Konfigurace škálovací sady virtuálních počítačů
Při škálování přidáte instance do škálovací sady virtuálních počítačů. Ve scénáři přepravní společnosti je škálování dobrým způsobem, jak zvládnout měnící se počet požadavků v průběhu času. Škálování upravuje počet virtuálních počítačů, na kterých běží webová aplikace, podle toho, jak se mění počet uživatelů. Systém tak má stálou dobu odezvy bez ohledu na aktuální zatížení.
V této lekci se dozvíte, jak škálovat škálovací sadu virtuálních počítačů. Škálování můžete provést ručně explicitním nastavením počtu instancí virtuálních počítačů ve škálovací sadě nebo můžete nakonfigurovat automatické škálování definováním pravidel škálování, která aktivují přidělení a zrušení přidělení virtuálních počítačů. Tato pravidla škálování pomocí monitorování různých výkonnostních metrik určují, kdy se systém má škálovat.
Ruční škálování Virtual Machine Scale Sets
Škálovací sadu virtuálních počítačů škálujete ručně zvýšením nebo snížením počtu instancí. Tuto úlohu můžete provést programově nebo přes Azure Portal.
Následující kód pomocí Azure CLI změní počet instancí ve škálovací sadě virtuálních počítačů:
az vmss scale \
--name MyVMScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Virtual Machine Scale Sets automatického škálování
Ruční škálování je za určitých okolností užitečné. V mnoha situacích je ale lepší použít automatické škálování. Díky němu může systém řídit počet instancí ve škálovací sadě.
Můžete použít tyto typy automatického škálování:
- Na základě plánu: Tento přístup použijte, pokud víte, že v určité datum nebo během určitého časového období budete čelit zvýšenému zatížení.
- Na základě metrik: Škálování se upravuje pomocí monitorování výkonnostních metrik spojených se škálovací sadou. Pokud tyto metriky překročí zadanou prahovou hodnotu, může škálovací sada automaticky spustit nové instance virtuálních počítačů. Pokud metriky signalizují, že tyto další prostředky už nejsou potřeba, může škálovací sada všechny nadbytečné instance zastavit.
Definování podmínek, pravidel a limitů automatického škálování
Automatické škálování je založené na množině podmínek, pravidel a limitů škálování. Podmínka škálování kombinuje čas a sadu pravidel škálování. Pokud aktuální čas spadá do období definovaného v podmínce škálování, vyhodnotí se pravidla škálování v této podmínce. Výsledek tohoto vyhodnocení určuje, jestli se ve škálovací sadě mají přidat nebo odebrat instance. Podmínka škálování definuje také limity škálování určující maximální a minimální počet instancí.
Ve scénáři přepravní společnosti můžete přidat pravidla škálování, která monitorují využití procesoru ve škálovací sadě. Pokud využití procesoru překročí prahovou hodnotu 75 %, navýší pravidlo škálování počet instancí virtuálních počítačů. Druhé pravidlo škálování může také monitorovat využití procesoru, ale snížit počet instancí virtuálních počítačů, když využití klesne pod 50 procent. Vzhledem k tomu, že aplikace je globální, by tato pravidla měla být aktivní neustále, nikoli jen v určitých hodinách.
Škálovací sada virtuálních počítačů může obsahovat mnoho podmínek škálování. Při každé shodující se podmínce škálování se provede nějaká akce. Škálovací sada může obsahovat také výchozí podmínku škálování, která se použije v případě, kdy se aktuální čas a výkonnostní metriky neshodují s žádnými jinými podmínkami škálování. Tato výchozí podmínka škálování je trvale aktivní. Neobsahuje žádná pravidla škálování a funguje jako podmínka škálování s hodnotou null , která neuvádí horizontální snížení nebo snížení kapacity. Můžete ale upravit výchozí podmínku škálování a nastavit výchozí počet instancí nebo můžete přidat dvojici pravidel škálování, která horizontální navýšení a opětovné snížení kapacity.
Použití automatického škálování na základě plánu
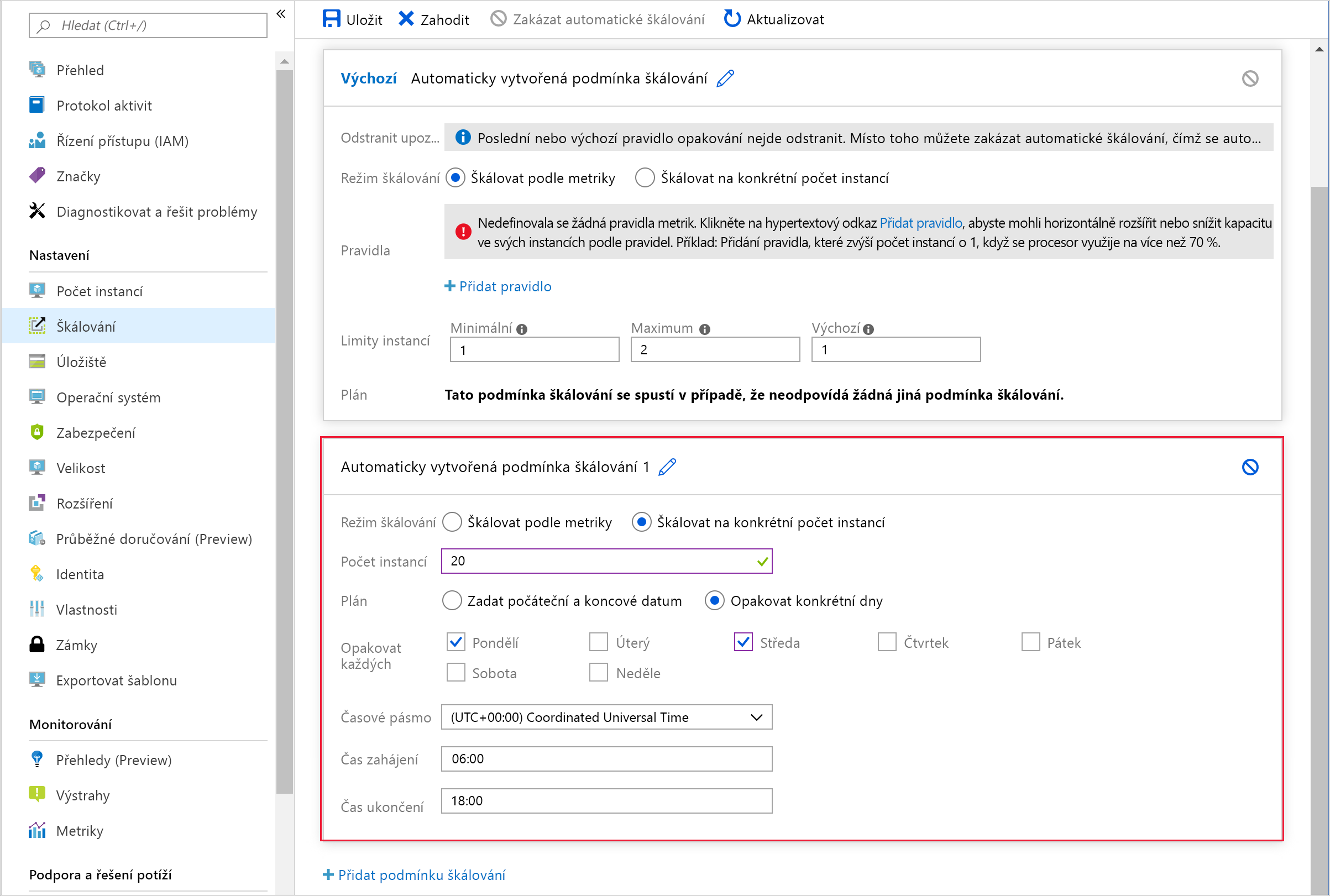
Škálování na základě plánu určuje počáteční a koncový čas a počet instancí, které se mají do škálovací sady přidat. Následující snímek obrazovky ukazuje příklad na webu Azure Portal. Počet instancí se každé pondělí a středu mezi 6:00 a 18:00 horizontálně rozšíří na 20. Pokud neexistují žádné jiné podmínky škálování, pak se mimo tyto časy použije výchozí podmínka škálování.
V tomto případě bude výchozí pravidlo systém škálovat zpět na dvě instance. Jedná se o hodnotu Maximum v této výchozí podmínce škálování.
