DirectQuery i Power BI
I Power BI Desktop eller Power BI-tjeneste kan du oprette forbindelse til mange forskellige datakilder på forskellige måder. Du kan importere data til Power BI, hvilket er den mest almindelige måde at hente data på. Du kan også oprette direkte forbindelse til nogle data i det oprindelige kildelager, som kaldes DirectQuery. I denne artikel beskrives primært DirectQuery-funktioner.
I denne artikel beskrives:
- De forskellige indstillinger for Dataforbindelse i Power BI.
- Vejledning til, hvornår du skal bruge DirectQuery i stedet for import.
- Begrænsninger og konsekvenser ved brug af DirectQuery.
- Anbefalinger til korrekt brug af DirectQuery.
- Sådan diagnosticerer du problemer med DirectQuerys ydeevne.
I artiklen fokuseres der på DirectQuery-arbejdsprocessen, når du opretter en rapport i Power BI Desktop, men den dækker også oprettelse af forbindelse via DirectQuery i Power BI-tjeneste.
Bemærk
DirectQuery er også en funktion i SQL Server Analysis Services. Denne funktion deler mange detaljer med Direct Query i Power BI, men der er også vigtige forskelle. Denne artikel dækker primært DirectQuery med Power BI og ikke SQL Server Analysis Services.
Du kan finde flere oplysninger om brug af DirectQuery med SQL Server Analysis Services under Brug DirectQuery til semantiske Power BI-modeller og Analysis Services (prøveversion). Du kan også downloade PDF DirectQuery i SQL Server 2016 Analysis Services.
Power BI-dataforbindelsestilstande
Power BI opretter forbindelse til et stort antal forskellige datakilder, f.eks.:
- Onlinetjenester som Salesforce og Dynamics 365.
- Databaser som SQL Server, Access og Amazon Redshift.
- Enkle filer i Excel, JSON og andre formater.
- Andre datakilder som Spark, websteder og Microsoft Exchange.
Du kan importere data fra disse kilder til Power BI. For nogle kilder kan du også oprette forbindelse ved hjælp af DirectQuery. Du kan finde en oversigt over de kilder, der understøtter DirectQuery, under Datakilder, der understøttes af DirectQuery. DirectQuery-aktiverede kilder er primært kilder, der kan levere en god interaktiv forespørgselsydeevne.
Du bør importere data til Power BI, hvor det er muligt. Import udnytter forespørgselsprogrammets høje ydeevne i Power BI og giver en yderst interaktiv oplevelse med fuld funktionalitet.
Hvis du ikke kan nå dine mål ved at importere data, f.eks. hvis dataene ændres ofte, og rapporter skal afspejle de nyeste data, kan du overveje at bruge DirectQuery. DirectQuery er kun praktisk, når den underliggende datakilde kan levere interaktive forespørgselsresultater på mindre end fem sekunder for en typisk aggregeret forespørgsel og kan håndtere den genererede forespørgselsbelastning. Overvej nøje begrænsningerne og konsekvenserne ved at bruge DirectQuery.
Power BI-import- og DirectQuery-funktioner udvikler sig over tid. Ændringer, der giver større fleksibilitet, når du bruger importerede data, giver dig mulighed for at importere oftere og fjerne nogle af ulemperne ved at bruge DirectQuery. Uanset forbedringer er ydeevnen for den underliggende datakilde en vigtig overvejelse, når du bruger DirectQuery. Hvis en underliggende datakilde er langsom, er det ikke muligt at bruge DirectQuery for den pågældende kilde.
I følgende afsnit beskrives de tre muligheder for at oprette forbindelse til data: import, DirectQuery og direkte forbindelse. I resten af artiklen fokuseres der på DirectQuery.
Importér forbindelser
Når du opretter forbindelse til en datakilde som SQL Server og importerer data i Power BI Desktop, opstår følgende resultater:
Når du indledningsvist henter data, definerer hvert sæt tabeller, du vælger, en forespørgsel, der returnerer et sæt data. Du kan redigere disse forespørgsler, før du indlæser dataene, f.eks. for at anvende filtre, aggregere dataene eller joinforbinde forskellige tabeller.
Ved indlæsning importeres alle de data, der er defineret af forespørgslerne, til Power BI-cachen.
Oprettelse af en visualisering i Power BI Desktop forespørger de cachelagrede data. Power BI-lageret sikrer, at forespørgslen er hurtig, og at alle ændringer af visualiseringen afspejles med det samme.
Visualiseringer afspejler ikke ændringer af de underliggende data i datalageret. Du skal importere dataene igen for at opdatere dataene.
Publicering af rapporten til Power BI-tjeneste som en .pbix-fil opretter og uploader en semantisk model, der indeholder de importerede data. Du kan derefter planlægge dataopdatering, f.eks. importere dataene igen hver dag. Afhængigt af placeringen af den oprindelige datakilde kan det være nødvendigt at konfigurere en datagateway i det lokale miljø til opdateringen.
Hvis du åbner en eksisterende rapport eller opretter en ny rapport i Power BI-tjeneste forespørger de importerede data igen, hvilket sikrer interaktivitet.
Du kan fastgøre visualiseringer eller hele rapportsider som dashboardfelter i Power BI-tjeneste. Felterne opdateres automatisk, når den underliggende semantiske model opdateres.
DirectQuery-forbindelser
Når du bruger DirectQuery til at oprette forbindelse til en datakilde i Power BI Desktop, sker følgende resultater:
Du kan bruge Hent data til at vælge kilden. For relationskilder kan du stadig vælge et sæt tabeller, der definerer en forespørgsel, der logisk returnerer et datasæt. For flerdimensionelle kilder som SAP Business Warehouse (SAP BW) skal du kun vælge kilden.
Ved indlæsning importeres der ingen data i Power BI-lageret. Når du opretter en visualisering, sender Power BI Desktop i stedet forespørgsler til den underliggende datakilde for at hente de nødvendige data. Den tid, det tager at opdatere visualiseringen, afhænger af ydeevnen af den underliggende datakilde.
Eventuelle ændringer af de underliggende data afspejles ikke med det samme i eksisterende visualiseringer. Det er stadig nødvendigt at opdatere. Power BI Desktop sender de nødvendige forespørgsler for hver visualisering igen og opdaterer visualiseringen efter behov.
Publicering af rapporten til Power BI-tjeneste opretter og uploader en semantisk model på samme måde som til import. Denne semantiske model indeholder dog ingen data.
Åbning af en eksisterende rapport eller oprettelse af en ny rapport i Power BI-tjeneste forespørger den underliggende datakilde for at hente de nødvendige data. Afhængigt af placeringen af den oprindelige datakilde kan det være nødvendigt at konfigurere en datagateway i det lokale miljø for at hente dataene.
Du kan fastgøre visualiseringer eller hele rapportsider som dashboardfelter. For at sikre, at åbning af et dashboard sker hurtigt, opdateres felterne automatisk efter en tidsplan, f.eks. hver time. Du kan styre opdateringshyppigheden, afhængigt af hvor ofte dataene ændres, og hvor vigtigt det er at se de nyeste data.
Når du åbner et dashboard, afspejler felterne dataene på tidspunktet for den seneste opdatering, ikke nødvendigvis de seneste ændringer af den underliggende kilde. Du kan opdatere et åbent dashboard for at sikre, at det er aktuelt.
Direkte forbindelser
Når du opretter forbindelse til SQL Server Analysis Services, kan du vælge at importere dataene eller bruge en direkte forbindelse til den valgte datamodel. Brug af en direkte forbindelse svarer til DirectQuery. Der importeres ingen data, og den underliggende datakilde forespørges om at opdatere visualiseringer.
Når du f.eks. bruger import til at oprette forbindelse til SQL Server Analysis Services, definerer du en forespørgsel i forhold til den eksterne SQL Server Analysis Services-kilde og importerer dataene. Hvis du opretter direkte forbindelse, definerer du ikke en forespørgsel, og hele den eksterne model vises på feltlisten.
Denne situation gælder også, når du opretter forbindelse til følgende kilder, bortset fra at der ikke er mulighed for at importere dataene:
Semantiske Power BI-modeller, f.eks. oprettelse af forbindelse til en semantisk Power BI-model, der allerede er publiceret til tjenesten, for at oprette en ny rapport over den.
Microsoft Dataverse.
Når du publicerer SQL Server Analysis Services-rapporter, der bruger direkte forbindelser, svarer funktionsmåden i Power BI-tjeneste til DirectQuery-rapporter på følgende måder:
Åbning af en eksisterende rapport eller oprettelse af en ny rapport i Power BI-tjeneste forespørger den underliggende SQL Server Analysis Services-kilde, hvilket muligvis kræver en datagateway i det lokale miljø.
Dashboardfelter opdateres automatisk efter en tidsplan, f.eks. hver time.
En direkte forbindelse adskiller sig også fra DirectQuery på flere måder. Dynamiske forbindelser overfører f.eks. altid identiteten for den bruger, der åbner rapporten, til den underliggende SQL Server Analysis Services-kilde.
DirectQuery-use cases
Forbind med DirectQuery kan være nyttigt i følgende scenarier. I flere af disse tilfælde er det nødvendigt eller gavnligt at lade dataene være på den oprindelige kildeplacering.
DirectQuery i Power BI giver de største fordele i følgende scenarier:
- Dataene ændres ofte, og du har brug for rapportering i næsten realtid.
- Du skal håndtere store data uden at skulle samle på forhånd.
- Den underliggende kilde definerer og anvender sikkerhedsregler.
- Der gælder begrænsninger for datasuverænitet.
- Kilden er en flerdimensionel kilde, der indeholder målinger, f.eks. SAP BW.
Data ændres ofte, og du har brug for rapportering i næsten realtid
Du kan opdatere modeller med importerede data højst én gang i timen, oftere med Power BI Pro- eller Power BI Premium-abonnementer. Hvis dataene ændres hele tiden, og det er nødvendigt for rapporter at vise de nyeste data, opfylder brugen af import med planlagt opdatering muligvis ikke dine behov. Du kan streame data direkte i Power BI, selvom der er grænser for de datamængder, der understøttes i dette tilfælde.
Brug af DirectQuery betyder, at åbning eller opdatering af en rapport eller et dashboard altid viser de nyeste data i kilden. Dashboardfelterne kan også opdateres oftere, så ofte som hvert 15. minut.
Dataene er meget store
Hvis dataene er meget store, er det ikke muligt at importere det hele. DirectQuery kræver ingen stor dataoverførsel, fordi den forespørger data på plads. Store data kan dog også gøre ydeevnen af forespørgsler i forhold til den underliggende kilde for langsom.
Du behøver ikke altid at importere detaljerede data. Power Query-editor gør det nemt at samle data på forhånd under importen. Teknisk set er det muligt at importere præcis de aggregerede data, du har brug for for hver visualisering. Selvom DirectQuery er den nemmeste metode til store data, kan import af aggregerede data være en løsning, hvis den underliggende datakilde er for langsom til DirectQuery.
Disse oplysninger vedrører kun brug af Power BI. Du kan få flere oplysninger om brug af store modeller i Power BI i store semantiske modeller i Power BI Premium. Der er ingen begrænsninger for, hvor ofte dataene kan opdateres.
Den underliggende kilde definerer sikkerhedsregler
Når du importerer data, opretter Power BI forbindelse til datakilden ved hjælp af den aktuelle brugers Power BI Desktop-legitimationsoplysninger eller de legitimationsoplysninger, der er konfigureret til planlagt opdatering fra Power BI-tjeneste. Når du publicerer og deler rapporter, der har importerede data, skal du være forsigtig med kun at dele med brugere, der har tilladelse til at se dataene, eller du skal definere sikkerhed på rækkeniveau som en del af den semantiske model.
Med DirectQuery kan en rapportfremvisers legitimationsoplysninger overføres til den underliggende kilde, som anvender sikkerhedsregler. DirectQuery understøtter enkeltlogon (SSO) til Azure SQL-datakilder og via en datagateway til sql-servere i det lokale miljø. Du kan få flere oplysninger under Oversigt over enkeltlogon (SSO) for gateways i Power BI.
Der gælder begrænsninger for datasuverænitet
Nogle organisationer har politikker om datasuverænitet, hvilket betyder, at data ikke kan forlade organisationens lokale miljø. Disse data præsenterer problemer for løsninger, der er baseret på dataimport. Med DirectQuery forbliver dataene på den underliggende kildeplacering. Men selv med DirectQuery bevarer Power BI-tjeneste nogle cachelagre af data på visualiseringsniveau på grund af planlagt opdatering af felter.
Den underliggende datakilde bruger målinger
En underliggende datakilde, f.eks. SAP HANA eller SAP BW, indeholder målinger. Målinger betyder, at importerede data allerede er på et bestemt aggregeringsniveau, som defineret af forespørgslen. En visualisering, der beder om data på et højere niveau, f.eks TotalSales by Year, aggregerer den aggregerede værdi yderligere. Denne sammenlægning er fin til additive målinger, f.eks . Sum og Min, men kan være et problem for ikke-additive målinger, f.eks . Average og DistinctCount.
Det kræver nemt at hente de korrekte aggregerede data, der er nødvendige for en visualisering, direkte fra kilden, ved at sende forespørgsler pr. visualisering som i DirectQuery. Når du opretter forbindelse til SAP BW, tillader valg af DirectQuery denne behandling af målinger. Du kan finde flere oplysninger under DirectQuery og SAP BW.
DirectQuery over SAP HANA behandler i øjeblikket data på samme måde som en relationskilde og producerer funktionsmåder, der ligner import. Du kan finde flere oplysninger under DirectQuery og SAP HANA.
DirectQuery-begrænsninger
Brug af DirectQuery har nogle potentielt negative konsekvenser. Nogle af disse begrænsninger varierer en smule afhængigt af den nøjagtige kilde, du bruger. I følgende afsnit beskrives de generelle konsekvenser af brugen af DirectQuery og begrænsninger, der er relateret til ydeevne, sikkerhed, transformationer, modellering og rapportering.
Generelle konsekvenser
Nogle generelle konsekvenser og begrænsninger ved brug af DirectQuery følger:
Hvis dataene ændres, skal du opdatere for at vise de nyeste data. På grund af brugen af cachelagre er der ingen garanti for, at visualiseringer altid viser de nyeste data. En visualisering kan f.eks. vise transaktioner inden for den seneste dag. En ændring af udsnittet kan opdatere visualiseringen for at vise transaktioner for de seneste to dage, herunder seneste nyligt ankomne transaktioner. Men hvis udsnittet returneres til den oprindelige værdi, kan det resultere i, at det igen viser den cachelagrede forrige værdi. Vælg Opdater for at rydde eventuelle cacher og opdatere alle visualiseringer på siden for at få vist de nyeste data.
Hvis data ændres, er der ingen garanti for konsistens mellem visualiseringer. Forskellige visualiseringer, uanset om de er på samme side eller på forskellige sider, opdateres muligvis på forskellige tidspunkter. Hvis dataene i den underliggende kilde ændres, er der ingen garanti for, at hver visualisering viser dataene på samme tidspunkt.
Da der kan være behov for mere end én forespørgsel for en enkelt visualisering, f.eks. for at få oplysninger og totaler, garanteres der ikke ensartethed i en enkelt visualisering. Hvis du vil sikre denne ensartethed, kræver det, at alle visualiseringer opdateres, når en visualisering opdateres, og at der bruges dyre funktioner som snapshotisolation i den underliggende datakilde.
Du kan i høj grad afhjælpe dette problem ved at vælge Opdater for at opdatere alle visualiseringerne på siden. Selv i importtilstand er der et lignende problem med at bevare konsistensen, når du importerer data fra mere end én tabel.
Du skal opdatere i Power BI Desktop for at afspejle skemaændringer. Når en rapport er publiceret, opdaterer Opdater i Power BI-tjeneste visualiseringerne i rapporten. Men hvis det underliggende kildeskema ændres, opdaterer Power BI-tjeneste ikke automatisk listen over tilgængelige felter. Hvis tabeller eller kolonner fjernes fra den underliggende kilde, kan det resultere i forespørgselsfejl ved opdatering. Hvis du vil opdatere felterne i modellen, så de afspejler ændringerne, skal du åbne rapporten i Power BI Desktop og vælge Opdater.
En grænse på 1 million rækker kan returneres for en hvilken som helst forespørgsel. Der er en fast grænse på 1 million rækker, der kan returneres i en enkelt forespørgsel til den underliggende kilde. Denne grænse har generelt ingen praktiske konsekvenser, og visualiseringer viser ikke så mange punkter. Grænsen kan dog forekomme i tilfælde, hvor Power BI ikke optimerer de sendte forespørgsler fuldt ud, og anmoder om et mellemliggende resultat, der overskrider grænsen.
Grænsen kan også forekomme under oprettelse af en visualisering på vejen til en mere rimelig sluttilstand. Hvis du f.eks. inkluderer Customer og TotalSalesQuantity , kan du nå denne grænse, hvis der er mere end 1 million kunder, indtil du anvender et filter. Den fejl, der returnerer, er: Resultatsættet for en forespørgsel til en ekstern datakilde har overskredet den maksimalt tilladte størrelse på '1000000' rækker.
Bemærk
Med Premium-kapaciteter kan du overskride grænsen på én million rækker. Du kan få flere oplysninger under maks. antal mellemliggende rækkesæt.
Du kan ikke ændre en model fra import til DirectQuery-tilstand. Du kan skifte en model fra DirectQuery-tilstand til importtilstand, hvis du importerer alle de nødvendige data. Det er ikke muligt at skifte tilbage til DirectQuery-tilstand, primært på grund af det funktionssæt, som DirectQuery-tilstand ikke understøtter. For flerdimensionelle kilder som SAP BW kan du heller ikke skifte fra DirectQuery til importtilstand på grund af den forskellige behandling af eksterne målinger.
Konsekvenser for ydeevne og belastning
Når du bruger DirectQuery, afhænger den overordnede oplevelse af ydeevnen for den underliggende datakilde. Hvis opdatering af hver visualisering, f.eks. efter ændring af en udsnitsværdi, tager mindre end fem sekunder, er oplevelsen rimelig, selvom den kan føles langsom sammenlignet med det øjeblikkelige svar med importerede data. Hvis kildens langsomhed medfører, at det tager længere tid end ti sekunder at opdatere individuelle visualiseringer, bliver oplevelsen urimeligt dårlig. Forespørgsler kan endda få timeout.
Sammen med ydeevnen for den underliggende kilde påvirker den belastning, der er placeret på kilden, også ydeevnen. Hver bruger, der åbner en delt rapport, og hvert dashboardfelt, der opdateres, sender mindst én forespørgsel pr. visualisering til den underliggende kilde. Kilden skal kunne håndtere en sådan forespørgselsbelastning, samtidig med at der opretholdes en rimelig ydeevne.
Sikkerhedsmæssige konsekvenser
Medmindre den underliggende datakilde bruger SSO, bruger en DirectQuery-rapport altid de samme faste legitimationsoplysninger til at oprette forbindelse til kilden, når den er publiceret til Power BI-tjeneste. Umiddelbart efter du har publiceret en DirectQuery-rapport, skal du konfigurere legitimationsoplysningerne for den bruger, der skal bruges. Indtil du konfigurerer legitimationsoplysningerne, medfører forsøg på at åbne rapporten i Power BI-tjeneste en fejl.
Når du har angivet brugerlegitimationsoplysninger, bruger Power BI disse legitimationsoplysninger til den person, der åbner rapporten, på samme måde som for importerede data. Hver bruger kan se de samme data, medmindre sikkerhed på rækkeniveau er defineret som en del af rapporten. Du skal være opmærksom på at dele rapporten som for importerede data, også selvom der er defineret sikkerhedsregler i den underliggende kilde.
Forbind til semantiske Power BI-modeller og Analysis Services i DirectQuery-tilstand bruger altid SSO, så sikkerheden svarer til direkte forbindelser til Analysis Services.
Alternative legitimationsoplysninger understøttes ikke, når du opretter DirectQuery-forbindelser til SQL Server fra Power BI Desktop. Du kan bruge dine aktuelle Legitimationsoplysninger til Windows eller databaselegitimationsoplysninger.
Du kan bruge flere datakilder i en DirectQuery-model ved hjælp af sammensatte modeller. Når du bruger flere datakilder, er det vigtigt at forstå de sikkerhedsmæssige konsekvenser af, hvordan data bevæger sig frem og tilbage mellem de underliggende datakilder.
Begrænsninger for datatransformation
DirectQuery begrænser de datatransformationer, du kan anvende i Power Query-editor. Med importerede data kan du nemt anvende et avanceret sæt transformationer til at rense og omforme dataene, før du bruger dem til at oprette visualiseringer. Du kan f.eks. fortolke JSON-dokumenter eller pivotere data fra en kolonne til en rækkeformular. Disse transformationer er mere begrænsede i DirectQuery.
Når du opretter forbindelse til en OLAP-kilde (online analytical processing), f.eks. SAP BW, kan du ikke definere nogen transformationer, og hele den eksterne model hentes fra kilden. For relationskilder som SQL Server kan du stadig definere et sæt transformationer pr. forespørgsel, men disse transformationer er begrænset af hensyn til ydeevnen.
Alle transformationer skal anvendes på hver forespørgsel til den underliggende kilde i stedet for én gang ved opdatering af data. Transformationer skal med rimelighed kunne oversættes til en enkelt oprindelig forespørgsel. Hvis du bruger en transformation, der er for kompleks, får du vist en fejl om, at enten den skal slettes, eller at forbindelsesmodellen er skiftet til import.
Dialogboksen Hent data eller Power Query-editor også bruge undermarkeringer i de forespørgsler, de genererer, og sender for at hente data til en visualisering. Forespørgsler, der er defineret i Power Query-editor, skal være gyldige i denne kontekst. Det er især ikke muligt at bruge en forespørgsel med almindelige tabeludtryk eller en, der aktiverer lagrede procedurer.
Begrænsninger for udformning
Udtrykket modellering i denne kontekst betyder, at du skal finjustere og forbedre rådata som en del af oprettelse af en rapport ved hjælp af dataene. Eksempler på modellering omfatter:
- Definition af relationer mellem tabeller.
- Tilføjelse af nye beregninger, f.eks. beregnede kolonner og målinger.
- Omdøbning og skjulning af kolonner og målinger.
- Definition af hierarkier.
- Definition af kolonneformatering, standardopsummering og sorteringsrækkefølge.
- Gruppering eller gruppering af værdier.
Du kan stadig foretage mange af disse modelforbedringer, når du bruger DirectQuery, og bruge princippet om at forbedre rådata til at forbedre senere forbrug. Nogle modelleringsfunktioner er dog ikke tilgængelige eller er begrænset med DirectQuery. Begrænsningerne anvendes for at undgå problemer med ydeevnen.
Følgende begrænsninger er fælles for alle DirectQuery-kilder. Der kan være flere begrænsninger for individuelle kilder.
Intet indbygget datohierarki: Med importerede data har hver dato/datetime-kolonne også et indbygget datohierarki tilgængeligt som standard. Hvis du f.eks. importerer en tabel med salgsordrer, der indeholder en kolonne OrderDate, og du bruger OrderDate i en visualisering, kan du vælge det relevante datoniveau, der skal bruges, f.eks. år, måned eller dag. Dette indbyggede datohierarki er ikke tilgængeligt med DirectQuery. Hvis der er en tilgængelig datotabel i den underliggende kilde, som det er almindeligt i mange data warehouses, kan du bruge DAX-funktionerne (Data Analysis Expressions) som normalt.
Understøttelse af dato/klokkeslæt kun til sekundniveau: For semantiske modeller, der bruger tidskolonner, udsteder Power BI kun forespørgsler til den underliggende DirectQuery-kilde op til detaljeniveauet for sekunder, ikke millisekunder. Fjern millisekunders data fra kildekolonnerne.
Begrænsninger i beregnede kolonner: Beregnede kolonner kan kun være inden for række, dvs. de kan kun referere til værdier i andre kolonner i den samme tabel uden at bruge nogen aggregeringsfunktioner. De tilladte DAX-skalarfunktioner, f.eks
LEFT(). , er også begrænset til de funktioner, der kan pushes til den underliggende kilde. Funktionerne varierer afhængigt af kildens nøjagtige egenskaber. Funktioner, der ikke understøttes, vises ikke i autofuldførelse, når DAX-forespørgslen oprettes for en beregnet kolonne, og resulterer i en fejl, hvis de bruges.Ingen understøttelse af
DAX PATH()overordnede/underordnede DAX-funktioner: Når du er i DirectQuery-tilstand, er det ikke muligt at bruge en række funktioner, der normalt håndterer overordnede/underordnede strukturer, f.eks. diagrammer over konti eller medarbejderhierarkier.Ingen klynger: Når du bruger DirectQuery, kan du ikke bruge klyngefunktionen til automatisk at finde grupper.
Rapporteringsbegrænsninger
Næsten alle rapporteringsfunktioner understøttes for DirectQuery-modeller. Så længe den underliggende kilde tilbyder et passende ydeevneniveau, kan du bruge det samme sæt visualiseringer som til importerede data.
En generel begrænsning er, at den maksimale længde på data i en tekstkolonne for Semantiske DirectQuery-modeller er 32.764 tegn. Rapportering om længere tekster resulterer i en fejl.
Følgende power BI-rapporteringsfunktioner kan medføre problemer med ydeevnen i DirectQuery-baserede rapporter:
Målingsfiltre: Visualiseringer, der bruger målinger eller samlinger af kolonner, kan indeholde filtre i disse målinger. Følgende grafik viser f.eks. SalesAmount efter Kategori, men kun for kategorier med mere end 20 mio . salg.

Denne fremgangsmåde medfører, at der sendes to forespørgsler til den underliggende kilde:
- Den første forespørgsel henter de kategorier, der opfylder betingelsen SalesAmount, der er større end 20 millioner.
- Den anden forespørgsel henter de nødvendige data til visualiseringen, som omfatter de kategorier, der opfylder betingelsen
WHERE.
Denne fremgangsmåde fungerer generelt godt, hvis der er hundreder eller tusinder af kategorier, som i dette eksempel. Ydeevnen kan forringes, hvis antallet af kategorier er meget større. Forespørgslen mislykkes, hvis der er mere end en million kategorier.
TopN-filtre: Du kan definere avancerede filtre for kun at filtrere på de øverste eller nederste
Nværdier, der er rangeret efter en måling. Filtre kan f.eks. omfatte de ti øverste kategorier. Denne fremgangsmåde sender igen to forespørgsler til den underliggende kilde. Den første forespørgsel returnerer dog alle kategorier fra den underliggende kilde, og derefterTopNbestemmes ud fra de returnerede resultater. Afhængigt af kardinaliteten for den involverede kolonne kan denne fremgangsmåde føre til problemer med ydeevnen eller forespørgselsfejl på grund af grænsen på én million rækker for forespørgselsresultater.Median: Alle sammenlægninger, f.eks
Sum. ellerCount Distinct, sendes til den underliggende kilde. Normalt understøttes aggregeringenmediandog ikke af den underliggende kilde. Formedianhentes detaljedataene fra den underliggende kilde, og medianen beregnes ud fra de returnerede resultater. Denne fremgangsmåde er rimelig til beregning af medianen for et relativt lille antal resultater.Der kan opstå problemer med ydeevnen eller forespørgselsfejl, hvis kardinaliteten er stor på grund af grænsen på én million rækker. Det kan f.eks. være rimeligt at forespørge efter medianland/områdepopulation , men mediansalgsprisen er muligvis ikke rimelig.
Avancerede tekstfiltre som "indeholder": Avanceret filtrering af en tekstkolonne tillader filtre som
containsogbegins with. Disse filtre kan resultere i forringet ydeevne for nogle datakilder. Brug især ikke standardfilteretcontains, hvis du har brug for et nøjagtigt match. Selvom resultaterne kan være de samme, afhængigt af de faktiske data, kan ydeevnen være markant anderledes på grund af indekser.Udsnit med flere markeringer: Udsnit tillader som standard kun, at der foretages en enkelt markering. Det kan medføre problemer med ydeevnen at tillade flere markeringer i filtre. Hvis brugeren f.eks. vælger 10 produkter af interesse, medfører hvert nyt valg, at der sendes forespørgsler til kilden. Selvom brugeren kan vælge det næste element, før forespørgslen er fuldført, resulterer denne fremgangsmåde i ekstra belastning på den underliggende kilde.
Totaler i tabelvisualiseringer: Som standard viser tabeller og matrixer totaler og subtotaler. I mange tilfælde kræver hentning af værdierne for sådanne totaler, at der sendes separate forespørgsler til den underliggende kilde. Dette krav gælder, når du bruger
DistinctCountsammenlægning eller i alle tilfælde, der bruger DirectQuery via SAP BW eller SAP HANA. Du kan slå sådanne totaler fra ved hjælp af ruden Format.
DirectQuery-anbefalinger
Dette afsnit indeholder en vejledning på højt niveau om, hvordan du bruger DirectQuery korrekt på grund af dens konsekvenser.
Underliggende datakildeydeevne
Valider, at simple visualiseringer opdateres inden for fem sekunder for at give en rimelig interaktiv oplevelse. Hvis det tager mere end 30 sekunder at opdatere visualiseringer, er det sandsynligt, at yderligere problemer efter rapportpublikationen vil gøre løsningen ubrugelig.
Hvis forespørgslerne er langsomme, skal du undersøge de forespørgsler, der er sendt til den underliggende kilde, og årsagen til den langsomme ydeevne. Du kan få flere oplysninger under Ydelsesdiagnosticering.
Denne artikel dækker ikke den brede vifte af anbefalinger til databaseoptimering på tværs af hele sættet af potentielle underliggende kilder. Følgende standardpraksis for databaser gælder for de fleste situationer:
For at opnå en bedre ydeevne skal du basere relationer på heltalskolonner i stedet for at sammenføje kolonner med andre datatyper.
Opret de relevante indeks. Oprettelse af indeks betyder generelt brug af kolonnelagerindekser i kilder, der understøtter dem, f.eks. SQL Server.
Opdater eventuelle nødvendige statistikker i kilden.
Modeldesign
Når du definerer modellen, skal du følge denne vejledning:
Undgå komplekse forespørgsler i Power Query-editor. Power Query-editor oversætter en kompleks forespørgsel til en enkelt SQL-forespørgsel. Den enkelte forespørgsel vises i undermarkering af hver forespørgsel, der sendes til den pågældende tabel. Hvis denne forespørgsel er kompleks, kan det medføre problemer med ydeevnen for hver forespørgsel, der sendes. Du kan få den faktiske SQL-forespørgsel for et sæt trin ved at højreklikke på det sidste trin under Anvendte trin i Power Query-editor og vælge Vis oprindelig forespørgsel.
Hold målinger enkle. I det mindste indledningsvist skal du begrænse målingerne til simple aggregeringer. Hvis målingerne fungerer tilfredsstillende, kan du definere mere komplekse målinger, men være opmærksom på ydeevnen.
Undgå relationer i beregnede kolonner. I databaser, hvor du skal foretage joinforbindelser med flere kolonner, tillader Power BI ikke, at relationer baseres på flere kolonner som den primære nøgle eller fremmede nøgle. Den almindelige løsning er at sammenkæde kolonnerne ved hjælp af en beregnet kolonne og basere joinforbindelsen på den pågældende kolonne.
Denne midlertidige løsning er rimelig for importerede data, men for DirectQuery resulterer den i en joinforbindelse på et udtryk. Dette resultat forhindrer normalt brug af indekser og medfører dårlig ydeevne. Den eneste løsning er faktisk at materialisere flere kolonner til en enkelt kolonne i den underliggende datakilde.
Undgå relationer i kolonnerne 'uniqueidentifier'. Power BI understøtter ikke en
uniqueidentifierdatatype oprindeligt. Hvis du definerer en relation mellemuniqueidentifierkolonner, resulterer det i en forespørgsel med en joinforbindelse, der omfatter en cast. Igen fører denne tilgang ofte til dårlig ydeevne. Den eneste løsning er at materialisere kolonner af en alternativ type i den underliggende datakilde.Skjul kolonnen 'til' for relationer. Kolonnen
tofor relationer er normalt den primære nøgle itotabellen. Denne kolonne skal være skjult, men hvis den er skjult, vises den ikke på feltlisten og kan ikke bruges i visualiseringer. Ofte er de kolonner, som relationer er baseret på, faktisk systemkolonner, f.eks. surrogatnøgler i et data warehouse. Det er stadig bedst at skjule sådanne kolonner.Hvis kolonnen har betydning, skal du introducere en beregnet kolonne, der er synlig, og som har et simpelt udtryk, der svarer til den primære nøgle, f.eks.:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Undersøg alle beregnede kolonner og ændringer af datatyper. Du kan bruge beregnede tabeller, når du bruger DirectQuery med sammensatte modeller. Disse egenskaber er ikke nødvendigvis skadelige, men de resulterer i forespørgsler, der indeholder udtryk i stedet for simple referencer til kolonner. Disse forespørgsler kan medføre, at indekser ikke bruges.
Undgå tovejskrydsfiltrering på relationer. Brug af tovejskrydsfiltrering kan føre til forespørgselssætninger, der ikke fungerer korrekt. Du kan finde flere oplysninger om tovejskrydsfiltrering under Aktivér tovejskrydsfiltrering for DirectQuery i Power BI Desktop, eller download hvidbogen om tovejskrydsfiltrering . Eksemplerne i papiret er til SQL Server Analysis Services, men de grundlæggende punkter gælder også for Power BI.
Eksperimentér med indstillingen Antag referentiel integritet. Indstillingen Antag referentiel integritet for relationer gør det muligt for forespørgsler at bruge
INNER JOINi stedetOUTER JOINfor sætninger. Denne vejledning forbedrer generelt forespørgselsydeevnen, selvom den afhænger af specifikationerne for datakilden.Brug ikke den relative datafiltrering i Power Query-editor. Det er muligt at definere relativ datofiltrering i Power Query-editor. Du kan f.eks. filtrere efter de rækker, hvor datoen er inden for de sidste 14 dage.

Dette filter oversættes dog til et filter, der er baseret på en fast dato, f.eks. det tidspunkt, hvor forespørgslen blev oprettet, som du kan se i den oprindelige forespørgsel.

Disse data er sandsynligvis ikke, hvad du ønsker. Hvis du vil sikre dig, at filteret anvendes på baggrund af datoen på det tidspunkt, hvor rapporten kører, skal du anvende datofilteret i rapporten. Du kan oprette en beregnet kolonne, der beregner antallet af dage siden ved hjælp af funktionen , og bruge den
DAX DATE()beregnede kolonne i filteret.
Rapportdesign
Når du opretter en rapport, der bruger en DirectQuery-forbindelse, skal du følge denne vejledning:
Overvej at bruge indstillinger til reduktion af forespørgsler: Power BI indeholder rapportindstillinger til at sende færre forespørgsler og til at deaktivere visse interaktioner, der medfører en dårlig oplevelse, hvis det tager lang tid at køre de resulterende forespørgsler. Disse indstillinger gælder, når du interagerer med din rapport i Power BI Desktop, og de gælder også, når brugerne bruger rapporten i Power BI-tjeneste.
Hvis du vil have adgang til disse indstillinger i Power BI Desktop, skal du gå til Filindstillinger>>Indstillinger og vælge Reduktion af forespørgsel.
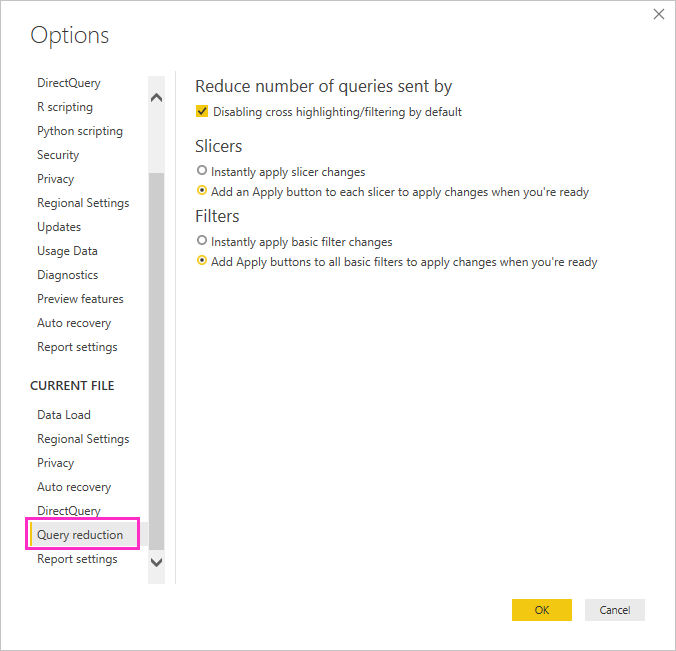
Markeringer på skærmen Reduktion afforespørgsel giver dig mulighed for at få vist knappen Anvend for udsnit eller filtervalg. Der sendes ingen forespørgsler, før du vælger knappen Anvend på filteret eller udsnittet. Forespørgslerne bruger derefter dine valg til at filtrere dataene. Med denne knap kan du foretage flere udsnit og filtervalg, før du anvender dem.
Anvend filtre først: Anvend altid eventuelle relevante filtre i starten af opbygningen af en visualisering. I stedet for f.eks. at trække TotalSalesAmount og ProductName ind og derefter filtrere efter et bestemt år, skal du anvende filteret på Year i begyndelsen.
Hvert trin i opbygningen af en visualisering sender en forespørgsel. Selvom det er muligt at foretage en anden ændring, før den første forespørgsel er fuldført, efterlader denne fremgangsmåde stadig unødvendig belastning på den underliggende kilde. Anvendelse af filtre tidligt gør generelt disse mellemliggende forespørgsler billigere. Hvis du ikke anvender filtre tidligt, kan det resultere i, at du rammer grænsen på en million rækker.
Begræns antallet af visualiseringer på en side: Når du åbner en side eller ændrer et udsnitsværktøj eller et filter på sideniveau, opdateres alle visualiseringerne på siden. Der er en grænse for antallet af parallelle forespørgsler. I takt med at antallet af visualiseringer øges, opdateres nogle visualiseringer serielt, hvilket øger den tid, det tager at opdatere siden. Det er derfor bedst at begrænse antallet af visualiseringer på en enkelt side og i stedet have flere, enklere sider.
Overvej at slå interaktion mellem visualiseringer fra: Som standard kan visualiseringer på en rapportside bruges til at krydsfiltrere og fremhæve de andre visualiseringer på siden. Hvis du f.eks. vælger 1999 i cirkeldiagrammet, fremhæves søjlediagrammet på tværs for at vise salget efter kategori for 1999.
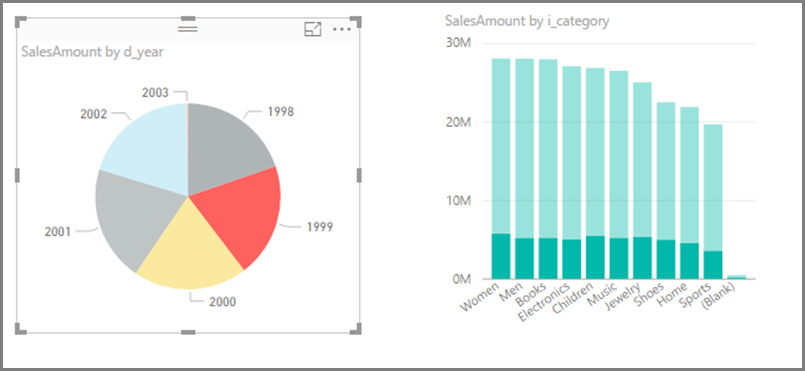
Krydsfiltrering og krydsfremhævning i DirectQuery kræver, at der sendes forespørgsler til den underliggende kilde. Du bør slå denne interaktion fra, hvis den tid, det tager at reagere på brugernes valg, er urimelig lang.
Du kan bruge indstillingerne for reduktion af forespørgsler til at deaktivere tværgående fremhævning i hele rapporten eller fra sag til sag. Du kan få flere oplysninger under Sådan krydsfiltrerer visualiseringer hinanden i en Power BI-rapport.
Maksimalt antal forbindelser
Du kan angive det maksimale antal forbindelser, DirectQuery åbner for hver underliggende datakilde, som styrer antallet af forespørgsler, der sendes samtidigt til hver datakilde.
DirectQuery åbner et maksimalt standardantal på 10 samtidige forbindelser. Hvis du vil ændre det maksimale antal for den aktuelle fil i Power BI Desktop, skal du gå til Filindstillinger>og Indstillinger> Indstillinger og vælge DirectQuery i sektionen Aktuel fil i ruden til venstre.
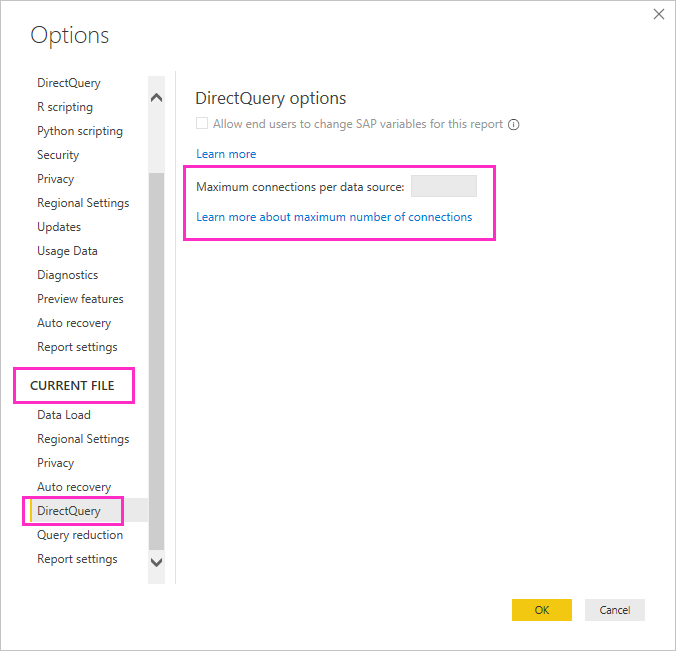
Indstillingen er kun aktiveret, når der er mindst én DirectQuery-kilde i den aktuelle rapport. Værdien gælder for alle DirectQuery-kilder og for alle nye DirectQuery-kilder, der føjes til rapporten.
Hvis du øger Det maksimale antal forbindelser pr. datakilde , kan der sendes flere forespørgsler til den underliggende datakilde op til det angivne maksimale antal. Denne fremgangsmåde er nyttig, når mange visualiseringer er på en enkelt side, eller når mange brugere får adgang til en rapport på samme tid. Når det maksimale antal forbindelser er nået, sættes yderligere forespørgsler i kø, indtil en forbindelse bliver tilgængelig. En højere grænse resulterer i mere belastning på den underliggende kilde, så indstillingen garanteres ikke at forbedre den overordnede ydeevne.
Når du publicerer en rapport til Power BI-tjeneste, afhænger det maksimale antal samtidige forespørgsler også af faste grænser, der er angivet for det destinationsmiljø, hvor rapporten publiceres. Power BI, Power BI Premium og Power BI-rapportserver indføre forskellige grænser. I nedenstående tabel vises de øvre grænser for de aktive forbindelser pr. datakilde for hvert Power BI-miljø. Disse grænser gælder for datakilder i cloudmiljøet og datakilder i det lokale miljø, f.eks. SQL Server, Oracle og Teradata.
| Miljø | Øvre grænse pr. datakilde |
|---|---|
| Power BI Pro | 10 aktive forbindelser |
| Power BI Premium | Afhænger af begrænsningen for semantisk model-SKU |
| Power BI-rapportserver | 10 aktive forbindelser |
Bemærk
Det maksimale antal DirectQuery-forbindelser gælder for alle DirectQuery-kilder, når du aktiverer forbedrede metadata, hvilket er standardindstillingen for alle modeller, der er oprettet i Power BI Desktop.
DirectQuery i Power BI-tjeneste
Alle DirectQuery-datakilder understøttes fra Power BI Desktop, og nogle kilder er også tilgængelige direkte fra Power BI-tjeneste. En virksomhedsbruger kan f.eks. bruge Power BI til at oprette forbindelse til deres data i Salesforce og straks få et dashboard uden at bruge Power BI Desktop.
Kun følgende to DirectQuery-aktiverede kilder er tilgængelige direkte i Power BI-tjeneste:
- Spark
- Azure Synapse Analytics (tidligere SQL Data Warehouse)
Selv for disse to kilder er det stadig bedst at starte DirectQuery-brug i Power BI Desktop. Selvom det er nemt at oprette forbindelse i Power BI-tjeneste, er der begrænsninger for yderligere forbedring af den resulterende rapport. I tjenesten er det f.eks. ikke muligt at oprette nogen beregninger eller bruge mange analysefunktioner eller opdatere metadataene for at afspejle ændringer i det underliggende skema.
Ydeevnen af en DirectQuery-rapport i Power BI-tjeneste afhænger af den belastningsgrad, der er placeret på den underliggende datakilde. Belastningen afhænger af:
- Antallet af brugere, der deler rapporten og dashboardet.
- Rapportens kompleksitet.
- Angiver, om rapporten definerer sikkerhed på rækkeniveau.
Rapportfunktionsmåde i Power BI-tjeneste
Når du åbner en rapport i Power BI-tjeneste, opdateres alle visualiseringer på den aktuelt synlige side. Hver visualisering kræver mindst én forespørgsel til den underliggende datakilde. Nogle visualiseringer kan kræve mere end én forespørgsel. En visualisering kan f.eks. vise aggregerede værdier fra to forskellige faktatabeller eller indeholde en mere kompleks måling eller indeholde totaler for en ikke-additiv måling, f.eks . Count Distinct. Hvis du flytter til en ny side, opdateres disse visualiseringer. Opdatering sender et nyt sæt forespørgsler til den underliggende kilde.
Hver brugerinteraktion i rapporten kan resultere i, at visualiseringer opdateres. Hvis du f.eks. vælger en anden værdi i et udsnitsværktøj, skal du sende et nyt sæt forespørgsler for at opdatere alle de berørte visualiseringer. Det samme gælder for at vælge en visualisering for at fremhæve andre visualiseringer eller ændre et filter. På samme måde kræver oprettelse eller redigering af en rapport, at der sendes forespørgsler for hvert trin på stien for at oprette den endelige visualisering.
Der er nogle cachelagring af resultater. Opdateringen af en visualisering sker øjeblikkeligt, hvis nøjagtigt de samme resultater blev hentet for nylig. Hvis sikkerhed på rækkeniveau er defineret, deles disse cacher ikke på tværs af brugere.
Brug af DirectQuery medfører nogle vigtige begrænsninger i nogle af de funktioner, Power BI-tjeneste tilbyder for publicerede rapporter:
Hurtig indsigt understøttes ikke: Hurtig indsigt i Power BI søger i forskellige undersæt af din semantiske model, mens du anvender et sæt avancerede algoritmer for at finde potentielt interessant indsigt. Da hurtig indsigt kræver forespørgsler med høj ydeevne, er denne funktion ikke tilgængelig på semantiske modeller, der bruger DirectQuery.
Brug af Udforsk i Excel resulterer i dårlig ydeevne: Du kan udforske en semantisk model ved hjælp af funktionen Udforsk i Excel , hvor du kan oprette pivottabeller og pivotdiagrammer i Excel. Denne funktion understøttes for semantiske modeller, der bruger DirectQuery, men ydeevnen er langsommere end at oprette visualiseringer i Power BI. Hvis det er vigtigt at bruge Excel til dine scenarier, skal du tage højde for dette problem ved at beslutte, om du vil bruge DirectQuery.
Excel viser ikke hierarkier: Når du f.eks. bruger Analysér i Excel, viser Excel ikke nogen hierarkier, der er defineret i Azure Analysis Services-modeller eller semantiske Power BI-modeller, der bruger DirectQuery.
Opdatering af dashboard
I Power BI-tjeneste kan du fastgøre individuelle visualiseringer eller hele sider til dashboards som felter. Felter, der er baseret på DirectQuery-semantiske modeller, opdateres automatisk ved at sende forespørgsler til de underliggende datakilder efter en tidsplan. Semantiske modeller opdateres som standard hver time, men du kan konfigurere opdatering mellem ugentligt og hvert 15. minut som en del af semantiske modelindstillinger.
Hvis der ikke er defineret sikkerhed på rækkeniveau i modellen, opdateres hvert felt én gang, og resultaterne deles på tværs af alle brugere. Hvis du bruger sikkerhed på rækkeniveau, kræver hvert felt, at der sendes separate forespørgsler pr. bruger til den underliggende kilde.
Der kan være en stor multiplikatoreffekt. Et dashboard med 10 felter, der er delt med 100 brugere, og som er oprettet på en semantisk model ved hjælp af DirectQuery med sikkerhed på rækkeniveau, resulterer i, at der sendes mindst 1000 forespørgsler til den underliggende datakilde for hver opdatering. Vær opmærksom på brugen af sikkerhed på rækkeniveau og konfigurationen af tidsplanen for opdatering.
Timeout for forespørgsel
Der gælder en timeout på fire minutter for individuelle forespørgsler i Power BI-tjeneste. Forespørgsler, der tager længere tid end fire minutter, mislykkes. Denne grænse er beregnet til at forhindre problemer, der skyldes alt for lange udførelsestider. Du bør kun bruge DirectQuery til kilder, der kan levere interaktiv forespørgselsydeevne.
Ydeevnediagnosticering
I dette afsnit beskrives det, hvordan du diagnosticerer problemer med ydeevnen, eller hvordan du får mere detaljerede oplysninger for at optimere dine rapporter.
Begynd at diagnosticere problemer med ydeevnen i Power BI Desktop i stedet for i Power BI-tjeneste. Problemer med ydeevnen er ofte baseret på ydeevnen for den underliggende kilde. Du kan nemmere identificere og diagnosticere problemer i det mere isolerede Power BI Desktop-miljø.
Denne fremgangsmåde eliminerer indledningsvist visse komponenter, f.eks. Power BI-gatewayen. Hvis der ikke opstår problemer med ydeevnen i Power BI Desktop, kan du undersøge rapportens specifikke egenskaber i Power BI-tjeneste.
Effektivitetsanalyse i Power BI Desktop er et nyttigt værktøj til at identificere problemer. Prøv at isolere eventuelle problemer til én visualisering i stedet for mange visualiseringer på en side. Hvis en enkelt visualisering på en Power BI Desktop-side er langsom, kan du bruge Effektivitetsanalyse til at analysere de forespørgsler, som Power BI Desktop sender til den underliggende kilde.
Du kan også få vist sporings- og diagnosticeringsoplysninger, som nogle underliggende datakilder udsender. Selvom der ikke er nogen sporinger fra kilden, kan sporingsfilen indeholde nyttige oplysninger om, hvordan en forespørgsel kører, og hvordan du kan forbedre den. Du kan bruge følgende proces til at få vist de forespørgsler, Power BI sender, og deres udførelsestider.
Brug SQL Server Profiler til at få vist forespørgsler
Power BI Desktop logfører som standard hændelser i en given session til en sporingsfil med navnet FlightRecorderCurrent.trc. Sporingsfilen findes i Power BI Desktop-mappen for den aktuelle bruger i en mappe med navnet AnalysisServicesWorkspaces.
For nogle DirectQuery-kilder indeholder denne sporingsfil alle forespørgsler, der er sendt til den underliggende datakilde. Følgende datakilder sender forespørgsler til loggen:
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (tidligere SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
Du kan læse sporingsfilerne ved hjælp af SQL Server Profiler, som er en del af den gratis download af SQL Server Management Studio.

Sådan åbner du sporingsfilen for den aktuelle session:
Under en Power BI Desktop-session skal du vælge Filindstillinger>>Indstillinger og derefter vælge Diagnosticering.
Under Samling af nedbrudsdump skal du vælge Åbn mappen crashdump/sporinger.
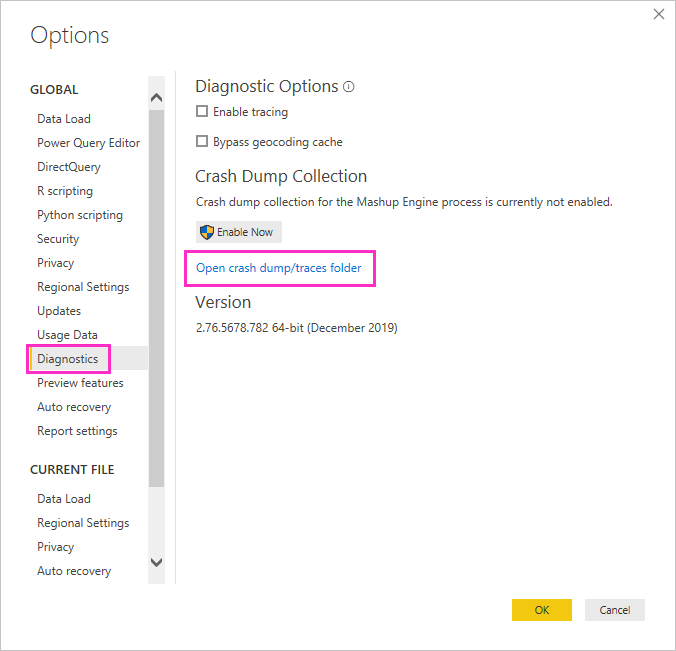
Mappen Power BI Desktop\Traces åbnes.
Gå til den overordnede mappe og derefter til mappen AnalysisServicesWorkspaces , som indeholder én arbejdsområdemappe for hver åbne forekomst af Power BI Desktop. Disse mapper er navngivet med et heltalssuffiks, f.eks AnalysisServicesWorkspace2058279583. Arbejdsområdemappen slettes, når den tilknyttede Power BI Desktop-session slutter.
I arbejdsområdemappen for den aktuelle Power BI-session indeholder mappen \Data sporingsfilen FlightRecorderCurrent.trc . Noter lokationen.
Åbn SQL Server Profiler, og vælg Fil>Åbn>sporingsfil.
Gå til eller angiv stien til sporingsfilen for den aktuelle Power BI-session, og åbn FlightRecorderCurrent.trc.
SQL Server Profiler viser alle hændelser fra den aktuelle session. På følgende skærmbillede fremhæves en gruppe af hændelser for en forespørgsel. Hver forespørgselsgruppe har følgende hændelser:
En
Query BeginogQuery End-hændelse, der repræsenterer starten og slutningen af en DAX-forespørgsel, der genereres ved at ændre en visualisering eller et filter i Brugergrænsefladen i Power BI eller fra at filtrere eller transformere data i Power Query-editor.Et eller flere par af
DirectQuery Beginhændelserne ogDirectQuery End, som repræsenterer forespørgsler, der er sendt til den underliggende datakilde som en del af evalueringen af DAX-forespørgslen.

Flere DAX-forespørgsler kan køre parallelt, så hændelser fra forskellige grupper kan flettes. Du kan bruge værdien ActivityID til at bestemme, hvilke hændelser der tilhører den samme gruppe.
Følgende kolonner er også interessante:
- TextData: Hændelsens tekstdetaljer. For
Query BeginogQuery End-hændelser er detaljerne DAX-forespørgslen. ForDirectQuery BeginogDirectQuery End-hændelser er detaljen den SQL-forespørgsel, der sendes til den underliggende kilde. TextData for den aktuelt valgte hændelse vises også i ruden nederst på skærmen. - EndTime: Det tidspunkt, hvor hændelsen blev fuldført.
- Varighed: I millisekunder tog det at køre DAX- eller SQL-forespørgslen.
- Fejl: Om der opstod en fejl, og i så fald vises hændelsen også med rødt.
Sådan registrerer du en sporing for at hjælpe med at diagnosticere et potentielt problem med ydeevnen:
Åbn en enkelt Power BI Desktop-session for at undgå forvirring i forbindelse med flere arbejdsområdemapper.
Gør det sæt handlinger, der er interessante i Power BI Desktop. Medtag nogle flere handlinger for at sikre, at de interessante hændelser ryddes i sporingsfilen.
Åbn SQL Server Profiler, og undersøg sporingen. Husk, at hvis du lukker Power BI Desktop, slettes sporingsfilen. Desuden vises yderligere handlinger i Power BI Desktop ikke med det samme. Du skal lukke sporingsfilen og åbne den igen for at få vist nye hændelser.
Bevar individuelle sessioner, der er rimeligt små, måske 10 sekunders handlinger, ikke hundredvis. Denne fremgangsmåde gør det nemmere at fortolke sporingsfilen. Der er også en grænse for størrelsen på sporingsfilen. I lange sessioner er der en chance for, at tidlige hændelser bliver droppet.
Forstå formatet af forespørgsler
Det generelle format for Power BI Desktop-forespørgsler bruger undermarkeringer for hver tabel, de refererer til. Forespørgslen Power Query-editor definerer undermarkeringsforespørgslerne. Antag f.eks., at du har følgende TPC-DS-tabeller i SQL Server:
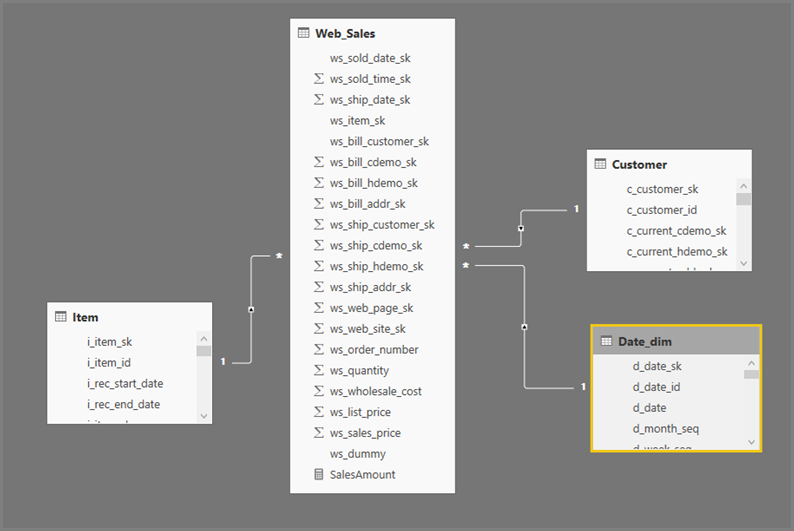
Kører følgende forespørgsel:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Resulterer i følgende visualisering i Power BI:
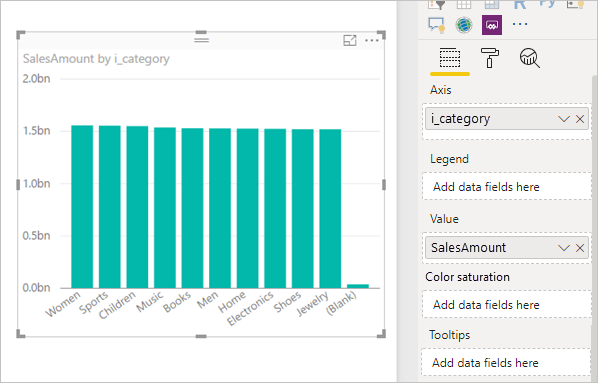
Hvis du opdaterer visualiseringen, oprettes SQL-forespørgslen på følgende billede. Der er tre undermarkeringsforespørgsler for Web_Sales, Itemog Date_dim, som hver især returnerer alle kolonnerne i den respektive tabel, selvom visualiseringen kun refererer til fire kolonner.

Power Query-editor definerer de nøjagtige forespørgsler undermarkeringer. Denne brug af undermarkeringsforespørgsler har ikke vist sig at påvirke ydeevnen for de datakilder, Som DirectQuery understøtter. Datakilder som SQL Server optimerer henvisningerne til de andre kolonner væk.
Power BI bruger dette mønster, fordi analytikeren leverer SQL-forespørgslen direkte. Power BI bruger forespørgslen som angivet uden at forsøge at omskrive den.
Relateret indhold
Du kan finde flere oplysninger om DirectQuery i Power BI under:
I denne artikel beskrives aspekter af DirectQuery, der er fælles på tværs af alle datakilder. Se følgende artikler for at få oplysninger om bestemte kilder: