Jak HDInsight funguje
HDInsight je systém pro zpracování dat distribuovaný v cloudu, který je ve výchozím nastavení vysoce dostupný a zabezpečený. Jádrem tohoto systému je Apache Hadoop. Apache Hadoop obsahuje dvě základní komponenty: Apache Hadoop Distributed File System (HDFS), který se používá pro úložiště, a Apache Hadoop Yet Another Resource Negotiator (YARN), který poskytuje zpracování. Kromě toho je jednoduchý programovací model MapReduce, který umožňuje zpracovávat a analyzovat data. Výhody použití MapReduce jsou, že je snadné nastavit a můžete řídit náklady prostřednictvím funkce automatického škálování.
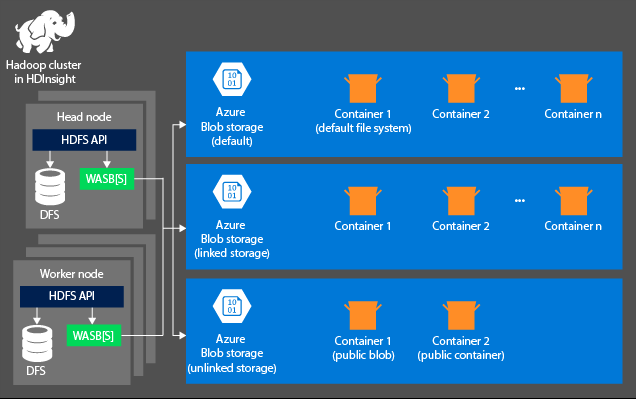
Úložiště
Aspekt úložiště se při zřizování clusteru HDInsight nevytvořil automaticky. Místo toho ho poskytuje systém kompatibilní s HDFS, jako je Azure Storage nebo Azure Data Lake. Oddělení úložiště od vrstvy zpracování umožňuje bezpečně odstranit clustery HDInsight, které se používají k výpočtu bez ztráty uživatelských dat. Při přidávání clusteru HDInsight musíte definovat výchozí systém souborů. Podle potřeby můžete propojit a zrušit propojení systémů souborů, abyste zvětšili velikost úložiště.
Následující informace jsou specifické pro HDInsight 3.6 a vyšší. Během procesu vytváření clusteru HDInsight můžete jako výchozí systém souborů vybrat Azure Storage nebo Azure Data Lake Storage Gen2 s několika výjimkami. Poskytnutí výchozího systému souborů zajišťuje, aby při hledání souborů bylo možné přeložit relativní odkazy na soubory. Pro Azure Storage byste měli jako výchozí systém souborů zadat kontejner objektů blob.
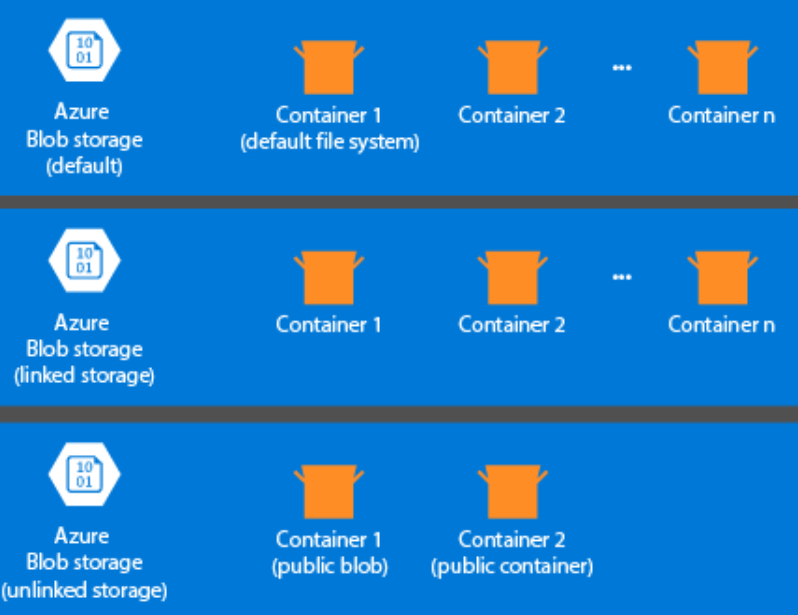
Většina nastavení používá Azure Data Lake Storage Gen2. Tento typ nastavení používá základní funkce systému souborů, které jsou kompatibilní se systémem Hadoop, integrací Microsoft Entra a seznamy řízení přístupu na základě POSIX (ACL). Azure Blob Storage můžete použít pro zpětnou kompatibilitu, ale důrazně doporučujeme používat Azure Data Lake Storage Gen2, kdykoli je to možné.
Zpracování
Při zpracování dat se výpočetní aspekt clusteru Hadoop ve službě HDInsight rozdělí do dvou logických oblastí. Hlavní (hlavní) uzly a pracovní uzly Hlavní uzel (hlavní) zodpovídá za příjem a správu požadavků klientů a následné předání žádosti pracovním uzlům, aby bylo možné zpracovávat data. Obvykle existují dva hlavní uzly. Aktivní hlavní uzel, který bude spravovat připojení klientů. Druhý pasivní hlavní uzel, který zajišťuje odolnost v případě, že primární uzel by se měl stát offline.
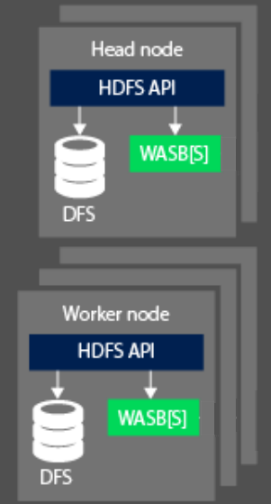
Pracovní uzel zodpovídá za zpracování dat přiřazených hlavním uzlem. Spravovaná data závisí na tom, jak programovací model MapReduce definoval způsob práce s daty a jak hlavní uzel přiděluje práci. Hlavní i pracovní uzel se můžou připojit buď přímo k místně připojenému distribuovanému systému souborů (DFS), nebo přistupovat k datům uloženým v Azure Blob nebo Azure Data Lake.
Z pohledu OSS provádí YARN možnosti správy prostředků clusteru HDInsight. Tato služba spravuje prostředky a plánování úloh, které se provádějí při zpracování dat. Nachází se mezi HDFS a výpočetním systémem clusteru HDInsight. Služba spolupracuje s dalšími technologiemi operačního systému a zajišťuje, aby prostředky pro zpracování úlohy HDInsight byly k dispozici. YARN spolupracuje s hlavním uzlem a distribuuje úlohu mezi pracovní uzly clusteru, aby se zajistilo, že se úlohy zpracování dat paralelizují.
HDFS, YARN a MapReduce jsou tři základní služby vyžadované pro Hadoop ve službě HDInsight. Obvykle se používají další technologie OSS, které usnadňují vytváření řešení. Hive můžete například použít jako abstraktní vrstvu. Ten, který se nachází nad MapReduce, abyste mohli psát konstruktory jazyka typu SQL pro provádění ad hoc zpracování a analýzy dat. Nebo můžete použít Apache Ambari k monitorování clusteru HDInsight.