Was ist ein Data Lake?
Ein Data Lake ist ein Repository zur Speicherung großer Datenmengen in ihrem nativen Rohformat. Data Lake-Speicher sind für die Skalierung auf Terabytes und Petabytes von Daten optimiert. Die Daten stammen in der Regel aus mehreren heterogenen Quellen und können strukturiert, teilweise strukturiert oder unstrukturiert sein. Ein Data Lake ist dazu gedacht, alles ohne jegliche Umwandlung im ursprünglichen Zustand zu speichern. Dieser Ansatz unterscheidet sich von einem herkömmlichen Data Warehouse: Hier werden die Daten bei der Erfassung transformiert und verarbeitet.
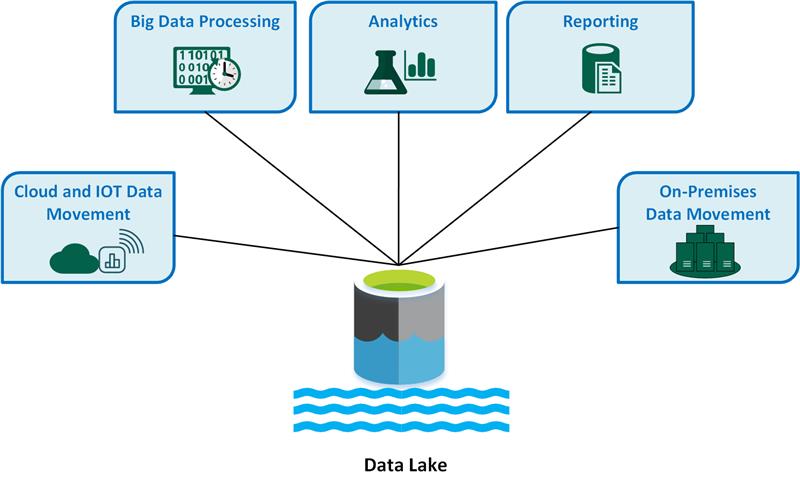
Im Anschluss sind wichtige Data Lake-Anwendungsfälle aufgeführt:
- Cloud- und IoT-Datenverschiebung
- Big Data-Verarbeitung
- Analytics
- Berichterstellung
- Lokale Datenverschiebung
Vorteile eines Data Lakes:
- Die Daten werden in ihrem Rohformat gespeichert, sodass keine Daten verloren gehen. Dies ist besonders in einer Big Data-Umgebung hilfreich, in der Sie unter Umständen nicht im Voraus wissen, welche Insights aus den Daten gewonnen werden können.
- Benutzer können die Daten untersuchen und eigene Abfragen erstellen.
- Ist ggf. schneller als herkömmliche ETL-Tools.
- Flexibler als ein Data Warehouse, da sowohl unstrukturierte als auch teilweise strukturierte Daten gespeichert werden können.
Ein vollständige Data Lake-Lösung umfasst sowohl Speicherung als auch Verarbeitung. Data Lake-Speicher ist für Fehlertoleranz, unbegrenzte Skalierbarkeit sowie für die Erfassung verschiedenster Daten mit hohem Durchsatz konzipiert. Die Data Lake-Verarbeitung basiert auf mindestens einem auf diese Ziele ausgerichteten Verarbeitungsmodul und ermöglicht die skalierte Verarbeitung der Daten aus einem Data Lake.
Verwendung eines Data Lakes
Ein Data Lake wird üblicherweise zum Durchsuchen von Daten, für die Datenanalyse und für Machine Learning verwendet.
Darüber hinaus kann ein Data Lake auch als Datenquelle für ein Data Warehouse fungieren. Bei diesem Ansatz werden die Rohdaten in den Data Lake aufgenommen und anschließend in ein abfragbares strukturiertes Format transformiert. Für diese Transformation wird in der Regel eine ELT-Pipeline (Extrahieren, Laden, Transformieren) verwendet, wodurch die Daten erfasst und direkt transformiert werden. Quelldaten, die bereits relational sind, können über einen ETL-Prozess ohne Umweg über den Data Lake in das Data Warehouse aufgenommen werden.
Data Lake-Speicher werden häufig zum Streamen von Veranstaltungen oder für IoT-Szenarien verwendet, da sie große Mengen von relationalen und nicht relationalen Daten ohne Transformation oder Schemadefinition aufnehmen können. Sie sind auf eine große Anzahl kleiner Schreibvorgänge mit geringer Wartezeit ausgelegt und für enormen Durchsatz optimiert.
