Anvend mange til mange-relationer i Power BI Desktop
Med relationer med en mange til mange-kardinalitet i Power BI Desktop kan du joinforbinde tabeller, der bruger en kardinalitet på mange til mange. Du kan nemmere og intuitivt oprette datamodeller, der indeholder to eller flere datakilder. Relationer med en mange til mange-kardinalitet er en del af de større funktioner til sammensatte modeller i Power BI Desktop. Du kan få flere oplysninger om sammensatte modeller under Brug sammensatte modeller i Power BI Desktop
Hvad en relation med en mange til mange-kardinalitet løser
Før relationer med en mange til mange-kardinalitet blev tilgængelige, blev relationen mellem to tabeller defineret i Power BI. Mindst en af de tabelkolonner, der er involveret i relationen, skulle indeholde entydige værdier. Men ofte indeholdt ingen kolonner entydige værdier.
To tabeller kan f.eks. have en kolonne med navnet CountryRegion. Værdierne for CountryRegion var dog ikke entydige i nogen af tabellerne. Hvis du vil joinforbinde sådanne tabeller, skulle du oprette en løsning. En løsning kan være at introducere ekstra tabeller med de nødvendige entydige værdier. Med relationer med en mange til mange-kardinalitet kan du joinforbinde sådanne tabeller direkte, hvis du bruger en relation med en kardinalitet på mange til mange.
Brug relationer med en mange til mange-kardinalitet
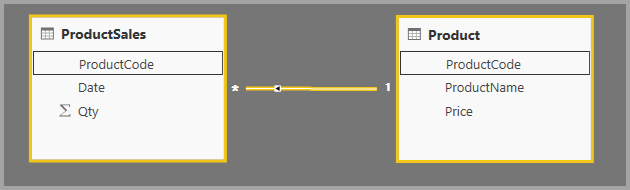
Når du definerer en relation mellem to tabeller i Power BI, skal du definere kardinaliteten for relationen. Relationen mellem ProductSales og Product – ved hjælp af kolonnerne ProductSales[ProductCode] og Product[ProductCode]– ville f.eks. være defineret som Mange-1. Vi definerer relationen på denne måde, fordi hvert produkt har mange salg, og kolonnen i tabellen Product (ProductCode) er entydig. Når du definerer en relationskardinalitet som Mange-1, 1-Mange eller 1-1, validerer Power BI den, så den kardinalitet, du vælger, svarer til de faktiske data.
Tag f.eks. et kig på den enkle model på dette billede:
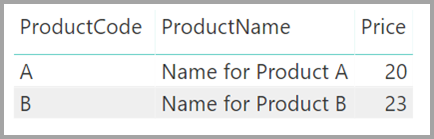
Forestil dig nu, at tabellen Product kun viser to rækker som vist:
Forestil dig også, at tabellen Sales kun indeholder fire rækker, herunder en række for et produkt C. På grund af en referentiel integritetsfejl findes rækken produkt C ikke i tabellen Product .
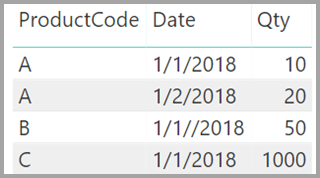
ProductName og Price (fra tabellen Product) sammen med det samlede antal for hvert produkt (fra tabellen ProductSales) vises som vist:

Som du kan se på det foregående billede, er der knyttet en tom Række af typen ProductName til salg for produkt C. Denne tomme række tager højde for følgende overvejelser:
Alle rækker i tabellen ProductSales , hvor der ikke findes en tilsvarende række i tabellen Product . Der er et problem med referentiel integritet, som vi kan se for produkt C i dette eksempel.
Alle rækker i tabellen ProductSales , hvor kolonnen med den fremmede nøgle er null.
Af disse årsager står den tomme række i begge tilfælde for salg, hvor ProductName og Price er ukendte.
Nogle gange er tabellerne joinforbundet af to kolonner, men ingen af kolonnerne er entydige. Overvej f.eks. disse to tabeller:
I tabellen Sales vises salgsdata efter State, og hver række indeholder salgsbeløbet for salgstypen i den pågældende stat. Staterne omfatter CA, WA og TX.
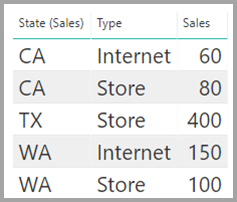
I tabellen CityData vises data om byer, herunder populationen og staten (f.eks. CA, WA og New York).

Der findes nu en kolonne for State i begge tabeller. Det er rimeligt at rapportere om både det samlede salg efter stat og den samlede befolkning i hver stat. Der findes dog et problem: Kolonnen State er ikke entydig i nogen af tabellerne.
