In diesem Artikel wird beschrieben, wie ein Entwicklungsteam Metriken verwendet, um Engpässe zu ermitteln und die Leistung eines verteilten Systems zu verbessern. Der Artikel basiert auf den tatsächlichen Auslastungstests, die wir für eine Beispielanwendung durchgeführt haben. Die Anwendung stammt aus der Azure Kubernetes Service-Baseline (AKS) für Microservices, zusammen mit einem Visual Studio Auslastungstestprojekt, das zum Generieren der Ergebnisse verwendet wird.
Dieser Artikel ist Teil einer Serie. Lesen Sie hier den ersten Teil.
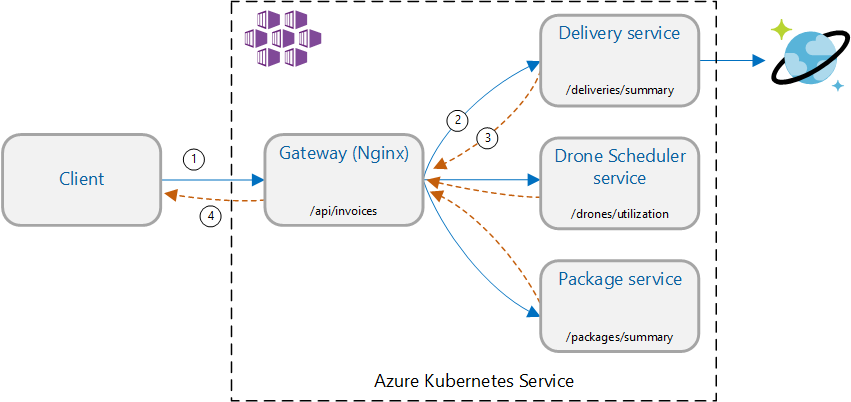
Szenario: Aufrufen mehrerer Back-End-Dienste zum Abrufen von Informationen und Aggregieren der Ergebnisse.
Dieses Szenario umfasst eine Drohnenlieferungsanwendung. Clients können eine REST-API abfragen, um ihre neuesten Rechnungsinformationen zu erhalten. Die Rechnung enthält eine Zusammenfassung von Lieferungen, Paketen und gesamter Drohnennutzung des Kunden. Diese Anwendung verwendet eine Microservicesarchitektur, die unter AKS ausgeführt wird, und die für die Rechnung benötigten Informationen sind auf mehrere Microservices verteilt.
Anstatt dass der Client jeden Dienst direkt aufruft, implementiert die Anwendung das Gatewayaggregationsmuster. Bei diesem Muster sendet der Client eine einzelne Anforderung an einen Gatewaydienst. Das Gateway ruft wiederum die Back-End-Dienste parallel auf und aggregiert die Ergebnisse dann in einer einzelnen Antwortnutzlast.
Test 1: Baselineleistung
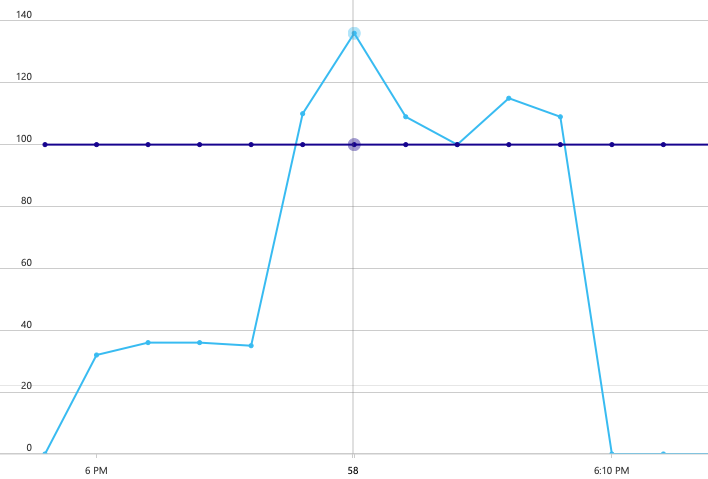
Zum Einrichten einer Baseline begann das Entwicklungsteam mit einem Schrittauslastungstest, in dem die Last während einer Gesamtdauer von 8 Minuten von einem simulierten Benutzer auf bis zu 40 gesteigert wurde. Das folgende Diagramm aus Visual Studio zeigt die Ergebnisse. Die violette Linie zeigt die Benutzerauslastung und die orangefarbene Linie den Durchsatz (durchschnittliche Anzahl von Anforderungen pro Sekunde) an.
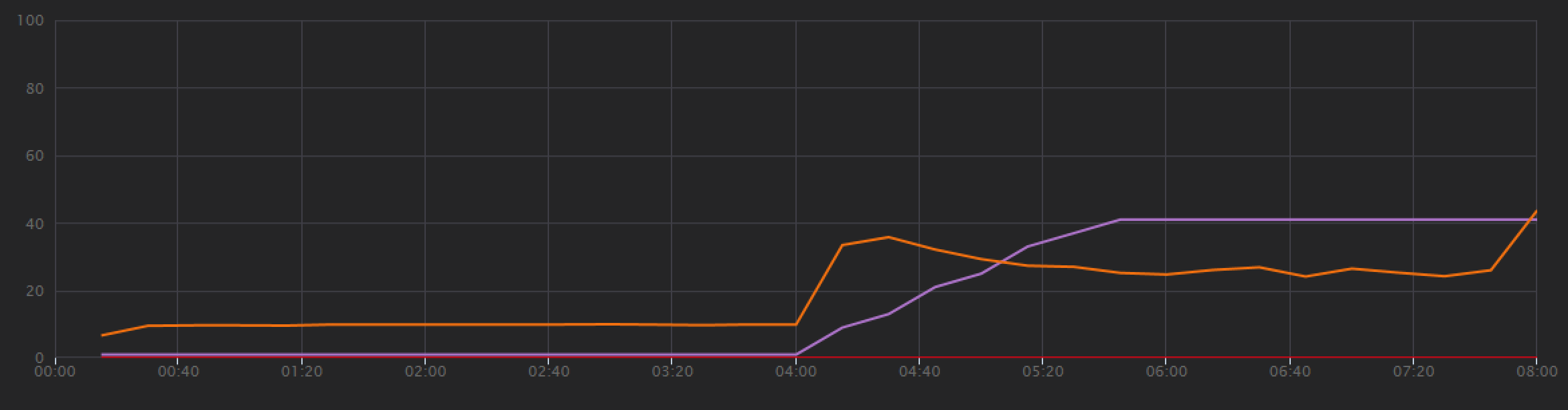
Die rote Linie entlang des unteren Rands des Diagramms zeigt an, dass keine Fehler an den Client zurückgegeben wurden, was ein positives Ergebnis ist. Der durchschnittliche Durchsatz steigt jedoch in der ersten Hälfte des Tests an und fällt dann für den Rest ab, auch wenn die Auslastung weiterhin zunimmt. Dies zeigt, dass das Back-End nicht mithalten kann. Dieses Muster tritt häufig auf, wenn ein System Ressourcenlimits erreicht – nach Erreichen eines Maximums sinkt der Durchsatz erheblich. Ressourcenkonflikte, vorübergehende Fehler oder eine Erhöhung der Anzahl von Ausnahmen können zu diesem Muster beitragen.
Wir analysieren nun die Überwachungsdaten, um zu erfahren, was innerhalb des Systems passiert. Das nächste Diagramm stammt aus Application Insights. Es zeigt die durchschnittliche Dauer der HTTP-Aufrufe des Gateways an die Back-End-Dienste.
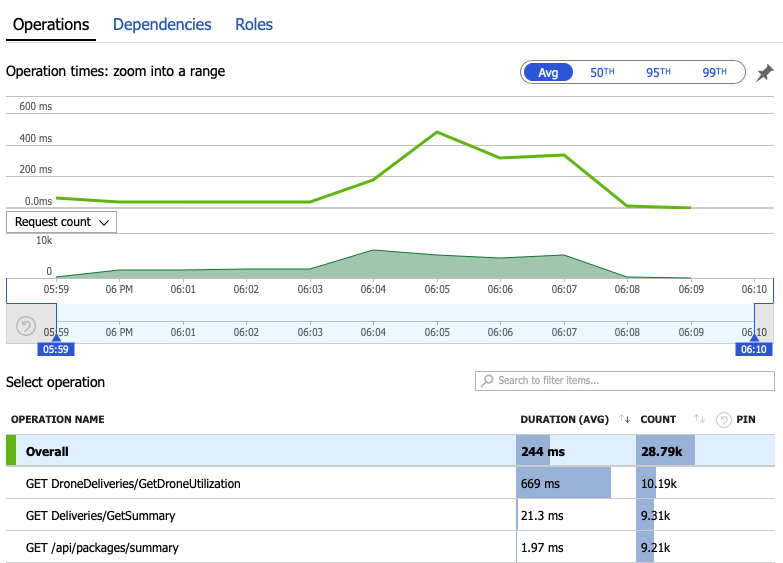
Dieses Diagramm zeigt, dass insbesondere der Vorgang GetDroneUtilization im Durchschnitt erheblich länger dauert – er liegt in einer anderen Größenordnung. Das Gateway führt diese Aufrufe parallel aus, sodass die langsamste Operation bestimmt, wie lange es dauert, bis die gesamte Anforderung abgeschlossen ist.
Der nächste Schritt besteht also darin, den Vorgang GetDroneUtilization zu untersuchen und Engpässe zu finden. Eine Möglichkeit ist die Ressourcenauslastung. Möglicherweise stehen diesem Back-End-Dienst nicht genügend CPU- oder Arbeitsspeicherressourcen zur Verfügung. Für einen AKS-Cluster sind diese Informationen im Azure-Portal über das Feature Azure Monitor Container Insights verfügbar. Die folgenden Diagramme zeigen die Ressourcennutzung auf Clusterebene:
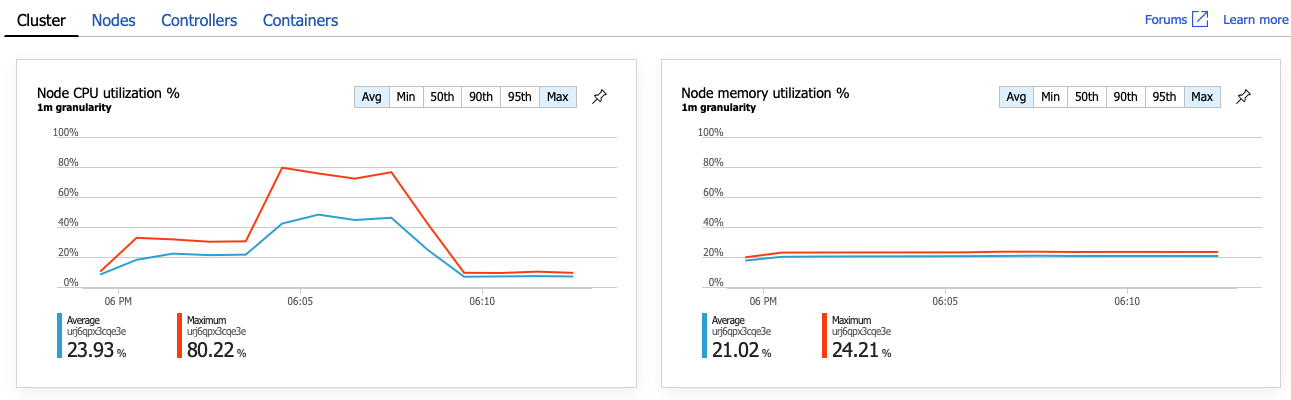
In diesem Screenshot werden sowohl die Durchschnittswerte als auch die Höchstwerte angezeigt. Es ist wichtig, nicht nur den Durchschnitt anzusehen, da der Durchschnitt Spitzenwerte in den Daten verbergen kann. Hier bleibt die durchschnittliche CPU-Auslastung unter 50 %, aber es gibt eine Reihe von Spitzen bis 80 %. Dies liegt nahe an der Kapazitätsgrenze, aber immer noch innerhalb von Toleranzen. Der Engpass hat eine andere Ursache.
Das nächste Diagramm zeigt den wahren Schuldigen. Dieses Diagramm zeigt die HTTP-Antwortcodes aus der Back-End-Datenbank des Lieferdiensts, in diesem Fall Azure Cosmos DB. Die blaue Linie stellt Erfolgscodes (HTTP 2xx) dar, während die grüne Linie HTTP 429-Fehler darstellt. Ein HTTP 429-Rückgabecode bedeutet, dass Azure Cosmos DB vorübergehend Anforderungen drosselt, da der Aufrufer mehr Ressourceneinheiten (Request Units, RU) als bereitgestellt beansprucht.
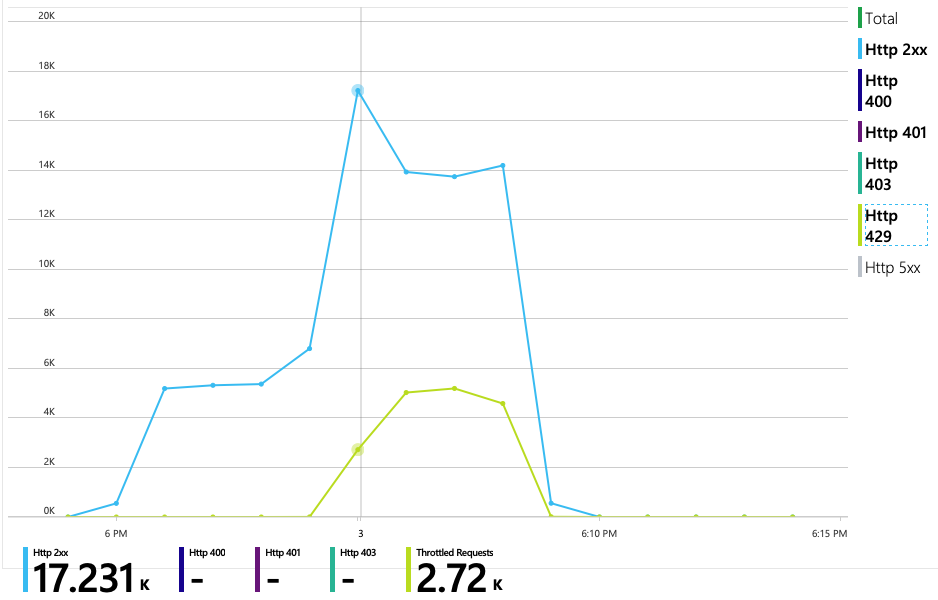
Um weitere Einblicke zu erhalten, hat das Entwicklungsteam Application Insights verwendet, um die End-to-End-Telemetrie für eine repräsentative Stichprobe von Anforderungen anzuzeigen. Hier ist ein Beispiel:
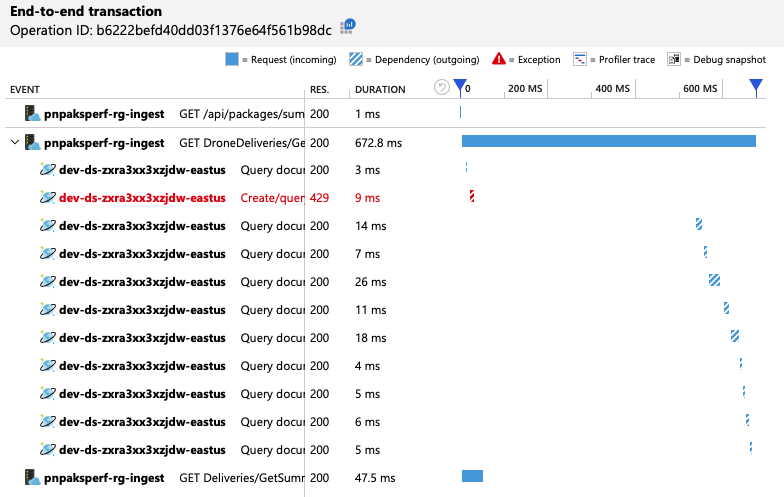
In dieser Ansicht werden die Aufrufe einer einzelnen Clientanforderung zusammen mit Timinginformationen und Antwortcodes angezeigt. Die Aufrufe der obersten Ebene erfolgen vom Gateway an die Back-End-Dienste. Der Aufruf von GetDroneUtilization wird erweitert, um Aufrufe externer Abhängigkeiten anzuzeigen – in diesem Fall an Azure Cosmos DB. Der Aufruf in Rot hat einen HTTP 429-Fehler zurückgegeben.
Beachten Sie die große Lücke zwischen dem HTTP 429-Fehler und dem nächsten Aufruf. Wenn die Azure Cosmos DB-Clientbibliothek einen HTTP 429-Fehler empfängt, stoppt sie automatisch und wartet auf die Wiederholung des Vorgangs. Diese Ansicht zeigt, dass der größte Teil der 672 ms, die dieser Vorgang gedauert hat, für das Warten auf die Wiederholung des Aufrufs an Azure Cosmos DB aufgewendet wurde.
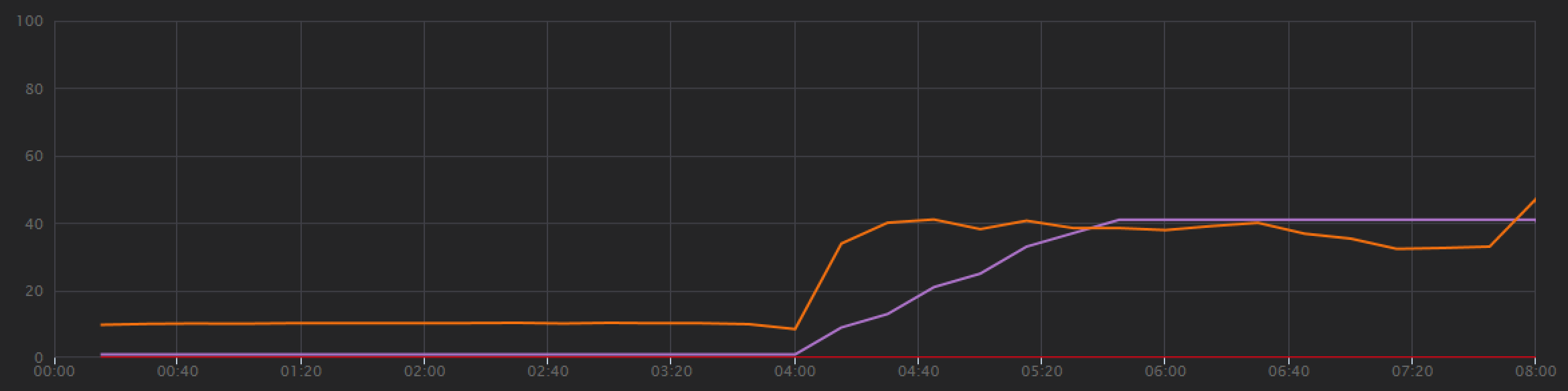
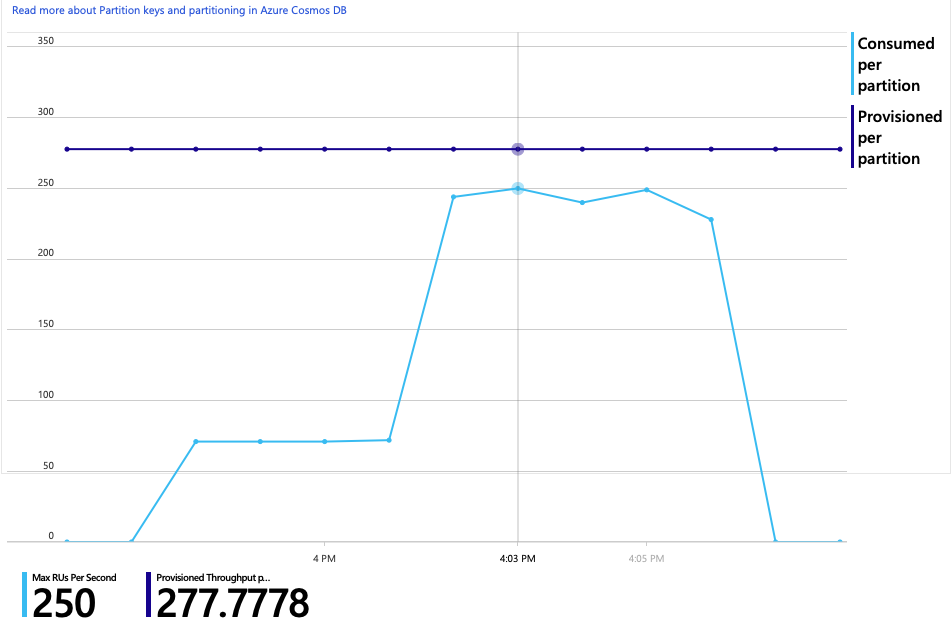
Im Folgenden finden Sie ein weiteres interessantes Diagramm für diese Analyse. Es zeigt den RU-Verbrauch pro physischer Partition im Vergleich zu bereitgestellten RUs pro physischer Partition:
Um dieses Diagramm verstehen zu können, müssen Sie verstehen, wie Azure Cosmos DB Partitionen verwaltet. Sammlungen in Azure Cosmos DB können über einen Partitionsschlüsselverfügen. Jeder mögliche Schlüsselwert definiert eine logische Partition der Daten in der Sammlung. Azure Cosmos DB verteilt diese logischen Partitionen auf eine oder mehrere physische Partitionen. Die Verwaltung physischer Partitionen wird automatisch von Azure Cosmos DB durchgeführt. Wenn Sie immer mehr Daten speichern, könnte Azure Cosmos DB logische Partitionen in neue physische Partitionen verschieben, um die Last auf die physischen Partitionen zu verteilen.
Für diesen Auslastungstest wurde die Azure Cosmos DB-Sammlung mit 900 RUs bereitgestellt. Das Diagramm zeigt 100 RUs pro physischer Partition, sodass insgesamt neun physische Partitionen vorhanden sind. Azure Cosmos DB führt das Sharding physischer Partitionen zwar automatisch durch, aber die Anzahl der Partitionen zu kennen, hilft Ihnen, einen Einblick in die Leistung zu erhalten. Das Entwicklungsteam verwendet diese Informationen später, wenn es die Optimierung fortsetzt. Wenn die blaue Linie die violette horizontale Linie kreuzt, hat der RU-Verbrauch die bereitgestellten RUs überschritten. An diesem Punkt beginnt Azure Cosmos DB mit der Drosselung von Aufrufen.
Test 2: Erhöhen der Ressourceneinheiten
Für den zweiten Auslastungstest hat das Team die Azure Cosmos DB-Sammlung von 900 RUs auf 2500 RUs horizontal hochskaliert. Der Durchsatz wurde von 19 Anforderungen/Sekunde auf 23 Anforderungen/Sekunde erhöht und die durchschnittliche Latenz von 669 ms auf 569 ms gesenkt.
| Metrik | Test 1 | Test 2 |
|---|---|---|
| Durchsatz (Anforderungen/Sekunde) | 19 | 23 |
| Durchschnittliche Latenz (ms) | 669 | 569 |
| Erfolgreiche Anforderungen | 9,8 Tsd. | 11 Tsd. |
Dies sind keine enormen Vorteile, aber das Diagramm zeigt im Zeitverlauf ein vollständigeres Bild:
Während der vorherige Test eine anfängliche Spitze gefolgt von einem scharfen Abfall zeigte, zeigt dieser Test einen konsistenteren Durchsatz. Der maximale Durchsatz ist jedoch nicht wesentlich höher.
Alle Anforderungen an Azure Cosmos DB gaben einen den 2xx-Status zurück, und die HTTP 429-Fehler verschwanden:
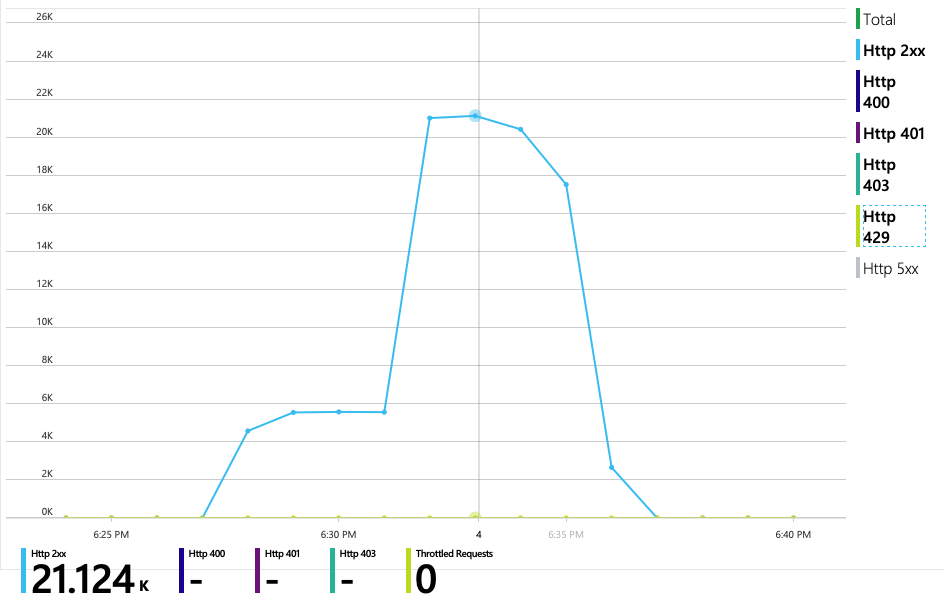
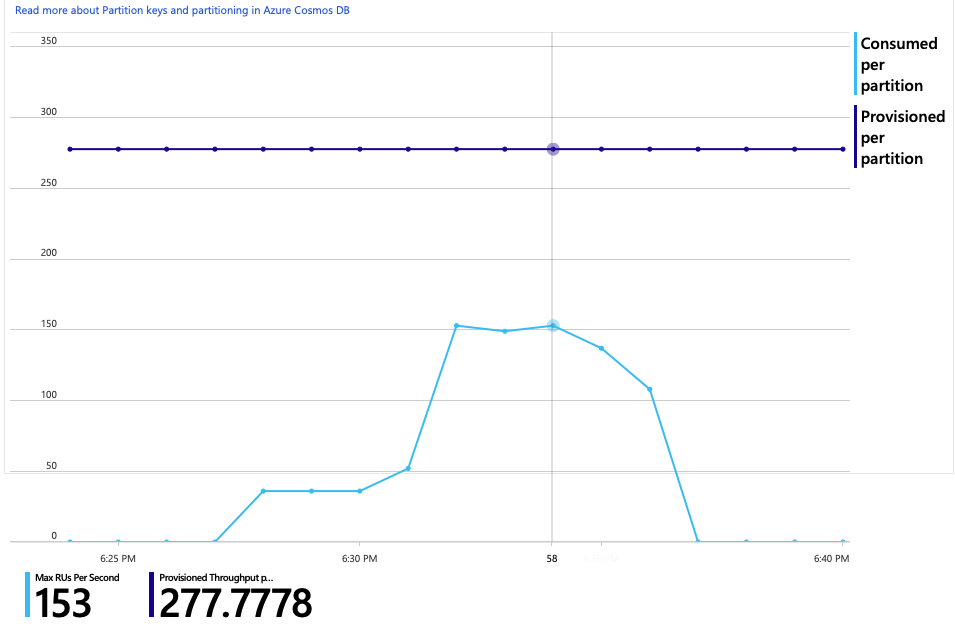
Das Diagramm des RU-Verbrauchs im Vergleich zu bereitgestellten RUs zeigt einen großen Spielraum. Es stehen ungefähr 275 RUs pro physischer Partition zur Verfügung, und die Spitze des Auslastungstests lag bei etwa 100 RUs pro Sekunde.
Eine weitere interessante Metrik ist die Anzahl der Aufrufe an Azure Cosmos DB pro erfolgreichem Vorgang:
| Metrik | Test 1 | Test 2 |
|---|---|---|
| Aufrufe pro Vorgang | 11 | 9 |
Wenn keine Fehler auftreten, sollte die Anzahl der Aufrufe mit dem tatsächlichen Abfrageplan identisch sein. In diesem Fall umfasst der Vorgang eine partitionsübergreifende Abfrage, die auf alle neun physischen Partitionen trifft. Der höhere Wert im ersten Auslastungstest spiegelt die Anzahl der Aufrufe wider, die einen 429-Fehler zurückgegeben haben.
Diese Metrik wurde durch Ausführen einer benutzerdefinierten Log Analytics-Abfrage berechnet:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Zusammenfassend zeigt der zweite Auslastungstest eine Verbesserung. Der GetDroneUtilization-Vorgang liegt jedoch immer noch in einer anderen Größenordnung als der nächstlangsamste Vorgang. Ein Blick auf die End-to-End-Transaktionen trägt zur Erklärung bei:
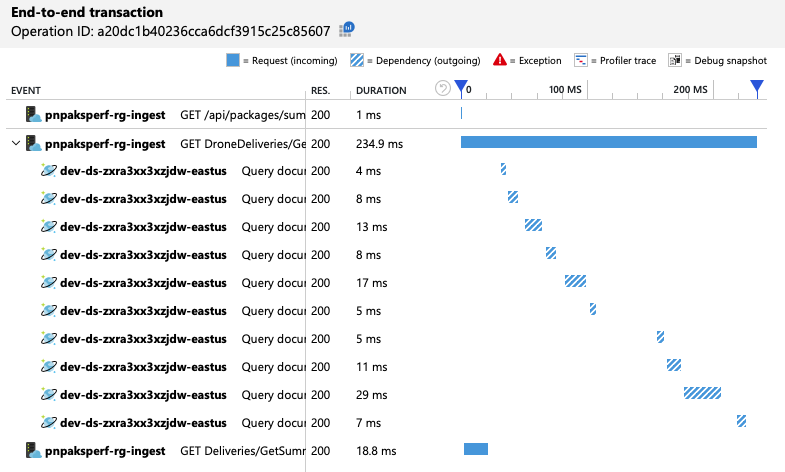
Wie bereits erwähnt, umfasst der GetDroneUtilization-Vorgang eine partitionsübergreifende Abfrage an Azure Cosmos DB. Dies bedeutet, dass der Azure Cosmos DB-Client die Abfrage an die einzelnen physischen Partitionen auffächern und die Ergebnisse erfassen muss. Wie die Ansicht der End-to-End-Transaktionen zeigt, werden diese Abfragen seriell ausgeführt. Der Vorgang dauert so lange wie die Summe aller Abfragen, und dieses Problems wird nur schlimmer, wenn die Datenmenge zunimmt und weitere physische Partitionen hinzugefügt werden.
Test 3: Parallele Abfragen
Basierend auf den vorherigen Ergebnissen ist die parallele Ausgabe der Abfragen offensichtlich eine Möglichkeit, die Latenz zu reduzieren. Das Azure Cosmos DB-Client-SDK verfügt über eine Einstellung, mit der der maximale Grad an Parallelität gesteuert wird.
| Wert | BESCHREIBUNG |
|---|---|
| 0 | Keine Parallelität (Standard) |
| > 0 | Maximale Anzahl paralleler Aufrufe |
| -1 | Das Client-SDK wählt einen optimalen Grad an Parallelität aus. |
Für den dritten Auslastungstest wurde diese Einstellung von 0 in -1 geändert. Die Ergebnisse sind in der folgenden Tabelle zusammengefasst:
| Metrik | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Durchsatz (Anforderungen/Sekunde) | 19 | 23 | 42 |
| Durchschnittliche Latenz (ms) | 669 | 569 | 215 |
| Erfolgreiche Anforderungen | 9,8 Tsd. | 11 Tsd. | 20 Tsd. |
| Gedrosselte Anforderungen | 2,72 Tsd. | 0 | 0 |
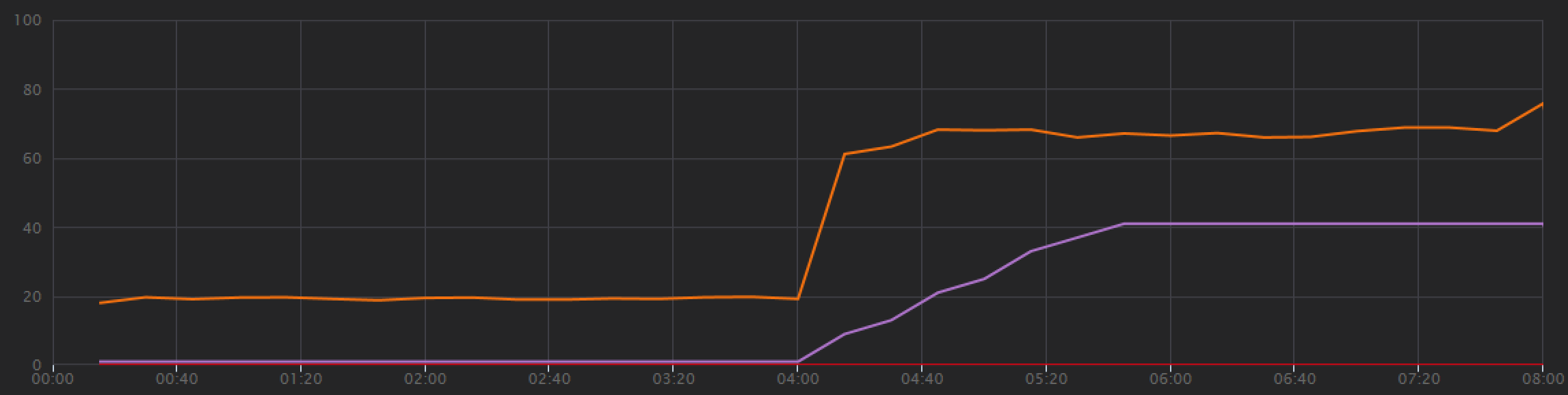
Im Auslastungstestdiagramm ist nicht nur der Gesamtdurchsatz weitaus höher (orangefarbene Linie), sondern der Durchsatz hält auch Schritt mit der Last (violette Linie).
Mithilfe der Ansicht der End-to-End-Transaktionen können wir überprüfen, ob der Azure Cosmos DB-Client Abfragen parallel durchführt:
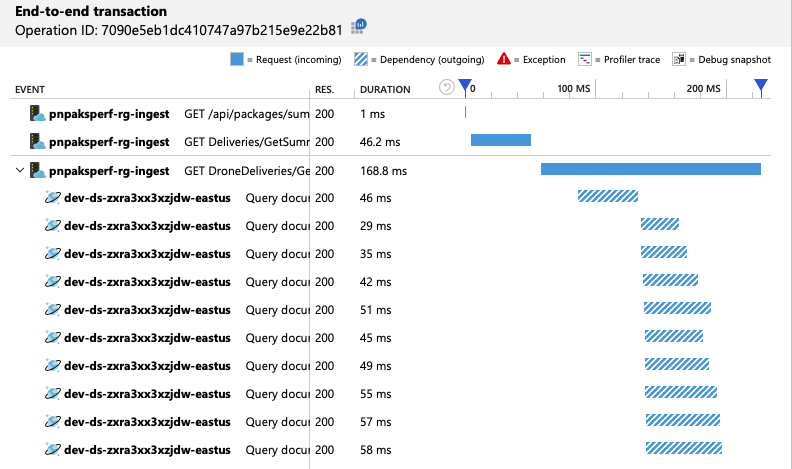
Interessanterweise hat das Verbessern des Durchsatzes den Nebeneffekt, dass die Anzahl der pro Sekunde verbrauchten RUs ebenfalls zunimmt. Obwohl Azure Cosmos DB während dieses Tests keine Anforderungen drosselt hat, lag der Verbrauch nahe dem Limit der bereitgestellten RUs:
Dieses Diagramm könnte ein Signal zum weiteren Aufskalieren der Datenbank sein. Es stellt sich jedoch heraus, dass wir stattdessen die Abfrage optimieren können.
Schritt 4: Optimieren der Abfrage
Der vorherige Auslastungstest zeigte eine bessere Leistung im Hinblick auf Latenz und Durchsatz. Die durchschnittliche Anforderungslatenz wurde um 68 % reduziert und der Durchsatz um 220 % gesteigert. Die partitionsübergreifende Abfrage ist jedoch ein Problem.
Das Problem bei partitionsübergreifenden Abfragen ist, dass Sie für RUs auf jeder Partition bezahlen. Wenn die Abfrage nur gelegentlich ausgeführt wird (etwa einmal pro Stunde), ist dies vielleicht nicht von Bedeutung. Wenn Sie jedoch eine Arbeitsauslastung mit vielen Lesevorgängen feststellen, die eine partitionsübergreifende Abfrage umfasst, sollten Sie überprüfen, ob die Abfrage durch Einschließen eines Partitionsschlüssels optimiert werden kann. (Möglicherweise müssen Sie die Sammlung so umgestalten, dass sie einen anderen Partitionsschlüssel verwendet.)
Hier ist die Abfrage für dieses spezielle Szenario:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Diese Abfrage wählt Datensätze aus, die einer bestimmten Besitzer-ID und dem Monat/Jahr entsprechen. Im ursprünglichen Entwurf ist keine dieser Eigenschaften der Partitionsschlüssel. Dies erfordert, dass der Client die Abfrage an die einzelnen physischen Partitionen auffächert und die Ergebnisse sammelt. Um die Abfrageleistung zu verbessern, hat das Entwicklungsteam den Entwurf so geändert, dass die Besitzer-ID der Partitionsschlüssel für die Sammlung ist. Auf diese Weise kann die Abfrage an eine bestimmte physische Partition gerichtet werden. (Azure Cosmos DB erledigt dies automatisch. Sie müssen die Zuordnung von Partitionsschlüsselwerten zu physischen Partitionen nicht verwalten.)
Nach dem Wechsel der Sammlung zu dem neuen Partitionsschlüssel trat eine drastische Verbesserung des RU-Verbrauchs ein, die sich direkt in niedrigeren Kosten niederschlug.
| Metrik | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| RUs pro Vorgang | 29 | 29 | 29 | 3.4 |
| Aufrufe pro Vorgang | 11 | 9 | 10 | 1 |
Die Ansicht der End-to-End-Transaktionen zeigt, dass die Abfrage wie vorhergesagt nur eine physische Partition liest:
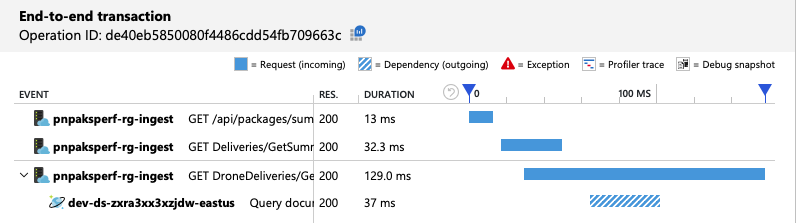
Der Auslastungstest zeigt die Verbesserung von Durchsatz und Latenz:
| Metrik | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Durchsatz (Anforderungen/Sekunde) | 19 | 23 | 42 | 59 |
| Durchschnittliche Latenz (ms) | 669 | 569 | 215 | 176 |
| Erfolgreiche Anforderungen | 9,8 Tsd. | 11 Tsd. | 20 Tsd. | 29 Tsd. |
| Gedrosselte Anforderungen | 2,72 Tsd. | 0 | 0 | 0 |
Eine Folge der verbesserten Leistung ist, dass die Knoten-CPU-Auslastung nun sehr hoch ist:

Gegen Ende des Auslastungstests erreichte die durchschnittliche CPU-Auslastung etwa 90 % und die maximale CPU-Auslastung 100 %. Diese Metrik gibt an, dass die CPU der nächste Engpass im System ist. Wenn ein höherer Durchsatz erforderlich ist, könnte der nächste Schritt das horizontale Hochskalieren des Lieferdiensts auf weitere Instanzen sein.
Zusammenfassung
In diesem Szenario wurden die folgenden Engpässe identifiziert:
- Drosselungsanforderungen von Azure Cosmos DB aufgrund unzureichender RU-Bereitstellung.
- Hohe Latenz durch serielles Abfragen mehrerer Datenbankpartitionen.
- Ineffiziente partitionsübergreifende Abfrage, da die Abfrage nicht den Partitionsschlüssel enthielt.
Außerdem wurde die CPU-Auslastung bei höherer Skalierung als potenzieller Engpass erkannt. Das Entwicklungsteam hat Folgendes untersucht, um diese Probleme zu diagnostizieren:
- Latenz und Durchsatz aus dem Auslastungstest.
- Azure Cosmos DB-Fehler und RU-Verbrauch.
- Die Ansicht der End-to-End-Transaktionen in Application Insights.
- CPU- und Arbeitsspeicherauslastung in Azure Monitor Container Insights
Nächste Schritte
Lesen Sie Leistungsbezogene Antimuster für Cloudanwendungen.