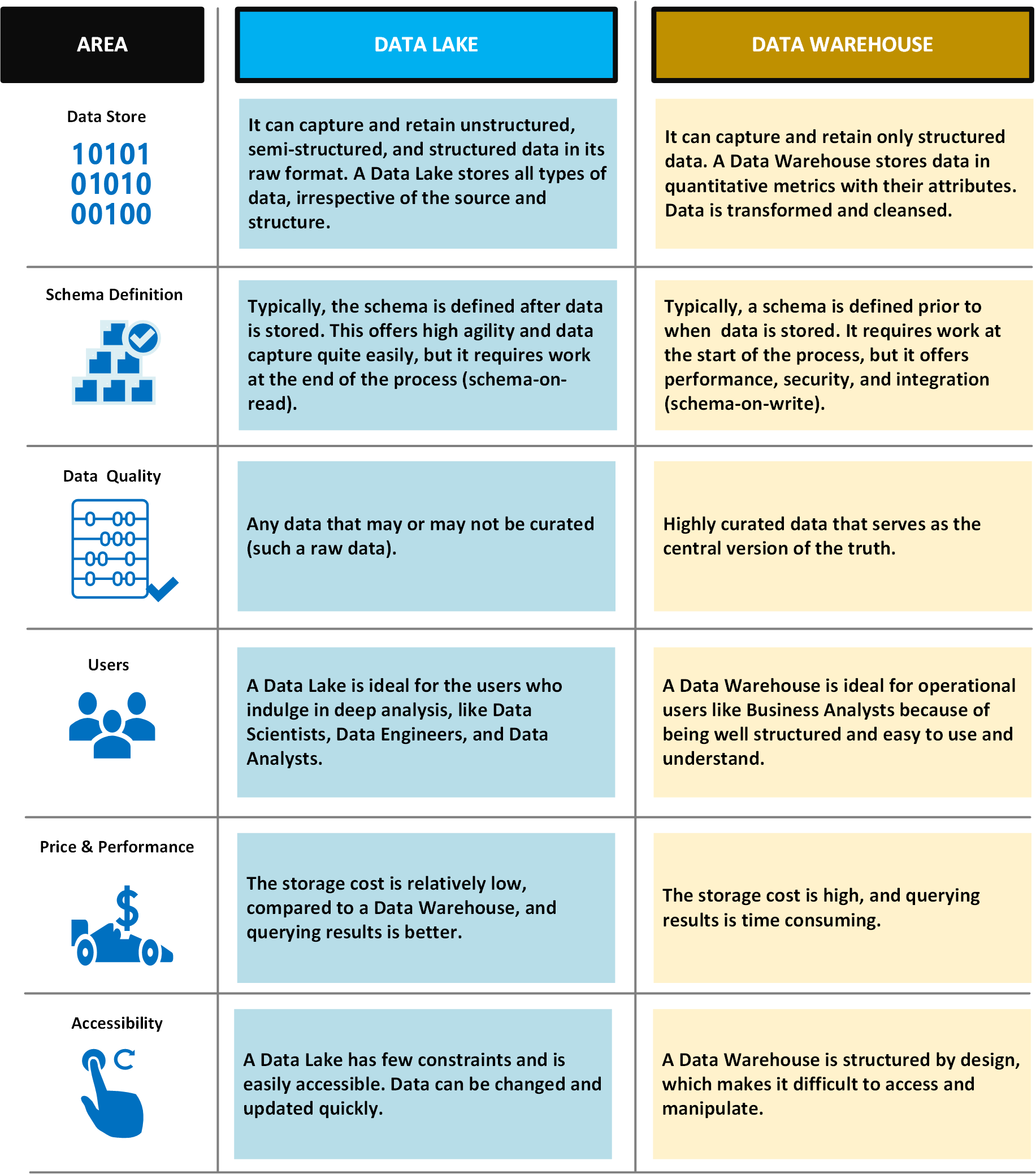
In der folgenden Tabelle werden Data Lakes und Data Warehouses verglichen:
Herausforderungen
- Ohne Schema oder beschreibende Metadaten lassen sich die Daten ggf. nur schwer nutzen oder abfragen.
- Mangelnde semantische Konsistenz zwischen den Daten kann die Datenanalyse für Benutzer ohne fundierte Datenanalysekompetenzen erschweren.
- Unter Umständen lässt sich die Qualität der in den Data Lake eingehenden Daten nur schwer garantieren.
- Ohne angemessene Governance kann es zu Problemen bei der Zugriffssteuerung und beim Datenschutz kommen. Welche Informationen werden in den Data Lake aufgenommen, wer kann auf diese Daten zugreifen, und wie können die Daten genutzt werden?
- Ein Data Lake ist vielleicht nicht die beste Integrationsmethode für Daten, die bereits relational ist.
- Für sich allein bietet ein Data Lake keine integrierten oder ganzheitlichen Ansichten für die gesamte Organisation.
- Ein Data Lake kann sich zu einem Sammelplatz für Daten entwickeln, die eigentlich nie analysiert oder zur Gewinnung von Insights genutzt werden.
Auswahl der Technologie
Erstellen Sie Data Lake-Lösungen mithilfe der folgenden von Azure angebotenen Dienste:
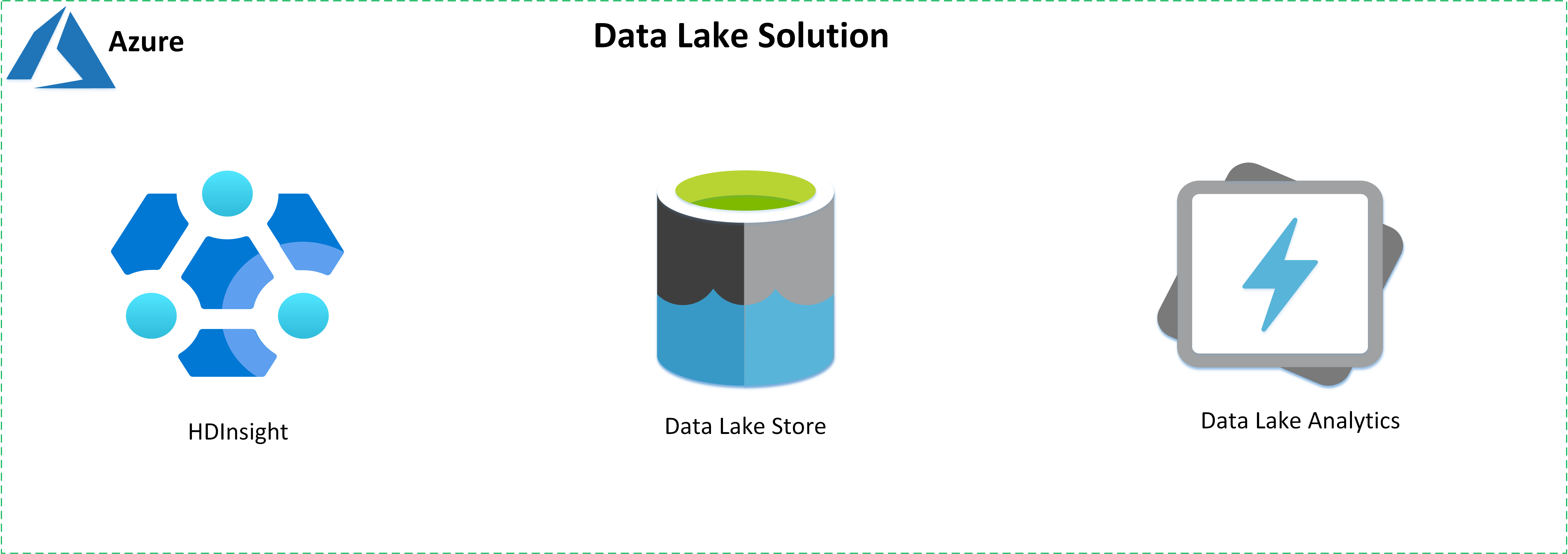
- Azure HD Insight ist ein umfassender, verwalteter Open-Source-Analysedienst in der Cloud für Unternehmen.
- Azure Data Lake Storage ist ein Hadoop-kompatibles Hyperscale-Repository.
- Azure Data Lake Analytics ist ein bedarfsgesteuerter Dienst für Analyseaufträge zum Vereinfachen von Big Data-Analysen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Avijit Prasad | Cloudberater
Nächste Schritte
- Was ist Azure HDInsight?
- Einführung in Azure Data Lake Storage
- Dokumentation zu Azure Data Lake Analytics
- Einführung in Azure Data Lake Storage (Trainingsmodul)
- Was ist ein Data Lake?
Verwandte Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für