Den forrige midlertidige løsning
Før udgivelsen af Power BI Desktop fra juli 2018 kunne du ikke oprette en direkte relation mellem disse tabeller. En almindelig løsning var at:
Opret en tredje tabel, der kun indeholder de entydige tilstands-id'er. Tabellen kan være en af eller alle:
- En beregnet tabel (defineret ved hjælp af DATA Analysis Expressions [DAX]).
- En tabel, der er baseret på en forespørgsel, der er defineret i Power Query-editor, som kan vise de entydige id'er, der er trukket fra en af tabellerne.
- Det kombinerede fulde sæt.
Relater derefter de to oprindelige tabeller til den nye tabel ved hjælp af almindelige Mange-1-relationer .
Du kan lade tabellen med den midlertidige løsning være synlig. Du kan også skjule tabellen med løsninger, så den ikke vises på listen Felter . Hvis du skjuler tabellen, angives mange-1-relationerne ofte til at filtrere i begge retninger, og du kan bruge feltet State fra begge tabeller. Sidstnævnte krydsfiltrering overføres til den anden tabel. Denne fremgangsmåde vises på følgende billede:
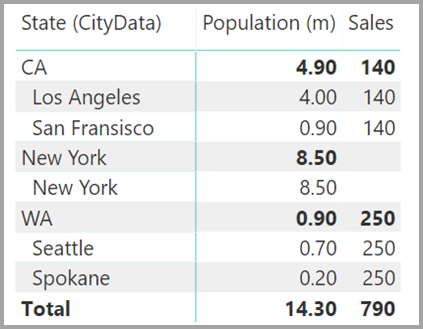
Et visuelt element, der viser State (fra tabellen CityData ) sammen med den samlede population og det samlede salg, vises derefter på følgende måde:

Bemærk
Da staten fra tabellen CityData bruges i denne midlertidige løsning, er det kun staterne i tabellen, der er angivet, så TX er udeladt. I modsætning til Mange-1-relationer , mens rækken Total indeholder alle Sales (herunder dem for TX), indeholder detaljerne ikke en tom række, der dækker sådanne uoverensstemmende rækker. På samme måde dækker ingen tom række Sales , hvor der er en null-værdi for State.
Lad os antage, at du også føjer City til denne visualisering. Selvom populationen pr. By er kendt, gentager Sales, der vises for City, ganske enkelt Sales for den tilsvarende State. Dette scenarie opstår normalt, når kolonnegruppering ikke er relateret til en aggregeret måling, som vist her:
Lad os sige, at du definerer den nye tabel Sales som kombinationen af alle Stater her, og vi gør den synlig på listen Felter . Den samme visualisering viser State (i den nye tabel), den samlede Population og det samlede salg:
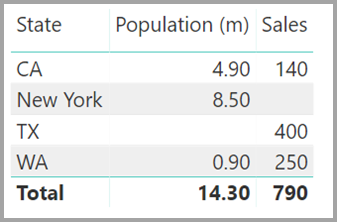
Som du kan se, vil TX – med salgsdata , men ukendte Population-data – og New York – med kendte Population-data , men ingen salgsdata , være inkluderet. Denne løsning er ikke optimal, og den har mange problemer. For relationer med en mange til mange-kardinalitet håndteres de deraf følgende problemer, som beskrevet i næste afsnit.
Du kan finde flere oplysninger om implementering af denne løsning under Vejledning til mange til mange-relationer.
Brug en relation med en mange til mange-kardinalitet i stedet for løsningen
Du kan relatere tabeller direkte, f.eks. dem, vi beskrev tidligere, uden at skulle ty til lignende løsninger. Det er nu muligt at angive relationskardinaliteten til mange til mange. Denne indstilling angiver, at ingen af tabellerne indeholder entydige værdier. I forbindelse med sådanne relationer kan du stadig styre, hvilken tabel der filtrerer den anden tabel. Du kan også anvende tovejsfiltrering, hvor hver tabel filtrerer den anden.
I Power BI Desktop er kardinaliteten som standard mange til mange , når den bestemmer, at ingen af tabellerne indeholder entydige værdier for relationskolonnerne. I sådanne tilfælde bekræfter en advarselsmeddelelse, at du vil angive en relation, og at ændringen ikke er den utilsigtede effekt af et dataproblem.
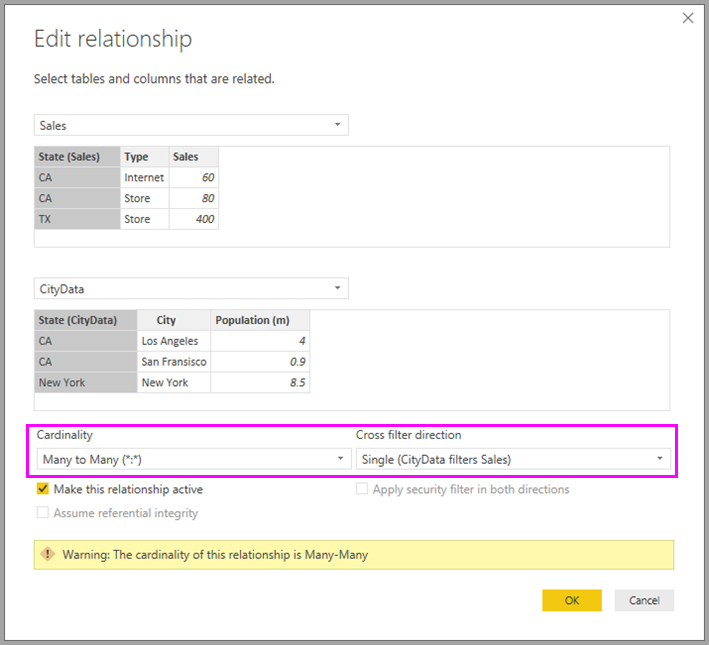
Når du f.eks. opretter en relation direkte mellem CityData og Sales – hvor filtre skal gå fra CityData til Sales – viser Power BI Desktop dialogboksen Rediger relation :
Den resulterende relationsvisning viser derefter den direkte mange til mange-relation mellem de to tabeller. Tabellernes udseende på listen Felter og deres senere funktionsmåde, når visualiseringerne oprettes, svarer til, da vi anvendte løsningen. I løsningen gøres den ekstra tabel, der viser de entydige tilstandsdata, ikke synlige. Som beskrevet tidligere vises en visualisering, der viser data for State, Population og Sales :

De største forskelle mellem relationer med en mange til mange-kardinalitet og de mere typiske Mange-1-relationer er som følger:
De viste værdier indeholder ikke en tom række, der står for uoverensstemmende rækker i den anden tabel. Værdierne tager heller ikke højde for rækker, hvor den kolonne, der bruges i relationen i den anden tabel, er null.
Du kan ikke bruge funktionen
RELATED(), fordi mere end én række kan være relateret.Brug af funktionen
ALL()i en tabel fjerner ikke filtre, der er anvendt på andre relaterede tabeller af en mange til mange-relation. I det foregående eksempel ville en måling, der er defineret som vist her, ikke fjerne filtre på kolonner i den relaterede CityData-tabel:![Screenshot of a script example. The example is, Sales total = Calculate(Sum('Sales'[Sales]), All('Sales')).](media/desktop-many-to-many-relationships/many-to-many-relationships_13.png)
En visualisering, der viser data for State, Sales og Sales total , vil resultere i denne grafik:
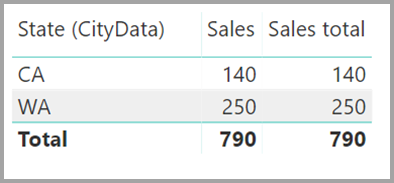
Med de foregående forskelle i tankerne skal du sørge for, at de beregninger, der bruger ALL(<Table>), f.eks . % af hovedtotalen, returnerer de forventede resultater.
Overvejelser og begrænsninger
Der er nogle få begrænsninger for denne version af relationer med mange til mange-kardinalitet og sammensatte modeller.
Følgende live-Forbind (flerdimensionelle) kilder kan ikke bruges sammen med sammensatte modeller:
- SAP HANA
- SAP Business Warehouse
- SQL Server Analysis Services
- Semantiske Power BI-modeller
- Azure Analysis Service
Når du opretter forbindelse til disse flerdimensionelle kilder ved hjælp af DirectQuery, kan du ikke oprette forbindelse til en anden DirectQuery-kilde eller kombinere den med importerede data.
De eksisterende begrænsninger ved at bruge DirectQuery gælder stadig, når du bruger relationer med en mange til mange-kardinalitet. Der er nu mange begrænsninger pr. tabel, afhængigt af tabellens lagringstilstand. En beregnet kolonne i en importeret tabel kan f.eks. referere til andre tabeller, men en beregnet kolonne i en DirectQuery-tabel kan stadig kun referere til kolonner i den samme tabel. Der gælder andre begrænsninger for hele modellen, hvis nogen tabeller i modellen er DirectQuery. Funktionerne QuickInsights og Q&A er f.eks. ikke tilgængelige for en model, hvis en tabel i den har lagringstilstanden DirectQuery.
Relateret indhold
Du kan finde flere oplysninger om sammensatte modeller og DirectQuery i følgende artikler:
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om