Oversigt over dataimport- og -eksportjob
Vigtigt
For kunder, der bruger Human Resources, er de funktioner, der er nævnt i denne artikel, i øjeblikket tilgængelige både i enkeltstående Dynamics 365 Human Resources og den flettede finansinfrastruktur. Navigation kan være en anden end angivet, når vi foretager opdateringer. Hvis du skal finde en bestemt side, kan du bruge Søg.
Når du vil oprette og administrere dataimport- og -eksportjob, skal du bruge arbejdsområdet Datastyring. Som standard opretter processen til import og eksport af data en midlertidig tabel for hver enhed i måldatabasen. Du kan kontrollere, rydde op eller konvertere data, før du flytter dem, når du stadieindstiller tabeller.
Bemærk!
I denne artikel antages det, at du er fortrolig med dataenheder.
Dataimport og -eksportproces
Her er trinnene til import eller eksport af data.
Opret et import- eller eksportjob, hvor du kan udføre følgende opgaver:
- Definer projektkategorien.
- Identificer de enheder, der skal importeres eller eksporteres.
- Angiv jobbets dataformat.
- Indstil enhederne, så de behandles i logiske grupper og i en rækkefølge, der giver mening.
- Bestem, om der skal bruges midlertidige tabeller.
Kontroller, at kildedataene og måldataene er tilknyttet korrekt.
Kontroller sikkerheden i dit import- eller eksportjob.
Kør import- eller eksportjobbet.
Kontroller, at jobbet kørte som forventet ved at gennemse jobhistorikken.
Ryd op i de midlertidige tabeller.
De resterende afsnit i denne artikel indeholder flere oplysninger om hvert trin i processen.
Bemærk!
For at opdatere formen til dataimport og -eksport, så den viser den seneste status, skal du bruge ikonet for opdatering. Opdatering på browserniveau anbefales ikke, da alle import-/eksportjob, der ikke køres i et batch, afbrydes.
Oprette et import- eller eksportjob
Et dataimport eller -eksportjob kan køres én gang eller mange gange.
Definer projektkategorien
Vi anbefaler, at du giver dig tid til at vælge en relevant projektkategori til dit import- eller eksportjob. Projektkategorier kan hjælpe dig med at administrere relaterede job.
Identificer de enheder, der skal importeres eller eksporteres
Du kan føje bestemte objekter til et import- eller eksportjob eller vælge en skabelon, der skal anvendes. Skabeloner udfylder et job med en liste over enheder. Indstillingen Anvend skabelon er tilgængelig, når du har give jobbet et navn og gemmer jobbet.
Angiv jobbets dataformat
Når du vælger en enhed, skal du vælge dataformatet, der eksporteres eller importeres. Du kan definere formater ved hjælp af feltet Opsætning af datakilder. Et dataformat for kilden er en kombination af Type, Filformat, Rækkeafgrænser og Kolonneafgrænser. Der er andre attributter, men disse er nøgleattributter, der kan forstå. Følgende tabel viser de gyldige kombinationer.
| Filformat | Række/kolonneafgrænser | XML-typografi |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-element XML-attribut |
| Afgrænset, fast bredde | Komma, semikolon, tabulering, lodret streg, kolon | -NA- |
Bemærk!
Det er vigtigt at vælge den rigtige værdi for Rækkeafgrænsningstegn, Kolonneafgrænsningstegn og Tekstafgrænsningstegn, hvis indstillingen Filformat er angivet til Afgrænset. Sørg for, at dine data ikke indeholder det tegn, der bruges som afgrænser eller operator, da dette kan resultere i fejl under import og eksport.
Bemærk!
I forbindelse med XML-baserede filformater skal du sørge for kun at bruge juridiske tegn. Yderligere oplysninger om gyldige tegn finder du i Gyldige tegn i XML 1.0. I XML 1.0 må der ikke være kontroltegn med undtagelse af faner, returneringer af omst., og linjeangivelser. Eksempler på ugyldige tegn er kantede kantede parenteser, kantede parenteser og skråstreger.
Brug Unicode i stedet for en bestemt kodeside til at importere eller eksportere data. Dette hjælper dig med at opnå de mest ensartede resultater og eliminere, at datastyringsjob mislykkes, da de inkluderer Unicode-tegn. De systemdefinerede kildedataformater, der bruger Unicode, har alle Unicode i kildenavnet. Unicode-formatet anvendes ved at vælge en Unicode-kodningsside med ANSI-kode som Kodeside i fanen Regionale indstillinger. Vælg en af følgende kodesider for Unicode:
| Tegntabel | Vist navn |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Yderligere oplysninger om kodesider finder du under Identifikation af kodeside.
Anbring enhederne i rækkefølge
Enheder kan sorteres i en dataskabelon eller i import- og eksportjob. Når du kører et job, der indeholder mere end én dataenhed, skal du sikre dig, at dataenhederne er i korrekt rækkefølge. Du anbringer primært enheder rækkefølge, så du kan løse eventuelle funktionelle afhængigheder mellem enheder. Hvis enheder ikke har funktionelle afhængigheder, kan de planlægges til parallel import eller eksport.
Kørsel af enheder, niveauer og nummerserier
Afviklingsenheden, niveauet i afviklingsenheden og rækkefølgen af en enhed hjælper med til at kontrollere den rækkefølge, data eksporteres eller importeres i.
- Enheder i forskellige afviklingsenheder behandles parallelt.
- I hver afviklingsenhed behandles enheder parallelt, hvis de har samme niveau.
- På hvert niveau behandles enheder i henhold til deres sekvensnummer på det pågældende niveau.
- Når et niveau er blevet behandlet, behandles den næste niveau.
Fornyet rækkefølge
Du ønsker at sætte dine enheder i en fornyet rækkefølge i følgende situationer:
- Hvis der kun bruges ét datajob til alle dine ændringer, kan du bruge indstillingerne til fornyet rækkefølge til at optimere udførelsestiden for hele jobbet. I disse tilfælde, kan du bruge udførelsesenheden til at repræsentere modulet, niveauet til at repræsentere funktionsområdet i modulet, og rækkefølgen til at repræsenterer enheden. Når du bruger denne metode, kan du arbejde parallelt på tværs af moduler, men du kan stadig arbejde i rækkefølge i et modul. For at sikre, at parallelle operationer gennemføres, skal du overveje alle afhængigheder.
- Hvis der bruges flere datajob (f.eks. et job for hvert modul), kan du bruge rækkefølge til at påvirke niveauet og rækkefølgen af enheder for optimal udførelse.
- Hvis der ikke er nogen afhængigheder overhovedet, kan du sætte enheder i rækkefølge ved forskellige udførelsesenheder for at få maksimal optimering.
Menuen Fornyet rækkefølge er tilgængelig, når flere enheder er markeret. Du kan skabe en fornyet rækkefølge baseret på udførelsesenhed, niveau eller indstillinger for rækkefølge. Du kan angive et interval til fornyet rækkefølge af de enheder, der er valgt. Enheden, niveauet og/eller løbenummeret, der er valgt for hver enhed, opdateres med det angivne interval.
Sortering
Du kan bruge indstillingen Sorter efter til at få enhedslisten i indstilling for at få vist listen i rækkefølge.
Afkortning
Ved importprojekter kan du vælge at afkorte poster i enhederne før importen. Afkortning er nyttig, hvis posterne skal importeres til et rent sæt tabeller. Denne indstilling er som standard slået fra.
Kontroller, at kildedataene og måldataene tilknyttes korrekt
Tilknytningen er en funktion, der gælder for både import- og eksportjob.
- I forbindelse med et importjob beskriver tilknytningen, hvilke kolonner i kildefilen, der bliver til kolonnerne i den midlertidige tabel. Systemet kan derfor afgøre, hvilke kolonnedata i kildefilen der skal kopieres til hvilken kolonne i den midlertidige tabel.
- I forbindelse med et eksportjob beskriver tilknytningen, hvilke kolonner i den midlertidige tabel (det vil sige kilden), der bliver til kolonnerne i målfilen.
Hvis kolonnenavnene i den midlertidige tabel og filen matcher hinanden, opretter systemet automatisk tilknytning, der er baseret på navnene. Men hvis navnene er forskellige, tilknyttes kolonnerne ikke automatisk. I så fald skal du fuldføre tilknytningen ved at vælge indstillingen Vis tilknytning på enheden i datajobbet.
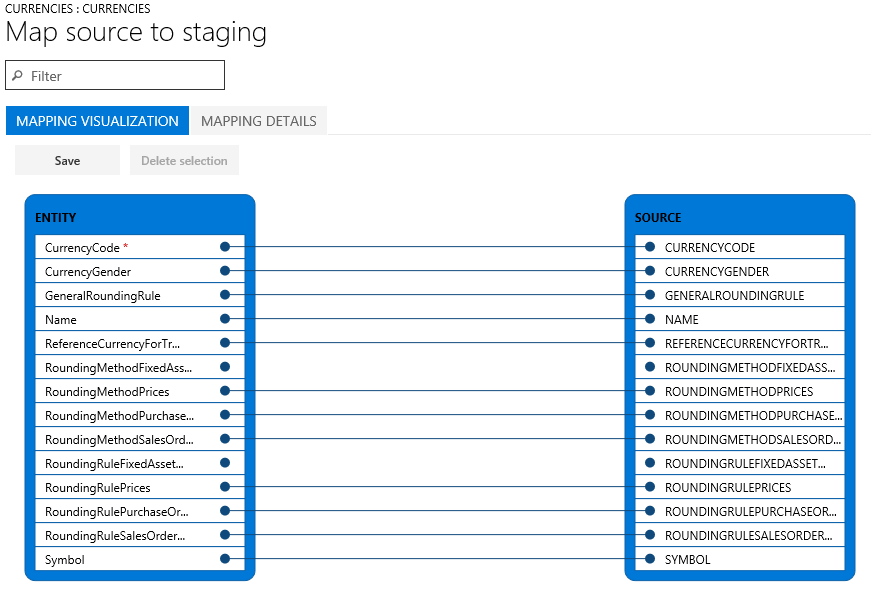
Der er to visninger af tilknytningen: Visualisering af tilknytning, som er standardvisningen, og Oplysninger om tilknytning. En rød stjerne (*) identificerer de påkrævede felter i enheden. Disse felter skal tilknyttes, før du kan arbejde med enheden. Du kan fjerne tilknytningen af andre felter, som du ønsker, når du arbejder med enheden. Hvis du vil fjerne tilknytningen af et felt, skal du vælge feltet i enten kolonnen Enhed eller kolonnen Kilde og derefter vælge Slet udvælgelse. Vælg Save for at gemme dine ændringer, og luk derefter siden for at gå tilbage til projektet. Du kan bruge den samme proces til at redigere felttilknytningen fra kilde til midlertidig fil, når du har importeret.
Du kan oprette en tilknytning på siden ved at vælge Generér kildetilknytning. En genereret tilknytning fungerer som en automatisk tilknytning. Du skal derfor manuelt tilknytte eventuelle ikke-tilknyttede felter.
Kontroller sikkerheden i dit import- eller eksportjob
Adgangen til arbejdsområdet i Datastyring kan begrænses, så brugere, som ikke eradministratorer, kun har adgang til bestemte datajob. Adgang til et datajob indebærer fuld adgang til udførelseshistorikken for jobbet og adgang til de midlertidige tabeller. Du skal derfor sikre dig, at relevante adgangskontroller er på plads, når du opretter et datajob.
Sikre et job efter roller og brugere
Brug menuen Gældende roller til at begrænse jobbet til en eller flere sikkerhedsroller. Det er kun brugere i disse roller, der har adgang til jobbet.
Du kan også begrænse et job til specifikke brugere. Når du sikrer et job efter brugere i stedet for roller, er der mere kontrol over, om flere brugere er tildelt en rolle.
Sikre et job efter juridisk enhed
Datajob er af natur globale. Hvis et datajob er blevet oprettet og brugt i en juridisk enhed, er jobbet derfor synligt i andre juridiske enheder i systemet. Denne standardindstilling kan være at foretrække i visse anvendelsesscenarier. F.eks. kan en organisation, der importerer fakturaer ved hjælp af dataenheder, sende data til en centraliseret fakturabehandlingsgruppe, der er ansvarlig for administration af fakturafejl for alle afdelinger i organisationen. I dette scenarie er det nyttigt for det centraliserede fakturabehandlingsteam at have adgang til fakturaimportjob fra alle juridiske enheder. Derfor opfylder standardfunktionsmåden kravene fra perspektivet for en juridisk enhed.
Men en organisation ønsker muligvis at have fakturabehandlingsteams pr. juridisk enhed. I så fald skal et team i en juridisk enhed kun have adgang til fakturaimportjobbet i sin egen juridiske enhed. For at opfylde disse krav, kan du konfigurere adgangskontrol baseret på juridisk enhed for datajob ved hjælp af menuen Anvendelige juridiske enheder i datajobbet. Når konfigurationen er udført, kan brugere kun se job, der er tilgængelige i den juridiske enhed, som de aktuelt er logget på. Hvis de vil se job fra en anden juridisk enhed, skal brugerne skifte til den pågældende juridiske enhed.
Et job kan sikres efter roller, brugere og juridisk enhed på samme tid.
Kør import- eller eksportjob
Du kan køre et job én gang ved at vælge knappen Import eller Eksport, når du har defineret jobbet. Du kan konfigurere et tilbagevendende job ved at vælge Opret tilbagevendende datajob.
Bemærk!
Et import- eller eksportjob kan køres ved at vælge knappen Importer eller Eksporter. Dette planlægger, at et batchjob kun skal køres én gang. Jobbet kan muligvis ikke køres med det samme, hvis batchtjenesten begrænser det pga. belastningen af batchtjenesten. Job kan også køres synkront ved at vælge Importer nu eller Eksporter nu. Dette starter jobbet med det samme og er nyttigt, hvis et batch ikke starter på grund af begrænsning. Jobbene kan også planlægges til at blive kørt på et senere tidspunkt. Det kan du gøre ved at vælge indstillingen Kør i batch. Batchressourcer er omfattet af begrænsning, så batchjobbet starter muligvis ikke med det samme. Det anbefales, at du bruger en batch, fordi det også vil hjælpe med store mængder data, der skal importeres eller eksporteres. Batchjob kan planlægges til at køre på en bestemt batchgruppe, hvilket giver mulighed for større kontrol set fra et belastningsjusteringsperspektiv.
Kontroller, at jobbet kørte som forventet
Jobhistorikken er tilgængelig i forbindelse med fejlfinding og undersøgelse på både import- og eksportjob. Kørsler af historiske job er organiseret efter tidsintervaller.
Hver jobkørsel indeholder følgende oplysninger:
- Detaljer om udførelse
- Udførelseslog
Oplysningerne om kørslen viser tilstanden for hver dataenhed, som jobbet behandlede. Derfor kan du hurtigt finde følgende oplysninger:
- Hvilke enheder blev behandlet.
- For en enhed, hvor mange poster der blev behandlet korrekt, og hvor mange der mislykkedes.
- De midlertidige poster for hver enhed.
Du kan hente de midlertidige data i en fil til eksportjob, eller du kan hente dem som en pakke til import- og eksportjob.
På grundlag af oplysningerne i kørslen, kan du også åbne kørselslogfilen.
Parallel import
For at gøre det hurtigere at importere data kan parallel behandling af en filimport aktiveres, hvis enheden understøtter parallel import. Hvis du vil konfigurere parallel import for en enhed, skal du følge disse trin.
Gå til Systemadministration > Arbejdsområder > Datastyring.
I afsnittet Import/eksport skal du vælge feltet Rammeparametre for at åbne siden Rammeparametre for dataimport/-eksport.
Under fanen Indstillinger for enhed skal du vælge Konfigurer udførelsesparametre for enhed for at åbne siden Udførelsesparametre for enhedsimport.
Angiv følgende felter for at konfigurere parallel import for en enhed:
- I feltet Enhed skal du vælge enheden. Hvis enhedsfeltet er tomt, bruges den tomme værdi som standardindstilling for alle efterfølgende importer, hvis enheden understøtter parallel import.
- I feltet Antal poster for importtærskel skal du angive grænsen for antallet af poster til import. Dette bestemmer det antal poster, der skal behandles af en tråd. Hvis en fil har 10K-poster, vil en postoptælling på 2500 med en opgaveoptælling på fire betyde, at hver tråd behandler 2500 poster.
- Angiv antallet af importopgaver i feltet Antal importopgaver. Optællingen må ikke overstige de maksimale batchtråde, der er tildelt batchafvikling i konfigurationen af >Server til systemadministration.
Oprydning i jobhistorik
Posterne i jobhistorikken og de relaterede data i den midlertidige tabel, der er ældre end 90 dage, slettes som standard automatisk. Oprydningsfunktionen i jobhistorikken i datastyring kan bruges til at konfigurere periodisk oprydning af kørselshistorikken med en lavere tilbageholdelsesperiode end denne standard. Denne funktionalitet erstatter den tidligere oprydning i midlertidige tabeller, hvilket nu frarådes. Følgende tabeller ryddes op i oprydningsprocessen.
Alle midlertidige tabeller
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Oprydningsfunktionen i kørselshistorikken åbnes fra oprydningen af > datastyringsjobhistorikken.
Planlægningsparametre
Når du planlægger oprydningsprocessen, skal der angives følgende parametre for at definere oprydningskriterierne.
Antal dage, historikken skal bevares – Denne indstilling bruges til at kontrollere den mængde udførelseshistorik, der skal bibeholdes. Historikken angives i antal dage. Når oprydningsjobbet planlægges som et tilbagevendende batchjob, vil denne indstilling fungere som et fortløbende vindue, der derved altid forlader historikken i det angivne antal dage, der er intakt, mens resten slettes. Standard er syv dage.
Antallet af timer , som jobbet skal udføres i – Afhængigt af det historikbeløb, der skal ryddes op, kan den samlede udførelsestid for oprydningsjobbet variere fra nogle få minutter til nogle få timer. Dette parameter skal angives til det antal timer, som jobbet skal udføre. Når oprydningsjobbet er udført i det angivne antal timer, afsluttes jobbet, og oprydningen genoptages, næste gang jobbet køres på baggrund af gentagelsesplanen.
Der kan angives en maksimal gennemførelsestid ved at angive en maksimumgrænse for det antal timer, jobbet skal køre, ved hjælp af denne indstilling. Oprydningslogikken gennemgår ét jobudførelses-id ad gangen i en kronologisk arrangeret rækkefølge, hvor det ældste bliver først til oprydningen af den relaterede kørselshistorik. Det stopper med at hente nye udførelses-id'er til oprydning, når den resterende udførelsesvarighed ligger inden for de sidste 10 % af den angivne varighed. I nogle tilfælde forventes det, at oprydningsjobbet fortsætter efter den angivne maksimale tid. Dette afhænger overvejende af, hvor mange poster der skal slettes for det aktuelle udførelses-id, der blev startet, før tærsklen på 10 % blev nået. Den oprydning, der blev påbegyndt, skal fuldføres for at sikre dataintegriteten, hvilket betyder, at oprydningen fortsætter, selvom den overskrider den angivne grænse. Når de er fuldført, afhentes nye udførelses-id'er ikke, og oprydningsjobbet afsluttes. Den resterende kørselshistorik, der ikke er ryddet op på grund af tilstrækkelig udførelsestid, afhentes, næste gang oprydningsjobbet planlægges. Standard- og minimumværdien for denne indstilling er angivet til 2 timer.
Tilbagevendende batch – Oprydningsjobbet kan køres som en engangskørsel, manuel kørsel, eller det kan også planlægges til tilbagevendende kørsel i batch. Batchen kan planlægges ved hjælp af indstillingerne Kør i baggrundsindstillinger , som er standardbatchopsætningen.
Bemærk!
Hvis oprydningsfunktionen for jobhistorikken ikke bruges, slettes den udførelseshistorik, der er ældre end 90 dage, stadig automatisk. Oprydning af jobhistorik kan også køres sammen med denne automatiske sletning. Kontrollér, at oprydningsjobbet er planlagt til at køre i gentagelse. Som forklaret ovenfor, vil jobbet kun rydde op i så mange udførelses-noget som muligt inden for det angivne maksimale antal timer.
Oprydning og arkivering af jobhistorik
Oprydning af jobhistorik og arkivering erstatter de tidligere versioner af oprydningsfunktionen. I dette afsnit beskrives disse nye egenskaber.
En af de vigtigste ændringer i oprydningsfunktionen er brugen af systembatchjobbet til oprydning af historikken. Brugen af systembatchjobbet giver mulighed for, at økonomi- og operationsapps kan få oprydningsbatchjobbet planlagt og kørt automatisk, så snart systemet er klar. Det er ikke længere nødvendigt at planlægge batchjobbet manuelt. I denne standardkørselstilstand køres batchjobbet hver time, der starter ved midnat, og udførelseshistorikken bevares for de seneste syv dage. Den slettede oversigt arkiveres, så den kan hentes senere. Fra og med version 10.0.20 er denne funktion altid aktiveret.
Den anden ændring i oprydningsprocessen er arkivering af den fjernede udførelseshistorik. Med oprydningsjobbet arkiveres de slettede poster til det blob-lager, som DIXF bruger til almindelig integration. Den arkiverede fil er i pakkeformatet DIXF og er tilgængelig i syv dage i blob, hvor den kan hentes. Standardlevetiden på syv dage for den arkiverede fil kan ændres til et maksimum på 90 dage i parametrene.
Ændre standardindstillingerne
Denne funktionalitet er aktuelt i prøveversion og skal aktiveres eksplicit ved at aktivere flightet DMFEnableExecutionHistoryCleanupSystemJob. Den midlertidige oprydningsfunktion skal også være aktiveret i funktionsstyring.
Hvis du vil ændre standardindstillingen for varigheden for den arkiverede fil, skal du gå til arbejdsområdet Dataadministration og vælge Oprydning i jobhistorik. Angiv Dage, som pakken skal bevares i blob til en værdi mellem 7 og 90 (inklusive). Dette påvirker de arkiver, der oprettes, efter at ændringen blev foretaget.
Hente den arkiverede pakke
Denne funktionalitet er aktuelt i prøveversion og skal aktiveres eksplicit ved at aktivere flightet DMFEnableExecutionHistoryCleanupSystemJob. Den midlertidige oprydningsfunktion skal også være aktiveret i funktionsstyring.
Hvis du vil hente den arkiverede kørselshistorik, skal du gå til arbejdsområdet Dataadministration og vælge Oprydning i jobhistorik. Vælg Historik for sikkerhedskopiering af pakke for at åbne historikformularen. I denne formular vises listen over alle arkiverede pakker. Du kan vælge og hente et arkiv ved at vælge Download pakke. Den hentede pakke er i DIXF-pakkeformat og indeholder følgende filer:
- Fil fra midlertidig enhedstabel
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG