Create jobs and input data for batch endpoints
Batch endpoints can be used to perform long batch operations over large amounts of data. Such data can be placed in different places. Some type of batch endpoints can also receive literal parameters as inputs. In this tutorial we'll cover how you can specify those inputs, and the different types or locations supported.
Before invoking an endpoint
To successfully invoke a batch endpoint and create jobs, ensure you have the following:
You have permissions to run a batch endpoint deployment. AzureML Data Scientist, Contributor, and Owner roles can be used to run a deployment. For custom roles definitions read Authorization on batch endpoints to know the specific permissions needed.
You have a valid Microsoft Entra ID token representing a security principal to invoke the endpoint. This principal can be a user principal or a service principal. In any case, once an endpoint is invoked, a batch deployment job is created under the identity associated with the token. For testing purposes, you can use your own credentials for the invocation as mentioned below.
Use the Azure CLI to sign in using either interactive or device code authentication:
az loginTo learn more about how to authenticate with multiple type of credentials read Authorization on batch endpoints.
The compute cluster where the endpoint is deployed has access to read the input data.
Tip
If you are using a credential-less data store or external Azure Storage Account as data input, ensure you configure compute clusters for data access. The managed identity of the compute cluster is used for mounting the storage account. The identity of the job (invoker) is still used to read the underlying data allowing you to achieve granular access control.
Create jobs basics
To create a job from a batch endpoint you have to invoke it. Invocation can be done using the Azure CLI, the Azure Machine Learning SDK for Python, or a REST API call. The following examples show the basics of invocation for a batch endpoint that receives a single input data folder for processing. See Understanding inputs and outputs for examples with different inputs and outputs.
Use the invoke operation under batch endpoints:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Invoke a specific deployment
Batch endpoints can host multiple deployments under the same endpoint. The default endpoint is used unless the user specifies otherwise. You can change the deployment that is used as follows:
Use the argument --deployment-name or -d to specify the name of the deployment:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configure job properties
You can configure some of the properties in the created job at invocation time.
Note
Configuring job properties is only available in batch endpoints with Pipeline component deployments by the moment.
Configure experiment name
Use the argument --experiment-name to specify the name of the experiment:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Understanding inputs and outputs
Batch endpoints provide a durable API that consumers can use to create batch jobs. The same interface can be used to specify the inputs and the outputs your deployment expects. Use inputs to pass any information your endpoint needs to perform the job.
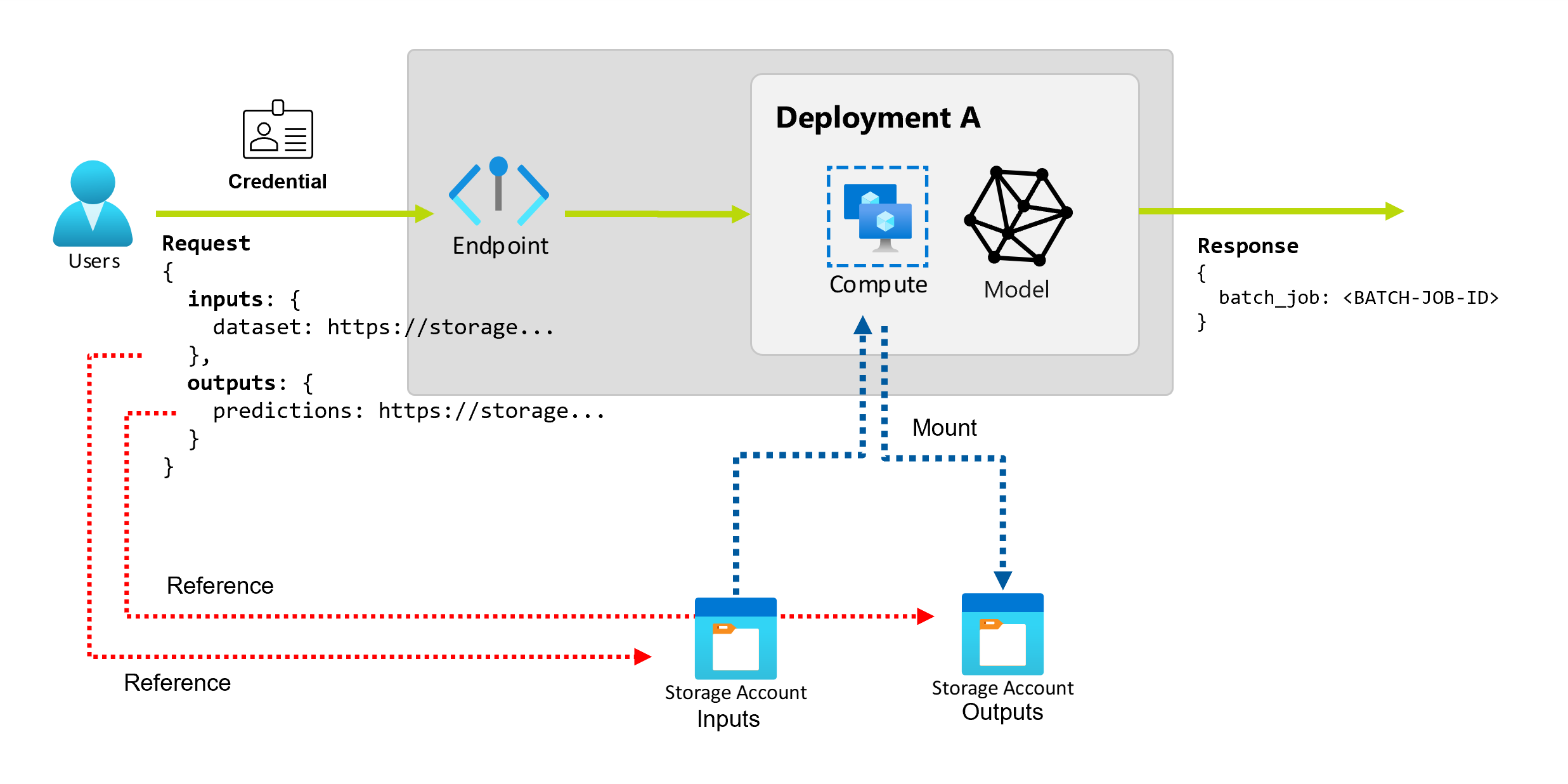
Batch endpoints support two types of inputs:
