Neuerungen in Azure KI Dokument Intelligenz
Dieser Inhalt gilt für:![]() v4.0 (Vorschau)
v4.0 (Vorschau)![]() v3.1 (allgemein verfügbar)
v3.1 (allgemein verfügbar)![]() v3.0 (allgemein verfügbar)
v3.0 (allgemein verfügbar)![]() v2.1 (allgemein verfügbar)
v2.1 (allgemein verfügbar)
Der Dokument Intelligenz-Dienst wird fortlaufend aktualisiert. Speichern Sie ein Lesezeichen für diese Seite, um bei Versionshinweisen, Verbesserungen von Features und unserer aktuellen Dokumentation auf dem neuesten Stand zu bleiben.
Wichtig
API-Vorschauversionen werden zurückgegeben, sobald die GA-API eingeführt wird. Die API-Version 2023-02-28-preview wird eingestellt. Wenn Sie die Vorschau-API oder die zugehörigen SDK-Versionen weiterhin verwenden, aktualisieren Sie Ihren Code auf die API-Version 2023-07-31.
Februar 2024
Die Rest-API für Document Intelligence 2024-02-29-preview ist jetzt verfügbar. Mit der API v3.1 werden neue und aktualisierte Funktionen eingeführt:
Öffentliche Vorschauversion 2024-02-29-preview ist derzeit nur in den folgenden Azure-Regionen verfügbar:
- USA, Osten
- USA, Westen 2
- Europa, Westen
Das Layoutmodell unterstützt jetzt die Abbildungserkennung und die Analyse der hierarchischen Dokumentstruktur (Abschnitte und Unterabschnitte). Die KI-Qualität der Lesereihenfolge und der Erkennung logischer Rollen wurde ebenfalls verbessert.
Benutzerdefinierte Extraktionsmodelle
- Benutzerdefinierte Extraktionsmodelle unterstützen jetzt Die Konfidenzbewertungen auf Zellen-, Zeilen- und Tabellenebene. Erfahren Sie mehr über die Tabellen-, Zeilen- und Zellvertrauenssicherheit.
- Benutzerdefinierte Extraktionsmodelle verfügen über VERBESSERUNGEN der KI-Qualität für die Feldextraktion.
- Das benutzerdefinierte Vorlagenextraktionsmodell unterstützt jetzt das Extrahieren überlappender Felder. Erfahren Sie mehr überlappende Felder und derenVerwendung.
Benutzerdefiniertes Klassifizierungsmodell
- Benutzerdefiniertes Klassifizierungsmodell unterstützt jetzt inkrementelle Schulung für Szenarien, in denen Sie das Klassifizierermodell mit zusätzlichen Beispielen oder zusätzlichen Klassen aktualisieren müssen. Erfahren Sie mehr über inkrementelle Sicherungen.
- Benutzerdefiniertes Klassifizierungsmodell bietet Unterstützung für Office-Dokumenttypen (.docx, .pptx und .xls). Erfahren Sie mehr über die Unterstützungerweiterter Dokumenttypen.
-
- Unterstützung für das neue Gebietsschema:
Gebietsschema Code Arabisch ( ar)Bulgarisch ( bg)Griechisch ( el)Hebräisch ( he)Mazedonisch ( mk)Russisch ( ru)Serbisch Kyrillisch ( sr-cyrl)Ukrainisch ( uk)Thailändisch ( th)Türkisch ( tr)Vietnamesisch ( vi)- Unterstützung für neue Währungscodes:
Währung Gebietsschema Code BAM Bosnische Konvertierbare Mark ( ba)BGN Bulgarischer Lew ( bg)ILS Israelischer Schekel ( il)MKD Mazedonischer Denar ( mk)RUB Russischer Rubel ( ru)THB Thailändischer Baht ( th)TRY Türkische Lira ( tr)UAH Ukrainische Hrywnja ( ua)VND Vietnamesischer Dong ( vn)- Steuerartikel unterstützen Expansion für Deutschland (), Spanien (
de),Portugal (ptes), Englisch Kanadaen-CA.
-
- Erweiterte Feldunterstützung für IDs und Führerscheine der Europäischen Union.
-
- Extrahieren von Informationen aus dem „Uniform Residential Loan Application“ (Formular 1003).
- Extrahieren Sie Informationen aus dem „Uniform Underwriting and Transmittal Summary“ oder dem Formular 1008.
- Extrahieren Sie Informationen aus der Offenlegung von Hypothekenabschluss.
-
- Extrahieren Sie Informationen aus Bankkarten.
-
- Neue Vorbauung, um Informationen aus Ehescheinen zu extrahieren.
Dezember 2023
Die Document Intelligence-Clientbibliotheken für die REST-API 2023-10-31-preview sind jetzt zur Verwendung verfügbar.
November 2023
Die Rest-API für Document Intelligence 2023-10-31-preview ist jetzt verfügbar. Mit der API v3.1 werden neue und aktualisierte Funktionen eingeführt:
Öffentliche Vorschauversion Preview 31.10.2023 ist derzeit nur in den folgenden Azure-Regionen verfügbar:
- USA, Osten
- USA, Westen 2
- Europa, Westen
-
- Spracherweiterung für Handschrift: Russisch(
ru), Arabisch(ar), Thai(th). - Konformität mit der Cyber-Executive Order (EO)
- Spracherweiterung für Handschrift: Russisch(
-
- Unterstützen Sie Office- und HTML-Dateien.
- Markdown-Ausgabeunterstützung.
- Verbesserungen bei der Erkennung von Tabellenüberschriften, Lesereihenfolge und Abschnittsüberschriften.
- Ab Dokument Intelligenz 2023-10-31-preview ist das allgemeine Dokumentmodell (vorkonfiguriertes Dokument) veraltet. Um Schlüssel-Wert-Paare aus Dokumenten zu extrahieren, verwenden Sie das
prebuilt-layoutModell mit aktiviertem optionalen Abfragezeichenfolgenparameterfeatures=keyValuePairs.
-
- Extrahiert jetzt Währung für alle preisbezogenen Felder.
Krankenversicherungskartenmodell
- Neue Feldunterstützung für Medicare- und Medicaid-Informationen.
-
- W-1099-Steuermodell. Unterstützt das 1099 Grundformular und die folgenden Varianten: A, B, C, CAP, DIV, G, H, INT, K, LS, LTC, MISC, NEC, OID, PATR, Q, QA, R, S, SA, SB.
-
- Unterstützung für das Feld
KVK - Unterstützung für das Feld
BPAY - Zahlreiche Feldoptimierungen.
- Unterstützung für das Feld
Benutzerdefinierte Klassifizierung
- Unterstützung für mehrsprachige Dokumente.
- Neue Optionen zum Teilen von Seiten: automatische Teilung, immer nach Seite geteilt, keine Teilung.
-
- Abfragefelder sind ab der
2023-10-31-preview-Version verfügbar. - Add-On-Funktionen sind in allen Modellen mit Ausnahme des Lesemodells verfügbar.
- Abfragefelder sind ab der
Hinweis
Mit der GA-Veröffentlichung (General Availability) der API 2022-08-31 sind die zugehörigen Vorschau-APIs veraltet. Wenn Sie die API-Versionen 2021-09-30-preview, 2022-01-30-preview oder 2022-06-30-preview verwenden, aktualisieren Sie Ihre Anwendungen auf die API-Version 2022-08-31. Es gibt einige kleinere Änderungen. Weitere Informationen finden Sie im Migrationsleitfaden.
Juli 2023
Hinweis
Die Formularerkennung heißt jetzt Azure KI Dokument Intelligenz!
- Dokument, Azure KI Services umfasst alle bisher als Cognitive Services und Azure Applied AI Services bezeichneten Dienste.
- Es gibt keine Änderungen an den Preisen.
- Die Namen Cognitive Services und Azure Applied AI werden in Abrechnungs-, Kostenanalyse-, Preislisten- und Preis-APIs von Azure weiterhin verwendet.
- Es gibt keine Breaking Changes an APIs (Anwendungsprogrammierschnittstellen) oder Clientbibliotheken.
- Einige Plattformen warten noch auf das Update mit der Umbenennung. Alle Erwähnung von Formularerkennung oder Document Intelligence in unserer Dokumentation beziehen sich auf denselben Azure-Dienst.
Dokument Intelligenz v3.1 (GA)
Die Dokument Intelligenz-API, Version 3.1, ist jetzt allgemein verfügbar! Die API-Version entspricht 2023-07-31.
Mit der API v3.1 werden neue und aktualisierte Funktionen eingeführt:
- Document Intelligence-APIs sind jetzt modularer und bieten Unterstützung für optionale Features. Sie können die Ausgabe jetzt anpassen, um die Features, die Sie benötigen, gezielt einzuschließen. Erfahren Sie mehr über optionale Parameter.
- Dokumentklassifizierungs-API zum Aufteilen einer Datei in einzelne Dokumente. Erfahren Sie mehr über die Dokumentklassifizierung.
- Vordefiniertes Vertragsmodell.
- Vorgefertigtes Modell für das US-Steuerformular 1098.
- Unterstützung für Office-Dateitypen mit der Lese-API.
- Barcodeerkennung in Dokumenten.
- Add-On-Funktion für die Formelerkennung.
- Add-On-Funktion für die Schriftartenerkennung.
- Unterstützung für hochauflösende Dokumente.
- Benutzerdefinierte neuronale Modelle erfordern jetzt eine einzige beschriftete Stichprobe zum Trainieren.
- Spracherweiterung für benutzerdefinierte neuronale Modelle. Trainieren von neuronalen Modellen für Dokumente in 30 Sprachen. Die vollständige Liste unterstützter Sprachen finden Sie unter Sprachunterstützung.
- 🆕 Vordefiniertes Krankenversicherungskartenmodell.
- Erweiterung des Gebietsschemas des vordefinierten Rechnungsmodells.
- Vordefinierte Empfangsmodellsprache und Gebietsschemaerweiterung mit mehr als 100 unterstützten Sprachen.
- Das vordefinierte ID-Modell unterstützt jetzt europäische IDs.
Dokument Intelligenz Studio UX Updates
✔️ Analyseoptionen
Dokument Intelligenz unterstützt jetzt komplexere Analysefunktionen, und Studio bietet einen einzigen Einstiegspunkt (Schaltfläche „Analyseoptionen“) für die problemlose Konfiguration der Add-On-Funktionen.
Je nach Dokumentextraktionsszenario können Sie die Features für Analysebereich, Dokumentseitenbereich, optionale Erkennung und Premium-Erkennung konfigurieren.

Hinweis
Die Schriftartenextraktion wird in Dokument Intelligenz Studio nicht visualisiert. Sie können die Ergebnisse der Schriftarterkennung jedoch im Stilabschnitt der JSON-Ausgabe überprüfen.
✔️ Automatische Beschriftung von Dokumenten mit vordefinierten Modellen oder einem Ihrer eigenen Modelle
Auf der Beschriftungsseite des benutzerdefinierten Extraktionsmodells können Sie Ihre Dokumente jetzt automatisch anhand eines der vordefinierten Modelle des Dokument Intelligenz-Diensts oder mithilfe der zuvor von Ihnen trainierten Modelle beschriften.

Bei einigen Dokumenten liegen nach der automatischen Beschriftung möglicherweise einige Beschriftungen doppelt vor. Stellen Sie sicher, dass Sie die Beschriftungen so ändern, dass auf der Beschriftungsseite keine doppelten Beschriftungen vorhanden sind.

✔️ Automatische Beschriftung von Tabellen
Auf der Beschriftungsseite des benutzerdefinierten Extraktionsmodells können Sie jetzt die Tabellen im Dokument automatisch beschriften. Eine manuelle Beschriftung ist nicht erforderlich.

✔️ Direktes Hinzufügen von Testdateien zu Ihrem Trainingsdataset
Wenn Sie ein benutzerdefiniertes Extraktionsmodell trainieren, verbessern Sie die Modellqualität über die Testseite, indem Sie bei Bedarf Testdokumente in das Trainingsdataset hochladen.
Wenn für einige Beschriftungen ein niedriger Konfidenzwert zurückgegeben wird, stellen Sie sicher, dass sie korrekt beschriftet sind. Fügen Sie sie andernfalls dem Trainingsdataset hinzu, und beschriften Sie sie neu, um die Modellqualität zu verbessern.

✔️ Verwenden der Dokumentlistenoptionen und -filter in benutzerdefinierten Projekten
Verwenden Sie die Beschriftungsseite des benutzerdefinierten Extraktionsmodells. Sie können jetzt ganz einfach durch Ihre Schulungsdokumente navigieren, indem Sie die Suchfunktion verwenden, filtern und sortieren.
Verwenden Sie die Rasteransicht, um Dokumente in der Vorschau anzuzeigen, oder verwenden Sie die Listenansicht, um einfacher durch die Dokumente zu scrollen.

✔️ Projektfreigabe
- Geben Sie mühelos benutzerdefinierte Extraktionsprojekte frei. Weitere Informationen finden Sie unter Projektfreigabe mit benutzerdefinierten Modellen.
Mai 2023
Einführung einer aktualisierten Dokumentation für Build 2023
🆕 Die Übersicht über Dokument Intelligenz verfügt über eine verbesserte Navigation, strukturierte Zugriffspunkte und verbesserte Bilder.
🆕 Wählen Sie ein Dokument Intelligenz-Modell aus, um die beste Dokument Intelligenz-Lösung für Ihre Projekte und Workflows auszuwählen.
April 2023
Ankündigung der neuesten öffentlichen Vorschauversion der Dokument Intelligenz-Clientbibliothek
Die Document Intelligence-REST-API, Version 2023-02-28-preview, unterstützt die Clientbibliotheken des öffentlichen Vorschaurelease. Dieses Release enthält die folgenden neuen Features und Funktionen, die für .NET/C# (4.1.0-beta-1)-, Java (4.1.0-beta-1)-, JavaScript (4.1.0-beta-1)- und Python (3.3.0b.1)-Clientbibliotheken verfügbar sind:
Weitere Informationen finden Sie unterDocument Intelligence SDK (Public Preview) und Versionshinweise vom März 2023.
März 2023
Wichtig
2023-02-28-preview-Funktionen sind derzeit nur in den folgenden Regionen verfügbar:
- Europa, Westen
- USA, Westen 2
- East US
- Das benutzerdefinierte Klassifizierungsmodell ist eine neue Funktionalität in der Dokument Intelligenz und ab der
2023-02-28-preview-API verfügbar. Testen Sie die Dokumentklassifizierungsfunktion mit dem Dokument Intelligenz Studio oder der REST-API. - Funktionen der Abfragefelder, die dem allgemeinen Dokumentmodell hinzugefügt wurden, verwenden Azure Open KI-Modelle, um bestimmte Felder aus Dokumenten zu extrahieren. Probieren Sie das Feature Allgemeine Dokumente mit Abfragefeldern mit Dokument Intelligenz Studio aus. Abfragefelder sind derzeit nur für Ressourcen in der Region
East USaktiv. - Add-On-Funktionen:
- Die Schriftextraktion wird jetzt mit der
2023-02-28-preview-API erkannt. - Die Formelextraktion wird jetzt mit der
2023-02-28-preview-API erkannt. - Die Extraktion mit hoher Auflösung wird jetzt mit der
2023-02-28-preview-API erkannt.
- Die Schriftextraktion wird jetzt mit der
- Updates für benutzerdefinierte Extraktionsmodelle:
- Das benutzerdefinierte neuronale Modell unterstützt jetzt zusätzliche Sprachen für Training und Analyse. Trainieren Sie neuronale Modelle für Niederländisch, Französisch, Deutsch, Italienisch und Spanisch.
- Das benutzerdefinierte Vorlagenmodell verfügt jetzt über eine verbesserte Funktionalität zur Signaturerkennung.
- Document Intelligence Studio-Updates:
- Zusätzlich zur Unterstützung für alle neuen Features wie Klassifizierung und Abfragefelder ermöglicht Studio jetzt die Projektfreigabe für benutzerdefinierte Modellprojekte.
- Neue Modellzugänge in der beschränkten Vorschauversion: Impfkarten, Verträge, US-Steuerformular 1098, US-Steuerformular 1098-E und US-Steuerformular 1098-T. Füllen Sie das Formular zum Anfordern einer privaten Vorschau von Dokument Intelligenz aus, und übermitteln Sie es, um Zugriff auf zugriffsbeschränkte Vorschaumodelle anzufordern.
- Updates für Belegmodelle:
- Dank des Belegmodells profitieren Sie von Unterstützung für thermische Quittungen.
- Das Belegmodell bietet jetzt Unterstützung für 18 Sprachen und drei Sprachdialekte (Englisch, Französisch, Portugiesisch).
- Das Belegmodell unterstützt jetzt die
TaxDetails-Extraktion.
- Das Layoutmodell verfügt jetzt über eine verbesserte Tabellenerkennung.
- Beim Modell „Lesen“ wurde die Erkennung einstelliger Zeichen verbessert.
Februar 2023
Ausgewählte Azure Dokument Intelligenz-Container für v3.0 stehen jetzt zur Verfügung!
Derzeit sind die Container Lesen v3.0 und Layout v3.0 verfügbar.
Weitere Informationen finden Sie unterInstallieren und Ausführen von Document Intelligence-Containern.
Januar 2023
Vordefiniertes Belegmodell – hinzugefügte Sprachen werden unterstützt. Das Belegmodell unterstützt jetzt diese hinzugefügten Sprachen und Gebietsschemas
- Japanisch – Japan (ja-JP)
- Französisch – Kanada (fr-CA)
- Niederländisch – Niederlande (nl-NL)
- Englisch – Vereinigte Arabische Emirate (en-AE)
- Portugiesisch – Brasilien (pt-BR)
Vordefiniertes Rechnungsmodell – hinzugefügte Sprachen werden unterstützt. Das Rechnungsmodell unterstützt jetzt diese hinzugefügten Sprachen und Gebietsschemas
- Englisch – USA (en-US), Australien (en-AU), Kanada (en-CA), Vereinigtes Königreich (en-GB), Indien (en-IN)
- Spanisch – Spanien (es-ES)
- Französisch – Frankreich (fr-FR)
- Italienisch – Italien (it-IT)
- Portugiesisch – Portugal (pt-PT)
- Niederländisch – Niederlande (nl-NL)
Vordefiniertes Rechnungsmodell – hinzugefügte Felder werden erkannt. Das Rechnungsmodell erkennt nun diese hinzugefügten Felder
- Currency code
- Zahlungsoptionen
- Gesamtrabatt
- Steuerposten (nur en-IN)
Vordefiniertes ID-Modell – hinzugefügte Dokumenttypen werden unterstützt. Das ID-Modell unterstützt jetzt diese hinzugefügten Dokumenttypen
- US-Militär-ID
Tipp
Alle Updates vom Januar 2023 sind mit der REST-API-Version 2022-08-31 (GA) verfügbar.
Vordefiniertes Belegmodell – zusätzliche Sprachunterstützung:
Das vordefinierte Belegmodell unterstützt jetzt die folgenden Sprachen:
- Englisch – Vereinigte Arabische Emirate (en-AE)
- Niederländisch – Niederlande (nl-NL)
- Französisch – Kanada (fr-CA)
- Deutsch – (de-DE)
- Italienisch – (it-IT)
- Japanisch – Japan (ja-JP)
- Portugiesisch – Brasilien (pt-BR)
Vordefiniertes Rechnungsmodell – zusätzliche Sprachunterstützung und Feldextraktionen
Das vordefinierte Rechnungsmodell unterstützt jetzt die folgenden Sprachen:
- Englisch – Australien (en-AU), Kanada (en-CA), Vereinigtes Königreich (en-UK), Indien (en-IN)
- Portugiesisch – Brasilien (pt-BR)
Das vordefinierte Rechnungsmodell unterstützt jetzt die folgenden Feldextraktionen:
- Currency code
- Zahlungsoptionen
- Gesamtrabatt
- Steuerposten (nur en-IN)
Vordefiniertes Ausweisdokumentmodell – Unterstützung zusätzlicher Dokumenttypen
Das vordefinierte Ausweisdokumentmodell unterstützt jetzt die folgenden Dokumenttypen:
- Führerscheinerweiterung für Indien, Kanada, Vereinigtes Königreich und Australien
- US-Militärausweise und -Ausweisdokumente
- Indische Personalausweise und Ausweisdokumente (PAN und Aadhaar)
- Australische Personalausweise und Ausweisdokumente (Fotokarte, Schlüsselpass-ID)
- Kanada Personalausweise und Ausweisdokumente (Personalausweis, Maple-Karte)
- Personalausweise und Ausweisdokumente des Vereinigten Königreichs (nationaler/regionaler Personalausweis)
Dezember 2022
Dokument Intelligenz Studio-Updates
Die Document Intelligence Studio-Version vom Dezember enthält die neuesten Updates für Dokument Intelligenz Studio. Es gibt erhebliche Verbesserungen an der Benutzeroberfläche, vor allem bei der Unterstützung benutzerdefinierter Modellbezeichnungen.
Seitenbereich: Studio unterstützt jetzt die Analyse von angegebenen Seiten aus einem Dokument.
Benutzerdefinierte Modellbezeichnungen:
Automatisches Ausführen der Layout-API: Sie können die Layout-API während des Setupprozesses für ein benutzerdefiniertes Modell automatisch für alle Dokumente in Ihrem Blobspeicher ausführen.
Suchen Studio bietet jetzt Suchfunktionen zum Suchen von Wörtern in einem Dokument. Diese Verbesserung ermöglicht eine einfachere Navigation während der Bezeichnung.
Navigation: Sie können Bezeichnungen für beschriftete Wörter in einem Dokument auswählen.
Automatische Tabellenbezeichnung: Nachdem Sie das Tabellensymbol in einem Dokument ausgewählt haben, können Sie die extrahierte Tabelle in der Beschriftungsansicht automatisch beschriften.
Bezeichnung von Untertypen und Untertypen der zweiten Ebene: Studio unterstützt jetzt Untertypen für Tabellenspalten, Tabellenzeilen und Untertypen der zweiten Ebene für Typen wie Datumsangaben und Zahlen.
Das Erstellen benutzerdefinierter neuronaler Modelle wird jetzt in der Region „US Gov Virginia“ unterstützt.
Die API-Vorschauversionen
2022-01-30-previewund2021-09-30-previewwerden am 31. Januar 2023 eingestellt. Aktualisieren Sie auf die API-Version2022-08-31, um Dienstunterbrechungen zu vermeiden.
November 2022
- Ankündigung der neuesten stabilen Version von Azure KI Dokument Intelligenz-Bibliotheken
- Dieses Release enthält wichtige Änderungen und Updates für .NET-, Java-, JavaScript- und Python-Clientbibliotheken. Weitere Informationen finden Sie unterAzure SDK DevBlog.
- Die wichtigsten Verbesserungen sind die Einführung von zwei neuen Clients:
DocumentAnalysisClientundDocumentModelAdministrationClient.
Oktober 2022
Dokument Intelligenz-Inhalte mit Versionsangabe
Die Dokumentation zu Dokument Intelligenz wurde aktualisiert, um Inhalte mit Versionsangaben anzuzeigen. Jetzt können Sie wählen, ob Sie die Inhalte für die Version
v3.0 GAoder die Versionv2.1 GAanzeigen möchten. Die Oberfläche der Version 3.0 ist die Standardeinstellung.
Dokument Intelligenz Studio-Beispielcode
- Beispielcode für die Dokument Intelligenz Studio-Umgebung für Beschriftungen ist jetzt auf GitHub verfügbar. Kunden können Dokument Intelligenz entwickeln und in ihre eigene Benutzeroberfläche integrieren oder ihre eigene neue Benutzeroberfläche mithilfe des Dokument Intelligenz Studio-Beispielcodes erstellen.
Spracherweiterung
- In der neuesten Vorschauversion unterstützen die Vorlagenmodelle Read (OCR), Layout und Custom der Dokument Intelligenz jetzt 134 neue Sprachen. Zu diesen Sprachergänzungen gehören Griechisch, Lettisch, Serbisch, Thai, Ukrainisch und Vietnamesisch sowie mehrere Sprachen in lateinischer und kyrillischer Schrift. Dokument Intelligenz unterstützt jetzt insgesamt 299 Sprachen in den aktuellen GA- und neuen Vorschauversionen. Auf der Seite Unterstützte Sprachen finden Sie alle unterstützen Sprachen.
- Verwenden Sie den REST-API-Parameter
api-version=2022-06-30-preview, wenn Sie die API oder das entsprechende SDK verwenden, um die neuen Sprachen in Ihren Anwendungen zu unterstützen.
Neues vordefiniertes Vertragsmodell
- Ein neues vordefiniertes Modell, das Informationen aus Verträgen wie Parteien, Titel, Vertrags-ID, Unterzeichnungsdatum usw. extrahiert. Das Vertragsmodell befindet sich derzeit in der Vorschau. Hier können Sie Zugriff anfordern.
Regionserweiterung für das Training benutzerdefinierter neuronaler Modelle
- Das Training von benutzerdefinierten neuronalen Modellen wird jetzt in weiteren Regionen unterstützt.
- East US
- USA (Ost 2)
- US Gov Arizona
- Das Training von benutzerdefinierten neuronalen Modellen wird jetzt in weiteren Regionen unterstützt.
September 2022
Hinweis
Ab Version 4.0.0 wurde eine neue Gruppe von Clients eingeführt, um die neuesten Features des Dokument Intelligenz-Diensts zu nutzen.
SDK-Version 4.0.0 GA-Release enthält die folgenden Updates:
- Version 4.0.0: allgemein verfügbar (2022-09-08)
- Unterstützt Clients mit REST-API v3.0 und v2.0
Regionserweiterung zum Trainieren benutzerdefinierter neuronaler Modelle jetzt in sechs neuen Regionen unterstützt
- Australien (Osten)
- USA (Mitte)
- Asien, Osten
- Frankreich, Mitte
- UK, Süden
- USA, Westen 2
Eine vollständige Liste der Regionen, in denen Training unterstützt wird, finden Sie unter Benutzerdefinierte neuronale Modelle.
Document Intelligence SDK-Version, Release
4.0.0 GA:- Version 4.0.0 (.NET/C#, Java, JavaScript) und Version 3.2.0 (Python) der Document Intelligence-Clientbibliotheken sind allgemein verfügbar und können in Produktionsanwendungen verwendet werden.
- Weitere Informationen zu Document Intelligence-Clientbibliotheken finden Sie in der SDK-Übersicht.
- Aktualisieren Sie Ihre Anwendungen mithilfe des Migrationsleitfadens für Ihre Programmiersprache.
August 2022
Die Vorschauversion der Dokument Intelligenz-SDK-Beta vom August 2022 enthält die folgenden Updates:
Version 4.0.0-beta.5 (2022-08-09)
Dokument Intelligenz v3.0 ist allgemein verfügbar.
- Dokument Intelligenz REST-API v3.0 ist nun allgemein verfügbar und kann in Produktionsanwendungen verwendet werden! Aktualisieren Sie Ihre Anwendungen mit der REST-API-Version 2022-08-31.
Dokument Intelligenz Studio-Updates
- Nächste Schritte: Unter jeder Modellseite verfügt das Studio jetzt über einen Abschnitt mit den nächsten Schritten. Benutzer können schnell auf Beispielcode, Richtlinien zur Problembehandlung und Preisinformationen zugreifen.
- Benutzerdefinierte Modelle: Das Studio enthält jetzt die Möglichkeit, Bezeichnungen in benutzerdefinierten Modellprojekten neu anzuordnen, um die Bezeichnungseffizienz zu verbessern.
- Kopieren von Modellen: Benutzerdefinierte Modelle können aus dem Studio in verschiedene Dokument Intelligenz-Dienste kopiert werden. Dieser Vorgang ermöglicht die Höherstufung eines trainierten Modells auf andere Umgebungen und Regionen.
- Löschen von Dokumenten: Das Studio unterstützt jetzt das Löschen von Dokumenten aus beschrifteten Datasets in benutzerdefinierten Projekten.
Updates für den Dokument Intelligenz-Dienst
- prebuilt-read. Das Lese-OCR-Modell ist jetzt auch in Dokument Intelligenz mit den beiden neuen Features für Absätze und Spracherkennung verfügbar. Erweiterte Dokumentszenarien von Lesezielen der Dokument Intelligenz, die mit den erweiterten Dokumentintelligenzfunktionen in der Dokument Intelligenz abgestimmt sind.
- prebuilt-layout. Das Layoutmodell extrahiert Absätze und gibt an, ob der extrahierte Text ein Absatz, Titel, Abschnittsüberschrift, eine Fußnote, ein Seitenkopf, ein Seitenfuß oder eine Seitenzahl ist.
- prebuilt-invoice. Die Felder „MwSt. gesamt“ und „Position/MwSt.“ werden nun in die vorhandenen Felder „Steuern gesamt“ respektive „Position/Steuern“ aufgelöst.
- prebuilt-idDocument. Unterstützung der Datenextraktion für US-amerikanische Ausweise, Sozialversicherungskarten und Green Cards. Unterstützung für Pass- und Visainformationen.
- prebuilt-receipt. Erweiterte Gebietsschemaunterstützung für Französisch (fr-FR), Spanisch (es-ES), Portugiesisch (pt-PT), Italienisch (it-IT) und Deutsch (de-DE)
- prebuilt-businessCard. Adressanalyseunterstützung zum Extrahieren von untergeordneten Feldern für Adresskomponenten wie Adresse, Ort, Bundesland/Kanton, Land/Region und Postleitzahl.
Verbesserungen der KI-Qualität
- prebuilt-read. Verbesserte Unterstützung für einzelne Zeichen, handschriftliche Datumsangaben, Beträge, Namen, andere wichtige Daten, die häufig in Quittungen und Rechnungen zu finden sind, sowie verbesserte Verarbeitung digitaler PDF-Dokumente.
- prebuilt-layout. Unterstützung für eine bessere Erkennung von zugeschnittenen Tabellen und rahmenlosen Tabellen sowie verbesserte Erkennung von langen übergreifenden Zellen.
- prebuilt-document. Verbesserte Wert- und Kontrollkästchenerkennung
- custom-neural. Verbesserte Genauigkeit für die Tabellenerkennung und -extraktion
Juni 2022
- Die Vorschauversion der Dokument Intelligenz-SDK-Beta vom Juni 2022 enthält die folgenden Updates:
Version 4.0.0-beta.4 (2022-06-08)
Die Juni-Version von Dokument Intelligenz Studio ist das neueste Update für Dokument Intelligenz Studio. In diesem Update wurden erhebliche Verbesserungen an Benutzererfahrung und Barrierefreiheit vorgenommen:
- Codebeispiel für JavaScript und C#: Die Registerkarte „Code“ in Studio fügt jetzt Codebeispiele für JavaScript und C# über das vorhandene für Python hinaus hinzu.
- Neue Benutzeroberfläche zum Hochladen von Dokumenten. Studio unterstützt jetzt das Hochladen eines Dokuments mit Drag & Drop auf die neue Benutzeroberfläche zum Hochladen.
- Neues Feature für benutzerdefinierte Projekte. Benutzerdefinierte Projekte unterstützen jetzt das Erstellen von Speicherkonten und Blobs beim Konfigurieren des Projekts. Darüber hinaus unterstützen benutzerdefinierte Projekte jetzt das Hochladen von Trainingsdateien direkt in Studio sowie das Kopieren des vorhandenen benutzerdefinierten Modells.
Das Release 2022-06-30-preview von Dokument Intelligenz v3.0 enthält umfangreiche Updates für die Feature-APIs:
- Layout erweitert die Strukturextraktion. Das Layout umfasst jetzt hinzugefügte Strukturelemente wie Abschnitte, Abschnittsüberschriften und Absätze. Dieses Update ermöglicht Szenarien mit feinerer Dokumentsegmentierung. Eine vollständige Liste der identifizierten Strukturelemente finden Sie unter erweiterter Struktur.
- Unterstützung von tabellarischen Feldern in benutzerdefinierten neuronalen Modellen. Benutzerdefinierte Dokumentmodelle unterstützen jetzt tabellarische Felder. Tabellarische Felder sind standardmäßig auch mehrere Seiten. Weitere Informationen zu tabellarischen Feldern in benutzerdefinierten neuronalen Modellen finden Sie unter tabellarische Felder.
- Unterstützung tabellarischer Felder in benutzerdefinierten Vorlagenmodellen für seitenübergreifende Tabellen. Benutzerdefinierte Formularmodelle unterstützen jetzt seitenübergreifende tabellarische Felder. Weitere Informationen zu tabellarischen Feldern in benutzerdefinierten Vorlagenmodellen finden Sie untertabellarische Felder.
- Die Ausgabe des Rechnungsmodells umfasst jetzt allgemeine Schlüssel-Wert-Paare für Dokumente. Wenn Rechnungen Pflichtfelder enthalten, die über die im vordefinierten Modell enthaltenen Felder hinausgehen, ergänzt das allgemeine Dokumentmodell die Ausgabe um Schlüssel-Wert-Paare. SieheSchlüssel-Werte-Paare.
- Erweiterung der Rechnungssprache. Das Rechnungsmodell umfasst erweiterte Sprachunterstützung. Sieheunterstützte Sprachen.
- Die vordefinierte Visitenkarte umfasst jetzt Unterstützung für die japanische Sprache. Sieheunterstützte Sprachen.
- Vordefiniertes Ausweisdokumentmodell. Das Ausweisdokumentmodell extrahiert jetzt DateOfIssue, Height, Weight, EyeColor, HairColor und DocumentDiscriminator aus US-Führerscheinen. SieheFeldextraktion.
- Das Lesemodell unterstützt jetzt gängige Microsoft Office-Dokumenttypen. Dokumenttypen wie Word (DOCX), Excel (XLSX) und PowerPoint (PPT) werden jetzt mit der Lese-API unterstützt. Siehe Datenextraktion.
Februar 2022
Version 4.0.0-beta.3 (2022-02-10)
Das Vorschaurelease von Document Intelligence Version 3.0 bietet mehrere neue Features, Funktionen und Verbesserungen:
- Benutzerdefiniertes neuronales Modell oder benutzerdefiniertes Dokumentmodell ist ein neues benutzerdefiniertes Modell zum Extrahieren von Text- und Auswahlmarkierungen aus strukturierten Formularen, halbstrukturierten und unstrukturierten Dokumenten.
- Das vordefinierte W-2-Modell ist ein neues vordefiniertes Modell zum Extrahieren von Feldern aus W-2-Formularen für Steuererklärungs- und Einkommensüberprüfungsszenarien.
- Die Lese-API extrahiert gedruckte Textzeilen, Wörter, Textpositionen, erkannte Sprachen und handschriftlichen Text, sofern erkannt.
- Das vortrainierte Modell Allgemeines Dokument wurde jetzt so aktualisiert, dass neben API-Text, Tabellen, Struktur und Schlüssel-Wert-Paaren aus Formularen und Dokumenten auch Auswahlmarkierungen unterstützt werden.
- Rechnungs-API Das vordefinierte Rechnungsmodell erweitert die Unterstützung auf spanischen Rechnungen.
- Dokument Intelligenz Studio fügt neue Demos für Lese-, W2-, Hotelbelegbeispiele und Unterstützung für das Training der neuen benutzerdefinierten neuronalen Modelle hinzu.
- Spracherweiterung Mit „Lesen“, „Layout“ und „Benutzerdefiniertes Formular“ von Dokument Intelligenz wird Unterstützung für 42 neue Sprachen hinzugefügt, einschließlich Arabisch, Hindi und anderen Sprachen, die arabische oder Devanagari-Schriften verwenden, um die Abdeckung auf 164 Sprachen zu erweitern. Die handschriftliche Sprachunterstützung wird auf Japanisch und Koreanisch erweitert.
Starten Sie mit der neuen REST API, Python oder .NET SDK für die API-Vorschau v3.0.
Document Intelligence-Modelldatenextraktion:
Modell Textextraktion Schlüssel-Werte-Paare Auswahlmarkierungen Tabellen Signaturen Lesen ✓ Allgemeines Dokument ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ Rechnung ✓ ✓ ✓ ✓ Rechnung ✓ ✓ ✓ ID-Dokument ✓ ✓ Visitenkarte ✓ ✓ Benutzerdefiniertes Vorlagenmodell ✓ ✓ ✓ ✓ ✓ Benutzerdefiniertes neuronales Modell ✓ ✓ ✓ ✓ Die Vorschauversion der Dokument Intelligenz-SDK-Beta enthält die folgenden Updates:
Benutzerdefinierte Dokumentmodelle und -modi:
- Benutzerdefinierte Vorlage (früher benutzerdefiniertes Formular)
- Benutzerdefiniertes neuronales Modell.
- Benutzerdefiniertes Modell – Buildmodus.
Vordefiniertes W-2-Modell (prebuilt-tax.us.w2)
Vordefiniertes Lesemodell (prebuilt-read)
Vordefiniertes Rechnungsmodell (Spanisch) (prebuilt-invoice)
November 2021
Version 4.0.0-beta.2 (2021-11-09)
| Paket (NuGet) | Changelog/Releaseverlauf | API-Referenzdokumentation
- SDK-Releaseupdate der Dokument Intelligenz-Vorschauversion 3.0 (beta.2) enthält Fehlerbehebungen und kleinere Featureupdates.
Oktober 2021
Die Dokument Intelligenz v3.0-Vorschauversion des Releases 4.0.0-beta.1 (2021-10-07) bietet mehrere neue Funktionen und Möglichkeiten:
Allgemeines Dokumentenmodell ist eine neue API, die ein vorab trainiertes Modell verwendet, um Text, Tabellen, Strukturen und Schlüssel-Wert-Paare aus Formularen und Dokumenten zu extrahieren.
Hotelquittung Modell zur vorgefertigten Quittungsverarbeitung hinzugefügt.
Erweiterte Felder für ID-Dokumente Das ID-Modell unterstützt Vermerke, Einschränkungen und die Extraktion der Fahrzeugklassifizierung aus US-Führerscheinen.
Unterschriftenfeld ist ein neuer Feldtyp in benutzerdefinierten Formularen zur Erkennung des Vorhandenseins einer Unterschrift in einem Formularfeld.
Sprachenerweiterung Unterstützung für 122 Sprachen (gedruckt) und 7 Sprachen (handschriftlich). Mit der neuesten Vorschauversion von „Layout“ und „Benutzerdefiniertes Formular“ von Dokument Intelligenz wird die Anzahl unterstützter Sprachen auf 122 erweitert. Die Vorschau umfasst die Textextraktion für Drucktexte in 49 neuen Sprachen, darunter Russisch, Bulgarisch und andere kyrillische sowie weitere lateinische Sprachen. Darüber hinaus unterstützt die Extraktion von handgeschriebenem Text jetzt sieben Sprachen, darunter Englisch und neue Vorschauversionen für Chinesisch (vereinfacht), Französisch, Deutsch, Italienisch, Portugiesisch und Spanisch.
Verbesserungen bei der Extraktion von Tabellen und Text Layout unterstützt jetzt die Extraktion von einzeiligen Tabellen, auch Key-Value-Tabellen genannt. Zu den Verbesserungen bei der Textextraktion gehören eine bessere Verarbeitung von digitalen PDFs und Maschinenlesbare Zone Text (MRZ) in Identitätsdokumenten sowie eine allgemeine Leistungssteigerung.
Document Intelligence Studio Zum Vereinfachen der Verwendung des Diensts können Sie jetzt auf Document Intelligence Studio zugreifen, um die verschiedenen vordefinierten Modelle zu testen oder ein benutzerdefiniertes Modell zu beschriften und zu trainieren.
Starten Sie mit der neuen REST API, Python oder .NET SDK für die API-Vorschau v3.0.
Datenextraktion des Dokument Intelligenz-Modells
Modell Textextraktion Schlüssel-Werte-Paare Auswahlmarkierungen Tabellen Allgemeines Dokument ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ Rechnung ✓ ✓ ✓ ✓ Rechnung ✓ ✓ ID-Dokument ✓ ✓ Visitenkarte ✓ ✓ Benutzerdefiniert ✓ ✓ ✓ ✓
September 2021
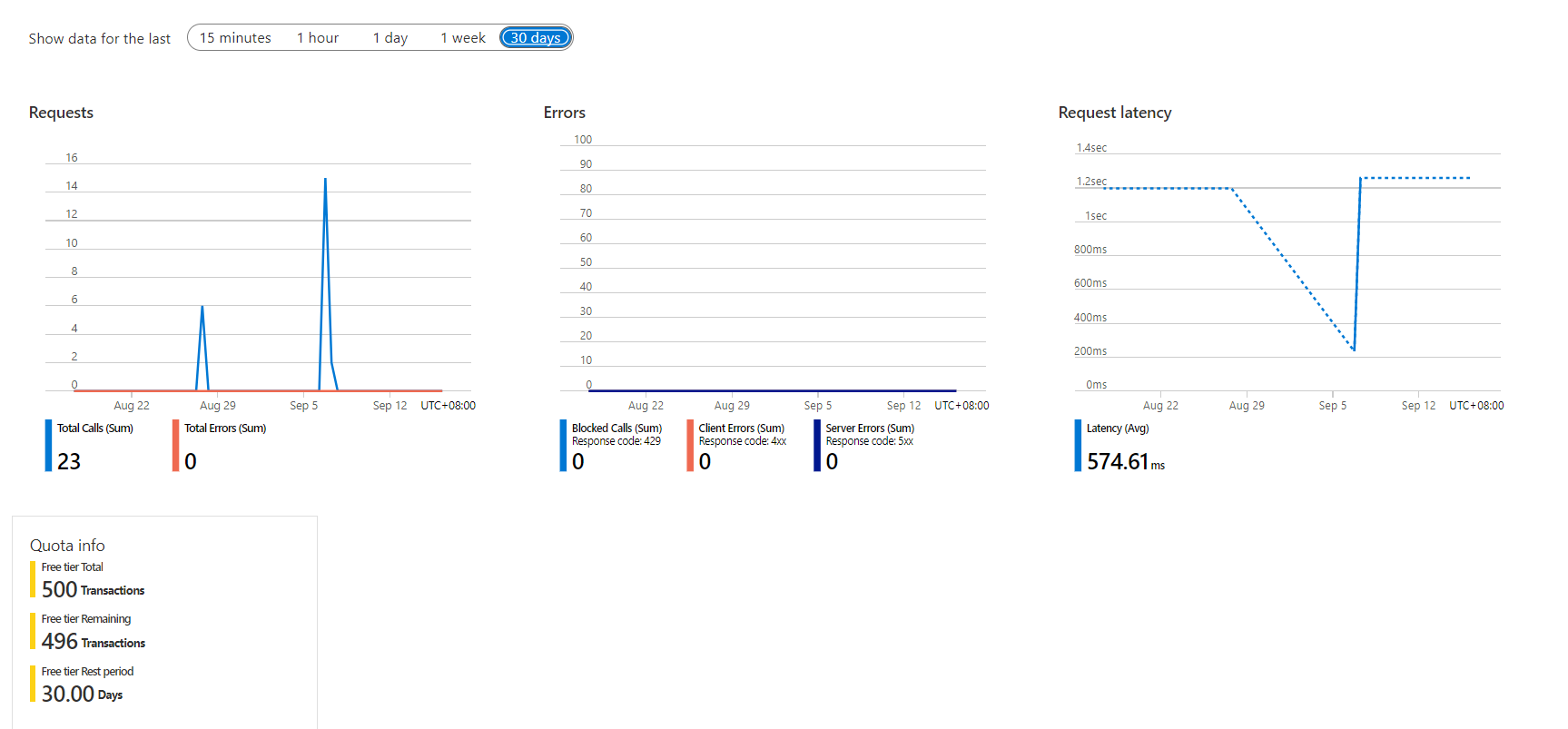
Erweiterte Funktionen des Azure-Metrik-Explorers sind in Ihrer Ressourcenübersicht der Dokument Intelligenz im Azure-Portal verfügbar.
Menü „Überwachung“:
Diagramme:
ID-Dokument-Modellaktualisierung: gegebene Namen einschließlich eines Suffixes, mit oder ohne Punkt, erfolgreich verarbeiten:
Eingabetext Ergebnis mit Update William Isaac Kirby Jr. Vorname: William Isaac
Nachname: Kirby Jr.Henry Caleb Ross Sr Vorname: Henry Caleb
Nachname: Ross Sr
Juli 2021
- Unterstützung für systemseitig zugewiesene verwaltete Identität: Sie können jetzt eine vom System zugewiesene verwaltete Identität aktivieren, um der Dokument Intelligenz begrenzten Zugriff auf private Speicherkonten zu gewähren, einschließlich Konten, die durch ein virtuelles Netzwerk oder eine Firewall geschützt sind oder Bring-your-own-Storage (BYOS) aktiviert haben. Erfahren Sie, wie Sie eine verwaltete Identität für Ihre Dokument Intelligenz-Ressource erstellen und verwenden.
Juni 2021
Dokument Intelligenz-Container Version 2.1 wurde in der geschlossenen Vorschau veröffentlicht und wird jetzt durch sechs Featurecontainer unterstützt: Layout, Visitenkarte,Ausweisdokument, Quittung, Rechnung und Benutzerdefiniert. Wenn Sie die Container verwenden möchten, müssen Sie eine Onlineanforderung einreichen und diese genehmigen lassen.
- Weitere Informationen finden Sie unterInstallieren und Ausführen von Docker-Containern für Dokument Intelligenz und Konfigurieren von Dokument Intelligenz-Containern.
Dokument Intelligenz-Connector wurde als Vorschauversion veröffentlicht: Der Dokument Intelligenz-Connector ist in Azure Logic Apps, Microsoft Power Automate und Microsoft Power Apps integrierbar. Der Connector unterstützt Workflowaktionen und Trigger zum Extrahieren und Analysieren von Dokumentdaten und -strukturen aus benutzerdefinierten und vordefinierten Formularen, Rechnungen, Belegen, Visitenkarten und Ausweis.
Dokument Intelligenz SDK v3.1.0 für C#, Java und Python auf v3.1.1 gepatcht Der Patch befasst sich mit Rechnungen, die keine Felder für Unterzeilenpositionen enthalten, wie z. B.
FormFieldmitText, aber ohneBoundingBoxoderPage.
Mai 2021
- Version 3.1.0 (2021-05-26)
Änderungsprotokoll/Releaseverlauf| Referenzdokumentation | NuGet-Paketversion 3.0.1 |
Dokument Intelligenz 2.1 ist allgemein verfügbar. Das GA-Release markiert die Stabilität der Änderungen, die in früheren 2.1 Preview-Paketversionen eingeführt wurden. Mit dieser Version können Sie Informationen und Daten aus den folgenden Dokumentenarten erkennen und extrahieren:
Probieren Sie zunächst das Dokument Intelligenz-Beispieltool aus und folgen Sie der Schnellstartanleitung.
Das Tabellenfeature der aktualisierten Layout-API wurde um die Kopfzeilenerkennung bei Spaltenköpfen erweitert, die mehrere Zeilen umfassen können. Jede Tabellenzelle verfügt über ein Attribut, das angibt, ob sie Teil einer Kopfzeile ist oder nicht. Anhand dieses Updates kann bestimmt werden, welche Zeilen den Tabellenkopf bilden.
April 2021
NuGet-Paketversion 3.1.0-beta.4
Neue Methoden zum Analysieren von Daten aus Identitätsdokumenten:
StartRecognizeIdDocumentsFromUriAsync
StartRecognizeIdDocumentsAsync
Eine Liste der Feldwerte finden Sie unterFelder extrahiert in unserem Dokumentation zu Dokument Intelligenz.
Die Gruppe der Dokumentsprachen, die für die Methode StartRecognizeContent angegeben werden können, wurde erweitert.
Neue Eigenschaft
Pages, die von den folgenden Klassen unterstützt wird:RecognizeBusinessCardsOptions
RecognizeCustomFormsOptions
RecognizeInvoicesOptions
RecognizeReceiptsOptionsMit der Eigenschaft
Pageskönnen Sie bei PDF- und TIFF-Dokumenten mit mehreren Seiten einzelne Seiten oder einen Seitenbereich auswählen. Geben Sie für einzelne Seiten die Seitenzahl ein (beispielsweise3). Für einen Seitenbereich (z. B. Seite 2 und Seiten 5-7) geben Sie die Seitenzahlen und -bereiche durch Kommata getrennt ein:2, 5-7.Neue Eigenschaft
ReadingOrder, die für die folgende Klasse unterstützt wird:Die Eigenschaft
ReadingOrderist ein optionaler Parameter, mit dem Sie angeben können, welcher Algorithmus für die Lesereihenfolge (basicodernatural) angewendet werden soll, um die Extraktionsreihenfolge von Textelementen zu bestimmen. Wenn Sie hier nichts angeben, lautet der Standardwertbasic.
- SDK-Vorschauupdates für API-Version
2.1-preview.3führen Featureupdates und -verbesserungen ein.
März 2021
Dokument Intelligenz v2.1 Public Preview v2.1-preview.3 wurde veröffentlicht und enthält die folgenden Features:
Neues vordefiniertes ID-Modell: Mit dem neuen vordefinierten ID-Modell können Kunden Ausweispapiere erfassen und strukturierte Daten zurückgeben, um die Verarbeitung zu automatisieren. Dabei werden unsere leistungsstarken Funktionen zur optischen Zeichenerkennung (Optical Character Recognition, OCR) mit Ausweiserkennungsmodellen kombiniert, um wesentliche Informationen aus Reisepässen und US-Führerscheinen zu extrahieren.
Weitere Informationen zum vordefinierten ID-Modell

Extraktion von Rechnungspositionen für das Rechnungsmodell: Das vordefinierte Rechnungsmodell unterstützt jetzt die Extraktion von Einzelposten. Es extrahiert nun vollständige Artikel und deren Bestandteile – Beschreibung, Betrag, Menge, Produkt-ID, Datum und mehr. Mit einem einfachen API-/SDK-Aufruf können Sie nützliche Daten aus Rechnungen extrahieren, z. B. Text, Tabellen, Schlüssel-Wert-Paare und Einzelposten.
Überwachtes Beschriften und Trainieren von Tabellen, Beschriftung leerer Werte: Zusätzlich zu den hochmodernen Deep Learning-Funktionen der Dokument Intelligenz zur automatischen Tabellenextraktion können Kunden nun auch Tabellen beschriften und trainieren. Dieses neue Release bietet die Möglichkeit, Einzelposten und Tabellen (dynamisch und fest) zu beschriften und zu trainieren sowie ein benutzerdefiniertes Modell zum Extrahieren von Schlüssel-Wert-Paaren und Einzelposten zu trainieren. Nach dem Trainieren eines Modells werden mit dem Modell Einzelposten als Teil der JSON-Ausgabe im Abschnitt „documentResults“ extrahiert.
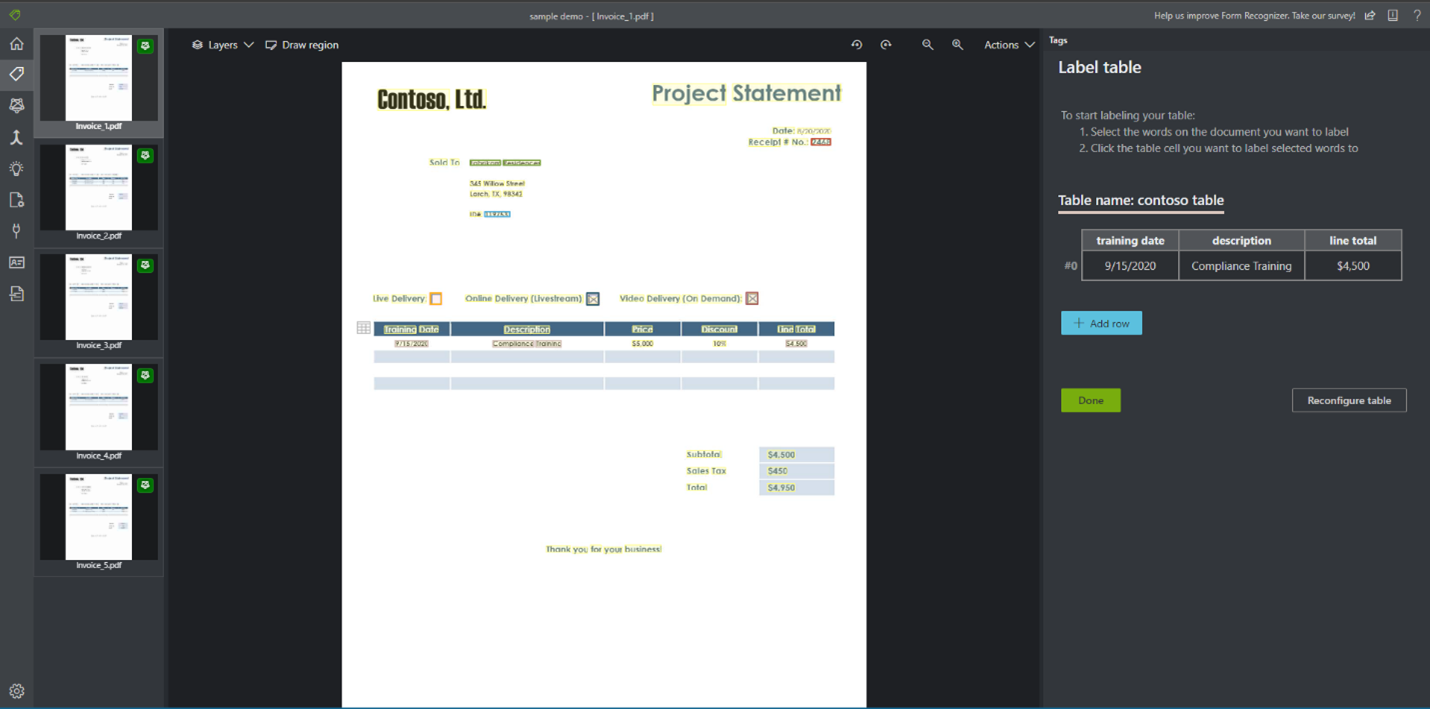
Zusätzlich zur Beschriftung von Tabellen können Sie jetzt auch leere Werte und Regionen beschriften. Wenn einige Dokumente in Ihrem Trainingssatz keine Werte für bestimmte Felder enthalten, können Sie diese beschriften, damit Ihr Modell weiß, wie es die Werte aus den analysierten Dokumenten richtig extrahieren soll.
Unterstützung für 66 neue Sprachen: Die Layout-API und benutzerdefinierten Modelle für die Dokument Intelligenz unterstützen jetzt 73 Sprachen.
Weitere Informationen zur Sprachunterstützung von Dokument Intelligenz
Natürliche Leserichtung, Handschriftklassifizierung und Seitenauswahl: Mit diesem Update können Sie festlegen, dass Textzeilen in der natürlichen Leserichtung ausgegeben werden anstatt in der standardmäßigen Leserichtung von links nach rechts und von oben nach unten. Dazu verwenden Sie den neuen Abfrageparameter „readingOrder“ und legen ihn für eine benutzerfreundlichere Ausgabe der Leserichtung auf den Wert „natural“ fest. Für lateinische Sprachen klassifiziert die Dokument Intelligenz außerdem Textzeilen als handschriftlich oder nicht handschriftlich und gibt eine Konfidenzbewertung an.
Qualitätsverbesserungen beim vordefinierten Belegmodell: Dieses Update enthält zahlreiche Qualitätsverbesserungen für das vordefinierte Belegmodell, insbesondere rund um die Extraktion von Einzelposten.


November 2020
Dokument Intelligenz v2.1-preview.2 wurde veröffentlicht und enthält die folgenden Features:
Neues vordefiniertes Rechnungsmodell: Mit dem neuen vordefinierten Rechnungsmodell können Kunden Rechnungen in verschiedenen Formaten erstellen und strukturierte Daten zurückgeben, um die Rechnungsverarbeitung zu automatisieren. Es kombiniert unsere leistungsstarken Funktionen zur optischen Zeichenerkennung (Optical Character Recognition, OCR) mit Deep Learning-Modellen zum Rechnungsverständnis, um wichtige Informationen aus Rechnungen in englischer Sprache zu extrahieren. Es extrahiert wichtige Angaben, Tabellen und Informationen wie Kunde, Anbieter, Rechnungs-ID, Fälligkeitsdatum für die Rechnung, Summe, fälliger Betrag, Steuerbetrag, Lieferadresse und Rechnungsadresse.

Erweiterte Tabellenextraktion – Dokument Intelligenz bietet jetzt eine verbesserte Tabellenextraktion, die unsere leistungsstarken OCR-Funktionen (Optical Character Recognition, Optische Zeichenerkennung) mit einem Deep Learning-Modell für Tabellenextraktion kombiniert. Dokument Intelligenz kann Daten aus Tabellen extrahieren, einschließlich komplexer Tabellen mit zusammengeführten Spalten, Zeilen, ohne Rahmen und mehr.
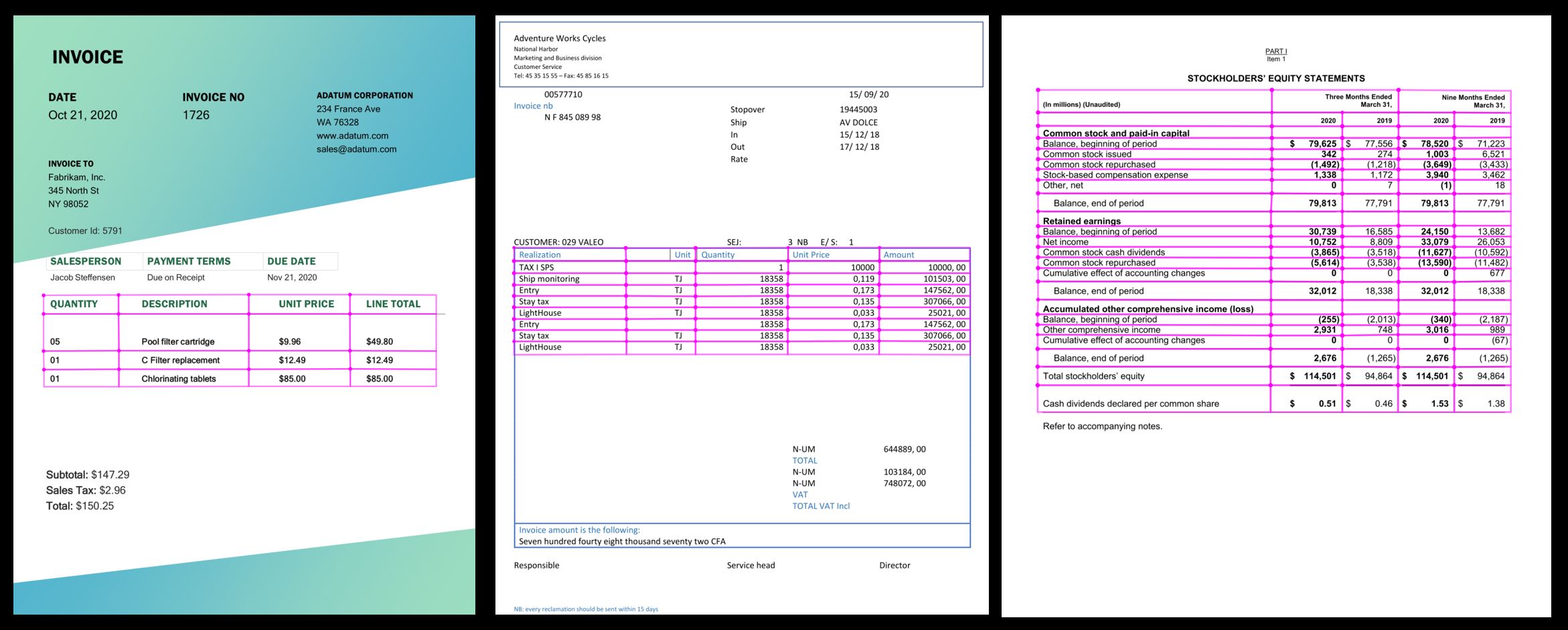
Update der Clientbibliothek: Die aktuelle Version der Clientbibliotheken für .NET, Python, Java und JavaScript unterstützt die Dokument Intelligenz 2.1-API.
Neue unterstützte Sprache: Japanisch - Die folgenden neuen Sprachen werden jetzt unterstützt: für
AnalyzeLayoutundAnalyzeCustomForm: Japanisch (ja). SprachunterstützungTextzeilenstilanzeige (handschriftlich/anders) (nur lateinische Sprachen) – Dokument Intelligenz gibt jetzt ein
appearance-Objekt aus, das – zusammen mit einer Konfidenzbewertung – jeweils klassifiziert, ob eine Textzeile von Hand geschrieben wurde oder nicht. Dieses Feature wird nur für lateinische Sprachen unterstützt.Qualitätsverbesserungen – Extraktionsverbesserungen, einschließlich Verbesserungen der einstelligen Extraktion.
Neues Feature „try-it-out“ im Tool für die Beschriftung von Beispielen für die Dokument Intelligenz – Möglichkeit zum Ausprobieren von vordefinierten Modellen für Rechnungen, Quittungen und Visitenkarten sowie der Layout-API mithilfe dieses Tools. Sehen Sie sich an, wie Ihre Daten extrahiert werden, ohne Code schreiben zu müssen.
Tool für die Beschriftung von Beispielen für Dokument Intelligenz testen

- Feedbackschleife – Wenn Sie Dateien über das Tool für die Bezeichnung von Beispielen analysieren, können Sie es jetzt auch dem Trainingssatz hinzufügen und die Bezeichnungen bei Bedarf anpassen und trainieren, um das Modell zu verbessern.
- Automatisches Bezeichnen von Dokumenten:: Bezeichnet hinzugefügte Dokumente automatisch basierend auf zuvor bezeichneten Dokumenten im Projekt.


August 2020
**Dokument Intelligenz
v2.1-preview.1umfasst die folgenden Funktionen:- REST-API-Referenz ist verfügbar - Anzeigen der
v2.1-preview.1 reference. - Neue unterstützte Sprachen Zusätzlich zu Englisch () werden jetzt die folgenden Sprachen () unterstützt: für
LayoutundTrain Custom Model: Englisch (en), Chinesisch (vereinfacht) (zh-Hans), Niederländisch (nl), Französisch (fr), Deutsch (de), Italienisch (it), Portugiesisch (pt) und Spanisch (es). - Kontrollkästchen-/Auswahlmarkierungserkennung: Dokument Intelligenz unterstützt das Erkennen und Extrahieren von Auswahlmarkierungen, z. B. von Kontrollkästchen und Optionsfeldern. Auswahlmarkierungen werden in
Layoutextrahiert, und Sie können jetzt auchTrain Custom Model-Layout, um Schlüssel-Wert-Paare für Auswahlmarkierungen zu extrahieren. - Model Compose – Ermöglicht das Zusammensetzen und Aufrufen mehrerer Modelle mit einer einzigen Modell-ID. Wenn Sie ein Dokument zur Analyse mit einer zusammengesetzten Modell-ID übermitteln, wird zunächst ein Klassifizierungsschritt durchgeführt, um es an das richtige benutzerdefinierte Modell weiterzuleiten. Model Compose steht für das
Train Custom Model-Train Custom Modelzur Verfügung. - Modellname – Fügen Sie Ihren benutzerdefinierten Modellen einen Anzeigenamen zur einfacheren Verwaltung und Nachverfolgung hinzu.
- Neues vordefiniertes Modell für Visitenkarten zum Extrahieren allgemeiner Felder von Visitenkarten in englischer Sprache.
- Neue Gebietsschemas für vordefinierte Belege: Neben Unterstützung für en-US ist jetzt auch zusätzliche Unterstützung für en-AU, en-CA, en-GB und en-IN verfügbar.
- Qualitätsverbesserungen für
Layout,Train Custom Model- Trainieren ohne Bezeichnungen und Trainieren mit Bezeichnungen.
- REST-API-Referenz ist verfügbar - Anzeigen der
v2.0 enthält das folgende Update:
- Die Clientbibliotheken für NET, Python, Java und JavaScript sind allgemein verfügbar.
Neue Beispiele sind auf GitHub verfügbar.
- Unter Knowledge Extraction Recipes – Forms Playbook werden bewährte Methoden aus echten Kundenprojekten mit der Dokument Intelligenz gesammelt und nützliche Codebeispiele, Checklisten und Beispielpipelines für die Entwicklung dieser Projekte bereitgestellt.
- Das Stichprobenbezeichnungstool wurde aktualisiert, um die neue Funktionalität von v2.1 zu unterstützen. Informationen zu den ersten Schritten mit dem Tool finden Sie in diesem Schnellstart.
- Im Dokument Intelligenz-Beispiel Intelligent Kiosk wird gezeigt, wie
Analyze ReceiptundTrain Custom Model- Trainieren ohne Bezeichnungen integriert werden.
Juli 2020
- Document Intelligence v2.0-Referenz verfügbar: Weitere Informationen finden Sie in der v2.0 API-Referenz sowie in den aktualisierten Clientbibliotheken für .NET, Python, Java und JavaScript.
Tabellenerweiterungen und Extraktionserweiterungen – Umfasst Verbesserungen der Genauigkeit und der Tabellenextraktion, insbesondere eine Funktion zum Erlernen von Tabellenheadern und -strukturen beim benutzerdefinierten Trainieren ohne Bezeichnungen.
Währungsunterstützung – Erkennung und Extraktion von globalen Währungssymbolen.
Azure Gov – Dokument Intelligenz steht jetzt auch in Azure Gov zur Verfügung.
Erweiterte Sicherheitsfeatures:
- Bring Your Own Key (BYOK) – Dokument Intelligenz verschlüsselt Ihre Daten automatisch, wenn sie in der Cloud persistent gespeichert werden, um sie zu schützen und Sie bei der Einhaltung der Sicherheits- und Complianceverpflichtungen Ihrer Organisation zu unterstützen. Standardmäßig verwendet Ihr Abonnement von Microsoft verwaltete Verschlüsselungsschlüssel. Sie können Ihr Abonnement jetzt auch mit eigenen Verschlüsselungsschlüsseln verwalten. Kundenseitig verwaltete Schlüssel, auch bezeichnet als „Bring Your Own Key“ (BYOK), bieten eine größere Flexibilität beim Erstellen, Rotieren, Deaktivieren und Widerrufen von Zugriffssteuerungen. Außerdem können Sie die zum Schutz Ihrer Daten verwendeten Verschlüsselungsschlüssel überwachen.
- Private Endpunkte: Ermöglichen in einem virtuellen Netzwerk den sicheren Zugriff auf Daten über eine private Verbindung.
Juni 2020
- CopyModel-API zu Clientbibliotheken hinzugefügt: Sie können jetzt Modelle mithilfe der Clientbibliotheken von einem Abonnement in ein anderes kopieren. Allgemeine Informationen zu diesem Feature finden Sie unter Sichern und Wiederherstellen von Modellen.
- Azure Active Directory-Integration: Sie können jetzt Ihre Azure AD-Anmeldeinformationen verwenden, um die Document Intelligence-Clientobjekte in den Clientbibliotheken zu authentifizieren.
- SDK-spezifische Änderungen – Hierzu zählen sowohl geringfügige Featureergänzungen als auch Breaking Changes. Weitere Informationen finden Sie in den SDK-Änderungsprotokollen.
April 2020
- SDK-Unterstützung für Version 2.0 der Dokument Intelligenz-API (Public Preview): In diesem Monat haben wir unsere Dienstunterstützung um ein Vorschau-SDK für Dokument Intelligenz Version 2.0 erweitert. Verwenden Sie die folgenden Links für die ersten Schritte mit Ihrer bevorzugten Programmiersprache:
- .NET SDK
- Java SDK
- Python SDK
- JavaScript SDK
Das neue SDK unterstützt alle Features von Version 2.0 der REST-API für Dokument Intelligenz. Sie können Ihr Feedback zu den Clientbibliotheken über das SDK-Feedbackformular teilen.
Kopieren eines benutzerdefinierten Modells: Mithilfe der neuen Funktion zum Kopieren benutzerdefinierter Modelle können Sie nun Modelle zwischen Regionen und Abonnements kopieren. Vor dem Aufrufen der API zum Kopieren eines benutzerdefinierten Modells müssen Sie zunächst die Autorisierung zum Kopieren in die Zielressource erhalten. Diese Autorisierung wird durch Aufrufen des Vorgangs für die Kopierautorisierung für den Zielressourcenendpunkt erreicht.
REST-API zum Generieren einer Kopierautorisierung
REST-API zum Kopieren eines benutzerdefinierten Modells
Verbesserungen der Sicherheit
Kundenseitig verwaltete Schlüssel stehen jetzt für die Formularerkennung zur Verfügung. Weitere Informationen finden Sie unter Verschlüsselung für ruhende Daten der Dokument Intelligenz.
Verwenden Sie verwaltete Identitäten für den Zugriff auf Azure-Ressourcen mit Azure Active Directory. Weitere Informationen finden Sie unter Autorisieren des Zugriffs auf verwaltete Identitäten.
März 2020
- Werttypen für die Beschriftung Sie können nun die Typen der Werte angeben, die Sie mit dem Tool zur Beschriftung von Beispielen für Dokument Intelligenz beschriften. Derzeit werden die folgenden Werttypen und Variationen unterstützt:
string- Standardwert,
no-whitespaces,alphanumeric
- Standardwert,
number- Standardwert,
currency
- Standardwert,
date- Standardwert,
dmy,mdy,ymd
- Standardwert,
timeinteger
Weitere Informationen zur Verwendung dieses Features finden Sie in der Anleitung zum Tool zum Bezeichnen von Beispielen.
Visualisierung von Tabellen Im Tool für die Bezeichnung von Beispielen werden nun im Dokument erkannte Tabellen angezeigt. Mithilfe dieses Features können Sie die erkannten und extrahierten Tabellen aus dem Dokument anzeigen, bevor Sie die Beschriftung und Analyse durchführen. Dieses Feature kann mithilfe der Ebenenoption aktiviert bzw. deaktiviert werden.
Die folgende Abbildung ist ein Beispiel für die Erkennung und Extraktion von Tabellen:
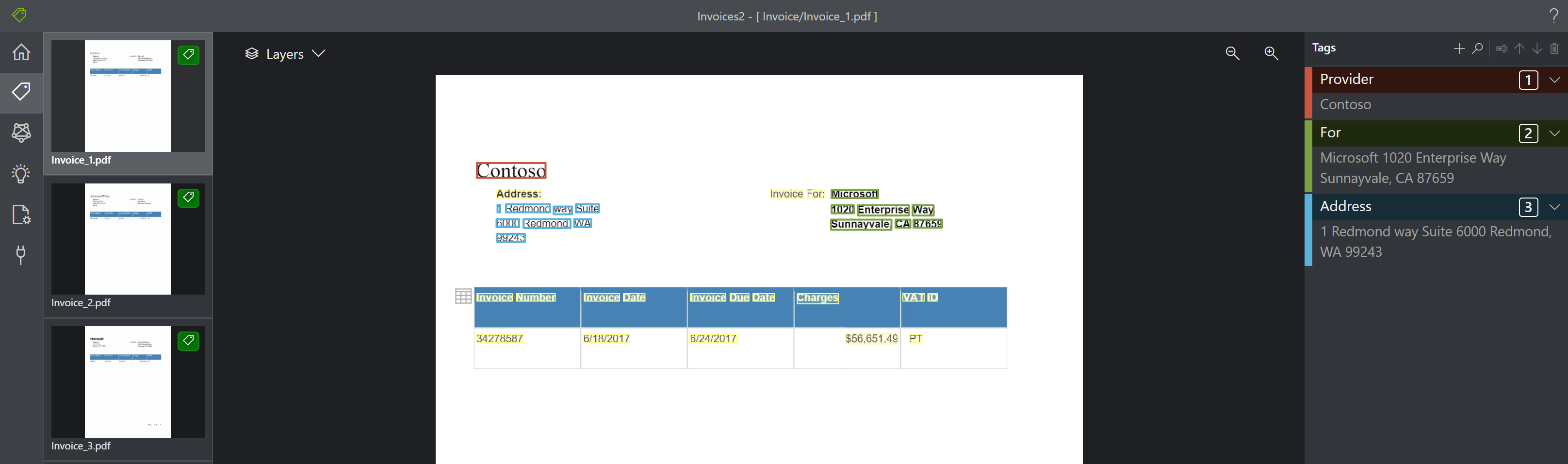
Die extrahierten Tabellen stehen in der JSON-Ausgabe unter
"pageResults"zur Verfügung.Wichtig
Das Beschriften von Tabellen wird nicht unterstützt. Nicht automatisch erkannte und extrahierte Tabellen können nur als Schlüssel-Wert-Paare beschriftet werden. Beim Beschriften von Tabellen als Schlüssel-Wert-Paare muss jede Zelle als eindeutiger Wert beschriftet werden.
Extraktionsverbesserungen
Dieses Release bietet Verbesserungen bei der Extraktion sowie eine verbesserte Genauigkeit. Hierzu zählt insbesondere die Möglichkeit, mehrere Schlüssel-Wert-Paare in der gleichen Textzeile zu beschriften und zu extrahieren.
Tool für die Beschriftung von Beispielen jetzt als Open-Source-Projekt verfügbar
Das Tool zur Beschriftung von Beispielen für Dokument Intelligenz ist jetzt als Open-Source-Projekt verfügbar. Sie können es in Ihre Lösungen integrieren und kundenspezifische Änderungen vornehmen, um es an Ihre individuellen Anforderungen anzupassen.
Weitere Informationen zum Tool zur Beschriftung von Beispielen für Dokument Intelligenz finden Sie in der Dokumentation auf GitHub.
Erzwingung von
TLS1.2TLS1.2 wird jetzt für alle HTTP-Anforderungen erzwungen, die an diesen Dienst gesendet werden. Weitere Informationen finden Sie unter Azure KI Services-Sicherheit.
Januar 2020
In dieser Version wird Dokument Intelligenz 2.0 eingeführt. In den folgenden Abschnitten finden Sie weitere Informationen zu neuen Features, Verbesserungen und Änderungen.
Neue Funktionen
Benutzerdefiniertes Modell
- Trainieren mit Bezeichnungen Sie können jetzt ein benutzerdefiniertes Modell mit manuell gekennzeichneten Daten trainieren. Diese Methode führt zu Modellen mit besserer Leistung und kann Modelle hervorbringen, die mit komplexen Formularen oder Formularen arbeiten, die Werte ohne Schlüssel enthalten.
- Asynchrone API Sie können asynchrone API-Aufrufe verwenden, um mit großen Datasets und Dateien zu trainieren und diese zu analysieren.
- Unterstützung von TIFF-Dateien Sie können jetzt mit TIFF-Dokumenten trainieren und Daten aus ihnen extrahieren.
- Verbesserte Extrahierungsgenauigkeit
Vordefiniertes Belegmodell
- Trinkgeldbeträge Sie können jetzt Trinkgeldbeträge und andere handschriftliche Werte extrahieren.
- Extraktion von Zeilenelementen Sie können Werte von Zeilenelementen aus Belegen extrahieren.
- Zuverlässigkeitswerte Sie können die Zuverlässigkeit des Modells für jeden extrahierten Wert anzeigen.
- Verbesserte Extrahierungsgenauigkeit
- Layoutextraktion Sie können nun mit der Layout-API Textdaten und Tabellendaten aus Ihren Formularen extrahieren.
Änderungen an der benutzerdefinierten Modell-API
Alle APIs für das Trainieren und Verwenden benutzerdefinierter Modelle wurden umbenannt, und einige synchrone Methoden sind jetzt asynchron. Dies sind die wichtigsten Änderungen:
- Der Prozess zum Trainieren eines Modells ist jetzt asynchron. Sie initiieren das Training über den API-Aufruf /custom/models. Dieser Aufruf gibt eine Vorgangs-ID zurück, die Sie in custom/models/{modelID} übergeben können, um die Trainingsergebnisse zurückzugeben.
- Die Schlüssel-Wert-Extraktion wird jetzt vom API-Aufruf /custom/models/{modelID}/analyze initiiert. Dieser Aufruf gibt eine Vorgangs-ID zurück, die Sie in custom/models/{modelID}/analyzeResults/{resultID} übergeben können, um die Extraktionsergebnisse zurückzugeben.
- Vorgangs-IDs für das Trainieren finden sich jetzt im Header Location von HTTP-Antworten, nicht mehr im Header Operation-Location.
Änderungen an der Beleg-API
Die APIs zum Lesen von Belegen wurden umbenannt.
Die Extraktion von Belegdaten wird jetzt vom API-Aufruf /prebuilt/receipt/analyze initiiert. Dieser Aufruf gibt eine Vorgangs-ID zurück, die Sie in /prebuilt/receipt/analyzeResults/{resultID} übergeben können, um die Extraktionsergebnisse zurückzugeben.
Änderungen am Ausgabeformat
- Die JSON-Antworten für alle API-Aufrufe haben neue Formate. Einige Schlüssel und Werte wurden hinzugefügt, entfernt oder umbenannt. Beispiele für die aktuellen JSON-Formate finden Sie in den Schnellstarts.
Nächste Schritte
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe von Dokument Intelligenz Studio zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.
Versuchen Sie, Ihre eigenen Formulare und Dokumente mithilfe des Dokument Intelligenz-Stichproben-Bezeichnungstools zu verarbeiten.
Führen Sie eine Dokument Intelligenz-Schnellstartanleitung durch, und beginnen Sie mit der Erstellung einer Anwendung zur Dokumentverarbeitung in der Entwicklungssprache Ihrer Wahl.