Použití Pythonu v Editor Power Query
V power BI Desktopu Editor Power Query můžete použít Python, programovací jazyk široce používaný statistiky, datovými vědci a datovými analytiky. Tato integrace Pythonu do Editor Power Query umožňuje provádět čištění dat pomocí Pythonu a provádět pokročilé formování a analýzy dat v datových sadách, včetně dokončování chybějících dat, předpovědí a clusteringu, a to jen pro několik názvů. Python je výkonný jazyk a dá se použít v Editor Power Query k přípravě datového modelu a vytváření sestav.
Předpoklady
Než začnete, budete muset nainstalovat Python a knihovnu pandas.
Nainstalujte Python – Pokud chcete používat Python v Editor Power Query Power BI Desktopu, musíte python nainstalovat na místní počítač. Python si můžete stáhnout a nainstalovat zdarma z mnoha míst, včetně oficiální stránky pro stažení Pythonu a Anaconda.
Instalace knihovny pandas – Pokud chcete používat Python s Editor Power Query, budete také muset nainstalovat knihovnu pandas. Pandas se používá k přesouvání dat mezi Power BI a prostředím Pythonu.
Použití Pythonu s Editor Power Query
Pokud chcete ukázat, jak používat Python v Editor Power Query, podívejte se na tento příklad z datové sady burzovního trhu na základě souboru CSV, který si tady můžete stáhnout, a postupovat podle toho. Kroky pro tento příklad jsou následující postup:
Nejprve načtěte data do Power BI Desktopu. V tomto příkladu načtěte soubor EuStockMarkets_NA.csv a z pásu karet Domů v Power BI Desktopu vyberte Získat datový>text/CSV.
