Vzorkování s vysokou hustotou v bodových grafech Power BI
Algoritmus vzorkování Power BI zlepšuje způsob, jakým bodové grafy představují data s vysokou hustotou.
Můžete například vytvořit bodový graf z prodejní aktivity vaší organizace, přičemž každý obchod má každý rok desítky tisíc datových bodů. Bodový graf těchto informací by vzorkoval data ze smysluplného znázornění těchto dat, aby ilustroval, jak došlo k prodeji v průběhu času. Podrobnosti o vzorkování dat s vysokou hustotou jsou popsány v tomto článku.

Poznámka:
Algoritmus vzorkování s vysokou hustotou popsaný v tomto článku je k dispozici v bodových grafech pro Power BI Desktop i pro služba Power BI.
Jak fungují bodové grafy s vysokou hustotou
Power BI dříve vybral kolekci ukázkových datových bodů v celé oblasti podkladových dat deterministickým způsobem, aby se vytvořil bodový graf. Power BI konkrétně vybere první a poslední řádky dat v řadě bodového grafu a zbývající řádky rovnoměrně rozdělí tak, aby se na bodovém grafu vykreslí celkem 3 500 datových bodů. Pokud by například vzorek měl 35 000 řádků, byly by pro vykreslení vybrány první a poslední řádky, pak by se vykresloval také každý desátý řádek (35 000 / 10 = každý desátý řádek = 3 500 datových bodů). Hodnoty null nebo body, které se nedaly vykreslit, například textové hodnoty, se také v datových řadách nezobzorovaly, a proto se při generování vizuálu nezohlednily. Při takovém vzorkování byla vnímaná hustota bodového grafu založená také na reprezentativních datových bodech, takže implicitní vizuální hustota byla okolnosti výběru bodů, nikoli úplné shromažďování podkladových dat.
Když povolíte vzorkování s vysokou hustotou, Power BI implementuje algoritmus, který eliminuje překrývající se body a zajistí, že body ve vizuálu budou při interakci s vizuálem dosažitelné. Algoritmus také zajišťuje, aby všechny body v datové sadě byly ve vizuálu reprezentovány a poskytovaly kontext významu vybraných bodů, a ne pouze vykreslování reprezentativního vzorku.
Podle definice se data s vysokou hustotou vzorkují a vytvářejí vizualizace, které reagují na interaktivitu. Příliš mnoho datových bodů ve vizuálu může zpomalit a odhloudit viditelnost trendů. Způsob vzorkování dat řídí vytvoření algoritmu vzorkování, aby poskytoval nejlepší prostředí pro vizualizaci a zajistilo, že jsou všechna data reprezentována. V Power BI je algoritmus vylepšený tak, aby poskytoval nejlepší kombinaci odezvy, reprezentace a zachování důležitých bodů v celkové sadě dat.
Poznámka:
Bodové grafy používající algoritmus vzorkování s vysokou hustotou se nejlépe vykreslují na čtvercových vizuálech, stejně jako u všech bodových grafů.
Jak funguje algoritmus vzorkování bodového grafu
Algoritmus vzorkování s vysokou hustotou pro bodové grafy využívá metody, které zachycují a představují podkladová data efektivněji a eliminují překrývající se body. Algoritmus začíná malým poloměrem pro každý datový bod, což je velikost vizuálního kruhu pro daný bod ve vizualizaci. Pak zvětší poloměr všech datových bodů. Pokud se dva nebo více datových bodů překrývají, představuje jeden kruh zvýšené velikosti poloměru tyto překrývající se datové body. Algoritmus dál zvyšuje poloměr datových bodů, dokud výsledkem této hodnoty poloměru není přiměřený počet datových bodů (3 500), které se zobrazují v bodovém grafu.
Metody v tomto algoritmu zajišťují, že jsou ve výsledném vizuálu reprezentovány odlehlé hodnoty. Algoritmus při určování překrývajících se také respektuje měřítko, aby exponenciální měřítka byla vizualizována s přesností na podkladové vizualizované body.
Algoritmus také zachovává celkový tvar bodového grafu.
Poznámka:
Při použití algoritmu vzorkování s vysokou hustotou pro bodové grafy je cílem přesné rozdělení dat, nikoli implicitní vizuální hustota. Můžete například vidět bodový graf se spoustou kruhů, které se překrývají (hustota) v určité oblasti a představte si, že se tam musí shlukutět mnoho datových bodů. Vzhledem k tomu, že algoritmus vzorkování s vysokou hustotou může použít jeden kruh k reprezentaci mnoha datových bodů, implicitní vizuální hustota nebo "clustering" se nezobrazí. Pokud chcete získat podrobnější informace v dané oblasti, můžete k přiblížení použít průřezy.
Kromě toho jsou datové body, které nelze vykreslit, jako jsou hodnoty null nebo textové hodnoty, ignorovány, takže je vybrána další hodnota, kterou lze vykreslit. Tím se dále zajistí zachování skutečného tvaru bodového grafu.
Při použití standardního algoritmu pro bodové grafy
Za okolností se vzorkování s vysokou hustotou nedá použít na bodový graf a použije se původní algoritmus. Tyto okolnosti jsou:
Pokud kliknete pravým tlačítkem myši na hodnotu v části Hodnoty a nastavíte ji tak, aby zobrazovala položky bez dat z nabídky, bodový graf se vrátí k původnímu algoritmu.
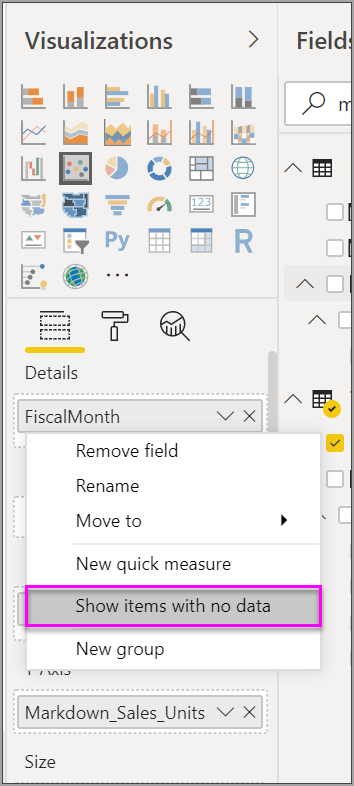
Všechny hodnoty v poli Osa přehrávání způsobí, že se bodový graf vrátí k původnímu algoritmu.
Pokud v bodovém grafu chybí osy X i Y, graf se vrátí k původnímu algoritmu.
Když v podokně Analýza použijete čáru poměru, graf se vrátí k původnímu algoritmu.

Zapnutí vzorkování s vysokou hustotou pro bodový graf
Pokud chcete přepnout vzorkování s vysokou hustotou na Zapnuto, vyberte bodový graf, přejděte do podokna Formát vizuálu , rozbalte kartu Obecné a v dolní části této karty posuňte posuvník vzorkování s vysokou hustotou na zapnuto.
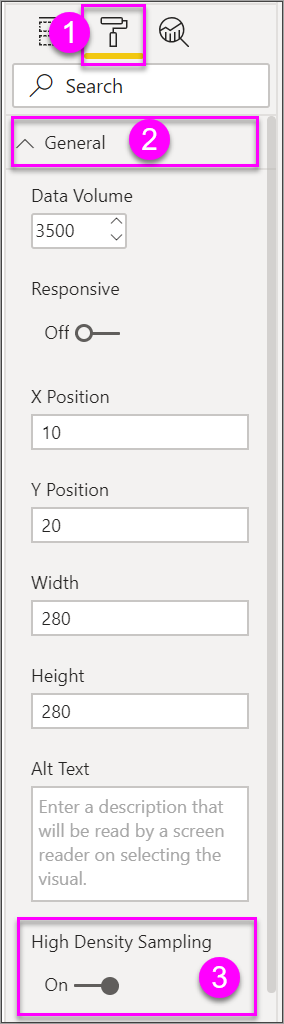
Poznámka:
Po zapnutí přepínače se Power BI pokusí použít algoritmus vzorkování s vysokou hustotou, kdykoli je to možné. Pokud se algoritmus nedá použít, například když umístíte hodnotu na osu Přehrávání , přepínač zůstane zapnutý , i když se graf vrátil ke standardnímu algoritmu. Pokud pak odeberete hodnotu z osy Přehrávání nebo pokud se podmínky změní tak, aby umožňovaly použití algoritmu vzorkování s vysokou hustotou, graf pro tento graf automaticky použije vzorkování s vysokou hustotou, protože tato funkce je aktivní.
Poznámka:
Datové body jsou seskupené nebo vybrané podle indexu. Legenda nemá vliv na vzorkování algoritmu. Ovlivňuje pouze řazení vizuálu.
Úvahy a omezení
Algoritmus vzorkování s vysokou hustotou je důležitým vylepšením Power BI. Algoritmus vzorkování s vysokou hustotou ale funguje pouze s živými připojeními k služba Power BI modelům, importovaným modelům nebo DirectQuery.