nastavení ve sloupci pořadí. Potom tuto transformaci použijte výběrem tlačítka OK .
Teď přejmenujte výsledný dotaz jako seřazení zákazníci pomocí podokna Nastavení dotazu na pravé straně obrazovky.
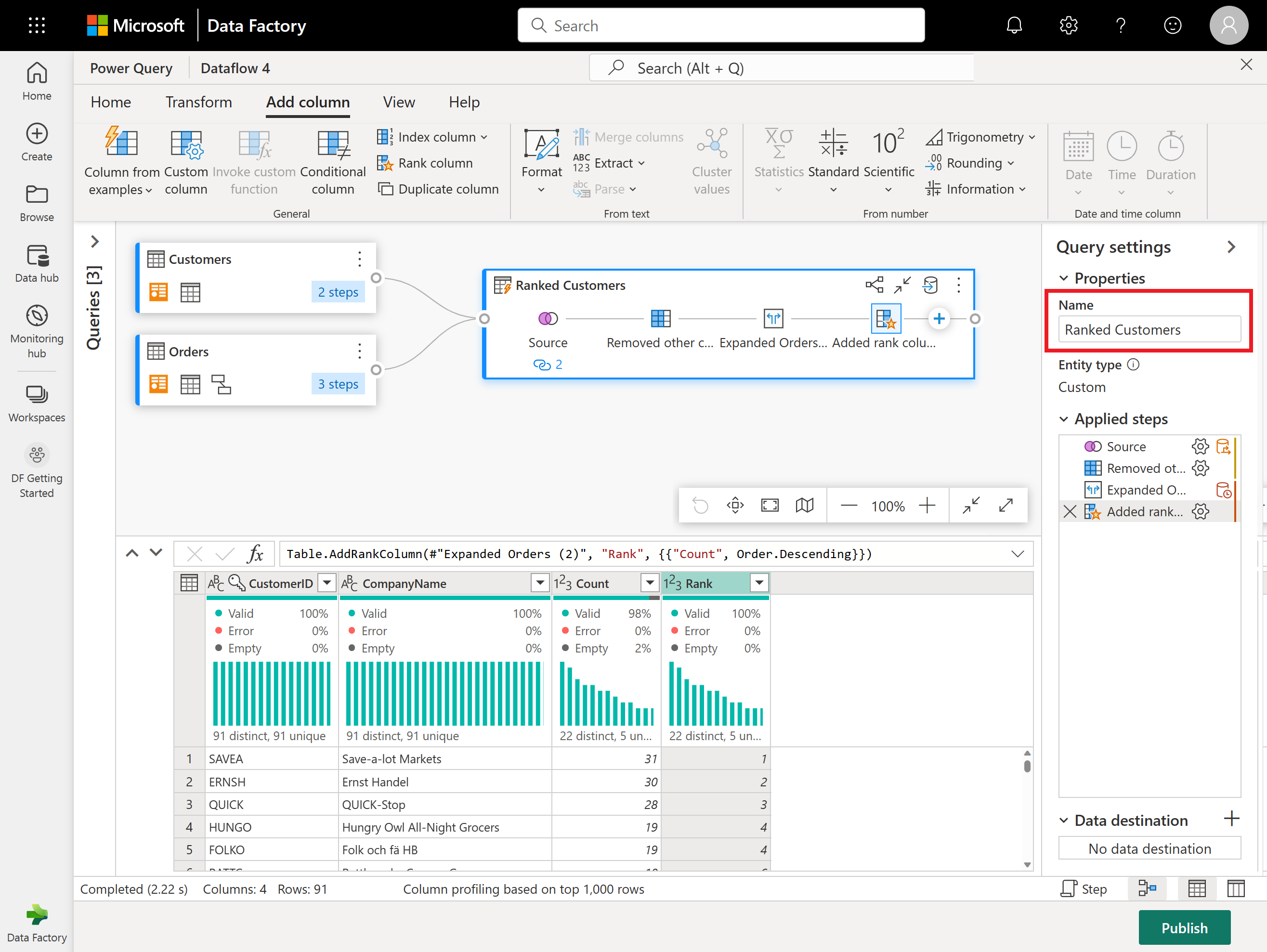
Dokončili jste transformaci a kombinování dat. Teď tedy nakonfigurujete jeho nastavení výstupního cíle. V dolní části podokna Nastavení dotazu vyberte Zvolit cíl dat.
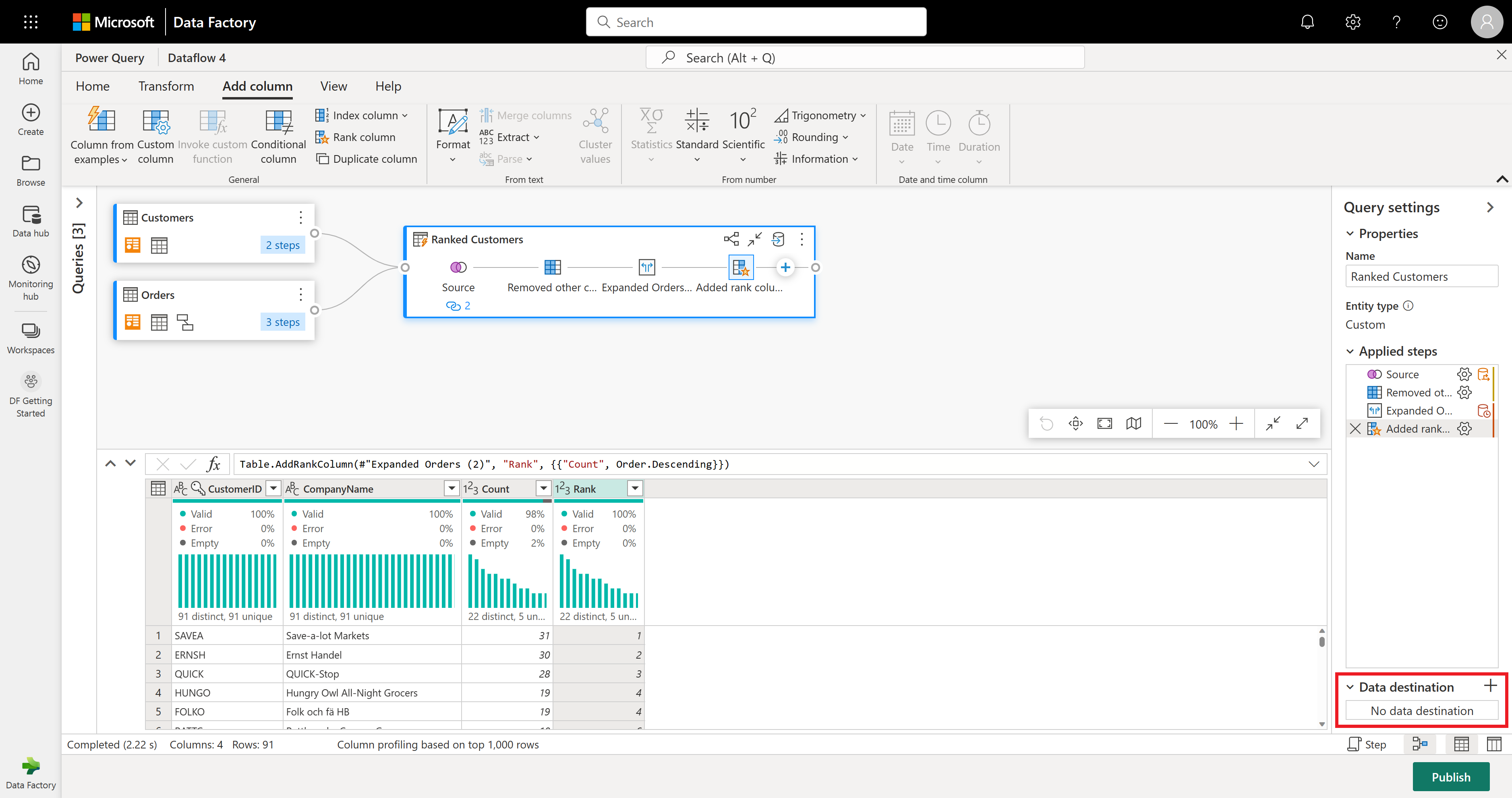
Pro účely tohoto kroku můžete nakonfigurovat výstup do jezera, pokud máte k dispozici, nebo tento krok přeskočit, pokud ne. V tomto prostředí můžete kromě metody update (Append nebo Replace) nakonfigurovat cílové jezero a tabulku pro výsledky dotazu.