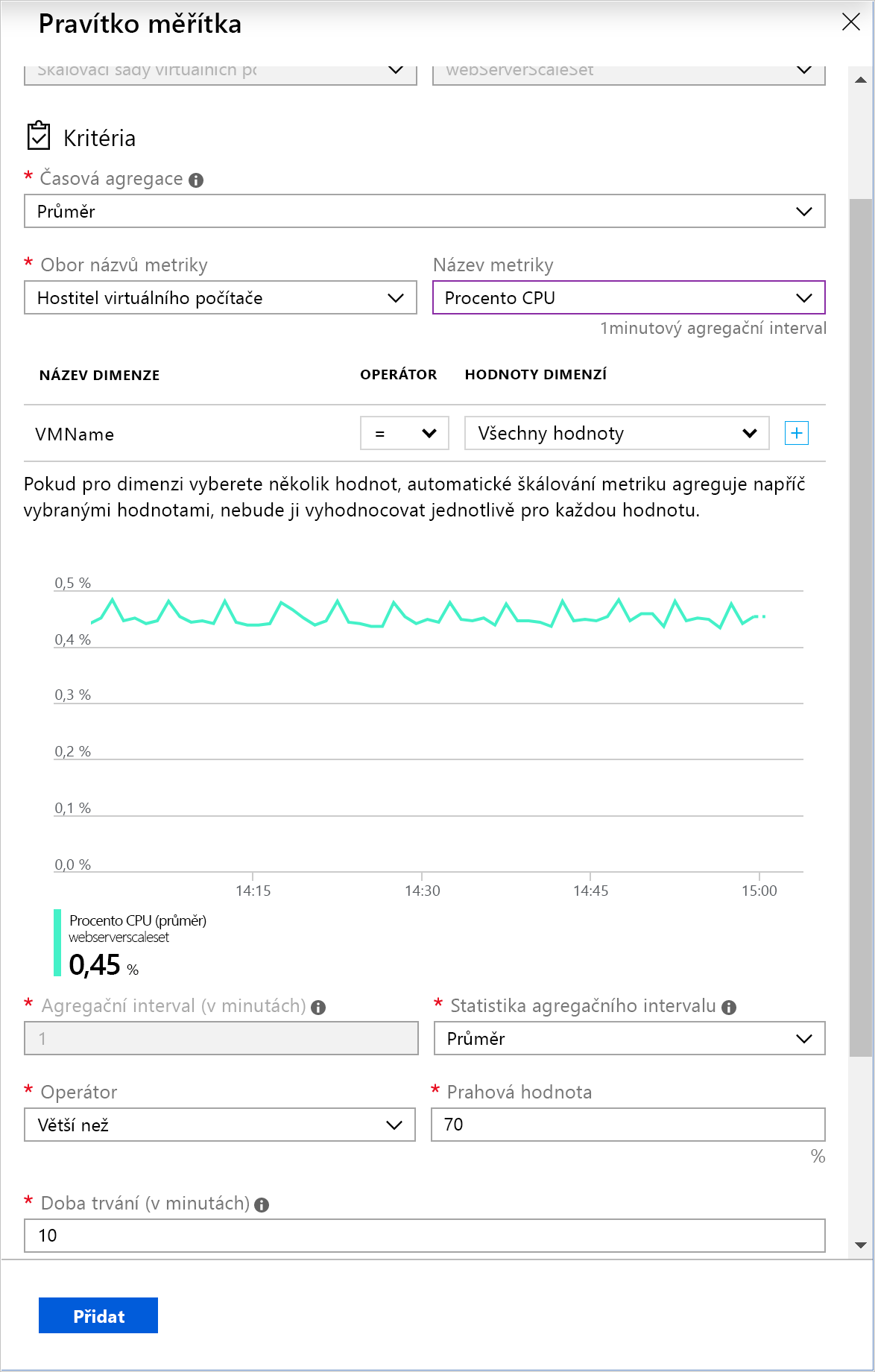
Použití automatického škálování na základě metrik
Pravidlo škálování na základě metrik určuje prostředky, které se mají monitorovat, jako je využití procesoru nebo doba odezvy. Toto pravidlo škálování přidává nebo odebírá instance ze škálovací sady podle hodnot těchto metrik. Můžete určit omezení počtu instancí, abyste zabránili nadměrnému horizontálnímu snížení nebo snížení kapacity škálovací sady.
V tomto ukázkovém scénáři chcete zvýšit počet instancí o jednu, když průměrné využití procesoru překročí 75 %. Kromě toho chcete operaci horizontálního rozšíření kapacity omezit na 50 instancí. Tento limit pomůže zabránit nákladnému a neovladatelnému škálování způsobenému útokem. Podobně chcete horizontálně snížit kapacitu, když průměrné využití procesoru klesne pod 50 %.
Tyto metriky se běžně používají k monitorování škálovací sady virtuálních počítačů:
- Procento CPU: Tato metrika udává využití procesoru ve všech instancích. Vysoká hodnota značí, že instance začínají být vázané na procesor, což by mohlo pozdržet zpracování žádostí klientů.
- Příchozí toky a Odchozí toky: Tyto metriky udávají rychlost, s jakou síťový provoz vstupuje do a vystupuje z virtuálních počítačů ve škálovací sadě.
- Čtení z disku – operace/s a Zápis na disk – operace/s: Tyto metriky udávají počet vstupně-výstupních operací disku ve škálovací sadě.
- Hloubka fronty datového disku: Tato metrika udává počet vstupně-výstupních žádostí jen vůči datovým diskům na virtuálních počítačích, které čekají na obsloužení.
Pravidlo škálování agreguje hodnoty metriky získané pro všechny instance. Agreguje hodnoty za časové období označované jako agregační interval. Každá metrika má vnitřní agregační interval, ale obvykle je toto období jedna minuta. Agregovaná hodnota se označuje jako časová agregace. Možnostmi pro časovou agregaci jsou Průměr, Minimum, Maximum, Součet, Poslední a Počet.
Jednominutový interval je velmi krátký na to, abyste zjistili, jestli budou změny metriky trvat dostatečně dlouho, aby bylo vhodné provést automatické škálování. Pravidlo škálování provede druhý krok, který dále agreguje hodnotu časové agregace pro delší, uživatelem zadanou dobu. Tato doba se označuje jako doba trvání. Minimální doba trvání je pět minut. Pokud je doba trvání nastavená například na 10 minut, agreguje pravidlo škálování 10 hodnot vypočítaných pro agregační interval.
Výpočet agregace pro dobu trvání se může lišit od výpočtu pro agregační interval. Předpokládejme například, že časová agregace je Průměr a shromážděná statistika je Procento CPU v jednominutovém agregačním intervalu. Pro každou minutu se vypočítá průměrné procento využití procesoru napříč všemi instancemi během dané minuty. Pokud je statistika agregačního intervalu nastavena na Maximum a doba trvání pravidla je nastavena na 10 minut, použije se ke zjištění toho, jestli byla překročena prahová hodnota pravidla, maximum 10 průměrných hodnot využití procesoru.
Když pravidlo škálování zjistí, že metrika překročila prahovou hodnotu, provede akci škálování. Touto akcí může být horizontální rozšíření kapacity nebo horizontální snížení kapacity. Akce horizontálního rozšíření kapacity počet instancí zvyšuje. Akce horizontálního snížení kapacity jejich počet snižuje.
Akce škálování při určování toho, jak reagovat na prahovou hodnotu, používá operátor, například menší než, větší než nebo rovno. Akce horizontálního rozšíření kapacity zpravidla k porovnání hodnoty metriky s prahovou hodnotou používají operátor větší než. Akce horizontálního snížení kapacity většinou porovnávají hodnotu metriky s prahovou hodnotou pomocí operátoru menší než. Akce škálování také nastavuje počet instancí na konkrétní úroveň, a nezvyšuje ani nesnižuje počet dostupných instancí.
Akce škálování má dobu přestávky určenou v minutách. Během této doby se pravidlo škálování znovu neaktivuje. Tato přestávka umožňuje systém mezi událostmi škálování stabilizovat. Spuštění nebo vypnutí instancí chvíli trvá, takže shromážděné metriky nemusí po několik minut vykazovat žádné zásadní změny. Minimální doba přestávky je pět minut.
Nakonec byste měli naplánovat horizontální snížení kapacity při snížení zatížení. V jedné podmínce škálování je vhodné definovat dvojici pravidel škálování. Jedno pravidlo škálování by mělo udávat, jak horizontálně navýšit kapacitu systému, když metrika překročí horní prahovou hodnotu. Druhé pravidlo musí definovat, jak systém škálovat zpět, když stejná metrika klesne pod dolní prahovou hodnotu. Nenastavujte obě prahové hodnoty na stejný údaj. V opačném případě byste mohli aktivovat řadu oscilačních událostí, které kapacitu vertikálně navyšují a zase zvětšují.
Následující obrázek ukazuje pravidlo škálování definované na webu Azure Portal.