- Data inputs, which are pointers to a specific storage location or Azure Machine Learning asset.
- Literal inputs, which are literal values (like numbers or strings) that you want to pass to the job.
The number and type of inputs and outputs depend on the type of batch deployment. Model deployments always require one data input and produce one data output. Literal inputs aren't supported. However, pipeline component deployments provide a more general construct to build endpoints and allow you to specify any number of inputs (data and literal) and outputs.
The following table summarizes the inputs and outputs for batch deployments:
| Deployment type | Input's number | Supported input's types | Output's number | Supported output's types |
|---|---|---|---|---|
| Model deployment | 1 | Data inputs | 1 | Data outputs |
| Pipeline component deployment | [0..N] | Data inputs and literal inputs | [0..N] | Data outputs |
Tip
Inputs and outputs are always named. Those names serve as keys to identify them and pass the actual value during invocation. For model deployments, since they always require one input and output, the name is ignored during invocation. You can assign the name that best describes your use case, like "sales_estimation".
Data inputs
Data inputs refer to inputs that point to a location where data is placed. Since batch endpoints usually consume large amounts of data, you can't pass the input data as part of the invocation request. Instead, you specify the location where the batch endpoint should go to look for the data. Input data is mounted and streamed on the target compute to improve performance.
Batch endpoints support reading files located in the following storage options:
- Azure Machine Learning Data Assets, including Folder (
uri_folder) and File (uri_file). - Azure Machine Learning Data Stores, including Azure Blob Storage, Azure Data Lake Storage Gen1, and Azure Data Lake Storage Gen2.
- Azure Storage Accounts, including Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, and Azure Blob Storage.
- Local data folders/files (Azure Machine Learning CLI or Azure Machine Learning SDK for Python). However, that operation results in the local data to be uploaded to the default Azure Machine Learning Data Store of the workspace you're working on.
Important
Deprecation notice: Datasets of type FileDataset (V1) are deprecated and will be retired in the future. Existing batch endpoints relying on this functionality will continue to work but batch endpoints created with GA CLIv2 (2.4.0 and newer) or GA REST API (2022-05-01 and newer) will not support V1 dataset.
Literal inputs
Literal inputs refer to inputs that can be represented and resolved at invocation time, like strings, numbers, and boolean values. You typically use literal inputs to pass parameters to your endpoint as part of a pipeline component deployment. Batch endpoints support the following literal types:
stringbooleanfloatinteger
Literal inputs are only supported in pipeline component deployments. See Create jobs with literal inputs to learn how to specify them.
Data outputs
Data outputs refer to the location where the results of a batch job should be placed. Outputs are identified by name, and Azure Machine Learning automatically assigns a unique path to each named output. However, you can specify another path if required.
Important
Batch endpoints only support writing outputs in Azure Blob Storage datastores. If you need to write to an storage account with hierarchical namespaces enabled (also known as Azure Datalake Gen2 or ADLS Gen2), notice that such storage service can be registered as a Azure Blob Storage datastore since the services are fully compatible. In this way, you can write outputs from batch endpoints to ADLS Gen2.
Create jobs with data inputs
The following examples show how to create jobs, taking data inputs from data assets, data stores, and Azure Storage Accounts.
Input data from a data asset
Azure Machine Learning data assets (formerly known as datasets) are supported as inputs for jobs. Follow these steps to run a batch endpoint job using data stored in a registered data asset in Azure Machine Learning:
Warning
Data assets of type Table (MLTable) aren't currently supported.
First create the data asset. This data asset consists of a folder with multiple CSV files that you'll process in parallel, using batch endpoints. You can skip this step if your data is already registered as a data asset.
Create a data asset definition in
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataThen, create the data asset:
az ml data create -f heart-dataset-unlabeled.ymlCreate the input or request:
DATASET_ID=$(az ml data show -n heart-dataset-unlabeled --label latest | jq -r .id)Note
Data assets ID would look like
/subscriptions/<subscription>/resourcegroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/data/<data-asset>/versions/<version>. You can also useazureml:/<datasset_name>@latestas a way to specify the input.Run the endpoint:
Use the
--setargument to specify the input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDFor an endpoint that serves a model deployment, you can use the
--inputargument to specify the data input, since a model deployment always requires only one data input.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDThe argument
--settends to produce long commands when multiple inputs are specified. In such cases, place your inputs in aYAMLfile and use--fileto specify the inputs you need for your endpoint invocation.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Input data from data stores
Data from Azure Machine Learning registered data stores can be directly referenced by batch deployments jobs. In this example, you first upload some data to the default data store in the Azure Machine Learning workspace and then run a batch deployment on it. Follow these steps to run a batch endpoint job using data stored in a data store.
Access the default data store in the Azure Machine Learning workspace. If your data is in a different store, you can use that store instead. You're not required to use the default data store.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Note
Data stores ID would look like
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Tip
The default blob data store in a workspace is called workspaceblobstore. You can skip this step if you already know the resource ID of the default data store in your workspace.
You need to upload some sample data to the data store. This example assumes you already uploaded the sample data included in the repo in the folder
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/datain the folderheart-disease-uci-unlabeledin the blob storage account. Ensure you've done that before moving forward.Create the input or request:
Place the file path in the following variable:
DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Note
See how the path
pathsis appended to the resource id of the data store to indicate that what follows is a path inside of it.Tip
You can also use
azureml://datastores/<data-store>/paths/<data-path>as a way to specify the input.Run the endpoint:
Use the
--setargument to specify the input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHFor an endpoint that serves a model deployment, you can use the
--inputargument to specify the data input, since a model deployment always requires only one data input.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderThe argument
--settends to produce long commands when multiple inputs are specified. In such cases, place your inputs in aYAMLfile and use--fileto specify the inputs you need for your endpoint invocation.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlIf your data is a file, use
uri_fileas type instead.
Input data from Azure Storage Accounts
Azure Machine Learning batch endpoints can read data from cloud locations in Azure Storage Accounts, both public and private. Use the following steps to run a batch endpoint job using data stored in a storage account:
Note
Check the section configure compute clusters for data access to learn more about additional configuration required to successfully read data from storage accoutns.
Create the input or request:
Run the endpoint:
Use the
--setargument to specify the input:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAFor an endpoint that serves a model deployment, you can use the
--inputargument to specify the data input, since a model deployment always requires only one data input.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderThe argument
--settends to produce long commands when multiple inputs are specified. In such cases, place your inputs in aYAMLfile and use--fileto specify the inputs you need for your endpoint invocation.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlIf your data is a file, use
uri_fileas type instead.
Create jobs with literal inputs
Pipeline component deployments can take literal inputs. The following example shows how to specify an input named score_mode, of type string, with a value of append:
Place your inputs in a YAML file and use --file to specify the inputs you need for your endpoint invocation.
inputs.yml
inputs:
score_mode:
type: string
default: append
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
You can also use the argument --set to specify the value. However, it tends to produce long commands when multiple inputs are specified:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Create jobs with data outputs
The following example shows how to change the location where an output named score is placed. For completeness, these examples also configure an input named heart_dataset.
Use the default data store in the Azure Machine Learning workspace to save the outputs. You can use any other data store in your workspace as long as it's a blob storage account.
Create a data output:
DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"For completeness, also create a data input:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Note
See how the path
pathsis appended to the resource id of the data store to indicate that what follows is a path inside of it.Run the deployment:
Next steps
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om