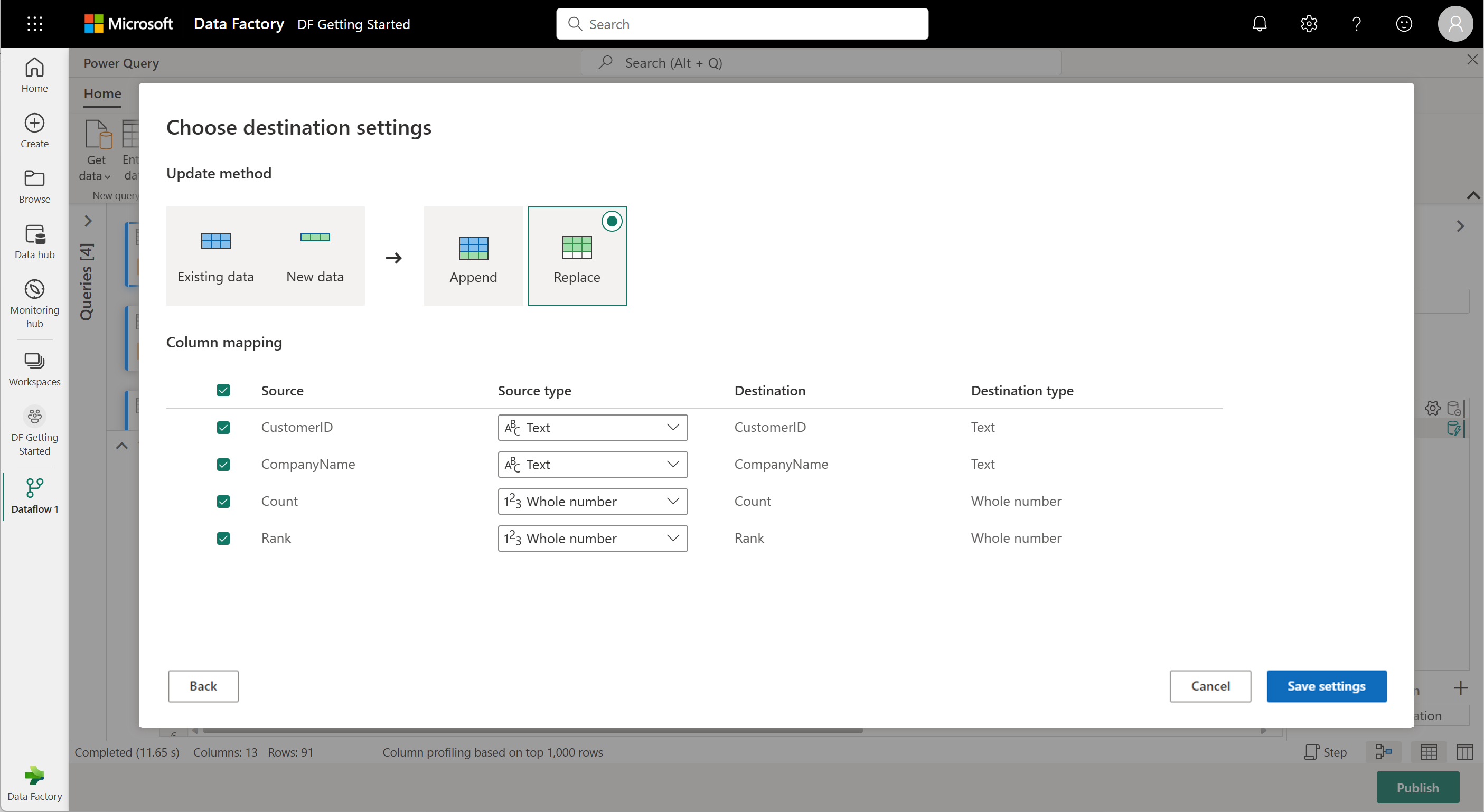
Váš tok dat je teď připravený k publikování. Zkontrolujte dotazy v zobrazení diagramu a pak vyberte Publikovat.
Teď se vrátíte do pracovního prostoru. Ikona číselníku vedle názvu toku dat označuje, že probíhá publikování. Po dokončení publikování je tok dat připravený k aktualizaci.
Důležité
Když se v pracovním prostoru vytvoří první tok dat Gen2, zřídí se položky Lakehouse a Warehouse společně s souvisejícími koncovými body analýzy SQL a sémantickými modely. Tyto položky jsou sdíleny všemi toky dat v pracovním prostoru a jsou nutné, aby tok dat Gen2 fungoval, neměl by být odstraněn a nejsou určeny k přímému použití uživateli. Položky jsou podrobností implementace toku dat Gen2. Položky nejsou v pracovním prostoru viditelné, ale můžou být přístupné v jiných prostředích, jako jsou poznámkové bloky, koncový bod analýzy SQL, Lakehouse a Warehouse. Položky můžete rozpoznat podle jejich předpony v názvu. Předpona položek je DataflowsStaging.
V pracovním prostoru vyberte ikonu Naplánovat aktualizaci .

Zapněte plánovanou aktualizaci, vyberte Přidat jiný čas a nakonfigurujte aktualizaci, jak je znázorněno na následujícím snímku obrazovky.
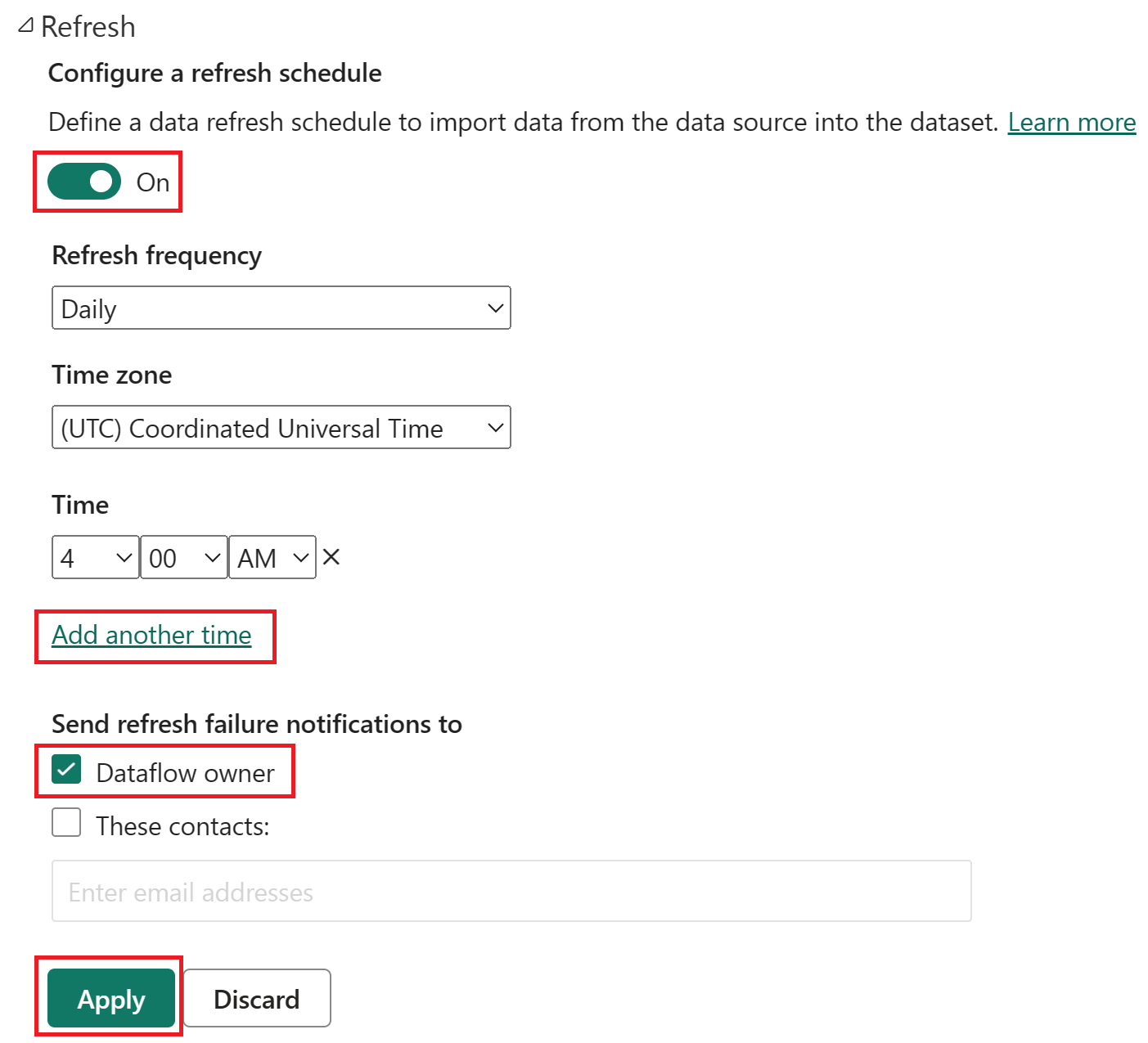
Snímek obrazovky s možnostmi plánované aktualizace se zapnutou plánovanou aktualizací, frekvencí aktualizace nastavenou na Denní, časovým pásmem nastaveným na koordinovaný univerzální čas a časem nastaveným na 4:00 Tlačítko Zapnuto, další výběr času, vlastník toku dat a tlačítko Použít jsou zvýrazněny.













Vyčištění prostředků
Pokud nebudete tento tok dat dál používat, odstraňte tok dat pomocí následujícího postupu:
Přejděte do pracovního prostoru Microsoft Fabric.
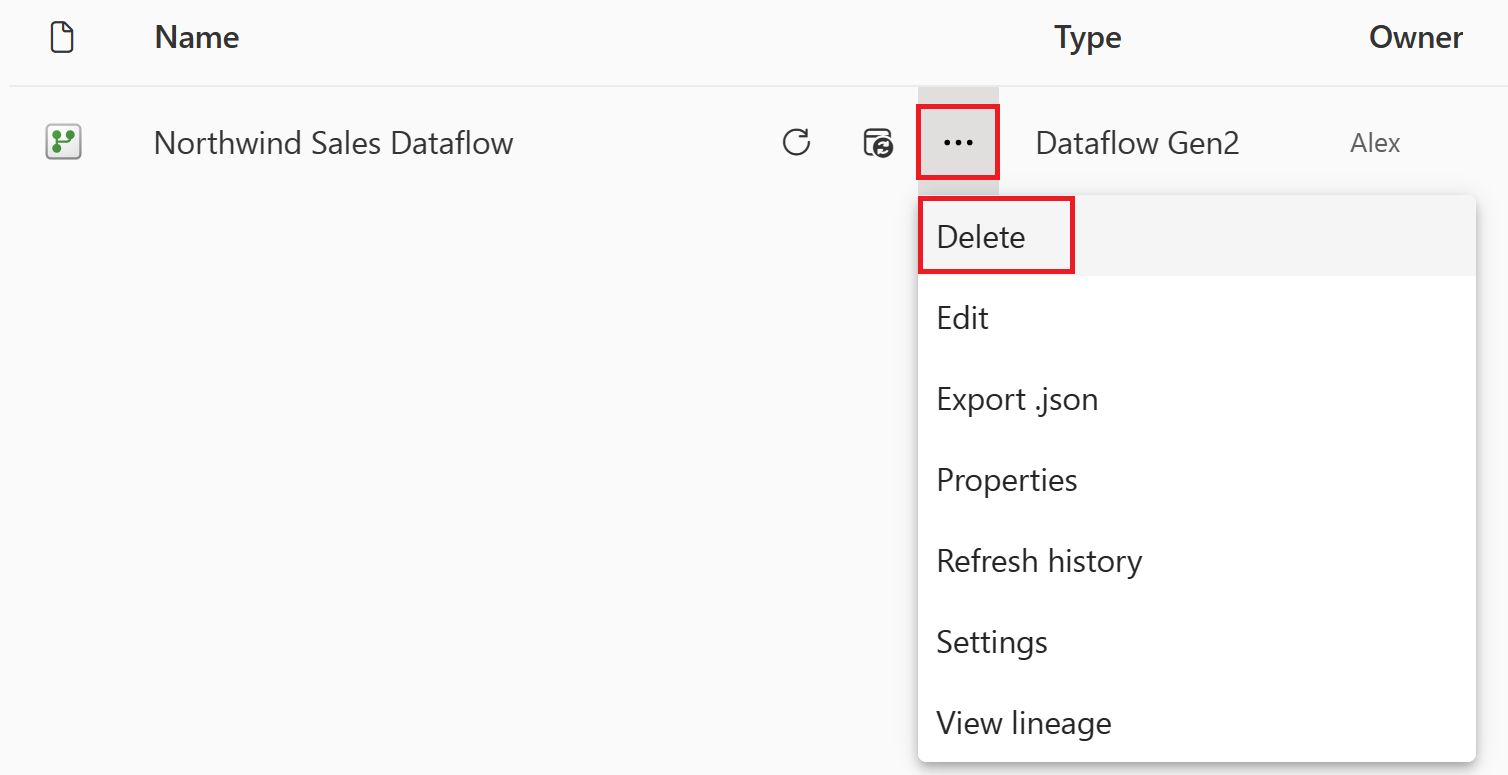
Vyberte svislé tři tečky vedle názvu toku dat a pak vyberte Odstranit.
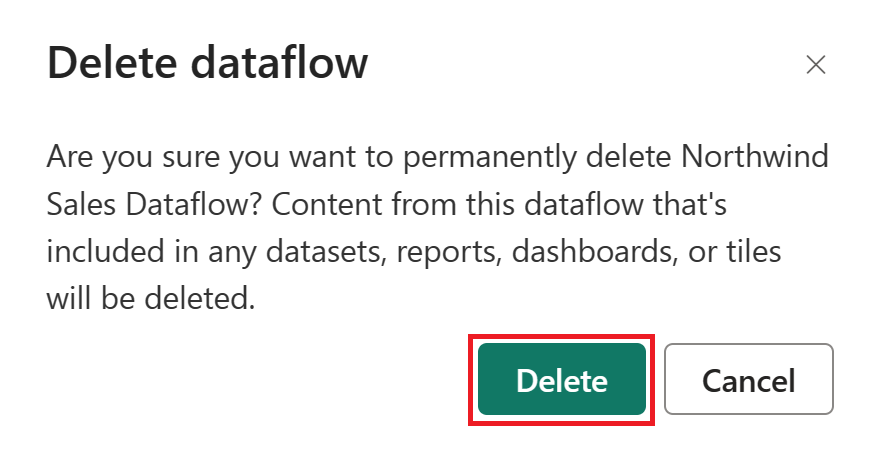
Výběrem možnosti Odstranit potvrďte odstranění toku dat.
Související obsah
Tok dat v této ukázce ukazuje, jak načíst a transformovat data v toku dat Gen2. Naučili jste se:
- Vytvořte tok dat Gen2.
- Transformujte data.
- Nakonfigurujte nastavení cíle pro transformovaná data.
- Spusťte a naplánujte datový kanál.
V dalším článku se dozvíte, jak vytvořit první datový kanál.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro