Principy Analýza textu
Než prozkoumáme možnosti analýzy textu služby Azure AI Language, podíváme se na některé obecné principy a běžné techniky používané k provádění analýzy textu a dalších úloh zpracování přirozeného jazyka (NLP).
Některé z nejstarších technik používaných k analýze textu s počítači zahrnují statistickou analýzu textu ( korpusu) k odvození určitého druhu sémantického významu. Jednoduše řečeno, pokud můžete určit nejčastěji používaná slova v daném dokumentu, můžete často získat dobrou představu o tom, o čem dokument je.
Tokenizace
Prvním krokem při analýze korpusu je rozdělit ho na tokeny. Z důvodu jednoduchosti si můžete představit jednotlivá slova v trénovacím textu jako token, i když ve skutečnosti se tokeny dají generovat pro částečná slova nebo kombinace slov a interpunkce.
Představte si například tuto frázi z slavné amerického prezidenta projevu: "My se rozhodneme přejít na měsíc". Frázi je možné rozdělit na následující tokeny s číselnými identifikátory:
- Jsme
- Zvolte
- na
- go
- prostředek
- Měsíc
Všimněte si, že "komu" (číslo tokenu 3) se v korpusu používá dvakrát. Fráze "my se rozhodneme přejít na měsíc" může být reprezentována tokeny [1,2,3,4,3,5,6].
Poznámka:
Použili jsme jednoduchý příklad, ve kterém jsou tokeny identifikovány pro jednotlivá slova v textu. Zvažte ale následující koncepty, které se můžou vztahovat na tokenizaci v závislosti na konkrétním druhu problému NLP, který se pokoušíte vyřešit:
- Normalizace textu: Před generováním tokenů můžete zvolit normalizaci textu odebráním interpunkce a změnou všech slov na malá písmena. Pro analýzu, která se spoléhá čistě na četnost slov, tento přístup zlepšuje celkový výkon. Nicméně, některé sémantické významy mohou být ztraceny - například zvažte větu "Pan Bank pracoval v mnoha bankách". Možná budete chtít, aby vaše analýza rozlišovala mezi osobou , kterou pan Bank a banky , ve kterých pracoval. Můžete také zvážit "banky", jako samostatný token pro "banky", protože zahrnutí období poskytuje informace, které slovo přichází na konec věty.
- Zastavte odebrání slova. Stop slova jsou slova, která by měla být vyloučena z analýzy. Například "the", "a" nebo "it" usnadňují čtení textu, ale přidávají malý sémantický význam. Když tato slova vyloučíte, řešení analýzy textu může být lépe schopné identifikovat důležitá slova.
- N-gramy jsou fráze s více termíny, například "Mám" nebo "on walked". Jedno slovo fráze je jednogram, dvouslovná fráze je bi-gram, tříslovná fráze je tri gram atd. Když vezmete v úvahu slova jako skupiny, model strojového učení může dávat lepší smysl pro text.
- Stemming je technika, ve které jsou algoritmy použity ke sloučení slov před jejich počítání , takže slova se stejným kořenem, jako je "síla", "napájení" a "výkon", jsou interpretovány jako stejný token.
Analýza četnosti
Po tokenizaci slov můžete provést určitou analýzu, abyste spočítali počet výskytů jednotlivých tokenů. Nejčastěji používaná slova (kromě zastavování slov , jako je "a", "the" atd.), mohou často poskytnout vodítko k hlavnímu předmětu textového korpusu. Například nejběžnější slova v celém textu řeči "přejít na měsíc", která jsme dříve považovali za "nový", "go", "mezera" a "měsíc". Pokud bychom chtěli text tokenizovat jako bi gramy (dvojice slov), nejběžnější bi-gram v řeči je "měsíc". Z těchtoinformacích
Tip
Jednoduchá analýza četnosti, ve které jednoduše spočítáte počet výskytů jednotlivých tokenů, může být efektivní způsob analýzy jednoho dokumentu, ale když potřebujete rozlišovat mezi více dokumenty ve stejném korpusu, potřebujete způsob, jak určit, které tokeny jsou v každém dokumentu nejrelevantní. Frekvence termínů – inverzní frekvence dokumentů (TF-IDF) je běžná technika, při které se počítá skóre na základě toho, jak často se slovo nebo termín vyskytuje v jednom dokumentu ve srovnání s jeho obecnější frekvencí v celé kolekci dokumentů. Při použití této techniky se u slov, která se často objevují v určitém dokumentu, se předpokládá vysoká míra relevance, ale relativně zřídka v celé řadě dalších dokumentů.
Strojové učení pro klasifikaci textu
Další užitečnou technikou analýzy textu je použití klasifikačního algoritmu, jako je logistická regrese, k trénování modelu strojového učení, který klasifikuje text na základě známé sady kategorizací. Běžnou aplikací této techniky je trénování modelu, který klasifikuje text jako pozitivní nebo negativní za účelem provádění analýzy mínění nebo dolování názorů.
Představte si například následující recenze restaurace, které jsou již označeny jako 0 (záporné) nebo 1 (kladné):
- Jídlo a servis byly oba skvělé: 1
- Opravdu hrozný zážitek: 0
- Mmm! chutné jídlo a zábavná vibe1:
- Pomalé služby a nestandardní jídlo: 0
S dostatečným popiskem recenzí můžete klasifikační model trénovat pomocí tokenizovaného textu jako funkcí a mínění (0 nebo 1) popisku. Model zapouzdří vztah mezi tokeny a míněním – například recenze s tokeny pro slova jako "skvělé", "chutné" nebo "zábavné" budou s větší pravděpodobností vrátit mínění 1 (pozitivní), zatímco recenze se slovy jako "hrozná", "pomalá" a "dílčí" se pravděpodobně vrátí 0 (negativní).
Sémantické jazykové modely
Vzhledem k tomu, že stav NLP pokročil, schopnost trénovat modely, které zapouzdřují sémantický vztah mezi tokeny, vedlo ke vzniku výkonných jazykových modelů. Jádrem těchto modelů je kódování tokenů jazyka jako vektorů (pole čísel s více hodnotami), která se označují jako vkládání.
Může být užitečné uvažovat o prvcích vloženého vektoru tokenu jako souřadnice v multidimenzionálním prostoru, aby každý token zabírá konkrétní "umístění". Bližší tokeny jsou mezi sebou podél konkrétní dimenze, tím více sémanticky souvisí. Jinými slovy, související slova jsou seskupené blíž. Jako jednoduchý příklad předpokládejme, že vkládání pro naše tokeny se skládá z vektorů se třemi prvky, například:
- 4 ("pes"): [10.3.2]
- 5 ("kůra"): [10,2,2]
- 8 ("kočka"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
Umístění tokenů můžeme vykreslit na základě těchto vektorů v trojrozměrném prostoru, například takto:
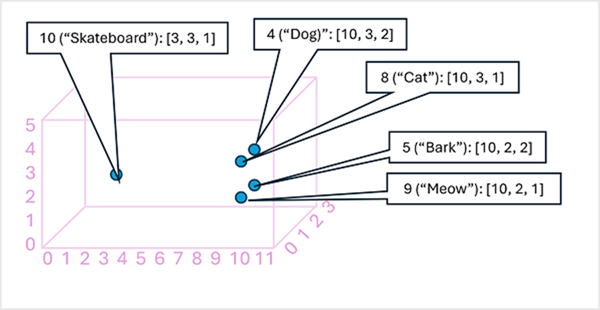
Umístěnítokench Například token pro "pes" je blízko "kočka" a také "kůra". Tokeny pro "kočku" a "kůru" jsou blízko "meow". Token pro "skateboard" je dále daleko od ostatních tokenů.
Jazykové modely, které používáme v odvětví, jsou založené na těchto principech, ale mají větší složitost. Například použité vektory mají mnohem více dimenzí. Existuje také několik způsobů, jak vypočítat vhodné vkládání pro danou sadu tokenů. Různé metody vedou k různým predikcím od modelů zpracování přirozeného jazyka.
Generalizované zobrazení většiny moderních řešení pro zpracování přirozeného jazyka je znázorněno v následujícím diagramu. Velký korpus nezpracovaného textu je tokenizován a používá se k trénování jazykových modelů, které mohou podporovat mnoho různých typů úloh zpracování přirozeného jazyka.
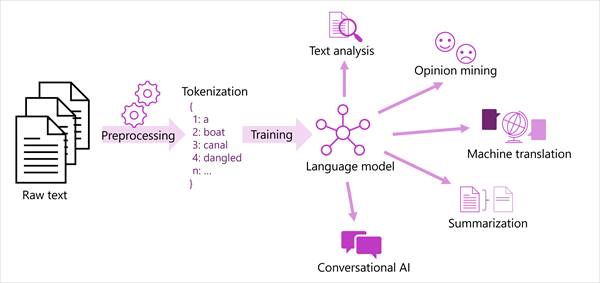
Mezi běžné úlohy NLP podporované jazykovými modely patří:
- Analýza textu, například extrakce klíčových termínů nebo identifikace pojmenovaných entit v textu
- Analýza mínění a dolování názorů pro kategorizaci textu jako kladné nebo záporné.
- Strojový překlad, ve kterém se text automaticky překládá z jednoho jazyka do druhého.
- Shrnutí, ve kterém jsou shrnuty hlavní body velkého textu.
- Konverzační řešení AI, jako jsou roboti nebo digitální asistenti, ve kterých jazykový model dokáže interpretovat vstup v přirozeném jazyce a vrátit odpovídající odpověď.
Tyto funkce a další funkce podporují modely ve službě Azure AI Language, kterou prozkoumáme dále.