Vyberte soubor a vyberte Otevřít a sdílený svazek clusteru se zobrazí v dialogovém okně soubor CSV.
Po načtení dat se zobrazí v podokně Pole v Power BI Desktopu.
Otevřete Editor Power Query výběrem možnosti Transformovat data na kartě Domů v Power BI Desktopu.
Na kartě Transformace vyberte Spustit skript Pythonu a zobrazí se editor skriptů Spustit python, jak je znázorněno v dalším kroku. Řádky 15 a 20 trpí chybějícími daty, stejně jako ostatní řádky, které nevidíte na následujícím obrázku. Následující kroky ukazují, jak Python tyto řádky dokončí za vás.
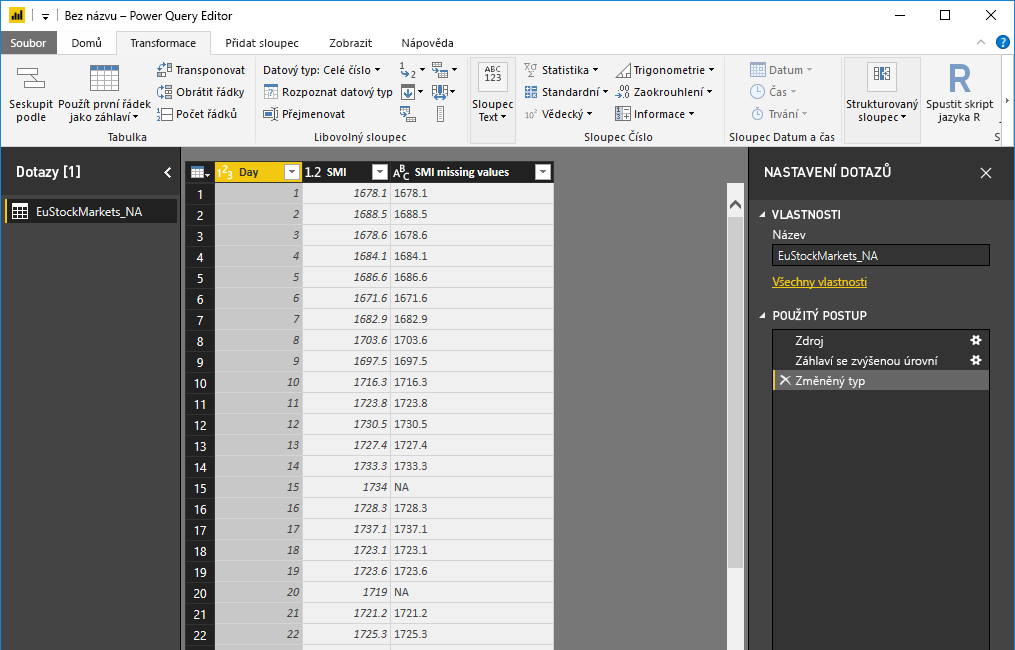
V tomto příkladu zadejte následující kód skriptu:
import pandas as pd completedData = dataset.fillna(method='backfill', inplace=False) dataset["completedValues"] = completedData["SMI missing values"]Poznámka
Aby předchozí kód skriptu fungoval správně, musíte mít ve svém prostředí Pythonu nainstalovanou knihovnu pandas . Pokud chcete nainstalovat knihovnu pandas, spusťte v instalaci Pythonu následující příkaz:
pip install pandasPři vložení do dialogového okna Spustit skript Pythonu vypadá kód jako v následujícím příkladu:
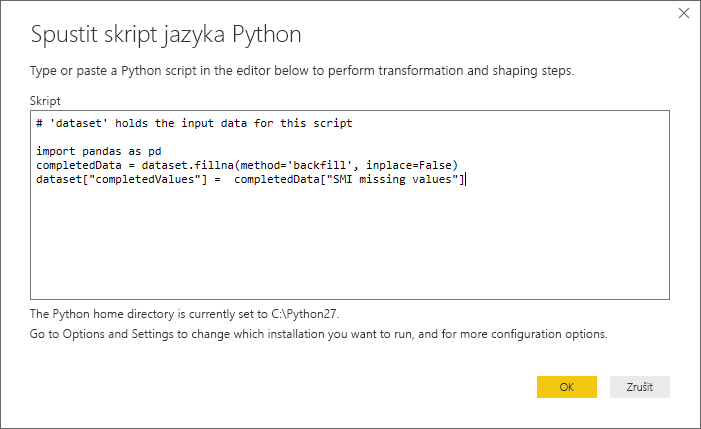
Po výběru možnosti OK Editor Power Query zobrazí upozornění na ochranu osobních údajů.
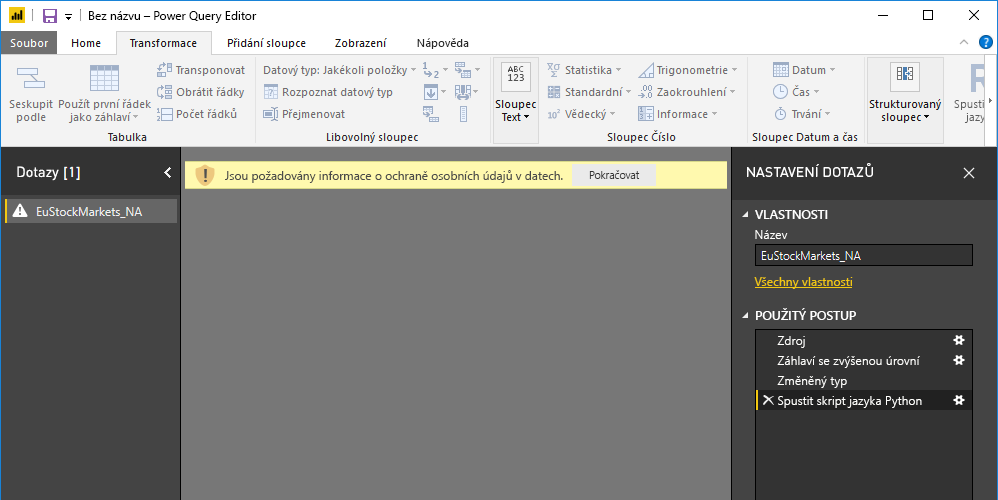
Aby skripty Pythonu správně fungovaly v služba Power BI, musí být všechny zdroje dat nastavené na veřejné. Další informace o nastavení ochrany osobních údajů a jejich dopadech najdete v tématu Úrovně ochrany osobních údajů.
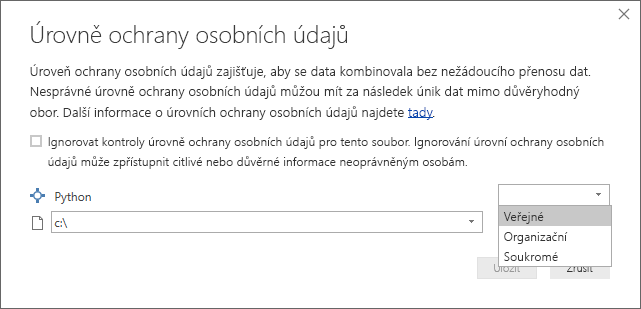
Všimněte si nového sloupce v podokně Pole s názvem completedValues. Všimněte si, že chybí několik datových prvků, například na řádku 15 a 18. Podívejte se, jak python to zpracovává v další části.
S pouhými třemi řádky skriptu Pythonu Editor Power Query vyplněné chybějícími hodnotami prediktivním modelem.
Vytváření vizuálů z dat skriptu Pythonu
Teď můžeme vytvořit vizuál, abychom viděli, jak kód skriptu Pythonu pomocí knihovny pandas dokončil chybějící hodnoty, jak je znázorněno na následujícím obrázku:
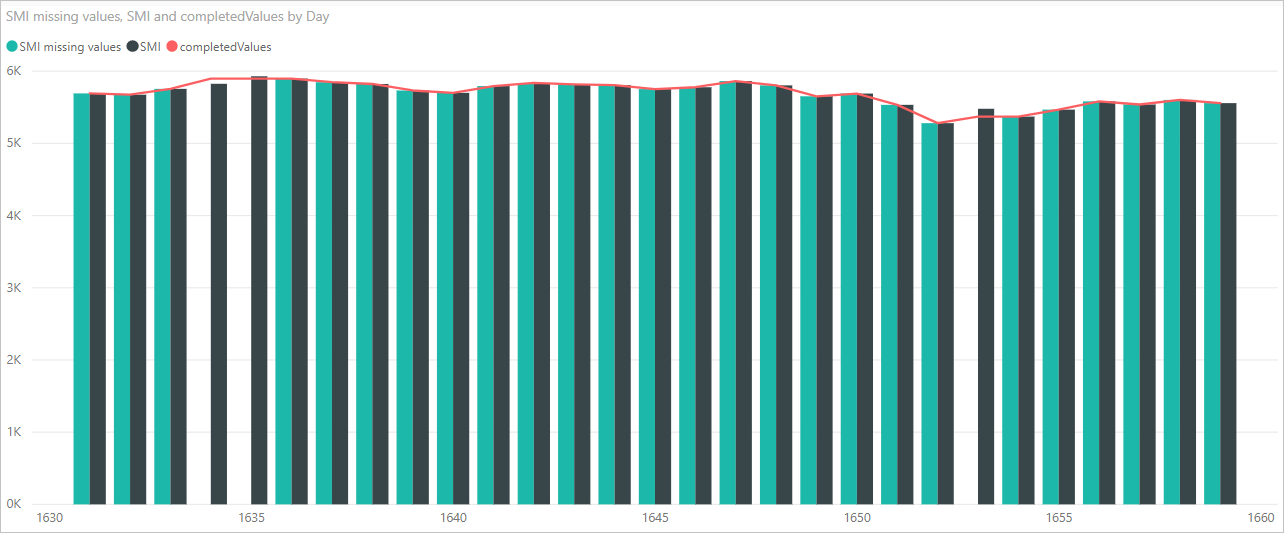
Po dokončení vizuálu a všech dalších vizuálů, které můžete chtít vytvořit pomocí Power BI Desktopu, můžete soubor Power BI Desktopu uložit. Soubory Power BI Desktopu se ukládají s příponou názvu souboru .pbix . Pak použijte datový model, včetně skriptů Pythonu, které jsou jeho součástí, v služba Power BI.
