Stikprøvetagning af linjer med høj tæthed i Power BI
Algoritmen for udsnit i Power BI forbedrer visualiseringer, der eksempeler data med høj tæthed. Du kan f.eks. oprette et kurvediagram ud fra dine detailbutikkers salgsresultater, hvor hver butik har mere end 10.000 salgskvitteringer hvert år. Et kurvediagram med sådanne salgsoplysninger vil tage et eksempel på data fra dataene for hver butik og oprette et kurvediagram med flere serier, der dermed repræsenterer de underliggende data. Sørg for at vælge en meningsfuld repræsentation af disse data for at illustrere, hvordan salget varierer over tid. Denne praksis er almindelig i visualisering af data med høj tæthed. Oplysningerne om stikprøvetagning af data med høj tæthed er beskrevet i denne artikel.
Bemærk
Algoritmen udsnit med høj tæthed, der er beskrevet i denne artikel, er tilgængelig i både Power BI Desktop og Power BI-tjeneste.
Sådan fungerer stikprøvetagning af linjer med høj tæthed
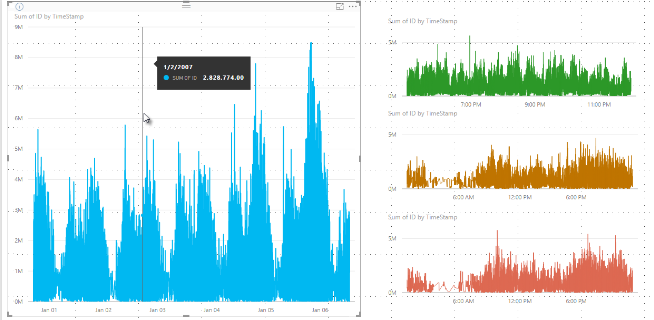
Tidligere valgte Power BI en samling af eksempeldatapunkter i hele rækken af underliggende data på en deterministisk måde. Hvis data med høj tæthed for en visualisering f.eks. strækker sig over ét kalenderår, kan der være 350 eksempeldatapunkter, der vises i visualiseringen, som hver især blev valgt for at sikre, at hele dataområdet blev repræsenteret i visualiseringen. For at hjælpe med at forstå, hvordan dette sker, kan du forestille dig, at du afbilder en aktiekurs over en periode på et år og vælger 365 datapunkter for at oprette et kurvediagramvisual. Det er ét datapunkt for hver dag.
I denne situation er der mange værdier for en aktiekurs inden for hver dag. Selvfølgelig er der en daglig høj og lav, men de kan forekomme når som helst i løbet af dagen, når aktiemarkedet er åbent. Hvis det underliggende dataeksempel blev taget kl. 10:30 og 12:00 hver dag i forbindelse med stikprøvetagning af linjer med høj tæthed, ville du få et repræsentativt snapshot af de underliggende data, f.eks. prisen kl. 10:30 og 12:00. Snapshottet registrerer muligvis ikke den faktiske høje og lave aktiekurs for det pågældende repræsentative datapunkt den pågældende dag. I denne situation og andre er stikprøvetagningen repræsentativ for de underliggende data, men den registrerer ikke altid vigtige punkter, som i dette tilfælde ville være de højeste og laveste aktiekurser i det daglige.
Pr. definition er der stikprøvetagning af data med høj tæthed for at oprette visualiseringer forholdsvis hurtigt, der reagerer på interaktivitet. For mange datapunkter i en visualisering kan fortrudte det og kan forringe synligheden af tendenser. Den måde, dataene er samplet på, er det, der driver oprettelsen af algoritmen for stikprøvetagning for at give den bedste visualiseringsoplevelse. I Power BI Desktop giver algoritmen den bedste kombination af svartid, repræsentation og tydelig bevarelse af vigtige punkter i hvert enkelt tidsudsnit.
Sådan fungerer den nye algoritme for linjetagning
Algoritmen for stikprøvetagning af linjer med høj tæthed er tilgængelig for visualiseringer af kurvediagrammer og områdediagrammer med en fortløbende x-akse.
I forbindelse med en visualisering med høj tæthed opdeler Power BI på intelligent vis dine data i segmenter med høj opløsning og vælger derefter vigtige punkter, der skal repræsentere hvert afsnit. Denne proces med udsnit af data med høj opløsning er justeret for at sikre, at det resulterende diagram visuelt ikke kan skelnes fra gengivelse af alle de underliggende datapunkter, men det er hurtigere og mere interaktivt.
Minimum- og maksimumværdier for linjevisualiseringer med høj tæthed
Følgende begrænsninger gælder for alle visualiseringer:
3.500 er det maksimale antal datapunkter , der vises på de fleste visualiseringer, uanset antallet af underliggende datapunkter eller serier, se undtagelser på følgende liste. Hvis du f.eks. har 10 serier med 350 datapunkter hver, har visualiseringen nået sin maksimale samlede grænse for datapunkter. Hvis du har én serie, kan den have op til 3.500 datapunkter, hvis algoritmen vurderer, at den bedste stikprøvetagning for de underliggende data.
Der er maksimalt 60 serier for alle visualiseringer. Hvis du har mere end 60 serier, kan du opdele dataene og oprette flere visualiseringer med 60 eller færre serier hver. Det er en god idé at bruge et udsnitsværktøj til kun at vise segmenter af dataene, men kun for visse serier. Hvis du f.eks. viser alle underkategorier i forklaringen, kan du bruge et udsnit til at filtrere efter den overordnede kategori på den samme rapportside.
Det maksimale antal datagrænser er højere for følgende visualiseringstyper, som er undtagelser fra grænsen på 3.500 datapunkter:
- Maksimalt 150.000 datapunkter for R-visualiseringer.
- 30.000 datapunkter for Visualiseringer i Azure Map.
- 10.000 datapunkter for nogle punktdiagramkonfigurationer (punktdiagrammer er som standard 3500).
- 3.500 for alle andre visualiseringer ved hjælp af stikprøvetagning med høj tæthed. Nogle andre visualiseringer kan visualisere flere data, men de bruger ikke stikprøvetagning.
Disse parametre sikrer, at visualiseringer i Power BI Desktop gengives hurtigt, reagerer på interaktion med brugere og ikke resulterer i unødvendigt beregningsspild på den computer, der gengiver visualiseringen.
Evaluer repræsentative datapunkter for linjevisualiseringer med høj tæthed
Når antallet af underliggende datapunkter overskrider det maksimale antal datapunkter, der kan repræsenteres i visualiseringen, starter en proces kaldet gruppering i beholdere. Gruppering opdeler de underliggende data i grupper kaldet placeringer og afgrænser derefter disse placeringer iterativt.
Algoritmen opretter så mange beholdere som muligt for at oprette den største granularitet for visualiseringen. I hver placering finder algoritmen minimum- og maksimumdataværdien for at sikre, at vigtige og betydelige værdier, f.eks. udenforliggende værdier, registreres og vises i visualiseringen. Baseret på resultaterne af gruppering i beholdere og efterfølgende evaluering af dataene af Power BI bestemmes minimumopløsningen for x-aksen for visualiseringen for at sikre maksimal granularitet for visualiseringen.
Som tidligere nævnt er minimumgranulariteten for hver serie 350 punkter, og maksimum er 3.500 for de fleste visualiseringer. Undtagelserne er angivet i forrige afsnit.
Hver placering repræsenteres af to datapunkter, som bliver placeringens repræsentative datapunkter i visualiseringen. Datapunkterne er den høje og lave værdi for den pågældende placering. Når du vælger den høje og lave værdi, sikrer processen for gruppering i beholdere, at en vigtig høj værdi eller betydelig lav værdi registreres og gengives i visualiseringen.
Hvis det lyder som en masse analyse for at sikre, at lejlighedsvise udenforliggende værdier registreres og vises korrekt i visualiseringen, er du korrekt. Det er den nøjagtige årsag til algoritmen og processen til gruppering i beholdere.
Værktøjstip og stikprøvetagning af linjer med høj tæthed
Det er vigtigt at bemærke, at denne proces til gruppering i beholdere, som resulterer i, at minimum- og maksimumværdien i en given placering registreres og vises, kan påvirke den måde, værktøjstip viser data på, når du holder markøren over datapunkterne. Lad os vende tilbage til vores eksempel om aktiekurser for at forklare, hvordan og hvorfor dette sker.
Lad os antage, at du opretter en visualisering baseret på aktiekursen, og at du sammenligner to forskellige aktier, som begge bruger stikprøvetagning med høj tæthed. De underliggende data for hver serie indeholder mange datapunkter. Du kan f.eks. registrere aktiekursen hvert sekund på dagen. Algoritmen for stikprøvetagning af linjer med høj tæthed udfører gruppering i beholdere for hver serie uafhængigt af den anden.
Lad os nu sige, at den første aktie hopper op i prisen kl. 12:02 og derefter hurtigt kommer tilbage 10 sekunder senere. Det er et vigtigt datapunkt. Når gruppering i beholdere finder sted for den pågældende aktie, er den højeste værdi kl. 12:02 et repræsentativt datapunkt for den pågældende placering.
Men for den anden aktie var 12:02 hverken høj eller lav i den placering, der inkluderede den pågældende tid. Måske opstod den høje og lave placering, der indeholder 12:02, tre minutter senere. I denne situation kan du se en værdi i værktøjstippet for den første aktie, når kurvediagrammet oprettes, og du holder markøren over 12:02. Det skyldes, at den sprang kl. 12:02, og at værdien blev valgt som placeringens høje datapunkt. Du kan dog ikke se nogen værdi i værktøjstippet kl. 12:02 for den anden aktie. Det skyldes, at den anden aktie ikke havde en høj eller lav værdi for den placering, der inkluderede 12:02. Der er derfor ingen data at vise for den anden aktie kl. 12:02, og derfor vises der ingen data for værktøjstip.
Denne situation opstår ofte med værktøjstip. De høje og lave værdier for en bestemt placering stemmer sandsynligvis ikke perfekt overens med de jævnt skalerede x-akseværdipunkter, og værktøjstippet viser ikke værdien.
Sådan aktiverer du stikprøvetagning af linjer med høj tæthed
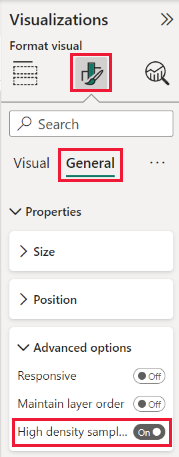
Som standard er algoritmen Slået til. Hvis du vil ændre denne indstilling, skal du gå til ruden Formatering på kortet Generelt , og nederst kan du se skyderen Udsnit med høj tæthed . Vælg skyderen for at slå Til eller Fra.
Overvejelser og begrænsninger
Algoritmen for stikprøvetagning af linjer med høj tæthed er en vigtig forbedring af Power BI, men der er et par overvejelser, du skal vide, når du arbejder med værdier og data med høj tæthed.
På grund af øget granularitet og processen for gruppering i beholdere viser værktøjstip muligvis kun en værdi, hvis de repræsentative data er justeret i forhold til markøren. Du kan få flere oplysninger i afsnittet Værktøjstip og stikprøvetagning af linjer med høj tæthed i denne artikel.
Når størrelsen på en overordnet datakilde er for stor, fjerner algoritmen serier (forklaringselementer) for at imødekomme den maksimale begrænsning for dataimport.
- I denne situation sorterer algoritmen forklaringsserier alfabetisk og starter listen over forklaringselementer i alfabetisk rækkefølge, indtil maksimum for dataimport er nået, og importerer ikke flere serier.
Når et underliggende datasæt har mere end 60 serier, det maksimale antal serier, sorteres serien alfabetisk af algoritmen, og serier ud over den 60. alfabetisk sorterede serie fjernes.
Hvis værdierne i dataene ikke er af typen numerisk eller dato/klokkeslæt, bruger Power BI ikke algoritmen og vender tilbage til den forrige algoritme for stikprøvetagning med høj tæthed.
Indstillingen Vis elementer uden data understøttes ikke med algoritmen.
Algoritmen understøttes ikke, når du bruger en direkte forbindelse til en model, der hostes i SQL Server Analysis Services version 2016 eller tidligere. Det understøttes i modeller, der hostes i Power BI eller Azure Analysis Services.