Poznámka
Chcete zobrazit dokončený soubor .pbix s těmito kroky? Máš štěstí. Dokončený soubor Power BI Desktopu použitý v těchto příkladech si můžete stáhnout přímo tady.
Po nahrání souboru .pbix do služba Power BI je potřeba provést několik dalších kroků, abyste umožnili aktualizaci dat ve službě a umožnili aktualizaci vizuálů ve službě. Data potřebují přístup k Pythonu, aby se vizuály aktualizovaly. Další kroky jsou následující:
- Povolte plánovanou aktualizaci pro datovou sadu. Pokud chcete povolit plánovanou aktualizaci sešitu, který obsahuje datovou sadu se skripty Pythonu, přečtěte si téma Konfigurace plánované aktualizace, která obsahuje také informace o osobní bráně.
- Nainstalujte osobní bránu. Na počítači, kde se soubor nachází, a kde je nainstalovaný Python, potřebujete nainstalovanou osobní bránu . Služba Power BI musí přistupovat k danému sešitu a znovu vykreslit všechny aktualizované vizuály. Další informace najdete v tématu Instalace a konfigurace osobní brány.
Úvahy a omezení
Dotazy, které obsahují skripty Pythonu vytvořené v Editor Power Query, mají určitá omezení:
Všechna nastavení zdroje dat Pythonu musí být nastavená na Veřejné a všechny další kroky v dotazu vytvořeném v Editor Power Query musí být také veřejné. Pokud se chcete dostat k nastavení zdroje dat, v Power BI Desktopu vyberte Možnosti souboru > a nastavení> Zdroje dat.
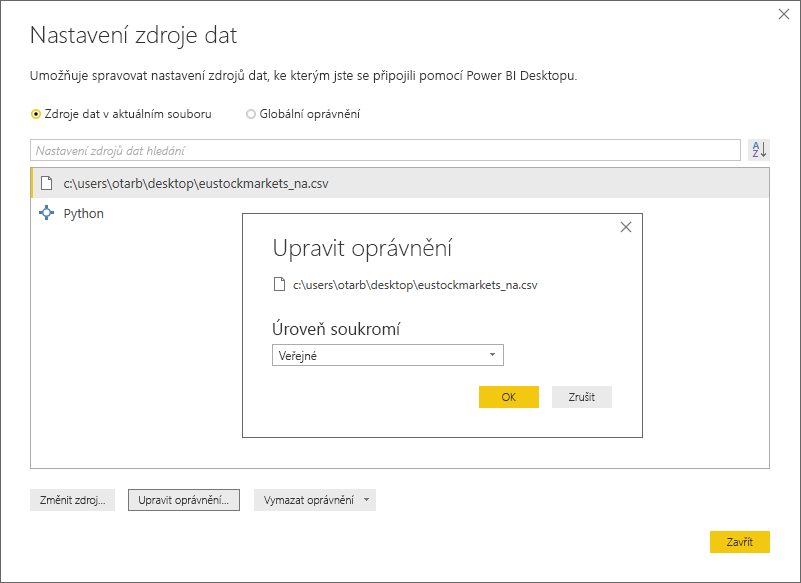
V dialogovém okně Zdroj dat Nastavení vyberte zdroje dat a pak vyberte Upravit oprávnění... a ujistěte se, že je úroveň ochrany osobních údajů nastavená na Veřejná.
Pokud chcete povolit plánovanou aktualizaci vizuálů nebo datových sad Pythonu, musíte povolit plánovanou aktualizaci a mít nainstalovanou osobní bránu na počítači, ve kterém je sešit a instalace Pythonu. Další informace o obou najdete v předchozí části tohoto článku, který obsahuje odkazy na další informace o jednotlivých částech.
Vnořené tabulky, které jsou tabulkou tabulek, se v současné době nepodporují.
S Pythonem a vlastními dotazy můžete dělat nejrůznější věci, takže data můžete zkoumat a tvarovat tak, jak chcete, aby se zobrazovala.